
- We’re rolling out MySQL Raft with the aim to eventually replace our current MySQL semisynchronous databases.
- The biggest win of MySQL Raft was simplification of the operation and making MySQL servers take care of promotions and membership. This gave the provable safety of Raft and reduced significant operational pain.
- Making MySQL server a true distributed system also has opened up possibilities in downstream systems to leverage it. Some of these ideas are starting to take shape.
At Meta, we run one of the largest deployments of MySQL in the world. The deployment powers the social graph along with many other services, like Messaging, Ads, and Feed. Over the last few years, we have implemented MySQL Raft, a Raft consensus engine that was integrated with MySQL to build a replicated state machine. We have migrated a large portion of our deployment to MySQL Raft and plan to fully replace the current MySQL semisynchronous databases with it. The project has delivered significant benefits to the MySQL deployment at Meta, including higher reliability, provable safety, significant improvements in failover time, and operational simplicity — all with equal or comparable write performance.
Background
To allow for high availability, fault tolerance, and scaling reads, Meta’s MySQL datastore is a massively sharded, geo-replicated deployment with millions of shards, holding petabytes of data. The deployment includes thousands of machines running over several regions and data centers across multiple continents.
Previously, our replication solution used the MySQL semisynchronous (semisync) replication protocol. This was a data path–only protocol. The MySQL primary would use semisynchronous replication to two log-only replicas (logtailers) within the primary region but outside of the primary’s failure domain. These two logtailers would act as semisynchronous ACKer (An ACK is an acknowledgment to the primary that the transaction has been locally written). This would allow the data path to have very low latency (sub-millisecond) commits and would provide high availability/durability for the writes. Regular MySQL primary-to-replica asynchronous replication was used for wider distribution to other regions.
The control plane operations (e.g., promotions, failover, and membership change) would be the responsibility of a set of Python daemons (henceforth called automation). Automation would do the necessary orchestration to promote a new MySQL server in a failover location as a primary. The automation would also point the previous primary and the remaining replicas to replicate from the new primary. Membership change operations would be orchestrated by another piece of automation called MySQL pool scanner (MPS). To add a new member, MPS would point the new replica to the primary and add it to the service discovery store. A failover would be a more complex operation in which the tailing threads of the logtailers (semisynchronous ACKers) would be shut down to fence the previous dead primary.
Why was MySQL Raft necessary?
In the past, to help guarantee safety and avoid data loss during the complex promotion and failover operations, several automation daemons and scripts would use locking, orchestration steps, a fencing mechanism, and SMC, a service discovery system. It was a distributed setup, and it was difficult to accomplish this atomically. The automation became more complex and harder to maintain over time as more and more corner cases needed to be patched.
We decided to take a completely different approach. We enhanced MySQL and made it a true distributed system. Realizing that control plane operations like promotions and membership changes were the trigger of most issues, we wanted the control plane and data plane operations to be part of the same replicated log. For this, we used the well-understood consensus protocol Raft. This also meant that the source of truth of membership and leadership moved inside the server (mysqld). This was the single biggest contribution of bringing in Raft because it enabled provable correctness (safety property) across promotions and membership changes into the MySQL server.
The Raft library and the MySQL Raft plugin
Our implementation of Raft for MySQL is based on Apache Kudu. We enhanced it significantly for the needs of MySQL and our deployment. We published this fork as an open source project, kuduraft.
Some of the key features that we added to kuduraft are:
- FlexiRaft — support for two different intersecting quorums: the data quorum and the leader election quorum
- Proxying — the ability to use a proxy intermediate node to reduce network bandwidth
- Compression — where we compress binary log (transaction) payloads once before distribution
- Log abstraction — to support different physical logfile implementations
- Primary ban — the ability to prevent some entities from being primary temporarily
We also had to make relatively big changes to MySQL replication to interface with Raft. For this, we created a new closed source MySQL plugin called MyRaft. MySQL would interface with MyRaft through the plugin APIs (similar APIs had been used for semisync as well), while we created a separate API for MyRaft to interface back with MySQL server (callbacks).
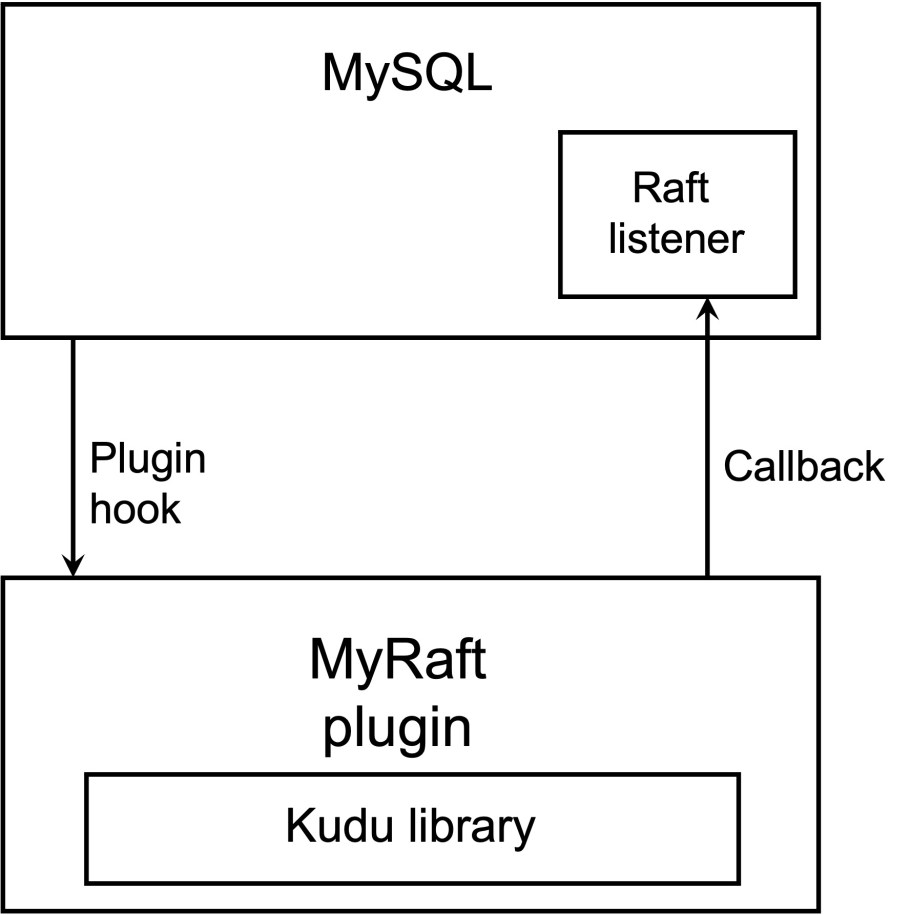
MySQL Raft replication topologies
A Raft ring would consist of several MySQL instances (four in the diagram) in different regions. The communication round-trip time (RTT) between these regions would range from 10 to 100 milliseconds. A few of these MySQLs (typically three) were allowed to become primaries, while the rest of them were only allowed to be pure read replicas (non-primary-capable). The MySQL deployment at Meta also has a long-standing requirement for extremely low latency commits. The services that use MySQL as a store (e.g., the social graph) need or have been designed to such extremely fast writes.
To meet this requirement, the configuration of FlexiRaft would use only in-region commits (single region dynamic mode). To enable this, each primary capable region would have two additional logtailers (witnesses or log-only entities). The data quorum for writes would be 2/3 (2 ACKs out of the 1 MySQL + 2 logtailers). Raft would still manage and run a replicated log across all the entities (1 primary-capable MySQL + 2 logtailers ) * 3 regions + (non-primary-capable MySQL) * 3 regions = 12 entities.
Raft roles: The leader, as the name suggests, is the leader in a term of the replicated log. A leader in Raft would also be the primary in MySQL and the one accepting client writes. The follower is a voting member of the ring and passively receives messages (AppendEntries) from the leader. A follower would be a replica in MySQL’s point of view and would be applying the transactions to its engine. It would not allow direct writes from user connections (read_only=1 is set). A learner would be a non-voting member of the ring, e.g., the three MySQLs in non-primary-capable regions (above). It would be a replica in MySQL’s point of view.

Replicated log
For replication, MySQL has historically used the binary log format. This format is central to MySQL’s replication, and we decided to preserve this. From the Raft perspective, the binary log became the replicated log. This was done via the log abstraction improvement to kuduraft. The MySQL transactions would be encoded as a series of events (e.g., Update Rows event) with a start and end for each transaction. The binary log would also have appropriate headers and would typically end with an ending event (Rotate event).
We had to tweak how MySQL manages its logs internally. On a primary, Raft would write to a binlog. This is no different from what happens in standard MySQL. In a replica, Raft would also write to a binlog instead of to a separate relay log in standard MySQL. This created simplicity for Raft as there was only one namespace of log files that Raft would be concerned about. If a follower were promoted to leader, it could seamlessly go back into its history of logs to send transactions to lagging members. The replica’s applier threads would pick up transactions from the binlog and then apply them to the engine. During this process, a new log file, the apply log, would be created. This apply log would play an important role in crash recovery of replicas but is otherwise a nonreplicated log file.
So, in summary:
In standard MySQL:
- Primary writes to binlog and sends binlog to replicas.
- Replicas receive in relay log and apply the transactions to the engine. During apply, a new replica-only binlog is created.
In MySQL Raft:
- Primary writes to binlog via Raft, and Raft sends binlog to followers/replicas.
- Replicas/followers receive in binlog and apply the transactions to the engine. An apply log is created during apply.
- Binlog is the replicated log from the Raft point of view.
Write transaction on MySQL primary using Raft
The transaction would first be prepared in the engine. This would happen in the thread of the user connection. The act of preparing the transaction would involve interactions with the storage engine (e.g., InnoDB or MyRocks) and generate an in-memory binlog payload for the transaction. At the time of commit, the write would pass through group commit/ordered_commit flow. GTIDs would be assigned, and then Raft would assign an OpId (term:index) to the transaction. At this point, Raft would compress the transaction, store it in its LogCache, and write through the transaction to a binlog file. It would asynchronously start shipping the transaction to other followers to get ACKs and reach consensus.
The user thread, which is in “commit” of the transaction, would be blocked, waiting for consensus from Raft. When Raft would get two out of three in-region votes, consensus commit would be reached. Raft would also ship the transaction to all out-of-region members but would ignore their votes because of an algorithm called FlexiRaft (described below). On consensus commit, the user thread would be unblocked, and the transaction would proceed and commit to the engine. After engine commit, the write query would finish and return to the client. Soon after, Raft would also asynchronously send a commit marker (OpId of current commit) to downstream followers so that they can also apply the transactions to their database.
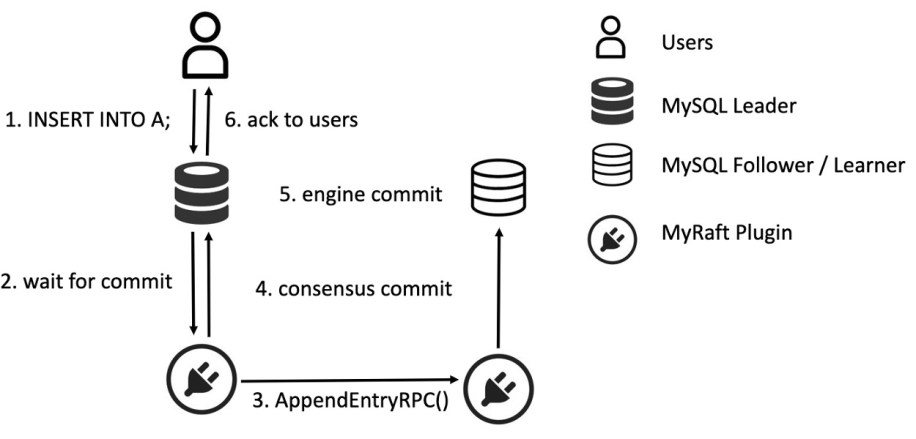
Crash recovery
Changes had to be made to crash recovery to make it work seamlessly with Raft. Crashes can happen at any time in the lifetime of a transaction and hence the protocol has to ensure consistency of members. Here are some key insights on how we made it work.
- Transaction was not flushed to binlog: In this case, the in-memory transaction payload (still in mysqld process memory as an in-memory buffer) would be lost and the prepared transaction in engine would be rolled back on process restart. Since there was no extra uncommitted transaction in the Raft log, no reconciliation with other members needs to be done.
- Transaction was flushed to binlog but never reached other members: Mysqld acts as a transaction coordinator and runs a two-phase commit protocol between the engine and the replicated binlog as the participants. On crash recovery, the prepared transaction in engine (e.g., InnoDB or MyRocks) would be rolled back (engine had not reached commit). Raft would go through failover, and a new leader would be elected. This leader would not have this transaction in its binlog and henceforth would truncate this transaction from the erstwhile leader’s binlog because of to a higher term (by pushing a No-Op message), when the erstwhile leader joins back the ring.
- Transaction was flushed to binlog and reached to next leader. Current leader died before committing to the engine: Similar to no. 2 above, the prepared transaction in the engine would be rolled back. The erstwhile leader would join the Raft ring as a follower. In this case, the new leader would have this transaction in its binlog and hence no truncation would happen, since the logs would match. When the commit marker is sent by the new leader, the transaction would be reapplied again from scratch.
Raft-initiated state machine transitions
Failover and regular maintenance operations can trigger leadership changes in Raft. After a leader is elected, the MyRaft plugin would try to to transition the accompanying MySQL into primary mode. For this, the plugin would orchestrate a set of steps. These callbacks from Raft → MySQL would abort in-flight transactions, roll back in-use GTIDs, transition the engine side log from apply-log to binlog, and eventually set the proper read_only settings. This mechanism is complex and currently not open sourced.
FlexiRaft
Since the Raft paper and Apache Kudu supported only a single global quorum, it would not work well at Meta, where rings were large but the data path quorum needed to be small.
To circumvent this issue, we innovated on FlexiRaft, borrowing ideas from Flexible Paxos.
At a high level, FlexiRaft allows Raft to have a different data commit quorum (small) but take a corresponding hit on the leader election quorum (large). By following provable guarantees of quorum intersection, FlexiRaft ensures that the longest log rules of Raft and the appropriate quorum intersection will guarantee provable safety.
FlexiRaft supports single region dynamic mode. In this mode, members are grouped together by their geo-region. The current quorum of Raft depends on who the current leader is (hence the name “single region dynamic”). The data quorum is the majority of voters in the leader’s region. During promotions, if terms are continuous, the Candidate will intersect with the last known leader’s region. FlexiRaft would also ensure that the quorum of the Candidate’s region is also attained, otherwise the subsequent No-Op message could get stuck. If in the rare case the terms are not continuous, Flexi Raft would try to figure out a growing set of regions which need to be intersected with for safety or, in the worst case, would fall back to the N region intersection case of Flexible Paxos. Thanks to pre-elections and mock elections, the incidences of term gaps are rare.
Control plane operations (promotions and membership changes)
In order to serialize promotion and membership change events in the binlog, we hijacked the Rotate Event and Metadata event of the MySQL binary log format. These events would carry the equivalent of No-Op messages and add-member/remove-member operations of Raft. Apache Kudu did not have support for joint consensus, hence we only allow one-at-a-time membership changes (you can change the membership by only one entity in one round to follow the rules of implicit quorum intersection).
Automation
With the implementation of MySQL Raft, we reached a very clean separation of concerns for the MySQL deployment. The MySQL server would be responsible for safety via Raft’s replicated state machine. The no-data-loss guarantee would be provably enshrined in the server itself. Automation (Python scripts, daemons) would initiate control plane operations and monitor the health of the fleet. It would also replace members or do promotions via Raft during maintenance or when a host failure was detected. Once in a while, automation could also change the regional placement of MySQL topology. Changing the automation to adapt to Raft was a massive undertaking, spanning multiple years of development and rollout effort.
During prolonged maintenance events, automation would set leadership ban information on Raft. Raft would disallow those banned entities from becoming leader or evacuate them promptly on inadvertent election. The automation would also promote away from those regions into other regions.
Learning from rollouts and challenges encountered along the way
Rolling out Raft to the fleet was a huge learning for the team. We initially developed Raft on MySQL 5.6 and had to migrate to MySQL 8.0.
One of the key learnings was that while correctness was easier to reason with Raft, the Raft protocol in itself does not help much in the concern of availability. Since our MySQL data quorum was very small (two out of three in-region members), two bad entities in the region could pretty much shatter the quorum and bring down availability. The MySQL fleet undergoes a good amount of churn every day (due to maintenance, host failures, rebalancing operations), so initiating and doing membership changes promptly and correctly were a key requirements for constant availability. A large part of the rollout effort was focused at doing logtailer and MySQL replacements promptly so that the Raft quorums were healthy.
We had to enhance kuduraft to make it more robust for availability. These improvements were not part of the core protocol but can be considered as engineering add-ons to it. Kuduraft has the support for pre-elections, but pre-elections are done only during a failover. During a graceful transfer of leadership, the designated Candidate moves directly to a real election, bumping the term. This leads to stuck leaders (kuduraft does not do auto step-down). To address this problem, we added a mock elections feature, which was similar to pre-elections but happened only upon a graceful transfer of leadership. Since this was an async operation, it did not increase promotion downtimes. A mock election would weed out cases where a real election would partially succeed and get stuck.
Handling byzantine failures: Raft’s membership list is considered to be blessed by Raft itself. But during the provisioning of new members, or because of races in automation, there could be bizarre cases of two different Raft rings intersecting. These zombie membership nodes had to be weeded out and should not be able to communicate with each other. We implemented a feature to block RPCs from such zombie members to the ring. This was, in some ways, a handling of a byzantine actor. We enhanced the Raft implementation after noticing these rare incidents that happened in our deployment.
Monitoring the MySQL Raft rollout
While launching MySQL Raft, one of the goals was to reduce operational complexity for on-calls, so that engineers could root-cause and mitigate issues. We built several dashboards, CLI tools, and scuba tables to monitor Raft. We added copious logging to MySQL, especially around the area of promotions and membership changes. We created CLIs for quorum and voting reports on a ring, which help us quickly identify when and why a ring is unavailable (shattered quorum). The investment in the tooling and automation infrastructure went hand-in-hand and might have been a bigger investment than the server changes. This investment paid off big-time and reduced operational and onboarding pain.
Quorum Fixer
Although it is undesirable, quorums do get shattered every now and then, leading to availability loss. The typical case is when automation does not detect unhealthy instances/logtailers in the ring and does not replace them quickly. This can happen because of poor detection, worker queue overload, or a lack of spare host capacity. Correlated failures, when multiple entities in the quorum go down at the same time, are less typical. These don’t happen often, because the deployments try to isolate failure domains across critical entities of the quorum through proper placement decisions. Long story short: At scale, unexpected things happen, despite existing safeguards. Tools need to be available to mitigate such situations in production. We built Quorum Fixer in anticipation of this.
Quorum Fixer is a manual remediation tool authored in Python that squelches the writes on the ring. It does out-of-band checks to figure out the longest log entity. It forcibly changes the quorum expectations for a leader election inside Raft, so that the chosen entity becomes a leader. After successful promotion, we reset the quorum expectation back, and the ring typically becomes healthy.
It was a conscious decision to not run this tool automatically, because we want to root cause and identify all cases of quorum loss and fix bugs along the way (not have them silently be fixed by automation).
Rolling out MySQL Raft
Transitioning from semisynchronous to MySQL Raft over a massive deployment is difficult. For this we created a tool (in Python) called enable-raft. Enable-raft orchestrates the transition from semisynchronous to Raft by loading the plugin and setting the appropriate configs (mysql sys-vars) on each of the entities. This process involves a small downtime for the ring. The tool was made robust over time and can roll out Raft at scale very quickly. We have used it to safely roll out Raft.
Testing and shadow workflow
Needless to say, doing a change in the core replication pipeline of MySQL is a very difficult project. Since data safety is at stake, testing was key for confidence. We leveraged shadow testing and failure injection significantly during the project. We would inject thousands of failovers and elections on test rings before every RPM package manager rollout. We would trigger replacements and membership changes on the test assets to trigger the critical code paths.
Long-running testing with data correctness checks were also key. We have automation that runs nightly on the shards, ensuring consistency of primaries and replicas. We are alerted to any such mismatch, and we debug it.
Performance
The performance of the write path latency for Raft was equivalent to semisync. The semisync machinery is slightly simpler and hence expected to be leaner, however we optimized Raft to get the same latencies as semi-sync. We optimized kuduraft to not add any more CPU to the fleet in spite of pulling in many more responsibilities that previously had been outside the server binary.
Raft made order-of-magnitude improvements to promotions and failover times. Graceful promotions, which are the bulk of leadership changes in the fleet, improved significantly, and we can typically finish a promotion in 300 milliseconds. In the semisync setups, since the service discovery store would be the source of truth, the clients noticing the finish of promotion would be much longer, leading to more elevated end user downtimes on a shard.
Raft typically does a failover within 2 seconds. This is because we heartbeat for Raft health every 500 milliseconds and start an election when three successive heartbeats fail. In the semisync world, this step was orchestration heavy and would take 20 to 40 seconds. Raft thereby gave a 10x improvement in downtimes for failover cases.
Next steps
Raft has helped solve problems with the operational management of MySQL at Meta by providing provable safety and simplicity. Our goals of having a hands off-management of MySQL consistency, and having tools for the rare cases of availability loss, are mostly met. Raft now opens up significant opportunities in the future, as we can focus on enhancing the offering to the services that use MySQL. One of the asks’ from our service owners is to have configurable consistency. Configurable consistency will allow the owners at the time of onboarding, to select whether the service needs X-region quorums or quorums that ask for copies in some specific geographies (e.g., Europe and the United States). FlexiRaft has seamless support for such configurable quorums, and we plan to start rolling out this support in the future. Such quorums will correspondingly lead to higher commit latencies, but use cases have to be able to trade-off between consistency and latency (e.g., PACELC theorem).
Because of the proxying feature (ability to send messages using a multihop distribution topology), Raft can also save network bandwidth across the Atlantic. We plan to use Raft to replicate from the United States to Europe only once, and then use Raft’s proxying feature to distribute within Europe. This will increase latency, but it will be nominal given that the bulk of the latency is in the cross-Atlantic transfer and the extra hop is much shorter.
Some of the more speculative ideas in Meta’s database deployments and distributed consensus space are about exploring leaderless protocols, like Epaxos. Our current deployments and services have worked with the assumptions that come with strong leader protocols, but we are starting to see a trickle of requirements where services would benefit from more uniform write latency in the WAN. Another idea that we are considering is to disentangle the log from the state machine (the database) into a disaggregated log setup. This will allow the team to manage the concerns of the log and replication separately from the concerns of the database storage and SQL execution engine.
Acknowledgements
Building and deploying MySQL Raft at Meta scale needed significant teamwork and management support. We would like to acknowledge the following people for their role in making this project a success. Shrikanth Shankar, Tobias Asplund, Jim Carrig, Affan Dar and David Nagle for supporting the team members during this journey. We would also like to thank the able Program Managers of this project Dan O and Karthik Chidambaram who kept us on track.
The engineering effort involved key contributions from several current and past team members including Vinaykumar Bhat, Xi Wang, Bartlomiej Pelc, Chi Li, Yash Botadra, Alan Liang, Michael Percy, Yoshinori Matsunobu, Ritwik Yadav, Luqun Lou, Pushap Goyal, Anatoly Karp and Igor Pozgaj.








