
- We’re introducing parameter vulnerability factor (PVF), a novel metric for understanding and measuring AI systems’ vulnerability against silent data corruptions (SDCs) in model parameters.
- PVF can be tailored to different AI models and tasks, adapted to different hardware faults, and even extended to the training phase of AI models.
- We’re sharing results of our own case studies using PVF to measure the impact of SDCs in model parameters, as well as potential methods of identifying SDCs in model parameters.
Reliability is an important aspect of any successful AI implementation. But the growing complexity and diversity of AI hardware systems also brings an increased risk of hardware faults such as bit flips. Manufacturing defects, aging components, or environmental factors can lead to data corruptions – errors or alterations in data that can occur during storage, transmission, or processing and result in unintended changes in information.
Silent data corruptions (SDCs), where an undetected hardware fault results in erroneous application behavior, have become increasingly prevalent and difficult to detect. Within AI systems, an SDC can create what is referred to as parameter corruption, where AI model parameters are corrupted and their original values are altered.
When this occurs during AI inference/servicing it can potentially lead to incorrect or degraded model output for users, ultimately affecting the quality and reliability of AI services.
Figure 1 shows an example of this, where a single bit flip can drastically alter the output of a ResNet model.

With this escalating thread in mind, there are two important questions: How vulnerable are AI models to parameter corruptions? And how do different parts (such as modules and layers) of the models exhibit different vulnerability levels to parameter corruptions?
Answering these questions is an important part of delivering reliable AI systems and services and offers valuable insights for guiding AI hardware system design, such as when assigning AI model parameters or software variables to hardware blocks with differing fault protection capabilities. Additionally, it can provide important information for formulating strategies to detect and mitigate SDCs in AI systems in an efficient and effective manner.
Parameter vulnerability factor (PVF) is a novel metric we’ve introduced with the aim to standardize the quantification of AI model vulnerability against parameter corruptions. PVF is a versatile metric that can be tailored to different AI models/tasks and is also adaptable to different hardware fault models. Furthermore, PVF can be extended to the training phase to evaluate the effects of parameter corruptions on the model’s convergence capability.
What is PVF?
PVF is inspired by the architectural vulnerability factor (AVF) metric used within the computer architecture community. We define a model parameter’s PVF as the probability that a corruption in that specific model parameter will lead to an incorrect output. Similar to AVF, this statistical concept can be derived from statistically extensive and meaningful fault injection (FI) experiments.
PVF has several features:
Parameter-level quantitative assessment
As a quantitative metric, PVF concentrates on parameter-level vulnerability, calculating the likelihood that a corruption in a specific model parameter will lead to an incorrect model output. This “parameter” can be defined at different scales and granularities, such as an individual parameter or a group of parameters.
Scalability across AI models/tasks
PVF is scalable and applicable across a wide range of AI models, tasks, and hardware fault models.
Provides insights for guiding AI system design
PVF can provide valuable insights for AI system designers, guiding them in making informed decisions about balancing fault protection with performance and efficiency. For example, engineers might leverage PVF to help map higher vulnerable parameters to better-protected hardware blocks and explore tradeoffs on latency, power, and reliability by enabling a surgical approach to fault tolerance at selective locations instead of a catch-all/none approach.
Can be used as a standard metric for AI vulnerability/resilience evaluation
PVF has the potential to unify and standardize such practices, making it easier to compare the reliability of different AI systems/parameters and fostering open collaboration and progress in the industry and research community.
How PVF works
Similar to AVF as a statistical concept, PVF needs to be derived through a large number of FI experiments that are statistically meaningful. Figure 2 shows an overall flow to compute PVF through a FI process. We’ve presented a case study on the open-source DLRM inference with more details and example case studies in our paper.
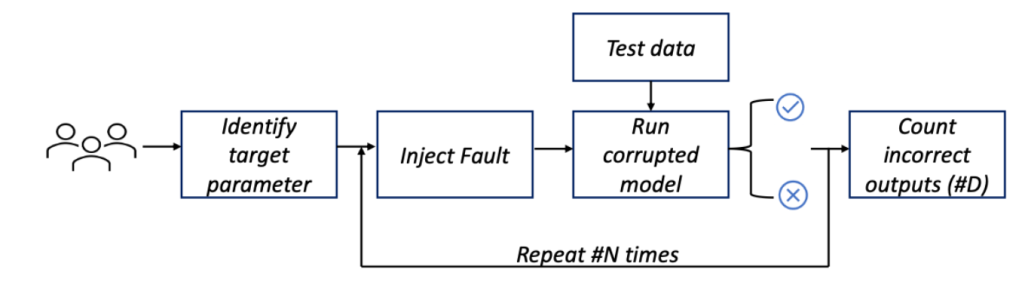
Figure 3 illustrates the PVF of three DLRM parameter components, embedding table, bot-MLP, and top-MLP, under 1, 2, 4, 8, 16, 32, 64, and 128 bit flips during each inference. We observe different vulnerability levels across different parts of DLRM. For example, under a single bit flip, the embedding table has relatively low PVF; this is attributed to embedding tables being highly sparse, and parameter corruptions are only activated when the particular corrupted parameter is activated by the corresponding sparse feature. However, top-MLP can have 0.4% under even a single bit flip. This is significant – for every 1000 inferences, four inferences will be incorrect. This highlights the importance of protecting specific vulnerable parameters for a given model based on the PVF measurement.
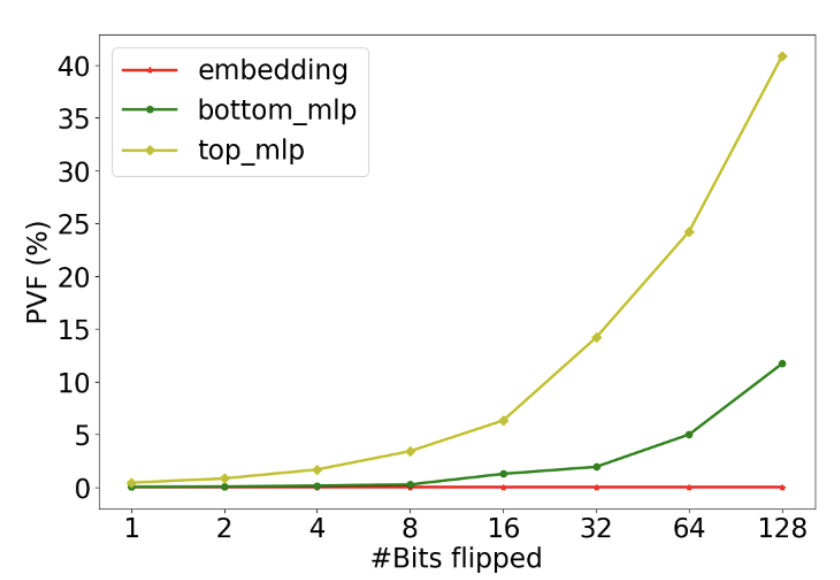
We observe that with 128 bit flips during each inference, for MLP components, PVF has increased to 40% and 10% for top-MLP and bot-MLP components respectively, while observing multiple NaN values. Top-MLP component has higher PVF than bot-MLP. This is attributed to the top-MLP being closer to the final model, and hence has less of a chance to be mitigated by inherent error masking probability of neural layers.
The applicability of PVF
PVF is a versatile metric where the definition of an “incorrect output” (which will vary based on the model/task) can be adapted to suit user requirements. To adapt PVF to various hardware fault models the method to calculate PVF remains consistent as depicted in Figure 2. The only modification required is the manner in which the fault is injected, based on the assumed fault models.
Furthermore, PVF can be extended to the training phase to evaluate the effects of parameter corruptions on the model’s convergence capability. During training, the model’s parameters are iteratively updated to minimize a loss function. A corruption in a parameter could potentially disrupt this learning process, preventing the model from converging to an optimal solution. By applying the PVF concept during training, we could quantify the probability that a corruption in each parameter would result in such a convergence failure.
Dr. DNA and further exploration avenues for PVF
The logical progression after understanding AI vulnerability to SDCs is to identify and lessen their impact on AI systems. To initiate this, we’ve introduced Dr. DNA, a method designed to detect and mitigate SDCs that occur during deep learning model inference. Specifically, we formulate and extract a set of unique SDC signatures from the distribution of neuron activations (DNA), based on which we propose early-stage detection and mitigation of SDCs during DNN inference.
We perform an extensive evaluation across 10 representative DNN models used in three common tasks (vision, GenAI, and segmentation) including ResNet, Vision Transformer, EfficientNet, YOLO, etc., under four different error models. Results show that Dr. DNA achieves a 100% SDC detection rate for most cases, a 95% detection rate on average and a >90% detection rate across all cases, representing 20-70% improvement over baselines. Dr. DNA can also mitigate the impact of SDCs by effectively recovering DNN model performance with <1% memory overhead and <2.5% latency overhead.
Read the research papers
Dr. DNA: Combating Silent Data Corruptions in Deep Learning using Distribution of Neuron Activations








