
AI plays a fundamental role in creating valuable connections between people and advertisers within Meta’s family of apps. Meta’s ad recommendation engine, powered by deep learning recommendation models (DLRMs), has been instrumental in delivering personalized ads to people. Key to this success was incorporating thousands of human-engineered signals or features in the DLRM-based recommendation system.
Despite training on vast amounts of data, there are limitations to current DLRM-based ads recommendations with manual feature engineering due to the inability of DLRMs to leverage sequential information from people’s experience data. To better capture the experiential behavior, the ads recommendation models have undergone foundational transformations along two dimensions:
- Event-based learning: learning representations directly from a person’s engagement and conversion events rather than traditional human-engineered features.
- Learning from sequences: developing new sequence learning architectures to replace traditional DLRM neural network architectures.
By incorporating these advancements from the fields of natural language understanding and computer vision, Meta’s next-generation ads recommendation engine addresses the limitations of traditional DLRMs, resulting in more relevant ads for people, higher value for advertisers, and better infrastructure efficiency.
These innovations have enabled our ads system to develop a deeper understanding of people’s behavior before and after converting on an ad, enabling us to infer the next set of relevant ads. Since launch, the new ads recommendation system has improved ads prediction accuracy – leading to higher value for advertisers and 2-4% more conversions on select segments.
The limits of DLRMs for ads recommendations
Meta’s DLRMs for personalized ads rely on a wide array of signals to understand people’s purchase intent and preferences. DLRMs have revolutionized learning from sparse features, which capture a person’s interactions on entities like Facebook pages, which have massive cardinalities often in the billions. The success of DLRMs is founded on their ability to learn generalizable, high dimensional representations, i.e., embeddings from sparse features.
To leverage tens of thousands of such features, various strategies are employed to combine features, transform intermediate representations, and compose the final outputs. Further, sparse features are built by aggregating attributes across a person’s actions over various time windows with different data sources and aggregation schemes.
Some examples of legacy sparse features thus engineered would be:
- Ads that a person clicked in the last N days → [Ad-id1, Ad-id2, Ad-id3, …, Ad-idN]
- Facebook pages a person visited in the past M days with a score of how many visits on each page → [(Page-id1, 45), (Page-id2, 30), (Page-id3, 8), …]
Human-engineered sparse features, as described above, have been a cornerstone for personalized recommendations with DLRMs for several years. But this approach has limitations:
- Loss of sequential information: Sequence information, i.e., the order of a person’s events, can provide valuable insights for better ads recommendations relevant to a person’s behavior. Sparse feature aggregations lose the sequential information in a person’s journeys.
- Loss of granular information: Fine-grained information like collocation of attributes in the same event is lost as features are aggregated across events.
- Reliance on human intuition: Human intuition is unlikely to recognize non-intuitive, complex interactions and patterns from vast quantities of data.
- Redundant feature space: Multiple variants of features get created with different aggregation schemes. Though providing incremental value, overlapping aggregations increase compute and storage costs and make feature management cumbersome.
People’s interests evolve over time with continuously evolving and dynamic intents. Such complexities are hard to model with handcrafted features. Modeling these inter-dynamics helps achieve a deeper understanding of a person’s behavior over time for better ad recommendations.
A paradigm shift with learning from sequences for recommendation systems
Meta’s new system for ads recommendations uses sequence learning at its core. This necessitated a complete redesign of the ads recommendations system across data storage, feature input formats, and model architecture. The redesign required building a new people-centric infrastructure, training and serving optimization for state-of-the-art sequence learning architectures, and model/system codesign for efficient scaling.
Event-based features
Event-based features (EBFs) are the building blocks for the new sequence learning models. EBFs – an upgrade to traditional features – standardizes heterogeneous inputs to sequence learning models along three dimensions:
- Event streams: the data stream for an EBF, e.g. the sequence of recent ads people engaged with or the sequence of pages people liked.
- Sequence length defines how many recent events are incorporated from each stream and is determined by the importance of each stream.
- Event Information: captures semantic and contextual information about each event in the stream such as the ad category a person engaged with and the timestamp of the event.
Each EBF is a single coherent object that captures all key information about an event. EBFs allow us to incorporate rich information and scale inputs systematically. EBF sequences replace legacy sparse features as the main inputs to the recommendation models. When combined with event models described below, EBFs have ushered in a departure from human-engineered feature aggregations.
Sequence modeling with EBFs
An event model synthesizes event embeddings from event attributes. It learns embeddings for each attribute and uses linear compression to summarize them into a single event attributed-based embedding. Events are timestamp encoded to capture their recency and temporal order. The event model combines timestamp encoding with the synthesized event attribute-based embedding to produce the final event-level representation – thus translating an EBF sequence into an event embedding sequence.
This is akin to how language models use embeddings to represent words. The difference is that EBFs have a vocabulary that is many orders of magnitude larger than a natural language because they come from heterogeneous event streams and encompass millions of entities.
The event embeddings from the event model are then fed into the sequence model at the center of the next-generation ads recommendation system. The event sequence model is a person level event summarization model that consumes sequential event embeddings. It utilizes state-of-the-art attention mechanisms to synthesize the event embeddings to a predefined number of embeddings that are keyed by the ad to be ranked. With techniques like multi-headed attention pooling, the complexity of the self-attention module is reduced from O(N*N) to O(M*N) . M is a tunable parameter and N is the maximum event sequence length.
The following figure illustrates the differences between DLRMs with a human-engineered features paradigm (left) and the sequence modeling paradigm with EBFs (right) from a person’s event flow perspective.
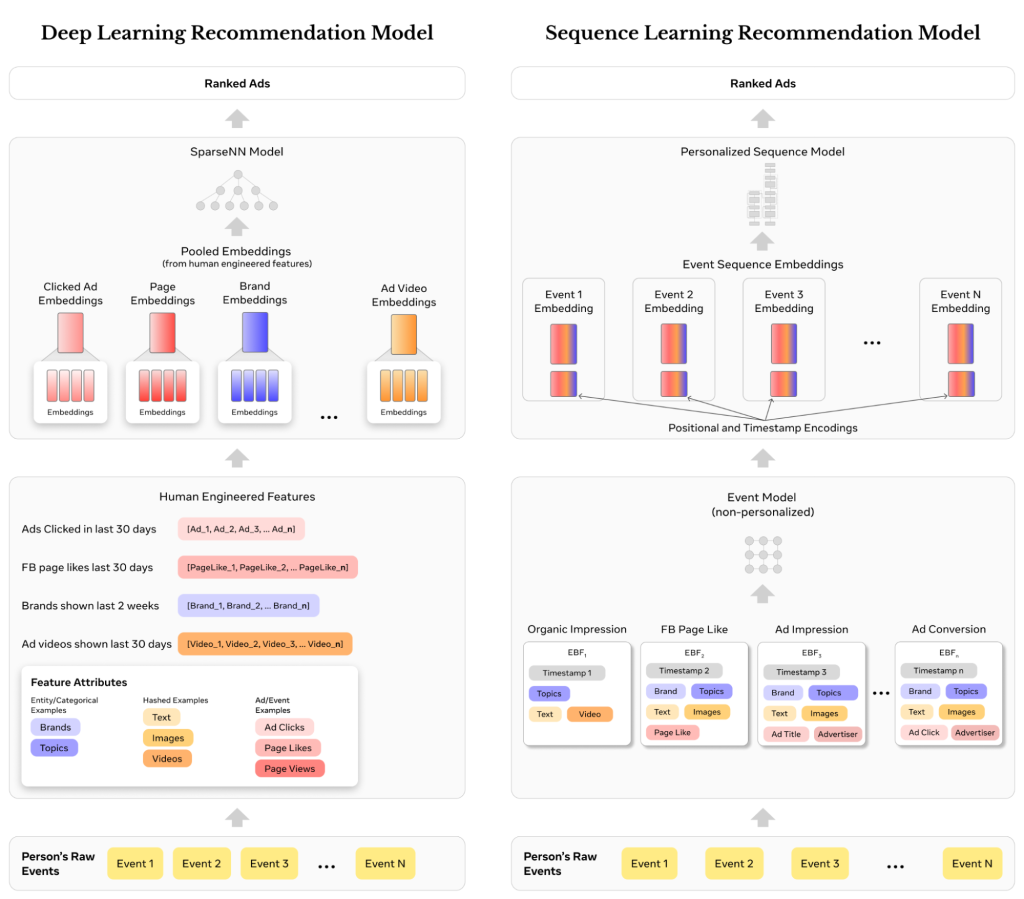
Scaling the new sequence learning paradigm
Following the redesign to shift from sparse feature learning to event-based sequence learning, the next focus was scaling across two domains — scaling the sequence learning architecture and scaling event sequences to be longer and richer.
Scaling sequence learning architectures
A custom transformer architecture that incorporates complex feature encoding schemes to fully model sequential information was developed to enable faster exploration and adoption of state-of-the-art techniques for recommendation systems. The main challenge with this architectural approach is achieving the performance and efficiency requirements for production. A request to Meta’s ads recommendation system has to rank thousands of ads in a few hundred milliseconds.
To scale representation learning for higher fidelity, the existing sum pooling approach was replaced with a new architecture that learned feature interactions from unpooled embeddings. Whereas the prior system based on aggregated features was highly optimized for fixed length embeddings that are pooled by simple methods like averaging, sequence learning introduces new challenges because different people have different event lengths. Longer variable length event sequences, represented by jagged embedding tensors and unpooled embeddings, result in larger compute and communication costs with higher variance.
This challenge of growing costs is addressed by adopting hardware codesign innovations for supporting jagged tensors, namely:
- Native PyTorch capabilities to support Jagged tensors.
- Kernel-level optimization for processing Jagged tensors on GPUs.
- A Jagged Flash Attention module to support Flash Attention on Jagged tensors.
Scaling with longer, richer sequences
Meta’s next-generation recommendation system’s ability to learn directly from event sequences to better understand people’s preferences is further enhanced with longer sequences and richer event attributes.
Sequence scaling entailed:
- Scaling with longer sequences: Increasing sequence lengths gives deeper insights and context about a person’s interests. Techniques like multi-precision quantization and value-based sampling techniques are used to efficiently scale sequence length.
- Scaling with richer semantics: EBFs enable us to capture richer semantic signals about each event e.g. through multimodal content embeddings. Customized vector quantization techniques are used to efficiently encode the embedding attributes of each event. This yields a more informative representation of the final event embedding.
The impact and future of sequence learning
The event sequence learning paradigm has been widely adopted across Meta’s ads systems, resulting in gains in ad relevance and performance, more efficient infrastructure, and accelerated research velocity. Coupled with our focus on advanced transformer architectures, event sequence learning has reshaped Meta’s approach to ads recommendation systems.
Going forward, the focus will be on further scaling event sequences by 100X, developing more efficient sequence modeling architectures like linear attention and state space models, key-value (KV) cache optimization, and multimodal enrichment of event sequences.
Acknowledgements
We would like to thank Abha Jain, Boyang Li, Carl Hu, Chen Liang, Dinesh Ramasamy, Doris Wang, Hong Li, Jonathan Herbach, Junjie Yang, Kun Jiang, Ketan Singh, Neeraj Bhatia, Paolo Massimi, Parshva Doshi, Pushkar Tripathi, Rengan Xu, Sandeep Pandey, Santanu Kolay, Yunnan Wu, Yuxi Hu, Zhirong Chen and the entire event sequence learning team involved in the development and productionization of the next-generation sequencing learning based ads recommendation system.








