
At Meta, our internal data tools are the main channel from our data scientists to our production engineers. As such, it’s important for us to empower our scientists and engineers not only to use data to make decisions, but also to do so in a secure and compliant way.
We’ve developed SQL Notebooks, a new tool that combines the power of SQL IDEs and Jupyter Notebooks. It allows SQL-based analytics to be done in a more scalable and secure way than traditional notebooks while still providing features from notebooks and basic SQL editing, such as multiple interdependent cells and Python post-processing.
In the year since its introduction, SQL Notebooks has already been adopted internally by the majority of data scientists and data engineers at Meta. Here’s how we combined two ubiquitous tools to create something greater than the sum of its parts.
The advantages of SQL
There are many ways people access data. It can be via an UI like Scuba, a domain-specific language (DSL) like our time-series database, or a programmatic API like Spark’s Scala. The primary way for accessing analytics data, however, is good old SQL. This includes most queries to our main analytics databases: Presto, Spark, and MySQL databases.
We have had internal tools to query data from distributed databases via SQL using a web interface since the early days. The first version, called HiPal (Hive + Pal), queried data from the Hive database and went on to inspire the open source tool Airpal. HiPal was later replaced by a more general tool, Daiquery, which can query any SQL-based data store, including Presto, Spark, MySQL, and Oracle, and provided out-of-the-box visualizations.
Daiquery is the go-to tool for many people who interact regularly with SQL, and is used by 90 percent of data scientists and engineers at Meta.
The power and limitations of notebooks
Jupyter Notebook has been a revolutionary tool for data scientists. It enables rich visualizations and in-step documentation by supporting multiple cells and inline markdown. At Meta, we’ve integrated notebooks with our ecosystem through a project called Bento.
However, while notebooks are very powerful, there are a few limitations:
- Scalability. Because the process runs locally, it is bounded in memory and CPU by a single machine, which prevents processing big data, for example.
- Reporting and sharing. Since a notebook is associated with a single machine, sharing any snapshot results with others requires saving it with the whole notebook.
There are two main drawbacks with this approach:
-
- Security: The underlying data might have ACL checks (e.g., at the table level). This is very hard to enforce for the snapshots since it would require executing the code and could lead to data leaks if the notebook owner is not very diligent with access control.
- Staleness: Because this is a snapshot of the data, it will not update unless someone runs the notebook regularly, which could lead to misleading results or require regular manual intervention from the notebook author.
Enter SQL Notebooks
SQL Notebooks combines the strengths of both notebooks and SQL editors in one. Here are some features that make SQL Notebooks powerful:
Modular SQL
We commonly receive feedback that SQL can get very complex and hard to maintain. Databases like Presto support common table expressions (CTEs), which helps tremendously with code organization. However, not everyone is familiar with CTEs, and sometimes it is hard to enforce good practices in making the code readable.
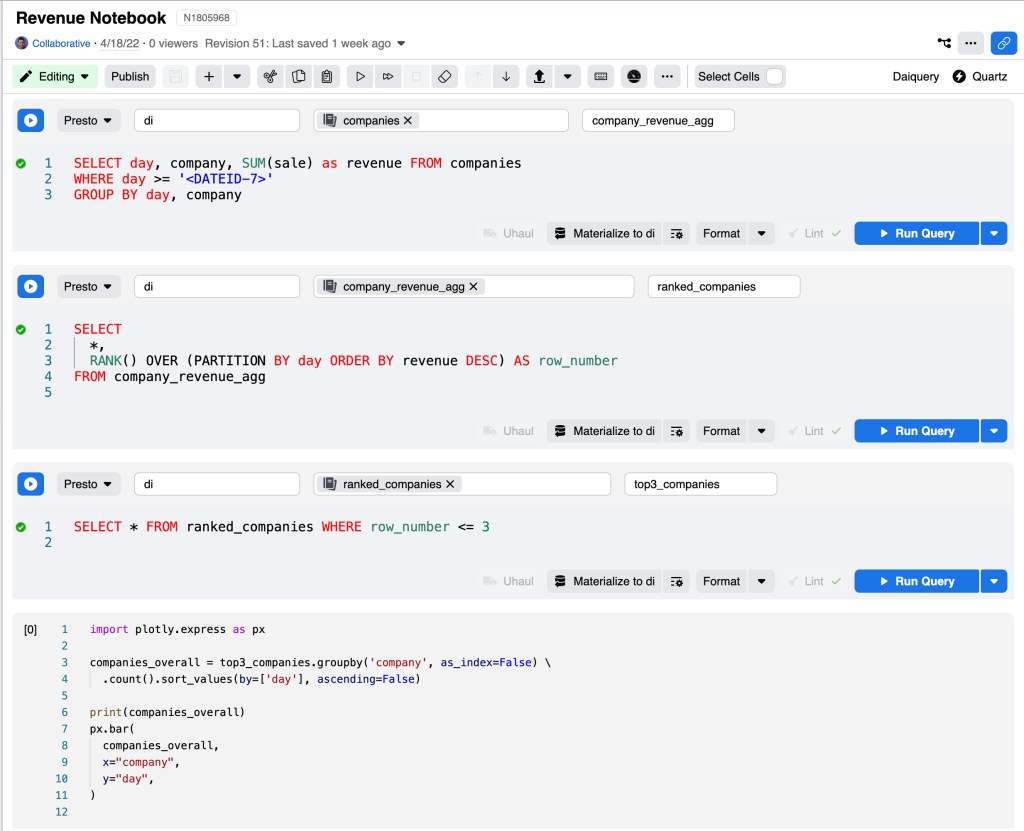
To better handle the perhaps natural growth of a query, we extended our SQL tool, Daiquery, to support multiple cells, much like a notebook. Each cell can have a name and reference other cells by their names as if they were tables.
For example, suppose we want to find the top three companies by revenue on each day in the past week:
In the first cell, we aggregate the data by company and day:
company_revenue_agg:
SELECT day, company, SUM(sale) as revenue FROM companies
WHERE day >= '<DATEID-7>'
GROUP BY day, company

In the second cell, we can use a window function to add a rank to each company within each day:
ranked_companies:
SELECT
*,
RANK() OVER (PARTITION BY ds ORDER BY hits DESC) AS row_number
FROM company_revenue_agg

Finally, on the third cell, we select only the top three ranks:
top3_companies:
SELECT * FROM ranked_companies WHERE row_number <= 3

Each query is simple on its own and can be run independently to inspect the intermediate results. When running ranked_companies, the query being sent to the server is actually:
WITH
company_revenue_agg AS (
SELECT day, company, SUM(sale) as revenue FROM companies
WHERE day >= '<DATEID-7>'
GROUP BY day, company
)
SELECT *,
RANK() OVER (PARTITION BY day ORDER BY revenue DESC) AS row_number
FROM company_revenue_agg
And when running the third cell, top3_companies, the underlying query becomes:
WITH
company_revenue_agg AS (
SELECT day, company, SUM(sale) as revenue FROM companies
WHERE day >= '<DATEID-7>'
GROUP BY day, company
),
ranked_companies AS (
SELECT *,
RANK() OVER (PARTITION BY day ORDER BY revenue DESC) AS row_number
FROM company_revenue_agg
)
SELECT * FROM ranked_companies WHERE row_number <= 3
Someone unaware of CTEs might end up composing this query as a nested query, which would be much more convoluted and harder to understand.
It is worth noting that neither the second nor the third cell requires the data from previous cells. Their SQL gets transformed into a self-contained cell that the distributed back end can understand. This avoids the scalability limitation we discussed above for notebooks.
The front end also appends a LIMIT 1000 statement to the SQL by default when printing/visualizing the results, so if the actual result of company_revenue_agg is longer, we would only see the top 1,000 rows. This limit does not apply when ranked_companies or top3_companies reference it. It is only for the output of the cell an output is requested from.
Python, visualizations, and markdown
In addition to supporting modular SQL, SQL Notebooks supports UI-based visualization. Similar to Vega, it is very convenient for most common visualization needs. It also supports markdown cells for inline documentation.
SQL Notebooks also supports sandboxed Python code. This feature can be used for the last-mile small data manipulation, which is difficult to express in SQL but is a breeze to do using Pandas and can be used to leverage custom visualization libraries, such as Plotly.
Continuing our previous SQL example, if we want to display a bar chart for the data obtained above, we can just run this Python cell:
import plotly.express as px
px.bar(
top3_companies,
x="day",
color="company",
y="hits",
barmode='group'
)
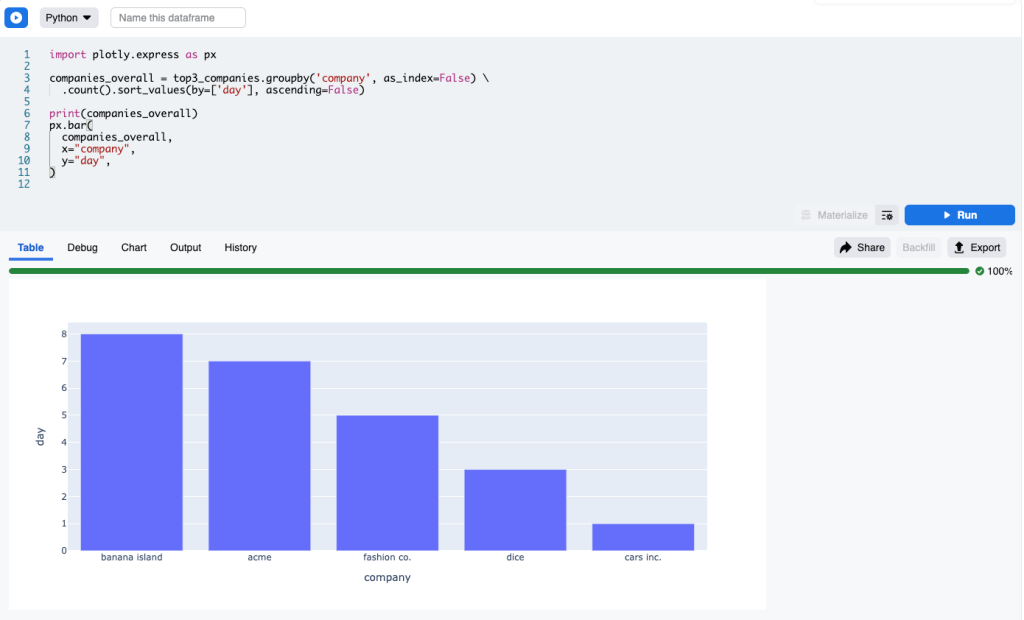
top3_companies is detected as an input to this snippet. The cell top3_companies is thus run beforehand, and its output is then made available as a Pandas dataframe.
Note that fetching data in Python or doing any operation that requires authentication is not allowed. To get data, the Python cell needs to depend on an upstream SQL cell. This is crucial for addressing security, as we will see next.
Sharing outputs safely
Because the SQL syntax is more constrained, it is feasible to statically determine whether a given user can execute a given query. This is virtually impossible to do with dynamic languages like Python.
Therefore, we can save the output of the SQL queries but use them only if the user could have run the SQL in the first place. This means we always rely on the table/column ACLs as the source of truth, and accidental data leakage cannot happen.
We can apply the same mechanism for the Python cells because we are not querying data in Python: We just need to check whether all the input SQLs the Python cell depends on can be run by the user. If so, it is safe to use the cached output for the Python execution.
Sharing fresh data
Because we have safe ways to execute queries and perform access control on their snapshots, we can avoid data staleness by having scheduled asynchronous jobs that update the snapshots.
SQL Editing
SQL Notebooks also brings the best of the Daiquery editor experience: auto-complete, metadata pane for tables (e.g., column names, types, and sample rows), SQL formatting, and the ability to build dashboards from cells.
What’s next for SQL Notebooks
It must be noted that while SQL Notebooks helps address some common issues with Python notebooks, it is not a comprehensive solution for everything. It still requires expressing the data fetching with SQL, and the sandboxed Python is restrictive. Bento/Jupyter notebooks remain better suited for advanced use cases like running machine learning jobs and interacting with back-end services via their Python APIs quickly.
As we announced this tool internally, it was noted how similar SQL Notebooks looks to Bento/Jupyter notebooks. As such, we have been collaborating with the Bento team to combine the tools into one so that users can make trade-offs within the tool instead of having to choose and be locked in. We also plan to deprecate the old Daiquery tool, and the new combined notebooks will be the ultimate unified way to access analytics data.
Acknowledgments
SQL Notebooks has been inspired by both Bento/Jupyter notebooks and Observable. We also want to thank the Bento and Daiquery teams for all the work they put into productionizing this tool.








