
- Facebook Ordered Queueing Service (FOQS) is a fully managed, distributed priority queueing service used for reliable message delivery among many services.
- FOQS has evolved from a regional deployment into a geo-distributed, global deployment to help ensure that data stored within logical queues is highly available, even through large-scale disaster scenarios.
- Migrating to a global architecture required architectural modifications to support routing and care to complete without interrupting service availability for FOQS customers.
FOQS is the priority queuing service that ensures reliable message delivery among many of Meta’s apps and services. For example, it is the platform for delivering messages that people leave on Facebook to let friends and family know they are safe in situations like an earthquake. Given the important role that FOQS plays, it must be resilient to large-scale disasters such as the complete failure of an entire data center or region, or planned outages when maintenance is being performed on a data center.
Since its inception as a regional installation with one main customer, FOQS has evolved into a global installation. After Hurricane Florence in 2018, we realized that to be truly disaster-ready, we needed to migrate to a global architecture with higher availability such that data in the queue is still globally accessible during disaster events. Along the way, we solved the operational challenges associated with migrating tenants to global installations and completed the migration in 2021 at incredible scale, incurring zero downtime for internal clients.
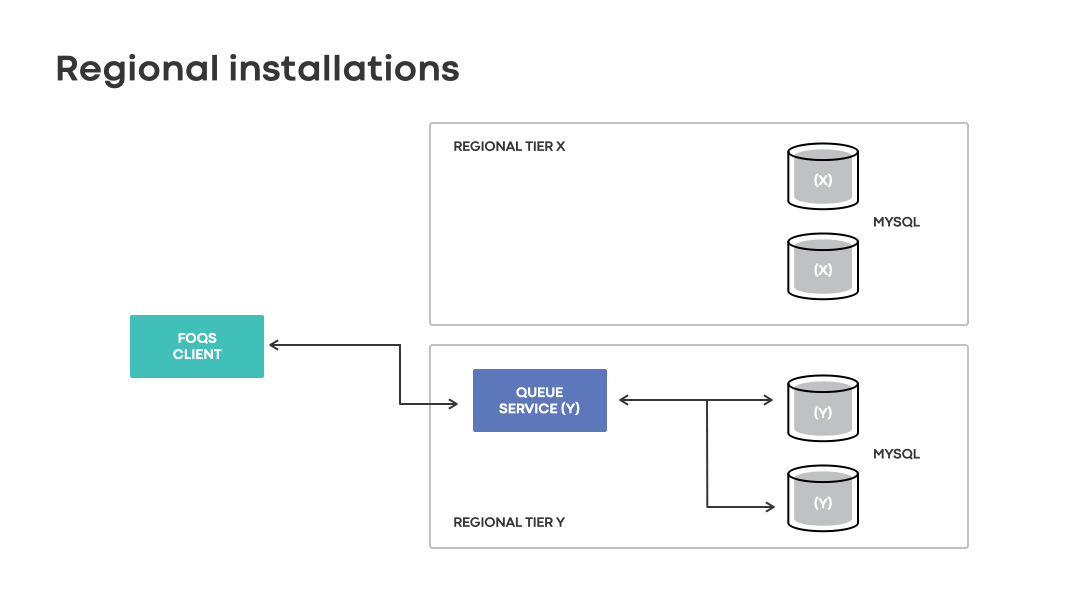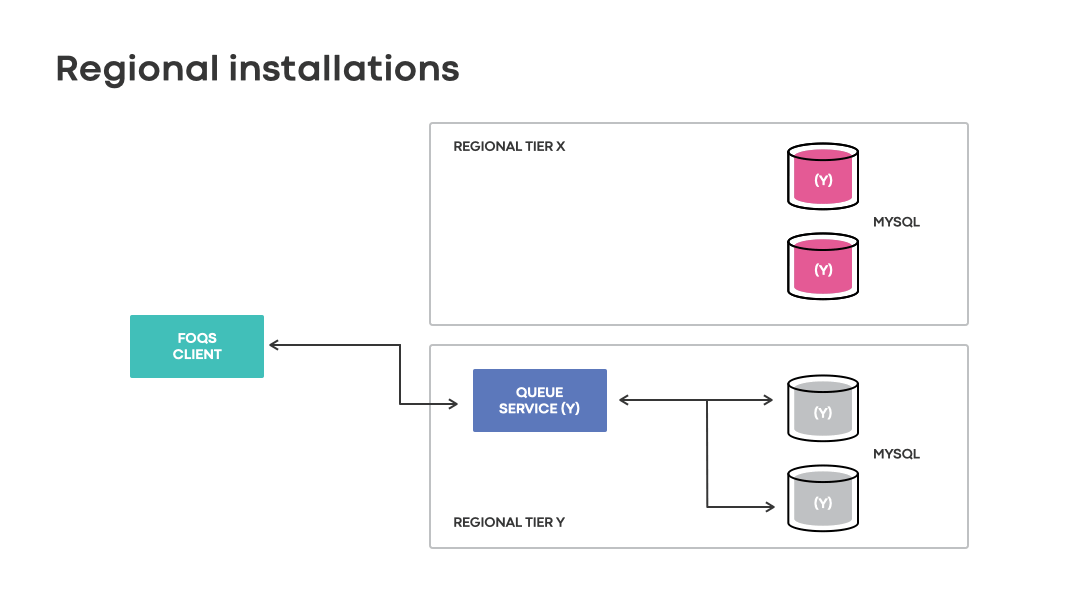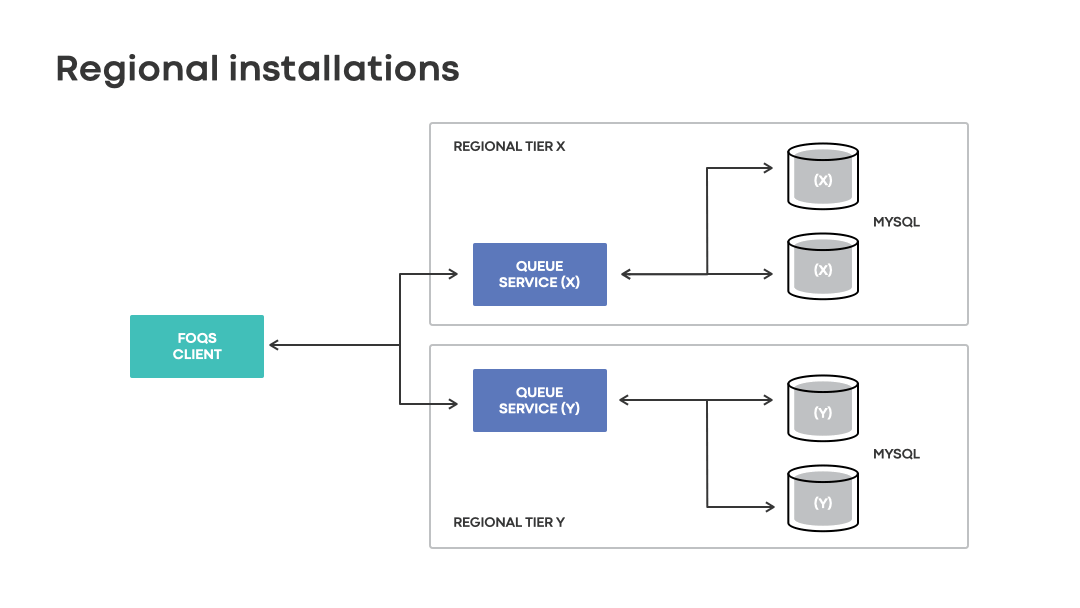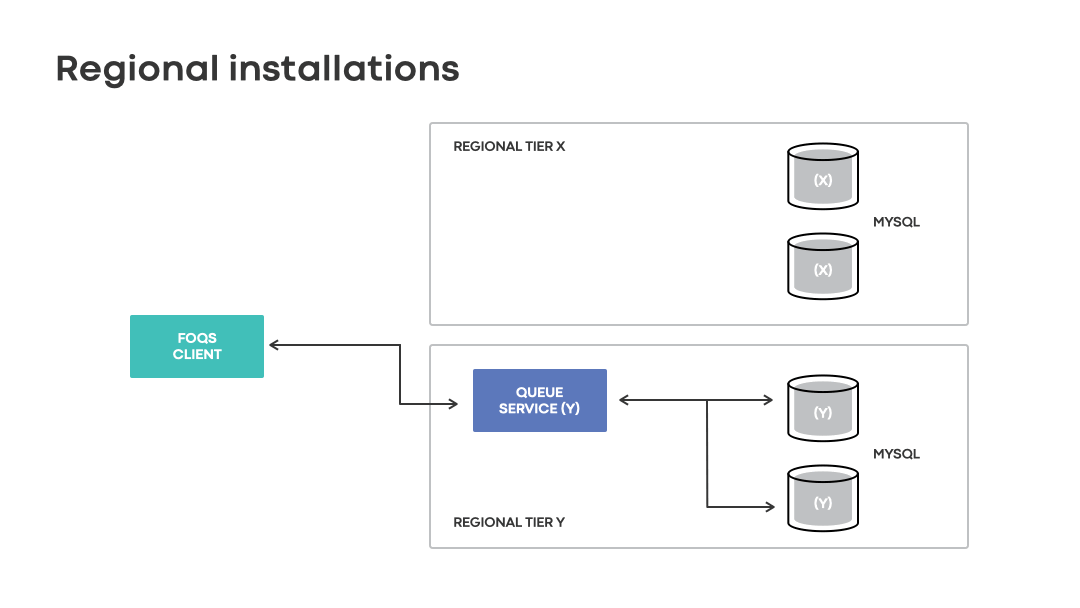
Regional installations
FOQS was originally developed in 2018 out of scaling necessity for Meta’s Asynchronous computing platform (aka Async). With our first iteration, the system was built on top of a three-region, semi-synchronous replicated MySQL topology with queue nodes in region X being completely isolated from queue nodes in region Y.
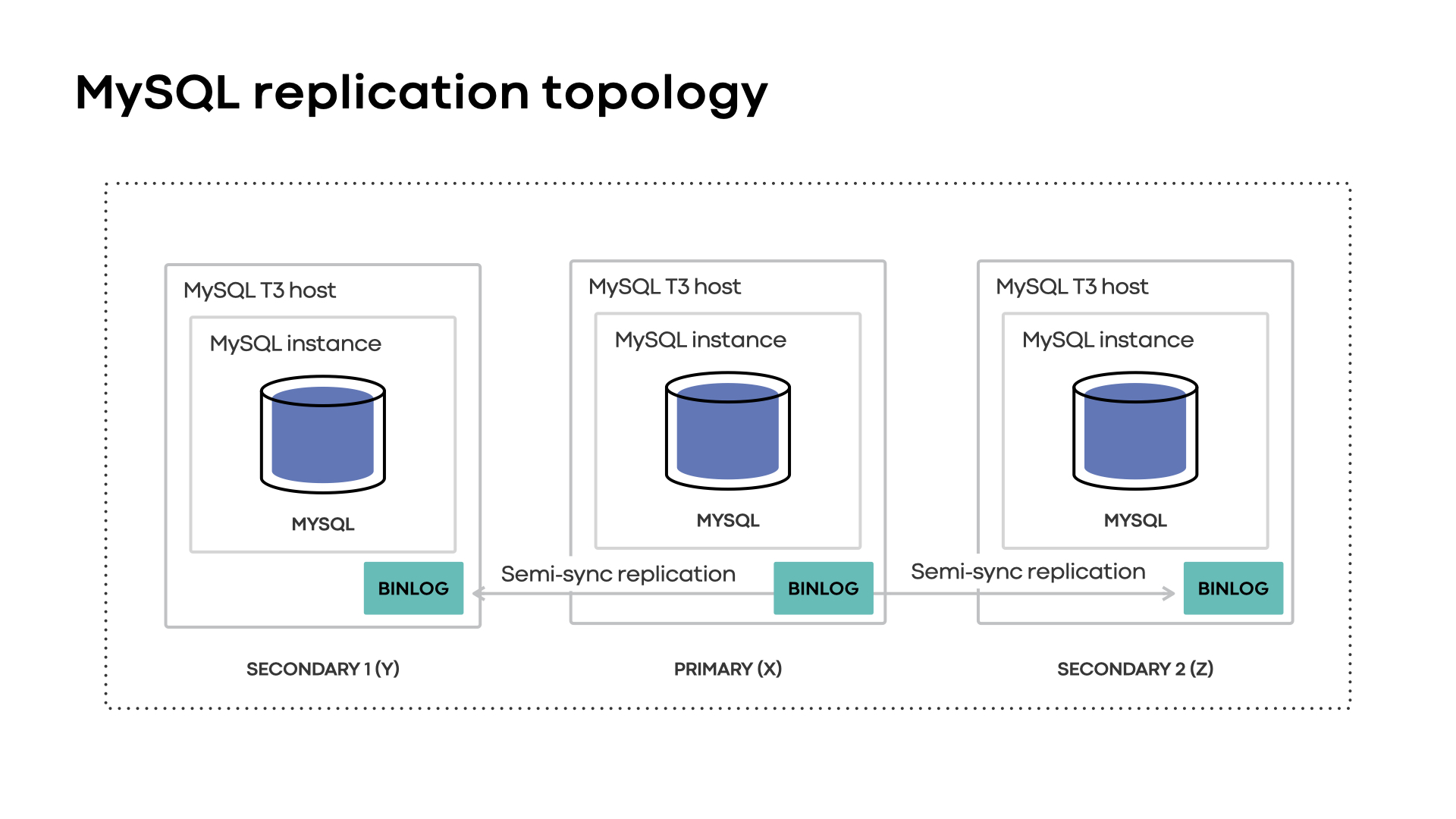
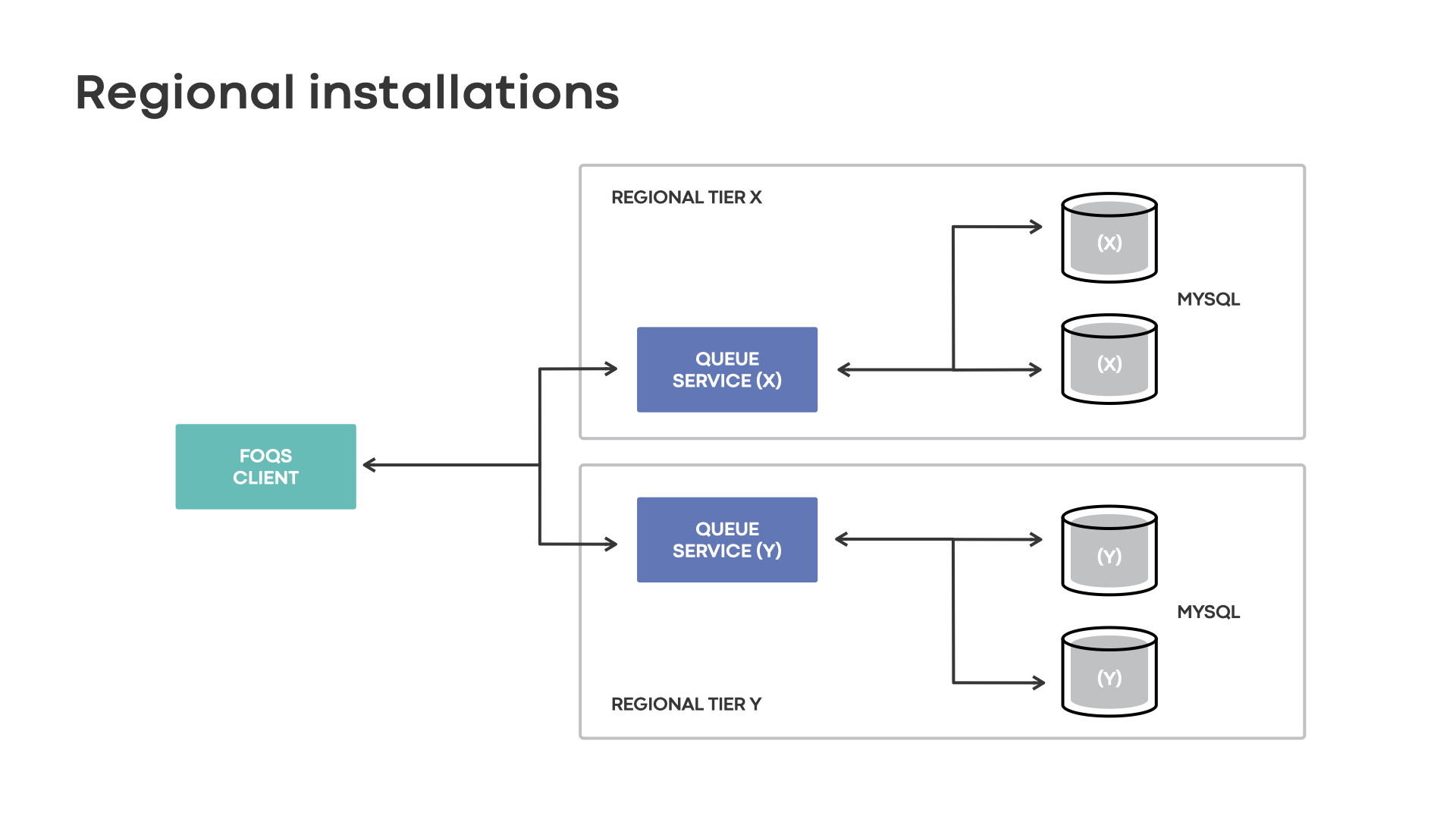
The nodes in each region manage MySQL replicas with the primary typically within the same region. Clients such as Async would use the FOQS client to talk to queue service in the physical region of their choosing, which then stores items in randomly selected MySQL shards for processing.
Benefits of regional installations
Customers of FOQS bear the responsibility of selecting a physical region to serve their requests. Considering that the complexities of regional outages and global load balancing are pushed to clients, FOQS’s regional architecture remains simple. Regional installations are also horizontally scalable, as they allow regions to scale up in isolation. Lastly, they offer low end-to-end queueing delay when producers and consumers are colocated with FOQS.
Challenges of regional installations
During any event leading to the unavailability of a primary replica in region X, MySQL can elect secondary replicas from region Y or Z as the new primary. After failover, the queue service in region X must send queries to the new primary database in region Y or Z where cross-region latencies increase up to hundreds of milliseconds.
In the event of complete network connectivity loss in region X, the limitations of the regional architecture become more glaring:
- Customers have to explicitly balance their traffic away from an impacted region. Regional installations force all of the disaster recovery and load-balancing complexity to clients.
- Pushing load-balancing complexity to customers often results in underutilization of system resources within FOQS. Additionally, it requires buffer capacity in other regions to accommodate shifted traffic.
- Due to an inability for MySQL primaries to be picked up outside of a given regional installation, items stored on replicas in the primary regions are susceptible to being “stuck” until connectivity is restored. Regional installations fail to offer access to data with high availability.
FOQS faced the gamut of challenges during a multiday disaster in late 2018 due to Hurricane Florence. The team was forced to employ manual steps aimed at rebalancing traffic, adding capacity to accommodate shifts and coordinating with customers to prevent substantial impact.
Global installations
Following Hurricane Florence, we quickly realized how unsustainable such actions would be as the teams and systems involved continued to scale. The team introduced global installations to better capitalize on FOQS’s MySQL replication topology and tolerate events that can affect a given region’s availability. Two major factors enabled our system to better tolerate disasters: following MySQL primaries on failovers and introducing an intelligent routing component as a service.
Following the primary
Global installations utilize global application primitives that exist in Shard Manager to support colocating MySQL primaries with a queue node in the corresponding region after failovers. For example, global installations enable FOQS to transition management of a shard that failed over from region X to region Y to a queue node in region Y. The failover and transition of management typically happen within seconds.
Since MySQL primaries are “followed” when they failover, global installations greatly increase the availability of data stored on MySQL shards and avoid two major issues observed with regional installations: stuck queue items and high cross-region latencies. Clients also benefit since no explicit action is required during a disaster, given that MySQL shards are always available via a queue node and accessible behind a single global service ID.
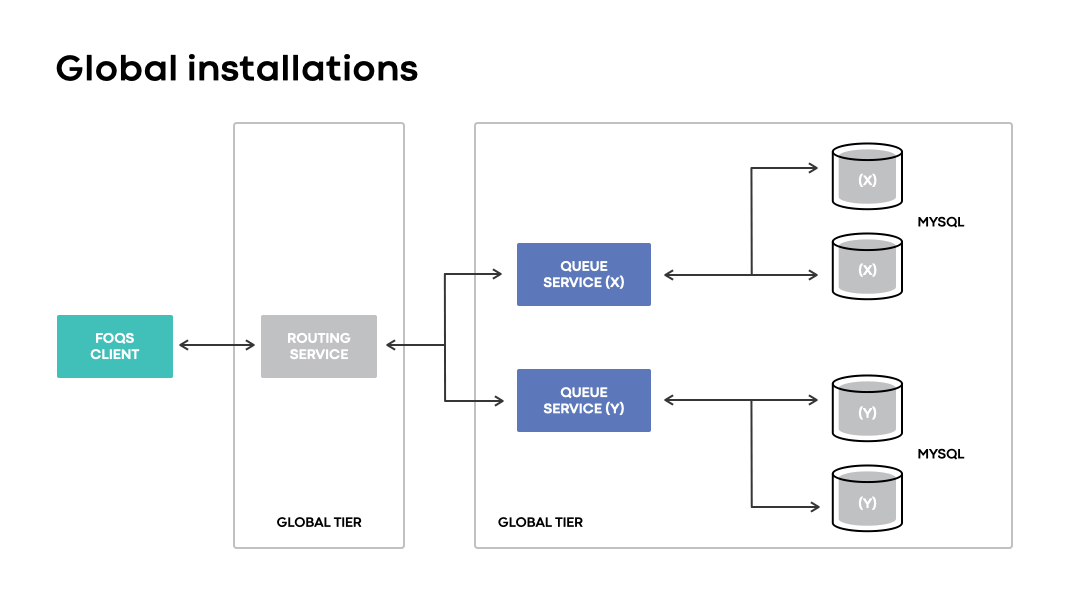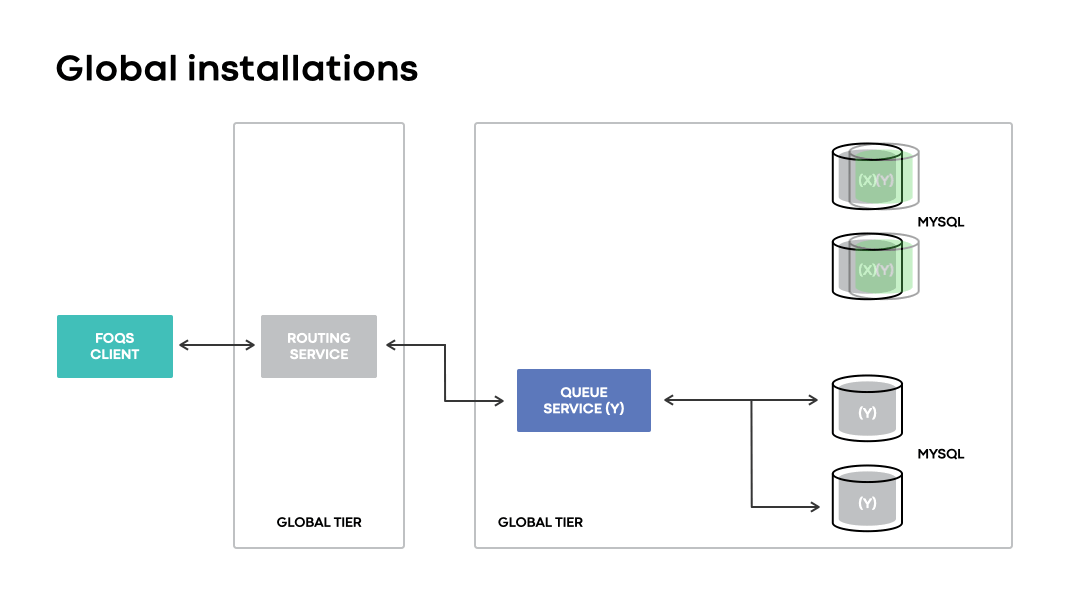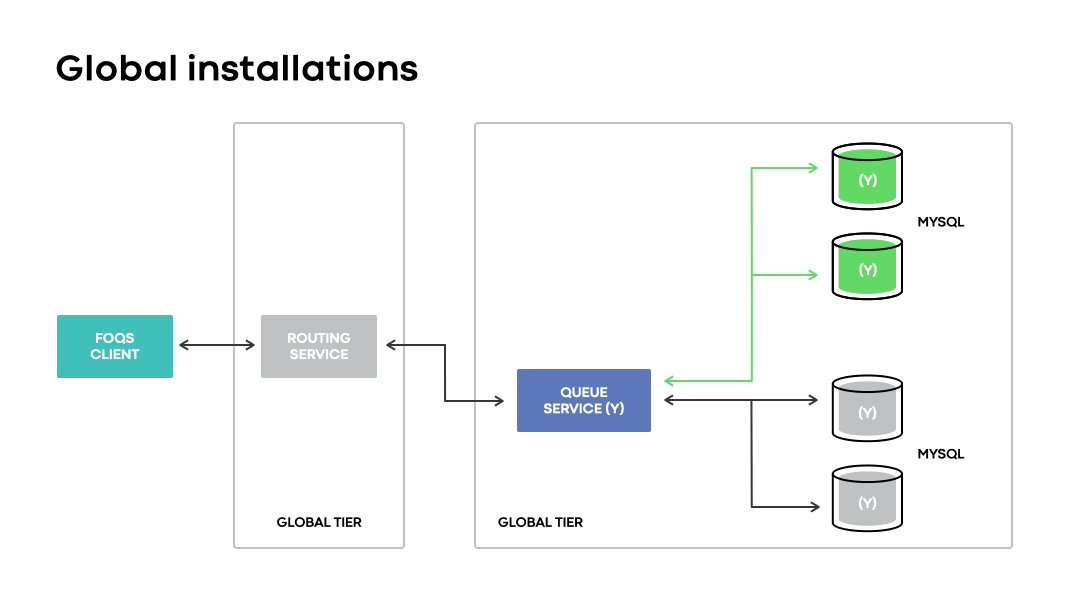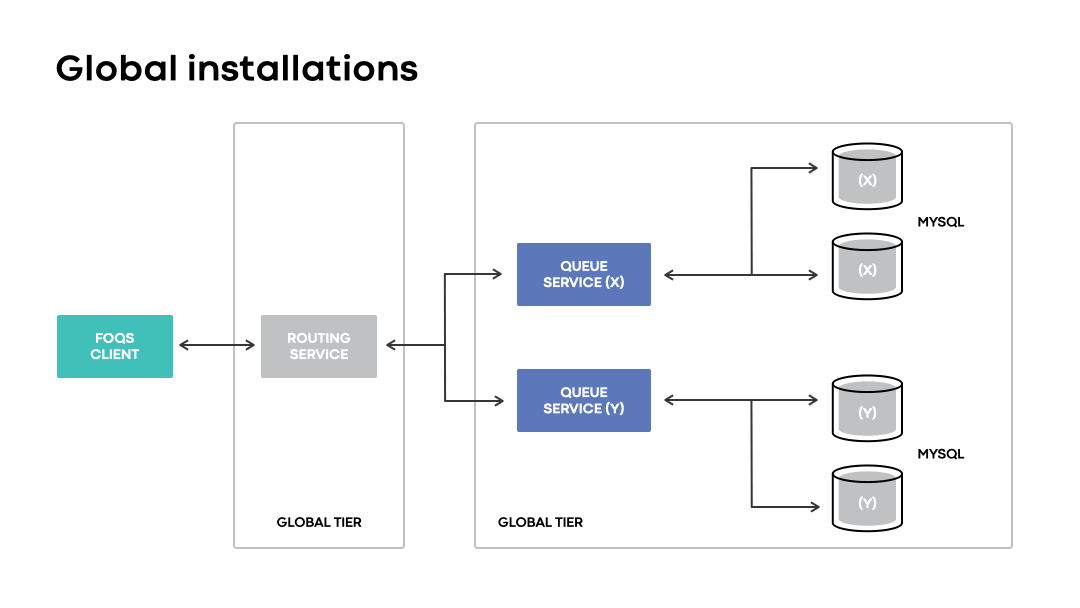
Introduction of routing service
For optimal latencies on global installations, FOQS added the routing service as a proxy between its clients and queue service. The routing service abstracts away all physical routing concerns from clients and enables optimal placement of items across a global queueing layer by exposing logical region preferences for routing.
Enqueue distribution
Enqueue distributor is a component in the routing service that handles optimal data placement with respect to regional preferences. The component maintains in-memory state to map logical region preferences to associated MySQL shards based on proximity. The enqueue API enables clients to specify logical regional preferences to hint where they’d like their items stored.
Upon receiving a request, the enqueue distributor will utilize its in-memory state to build a selection of queue nodes that are eligible to receive a request based on the specified region preference. Items utilizing region preferences are enqueued to their physical counterpart, if possible, or a region managing the associated failed-over MySQL shards. If no region preference is specified, items are typically routed within or near the region in which the request was received.
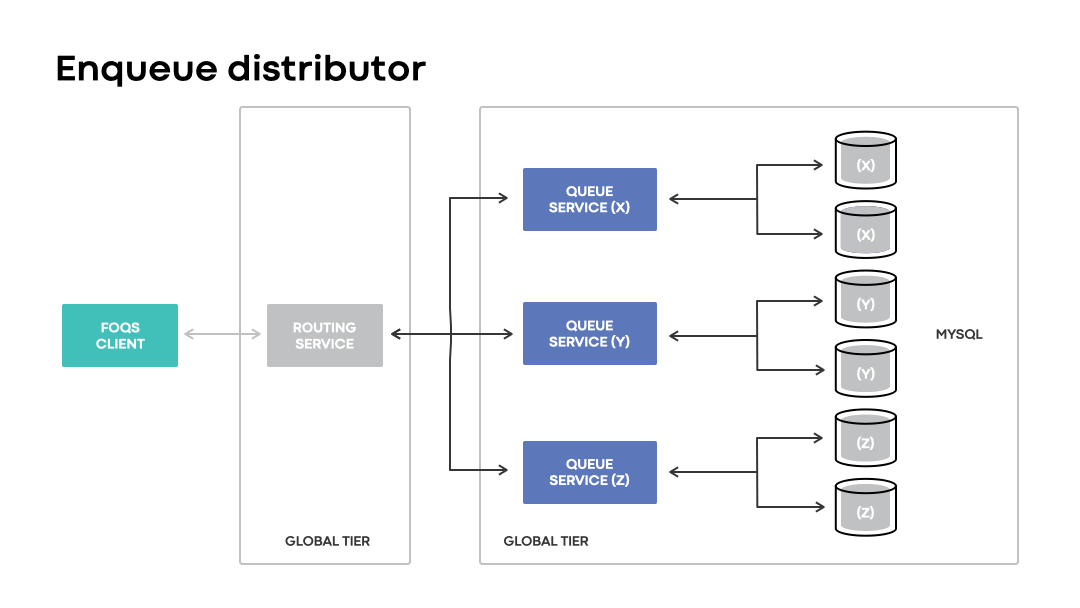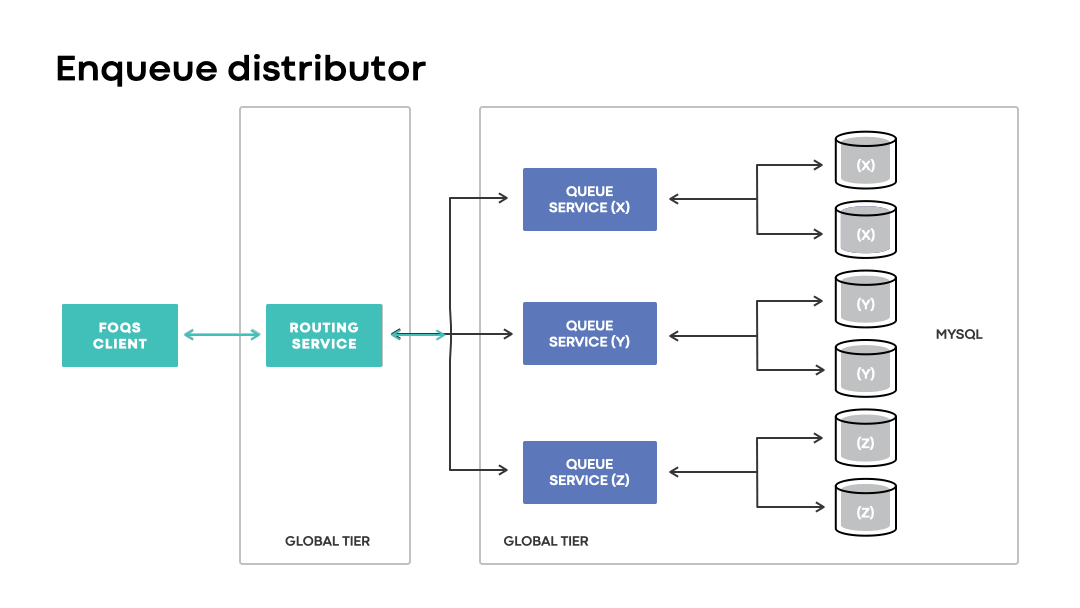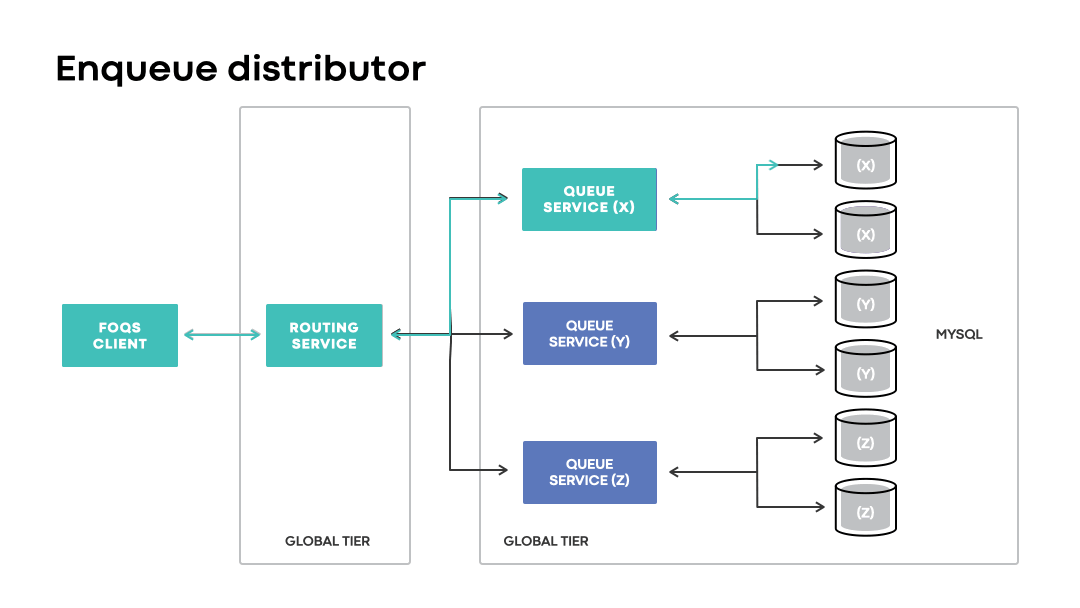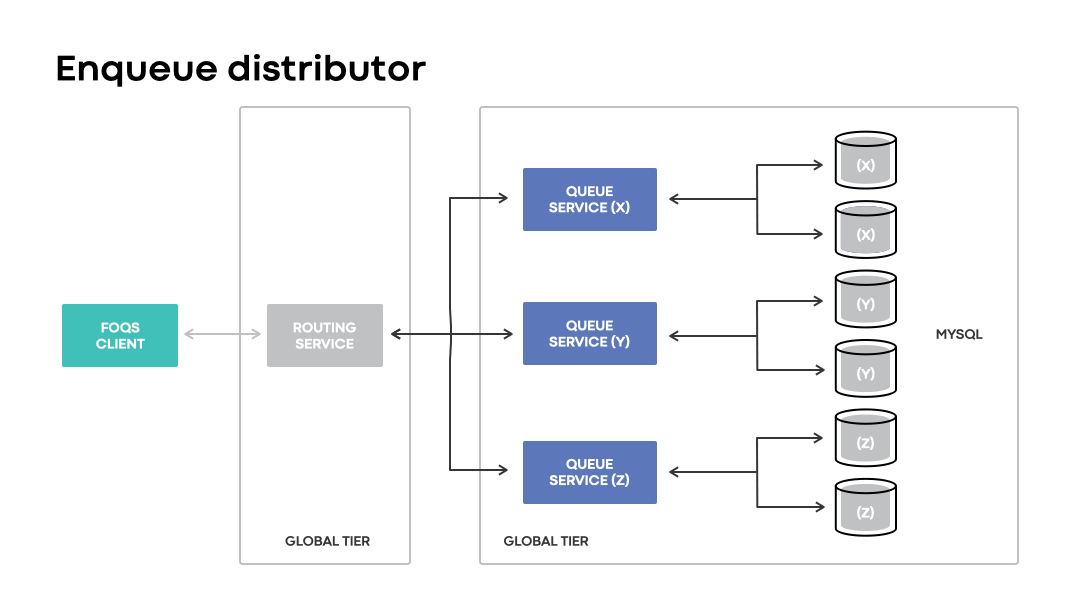
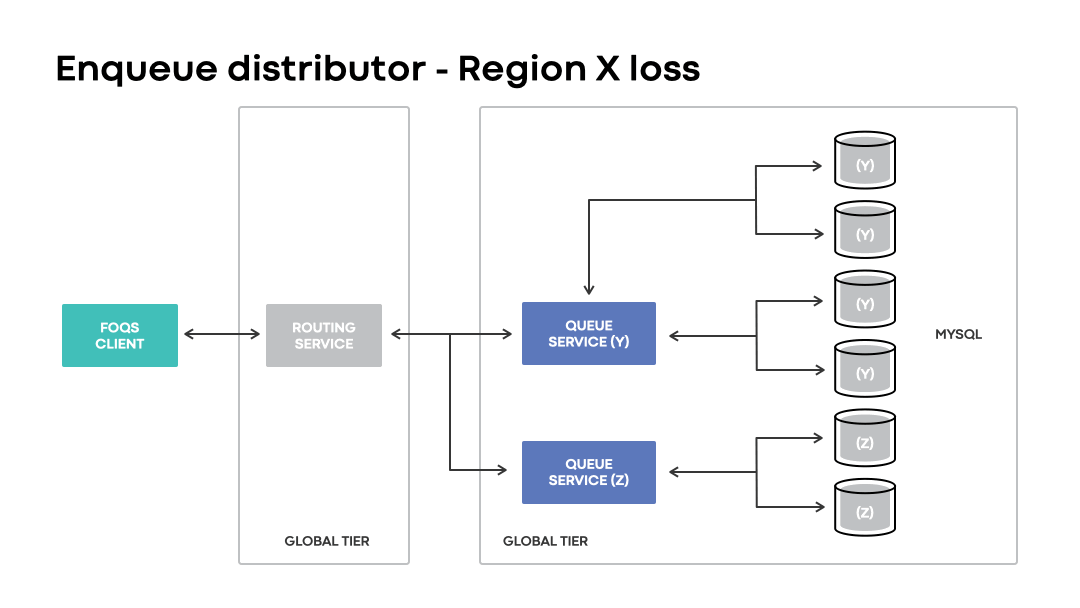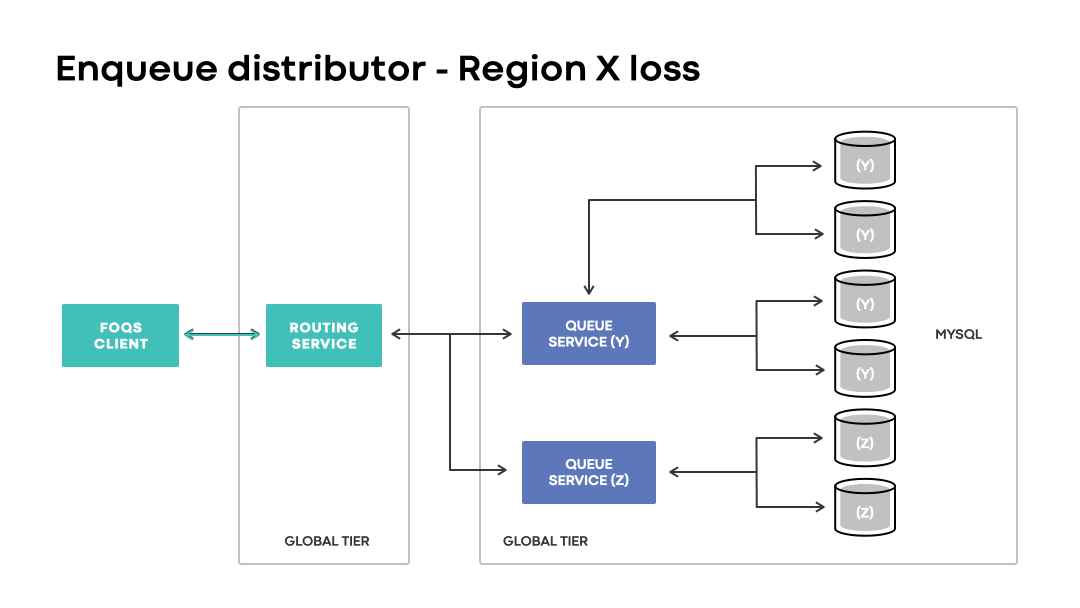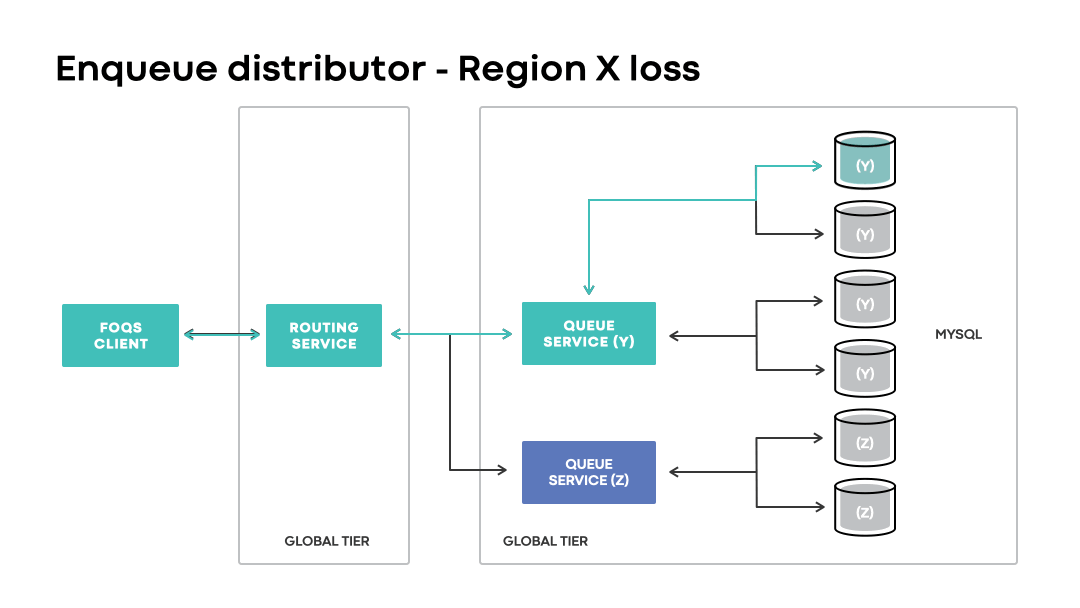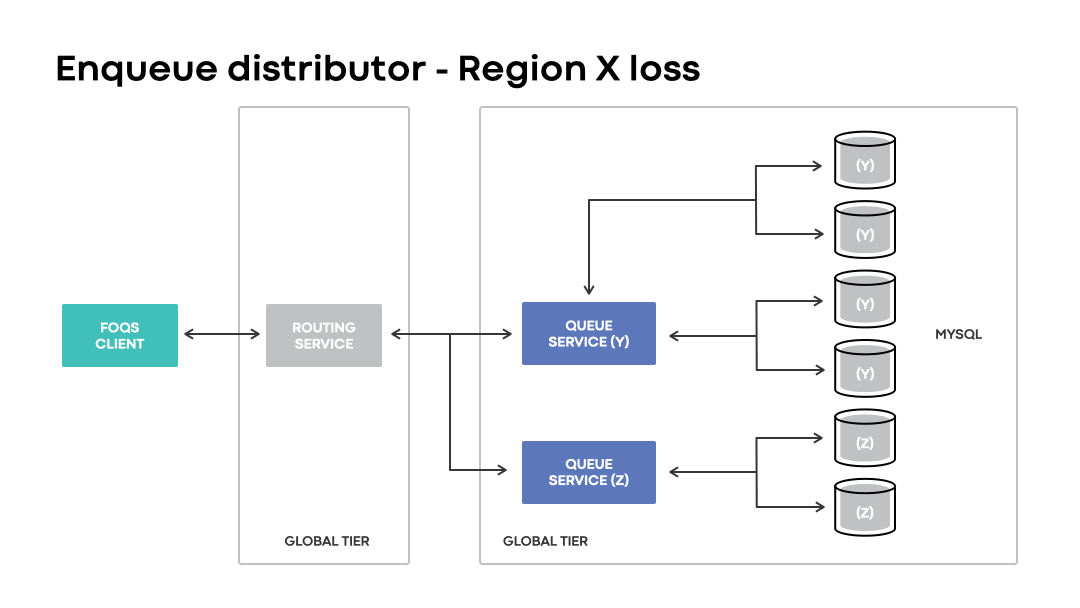
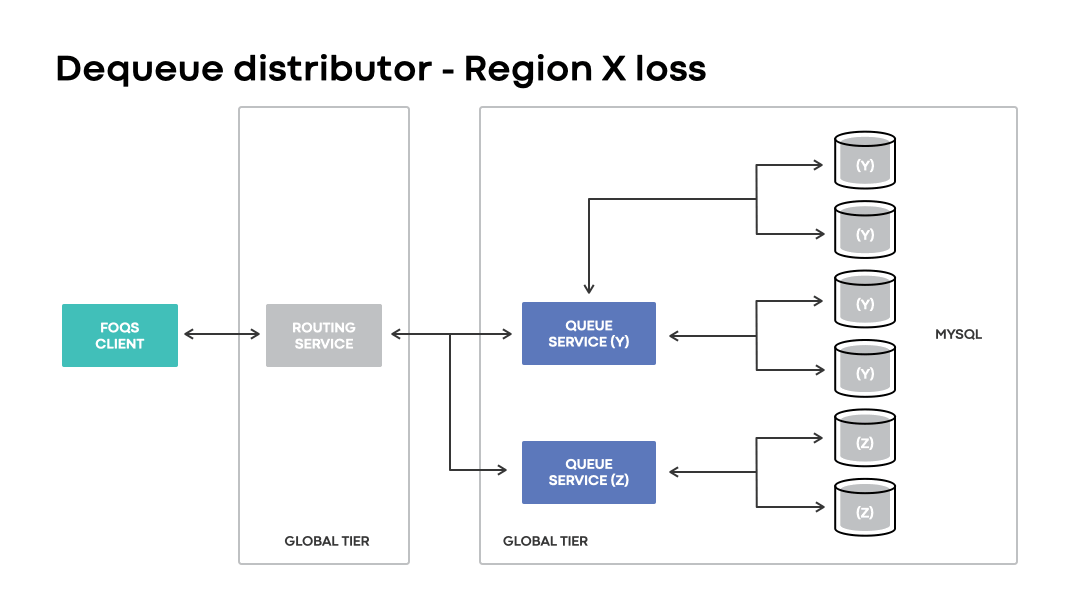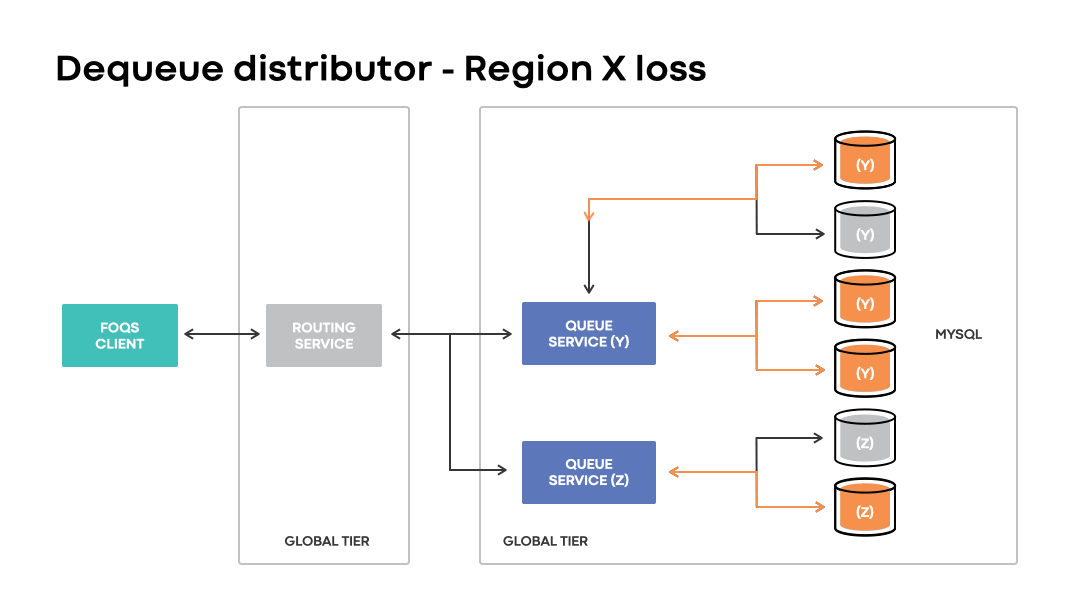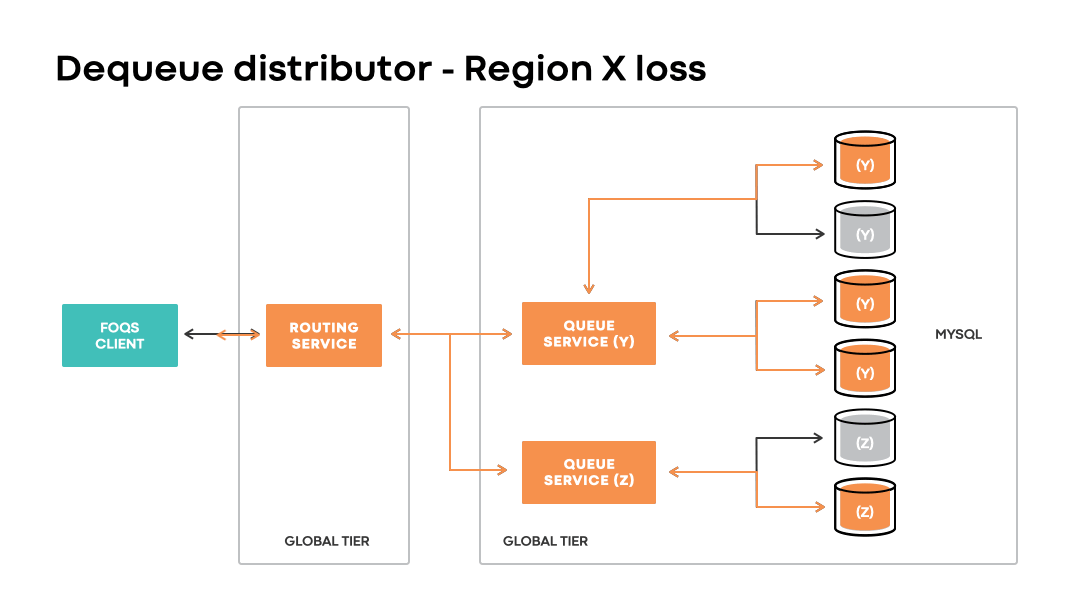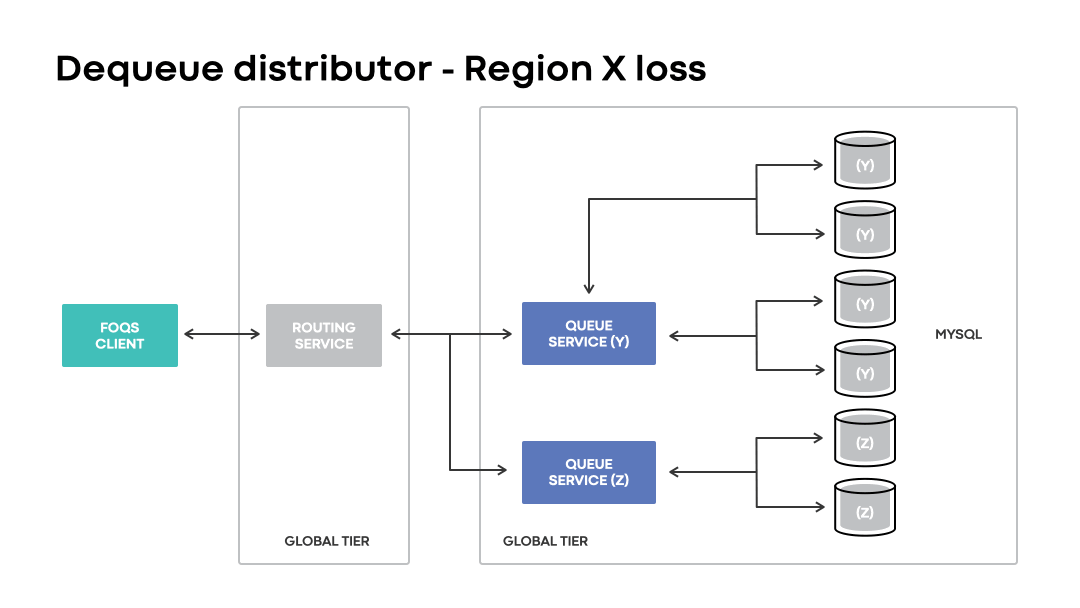
In disaster scenarios, global installations will continue accepting enqueue requests with a logical region preference matching an impacted region. Unlike regional installations, the loss of a region is handled transparently to clients. Instead of a request outright failing due to a physical region being unavailable, global installations route requests to wherever the corresponding MySQL capacity may be.
Dequeue distribution
Given that FOQS does not dictate a fixed placement of enqueued items associated with a logical queue, it requires a way to discover and dequeue “ready” queue items without significant delays. Dequeue distributor is the component that handles item discovery.
At a high level, each routing service node maintains an in-memory cache of queue nodes with items ready to be processed. The cache is represented as a heap that prioritizes all the queue nodes with items ready for consumption keyed by topic IDs. Dequeue distributor utilizes the cache in order to direct dequeue requests for a targeted topic ID to an appropriate queue host in the associated heap.
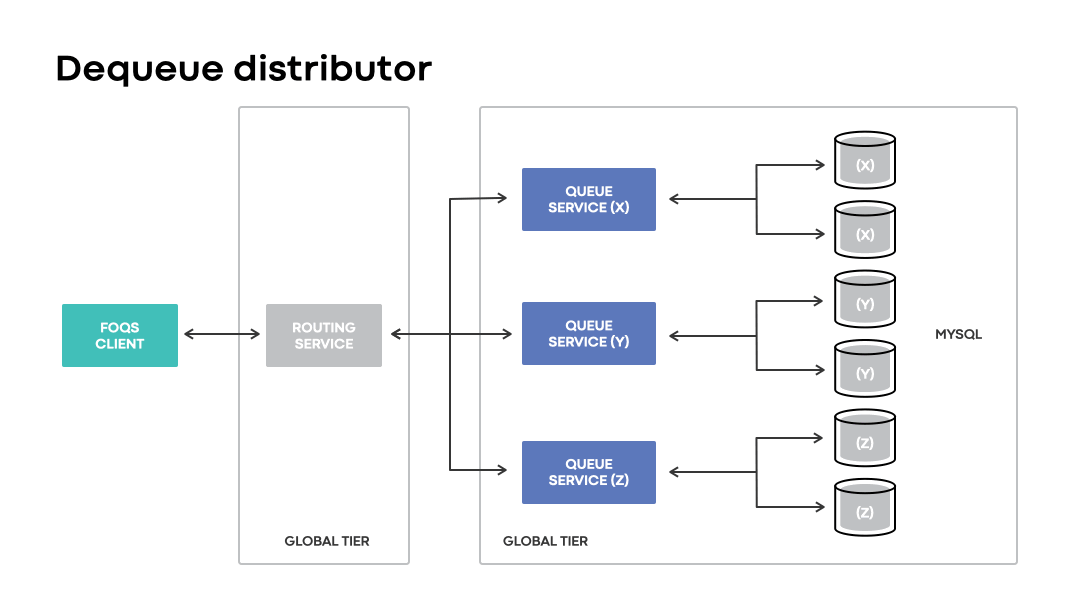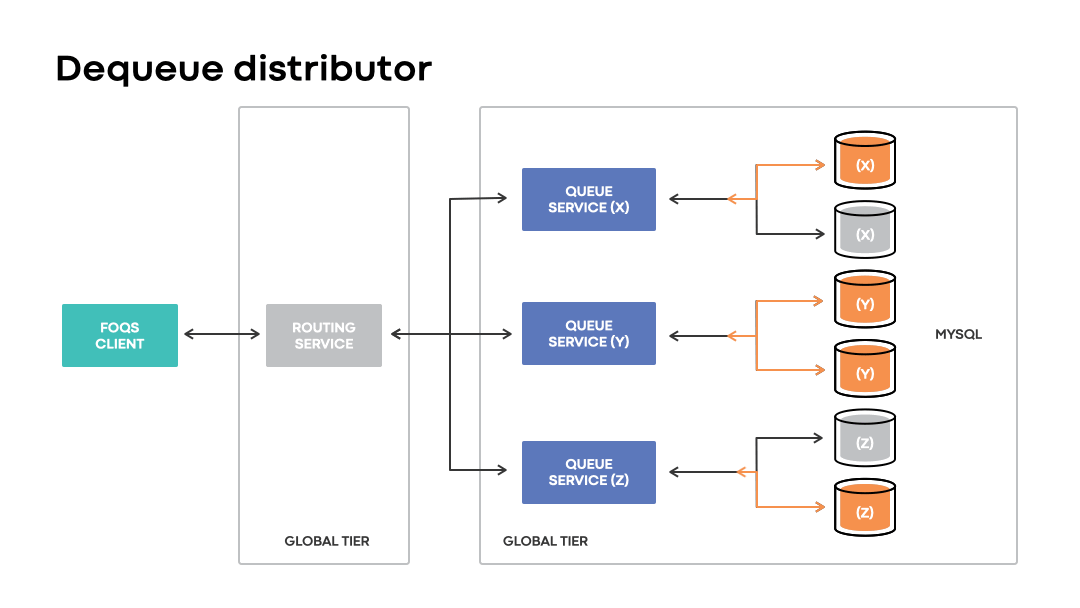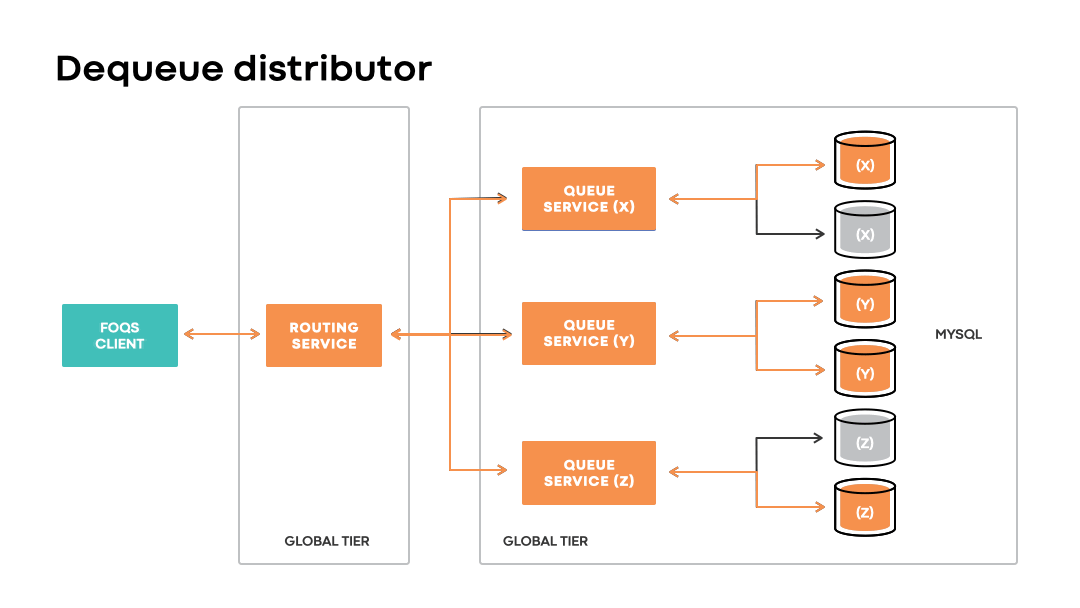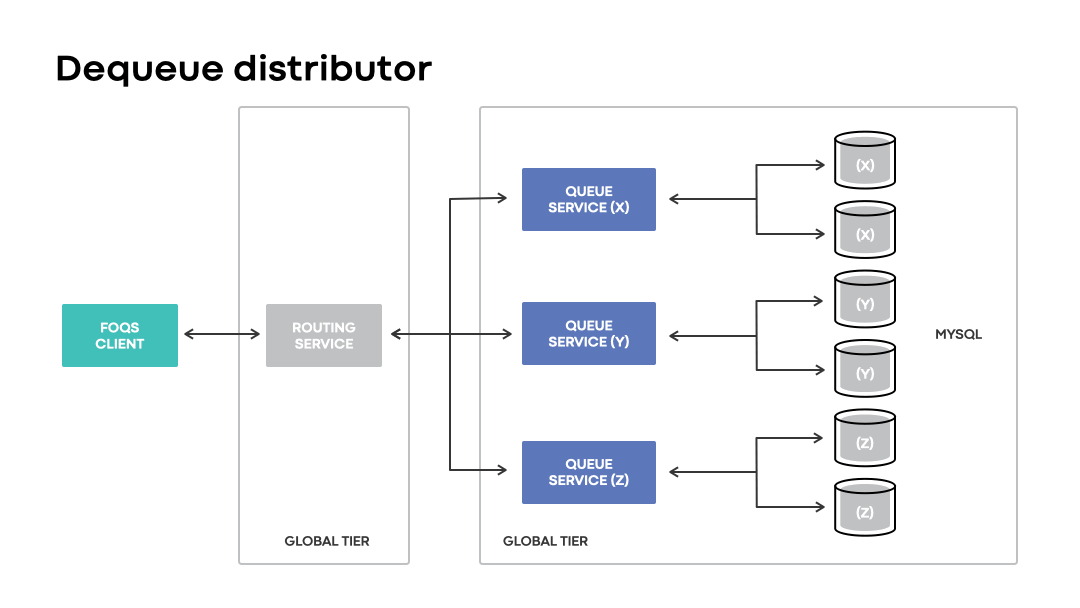
Like the enqueue distributor, the dequeue distributor enables clients to continue dequeuing items associated with a topic ID and logical region preference even in the event of unavailability of an associated physical region.
Migration at scale
Global installations have enabled the FOQS system to react to disasters in an elegant manner, entirely eliminating complexity for its clients while enabling higher data availability.
With the shift to global installations, the FOQS team added the routing service into its architecture. Despite the many benefits of the routing service, it introduced significant challenges when migrating FOQS’s biggest use case, Async.
Item discoverability
As the queueing layer was scaled out to accommodate Async’s traffic, the dequeue distributor struggled to maintain a fresh cache and optimally spread dequeue requests to queue nodes. Longer queuing delays and latency SLO violations ensued for Async as a result of the suboptimal routing of dequeue requests.
To address stale cache challenges, we parallelized cache replenishment aggregation being performed by routing service. As a result, replenishment latency was nearly halved, and occurrences of routing requests to stale queue nodes were greatly reduced.
With cache replenishment reduced, we began to observe other routing related issues: thundering herd and starvation. By default, the dequeue distributor is reliant upon an algorithm that directs requests to the top-k queue nodes in its cache. Each routing service node maintains a similar cache of logical queue IDs, ordered by priority. Queue nodes at the top of the caches have the highest probability of receiving dequeue requests. As traffic increased, we began to see thundering herd problems for nodes at the top of the cache and starvation for those at the bottom. Considering that physical distance is factored into the cache’s ordering scheme, starvation issues were most pronounced when routing cross-region from routing service to queue service.
To remediate routing challenges, randomization among the already prioritized queue nodes was added on the dequeue path during host selection. Randomly selecting among the prioritized queue services nodes in the dequeue distributor’s internal cache resulted in a better spread of requests and thus reduced queueing delay.
Massive migration with zero downtime
Migrating Async’s largest use case to a global installation was not without challenges and risks. With zero downtime for our clients, the team managed to complete the migration in mid-2021 by adopting several key risk-mitigation strategies:
- Utilizing a shadow environment to load and stress test the new architecture
- Establishing and leveraging a simple config-based rollout mechanism to enable quickly rolling forward and backward with regular increases
- Demonstrating a strong bias for investigating issues as they arise and performing retrospectives to understand root-causes and avoid past mistakes
- Developing high-level dashboards with clear metrics denoting the migration’s health and status in order to keep stakeholders up-to-date
For teams facing similar migrations, we hope that the practices applied to the migration from regional to global queue installations serve as inspiration to assist with your own challenges.
Migrating the scale that Async and FOQS handle proved to be a monumental challenge. With the migration of Async’s traffic to a global FOQS installation, we’ve observed much better resilience to disaster scenarios, and human involvement in response to events affecting entire regions is now essentially zero. In sum, we’ve built a globally available distributed queue at Meta scale that enables access to data with high availability. The system is capable of recovering from the loss of an entire region within a matter of seconds, automatically and unbeknown to clients.
Substantial technical and operational challenges were faced on the journey to improve the resiliency of FOQS. We would like to extend thanks to all members of the teams that have supported FOQS’s success. A special thank-you to the core team members who heroically tamed the migration woes detailed here: Nate Ackerman, James Anderson, Dylan Cauwels, Bo Huang, Girish Joshi, Manukranth Kolloju, Kevin Liu, Pavani Panakanti, and CQ Tang.








