
We will be hosting a talk about our work on Scaling a Distributed Priority Queue during our virtual Systems @Scale event at 11 am PT on Wednesday, February 24, followed by a live Q&A session. Please submit any questions to systemsatscale@fb.com before the event.
The entire Facebook ecosystem is powered by thousands of distributed systems and microservices, many of which would benefit from running the workload asynchronously, particularly at peak times of online traffic. Asynchronous computing offers several benefits, including enabling more effective resource utilization, improving system reliability, allowing services to schedule compute to execute on a future date, and helping the microservices communicate with one another dependably. What these services have in common is the need for a queue — a place to store work that needs to happen asynchronously or be passed from one service to another.
Facebook Ordered Queueing Service (FOQS) fills that role. It’s a fully managed, horizontally scalable, multitenant, persistent distributed priority queue built on top of sharded MySQL that enables developers at Facebook to decouple and scale microservices and distributed systems.
We’re openly sharing the design of FOQS, with the hope that the broader engineering community can build upon the ideas and designs presented here.
FOQS Use Cases
A typical use case for FOQS has two main components:
- A producer that enqueues items to be processed. These items can have a priority (to prioritize different work items) and/or a delay (if the item processing needs to be deferred).
- A consumer that uses the getActiveTopics API to discover topics that have items. A topic is a logical priority queue (more on this later). The consumer then dequeues items from those topics and processes them — either inline or by sending the item to a worker pool. If the processing succeeds, it acks the items back to FOQS. If it fails, the items are nacked and will be redelivered to the consumer (nacks can be delayed, just like enqueues).
FOQS supports hundreds of use cases across the Facebook stack, including:
- Async (Facebook’s asynchronous compute platform), which is a widely used general purpose asynchronous computing platform at Facebook. It powers a variety of use cases, ranging from notifications to integrity checks to scheduling posts for a future time, and leverages the ability of FOQS to hold large backlogs of work items to defer running use cases that can tolerate delays to off-peak hours.
- Video encoding service, which powers asynchronous video encoding use cases. When videos are uploaded, they are broken up into multiple components, each of which is stored in FOQS and later processed.
- Language translation technologies, which power translating posts between languages. This work can be computationally expensive and benefits from parallelization by being broken up into multiple jobs, stored in FOQS, and run in parallel by workers.
Building a distributed priority queue
FOQS stores items that live in a topic within a namespace. It exposes a Thrift API that consists of the following operations:
- Enqueue
- Dequeue
- Ack
- Nack
- GetActiveTopics
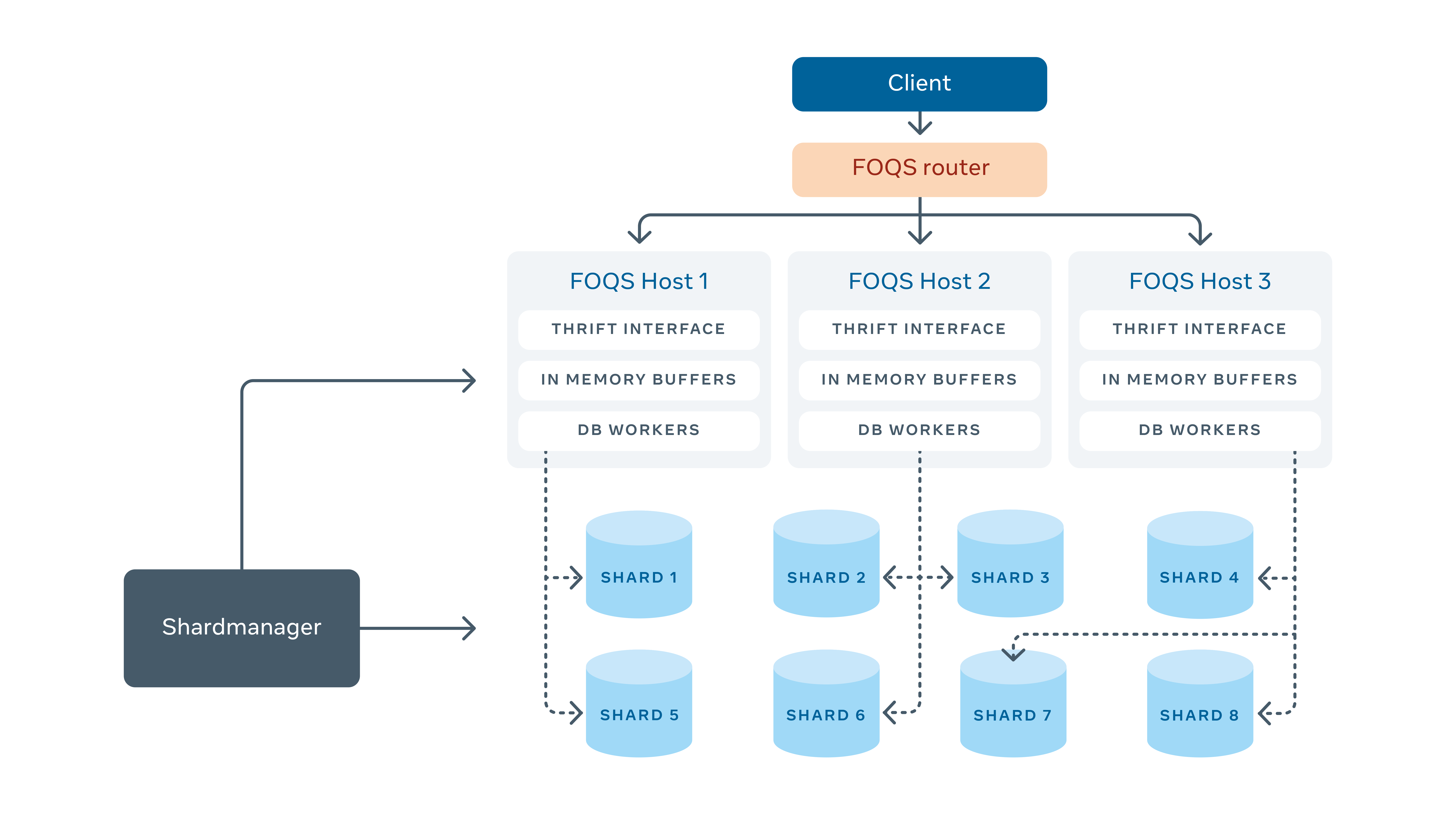
FOQS uses Shard Manager, an internal service, to manage the assignment of shards to hosts. Each shard is assigned to one host. In order to more easily communicate with other back-end services, FOQS implements a Thrift interface.
What is an item?
An item in FOQS is a message in a priority queue with some user specified data. In general, it consists of the following fields:
- Namespace: The unit of multitenancy for FOQS.
- Topic: A priority queue; one namespace can have many (thousands of) topics.
- Priority (a user-specified 32-bit integer): A lower number signifies a higher priority.
- Payload: an immutable binary blob that can be as large as 10 Kb. Developers are free to put whatever they want here.
- Metadata: A mutable binary blob. Developers are free to put whatever they want here. In general, metadata should be only a few hundred bytes.
- Dequeue delay — The timestamp where an item should be dequeued. This is also referred to as the deliver_after.
- Lease duration: The time duration within which an item dequeued by the consumer needs to be acked or nacked. If the consumer does neither, FOQS can redeliver the item based on the retry policy specified by the customer (at least once, at most once, and maximum retry counts).
- FOQS-assigned unique ID: This is used to identify an item by the API. Operations on an item use this ID.
- TTL: Limits how long items live in the queue. Once an item’s time to live (TTL) is hit, it will be deleted.
Each item in FOQS corresponds to one row in a MySQL table. Upon enqueue, an item ID is assigned.
What is a topic?
A topic is a logical priority queue, specified by a user-defined string. It contains items and sorts them by their priority and deliver_after value. Topics are cheap and dynamic, and are created simply by enqueueing an item and specifying that topic.
As topics are dynamic, FOQS provides an API for developers to discover topics by querying the active topics (topics with at least one item). When a topic has no more items, it ceases to exist.
What is a namespace?
A namespace corresponds to a queueing use case. It is the unit of multitenancy for FOQS. Each namespace gets some guaranteed capacity, measured in terms of enqueues per minute. Namespaces can share the same tier (a tier is an ensemble of FOQS hosts and MySQL shards that serve a group of namespaces) and not affect one another. Namespaces map to exactly one tier.
Enqueue
Enqueues are items’ entry point into FOQS. If an enqueue succeeds, the item is persisted and can eventually be dequeued.
When an enqueue request arrives at a FOQS host, the request gets buffered and returns a promise. Each MySQL shard has a corresponding worker that is reading items from the buffer and inserting them into MySQL. One database row corresponds to one item. Once the row insertion is complete (succeeds or fails), the promise is fulfilled and an enqueue response is sent back to the client. This is depicted in the diagram below:
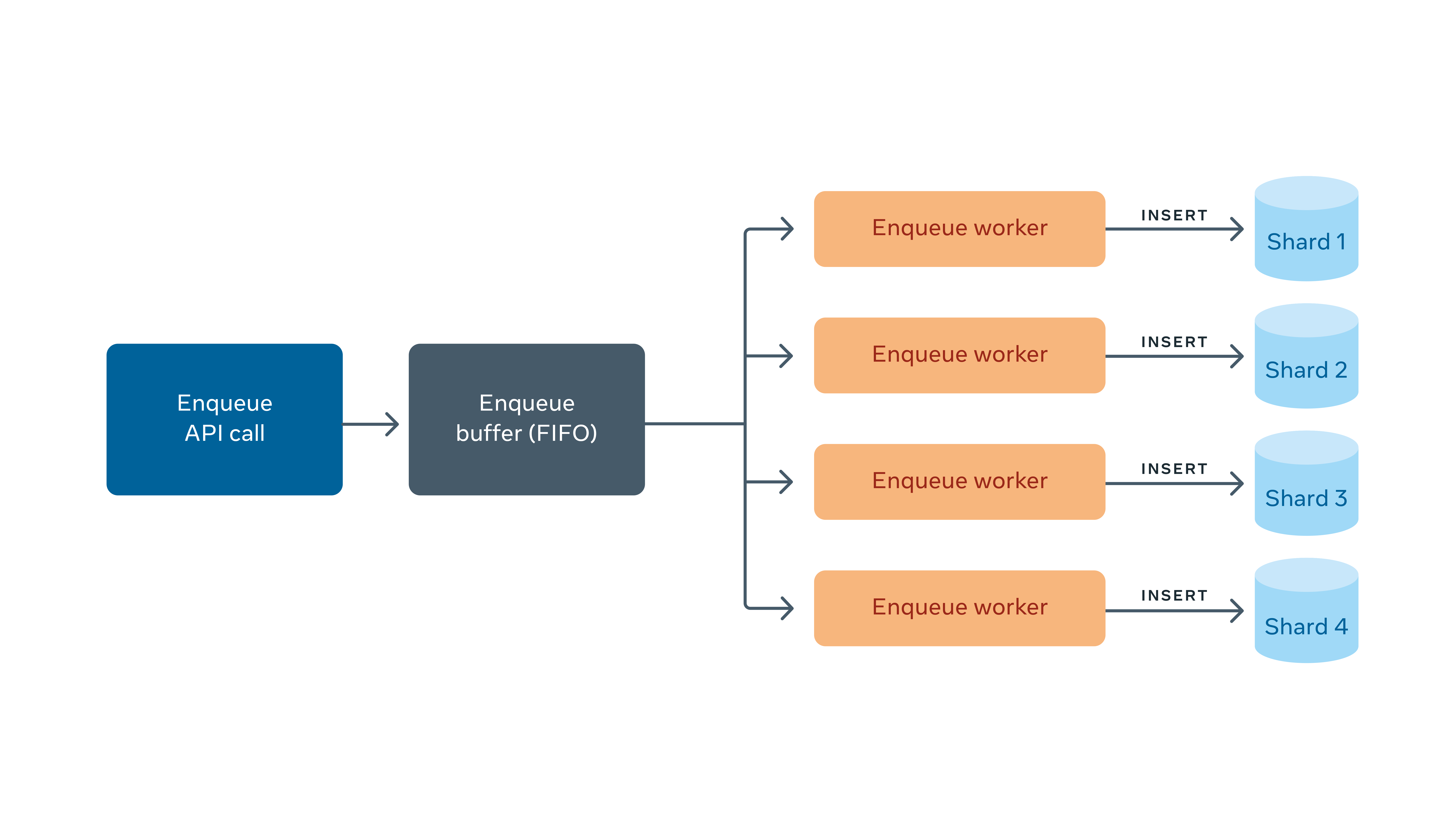
FOQS uses a circuit breaker design pattern to mark down shards that are unhealthy. Health is defined by slow queries (>x ms average over a rolling window) or error rate (>x% average over a rolling window). If the shard is deemed to be unhealthy, the worker stops accepting more work until it is healthy. This way, FOQS does not continue to overload already unhealthy shards with new items.
On success, the enqueue API returns a unique ID for an item. This ID is a string that contains the shard ID and a 64-bit primary key in the shard. This combination uniquely identifies every item in FOQS.
Dequeue
The dequeue API accepts a collection of (topic, count) pairs. For each topic requested, FOQS will return, at most, count items for that topic. The items are ordered by priority and deliver_after, so items with a lower priority will be delivered first. If multiple items are tied for lowest priority, lower deliver_after (i.e., older) items will be delivered first.
The enqueue API allows the lease duration for an item to be specified. When an item is dequeued, its lease begins. If the item is not acked or nacked within the lease duration, it is made available for redelivery. This is to avoid losing items when a downstream consumer crashes before it can ack or nack the item. FOQS supports both at least once and at most once delivery semantics. If an item is to be delivered at most once, it will be deleted when the lease expires; if at least once, redelivery will be attempted.
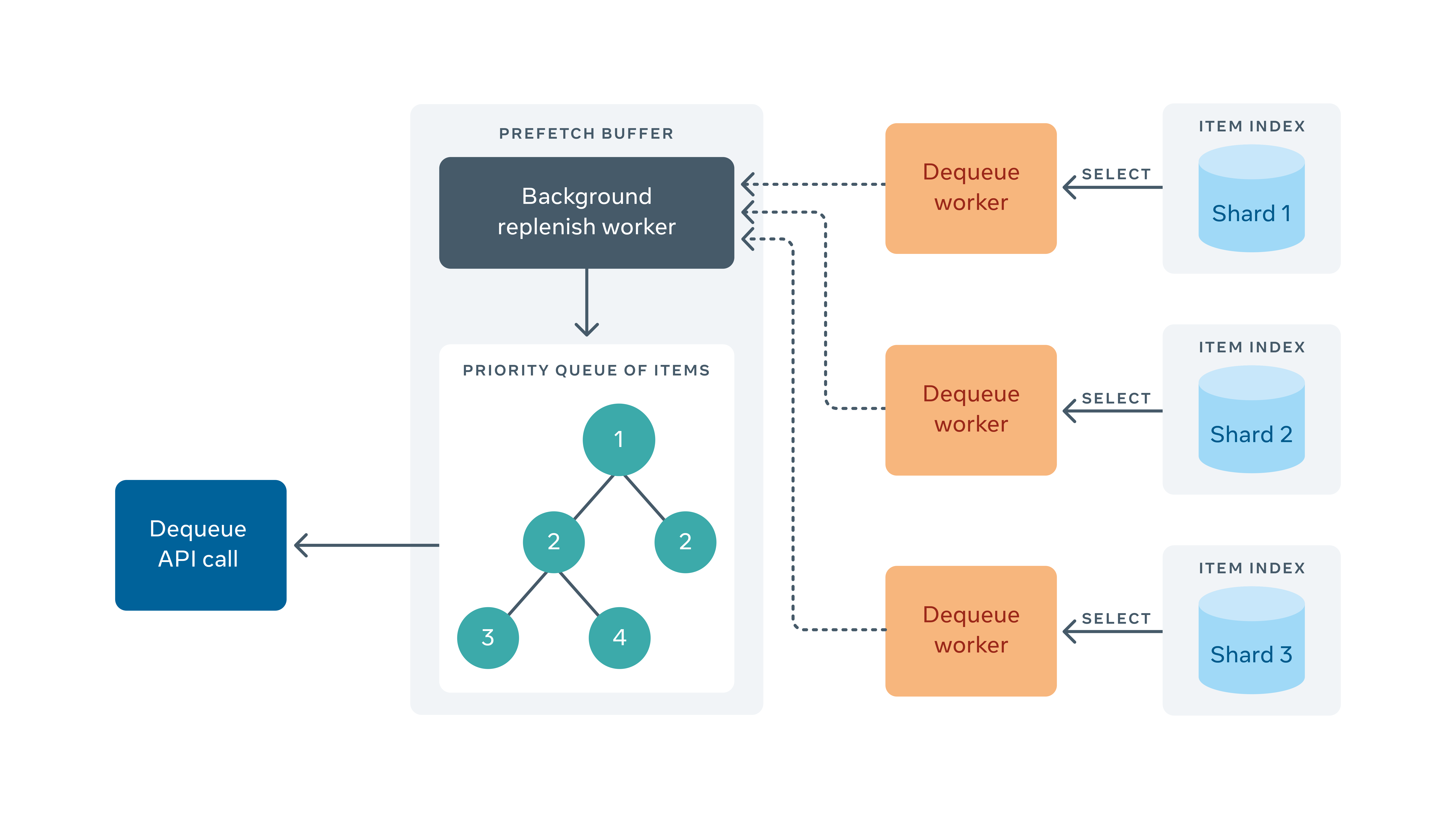
Since FOQS supports priorities, each host needs to run a reduce operation across the shards it owns to find the highest priority items and select those. To optimize this, FOQS maintains a data structure called the Prefetch Buffer, which works in the background and fetches the highest priority item across all shards and stores them to be dequeued by the client.
Each shard maintains an in-memory index of the primary keys of items that are ready to deliver on the shard, sorted by priority. This index is updated by any operation that marks an item as ready to deliver (i.e., enqueues). This allows the Prefetch Buffer to efficiently find the highest priority primary keys by doing a k-way merge and running select queries on those rows. The status of these rows is also updated in the database as “delivered” to avoid double delivery.
The prefetch buffer replenishes itself by storing the client demand (dequeue request rate) for each topic. The prefetch buffer will request items at a rate proportional to this demand. Topics that are being dequeued faster will get more items put in the prefetch buffer.
The dequeue API simply reads the items out of the Prefetch Buffer and returns them to the client.
Ack/Nack
An ack signifies that the item was dequeued and successfully processed, and therefore doesn’t need to be delivered again.
A nack, on the other hand, signifies that an item should be redelivered because the client needs to process it again. When an item is nacked, it can be deferred, allowing clients to leverage exponential backoff when processing items that are failing. Furthermore, clients can update the metadata of the item on nack in case they want to store partial results in the item.
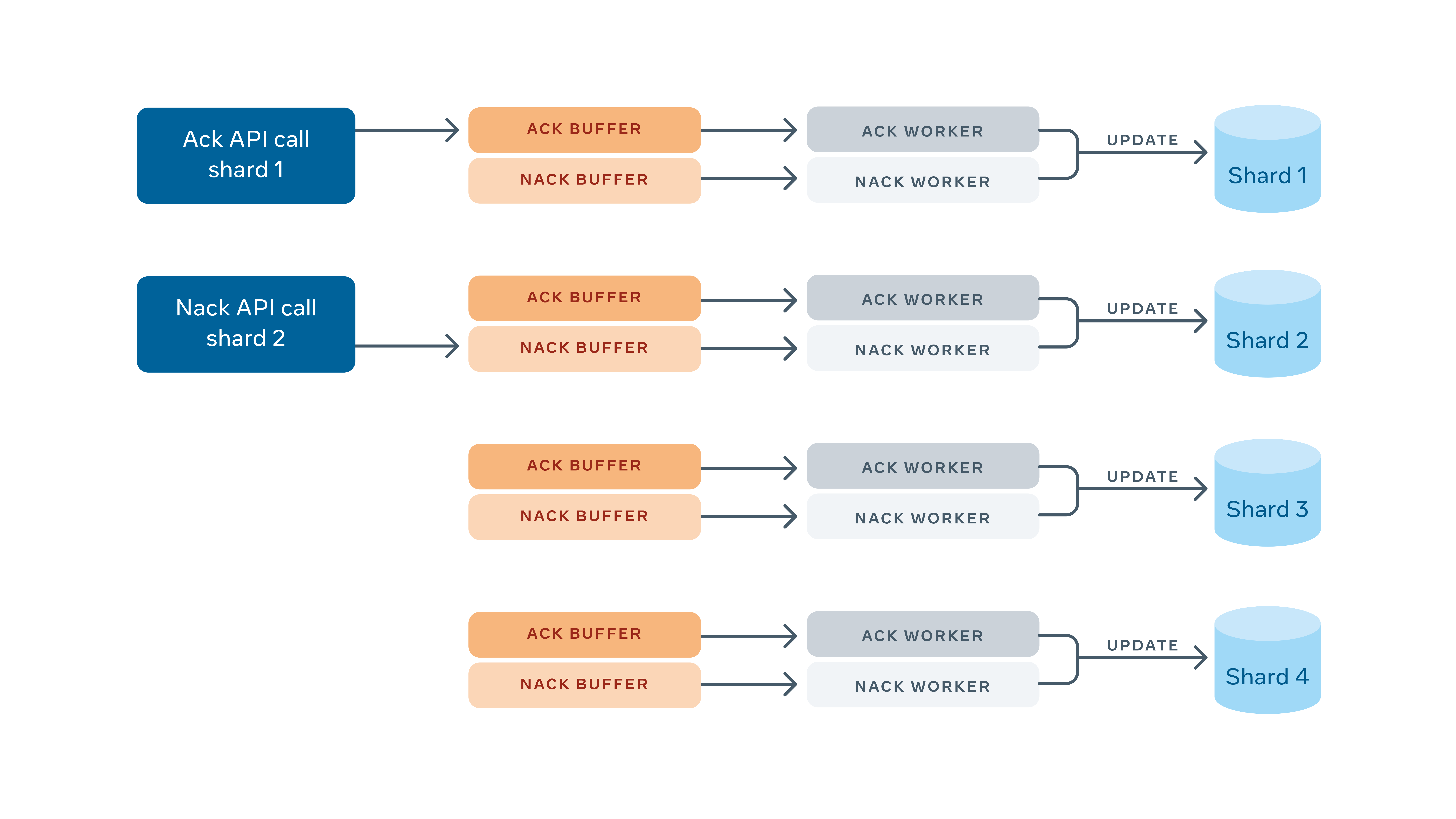
Because each MySQL shard is owned by at most one FOQS host, an ack/nack request needs to land on the host that owns the shard. Since the shard ID is encoded in every item ID, the FOQS client uses the shard to locate the host. This mapping is looked up via Shard Manager.
Once the ack/nack is routed to the correct host, it gets sent to a shard-specific in-memory buffer. A worker pulls items from this ack buffer and deletes those rows from the MySQL shard; similarly, a worker pulls items from the nack buffer. Rather than deleting the item, it updates the row with a new deliver_after time and metadata (if the client updated it). If the ack or nack operations get lost for any reason, such as MySQL unavailability or crashes of FOQS nodes, the items will be considered for redelivery after their leases expire.
Push vs. Pull
FOQS features a pull-based interface, where consumers use the dequeue API to fetch available data. To understand the motivation behind offering a pull model in the FOQS API, it helps to look at the diversity of workloads using FOQS with respect to the following characteristics:
- End-to-end processing delay needs: End-to-end processing delay is the delay between an item becoming ready and when it gets dequeued by a consumer. We see a mix of fast- and slow-moving workloads where some topics or subsets of items require shorter (millisecond) or tolerate longer (up to days) delays, depending on their priority.
- Rate of processing: Topics can be heterogeneous with respect to the rate at which items can be consumed (10s of items per minute to 10+ million items per minute). But depending on the availability of downstream resources at a given time, this can be different from the rate they are typically produced.
- Priorities: Topics vary in their priority of processing at the topic level or at individual item level within a topic.
- Location of processing: Certain topics and items need to be processed in specific regions to ensure affinity to data they are processing.
Here are the trade-offs between the pull and push models in the context of the workloads on FOQS.
| Pull | Push |
| Enables serving diverse needs by providing more flexibility to the consumer and keeps the queue layer simple. | Needs the queue layer to address challenges around overloading the consumers by pushing too fast. |
| Consumers must discover where data is located and pull it at an appropriate rate based on end-to-end processing latency needs. | Addresses these problems effectively as the data is pushed to the consumers as soon as it is available. |
By deciding to go with the pull model, we address the challenges with discoverability of items in the pull model with a routing layer component while providing more flexibility to consumers with respect to how and where they process the items.
Running FOQS at Facebook Scale
FOQS has experienced exponential growth over the past few years and now processes close to one trillion items per day. Processing backlogs have reached the order of hundreds of billions of items, reflecting the system’s ability to handle widespread downstream failures. In order to handle this scale, we had to implement some optimizations, explained next.
Putting all this together, the FOQS architecture looks like this:
Checkpointing
FOQS has background threads which run operations such as making deferred items ready to deliver, expiring lease and purging expired items rely on columns storing timestamps. For example, if we want to update the state of all the items that are ready to be delivered to reflect that they are ready to deliver, we would need a query that selects all rows with timestamp_column <= UNIX_TIMESTAMP()for update.
The problem with such a query is that MySQL needs to lock updates to all rows with timestamp ≲ now (not just the ones returned). It does this by keeping old versions of the row around in a linked list, known as the history list. Without going into too many details, the longer the history, the slower read queries are.
With checkpointing, FOQS maintains a lower bound on the query (the last known timestamp processed), which bounds the where clause. The where clause becomes:
WHERE <checkpoint> <= timestamp_column AND timestamp_column <= UNIX_TIMESTAMP()
By bounding the query from both sides, the number of rows that represent the history is smaller, making read (and update) performance better overall.
Disaster Readiness
Facebook’s software infrastructure needs to be able to withstand the loss of entire data centers. To do that, each FOQS MySQL shard is replicated to two additional regions. The cross-region replication is asynchronous, but the MySQL binlog gets persisted to another building in the same region synchronously.
If a data center needs to be drained (or MySQL databases are undergoing maintenance), the MySQL primary is temporarily put into read-only mode until the replicas can catch up. This usually takes a few milliseconds. Once the replica is caught up, it gets promoted to be the primary. Now that the MySQL database has its primary in another region, the shard gets assigned to a FOQS host in that region. This minimizes the amount of cross-region network traffic, which is comparatively expensive. Events to promote MySQL replicas to be primary can cause large capacity imbalances across regions (and in general, FOQS cannot make assumptions about how much capacity is available where). To handle such scenarios, FOQS has had to improve its routing so that enqueues go to hosts with enough capacity and dequeues go to hosts with highest-priority items.
FOQS itself uses a few disaster reliability optimizations:
- Enqueue forwarding: If an enqueue request lands on a host that is overloaded, FOQS forwards it to another host that has capacity.
- Global rate limiting: Since namespaces are the unit of multitenancy for FOQS, each namespace has a rate limit (computed as enqueues per minute). FOQS enforces this rate limit globally (across all regions). It is impossible to guarantee rate limits in a specific region, but FOQS does use traffic patterns to try to colocate capacity with traffic to minimize cross-region traffic.
Looking Ahead
FOQS supports hundreds of other services across the Facebook stack. The number-one priority is to keep operating the service reliably and efficiently.
Some of the near-term challenges the team will tackle include:
- Handling failures of multiple domains (region, data center, rack, etc.). When a region goes down, FOQS needs to ensure that no data is lost and that data from another region is available as quickly as possible.
- More effective load balancing of enqueue traffic and more efficient discoverability of items during dequeues in order to support a diverse set of customers and traffic patterns. As Facebook brings up new data centers, data will get further spread out around the world and discoverability will become even more important.
- Expanding the feature set to serve developer needs around workflows, timers, and strict ordering.
Thanks
Thanks to all the engineers who have contributed to this project including: Brian Lee, Dillon George, Hrishikesh Gadre, Jasmit Kaur Saluja, Jeffrey Warren, Manukranth Kolloju, Niharika Devanathan, Pavani Panakanti, Shan Phylim, and Yingji Zhang.








