
Over the years, as we’ve expanded in scale and functionalities, Facebook has evolved from a basic web server architecture into a complex one with thousands of services working behind the scenes. It’s no trivial task to scale the wide range of back-end services needed for Facebook’s products. And we found that many of our teams were building their own custom sharding solutions with overlapping functionalities. To address this problem, we built Shard Manager as a generic platform that facilitates efficient development and operation of reliable sharded applications.
The concept of using sharding to scale services is not new. However, to the best of our knowledge, we are the only generic sharding platform in the industry that achieves wide adoption at our scale. Shard Manager manages tens of millions of shards hosted on hundreds of thousands of servers across hundreds of applications in production.
An introduction to sharding
In the most basic form, people are familiar with sharding as a way to scale out services to support high throughput. The figure below illustrates the scaling of a typical web stack. The web tier is usually stateless and easy to scale out. As any server can handle any request, a wide range of traffic routing strategies can be used, like round robin or random.
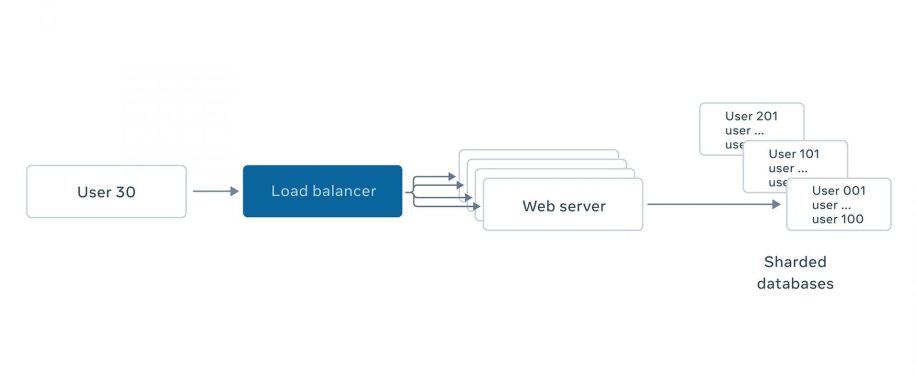
On the other hand, scaling the database part is nontrivial due to its state. We need to apply a scheme to deterministically spread data across servers. A simple scheme of hashing like hash(data_key) % num_servers can spread data but has the problem of shuffling data around when servers are added to scale. Consistent hashing addresses the issue by redistributing only a small subset of data from existing servers to new servers. However, this scheme requires application to have fine-grained keys for statistical load balancing to be effective. Consistent hashing’s ability to support constraint-based allocation (e.g., data of European Union users should be stored in European data centers for lower latency) is also limited due to its nature. As a result, only certain classes of applications such as distributed caching adopt this scheme.
An alternative scheme is to explicitly partition data into shards that are allocated to servers. The data of billions of users is stored across many database instances, and each instance can be treated as a shard. To increase fault tolerance, each database shard can have multiple copies (aka replicas), each of which can play different roles (e.g., primary or secondary) depending on the consistency requirement.
The allocation of shards to servers is explicitly computed with the capability of incorporating various constraints like locality preference, which hashing solutions cannot support. We found that the sharding approach is more flexible than hashing and suits the needs of a wider range of distributed applications.
Applications adopting this sharding approach often need certain shard management capabilities in order to operate reliably at scale. The most basic one is the ability to failover. In the event of a hardware or software failure, the system can divert client traffic away from failed servers and may even need to rebuild impacted replicas on healthy servers. In large data centers, there is always planned downtime for servers to perform hardware or software maintenance. The shard management system needs to ensure that each shard has enough healthy replicas by proactively moving replicas away from servers to be taken down if deemed necessary.
Additionally, the possibly uneven and ever-changing shard load requires load balancing, meaning the set of shards each server hosts must be dynamically adjusted to achieve uniform resource utilization and improve overall resource efficiency and service reliability. Finally, the fluctuation of client traffic requires shard-scaling, where the system dynamically adjusts replication factor on a per-shard basis to ensure its average per-replica load stays optimal.
We discovered that different service teams at Facebook were already building their own custom solutions to varying degrees of completeness. It was common to see services able to handle failover but have a very limited form of load balancing. This led to suboptimal reliability and high operation overhead. This is why we designed Shard Manager as a generic shard management platform.
Sharding as a platform with Shard Manager
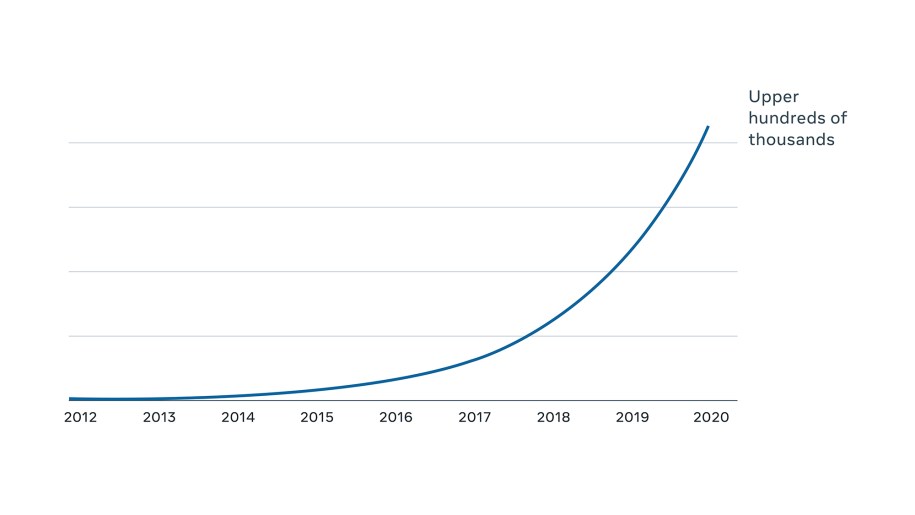
Over the years, hundreds of sharded applications have been built or migrated onto Shard Manager, totaling upper tens of millions of shard replicas on upper hundreds of thousands of servers with historical hypergrowth, as shown in the figure below.
These applications assist with the smooth functioning of various user-facing products, including the Facebook app, Messenger, WhatsApp, and Instagram.
Apart from the sheer number of applications, their use cases vary significantly in both complexity and scale, ranging from simple counter service with high tens of servers to complex, Paxos-based global storage service with tens of thousands of servers. The image below shows a wide spectrum of representative applications, with their scale indicated by font size.

Various factors contribute to the wide adoption. First, integrating with Shard Manager means simply implementing a small, straightforward interface consisting of add_shard and drop_shard primitives. Second, each application can declare its reliability and efficiency requirements via intent-based specification. Third, the use of a generic constrained optimization solver enables Shard Manager to provide versatile load-balancing capability and easily add support for new balancing strategies.
Last but not least, by fully integrating into the overall infrastructure ecosystem, including capacity and container management, Shard Manager supports not only efficient development but also safe operation of sharded applications, and therefore provides an end-to-end solution, which no similar platforms provide. Shard Manager supports more sophisticated use cases than do similar platforms, like Apache Helix, including Paxos-based storage system use cases.
Types of Shard Manager applications
We abstract the commonality of applications on Shard Manager and categorize them into three types: primary only, secondaries only, and primary-secondaries.
Primary only:
Each shard has a single replica, called the primary replica. These types of applications typically store state in external systems, like databases and data warehouses. A common paradigm is that each shard represents a worker that fetches designated data, processes them, optionally serves client requests, and writes back the results, with optional optimizations like batching. Stream processing is one real example that processes data from an input stream and writes results to an output stream. Shard Manager provides an at-most-one-primary guarantee to help prevent data inconsistency due to duplicate data processing, like a traditional ZooKeeper lock-based approach.
Secondaries only:
Each shard has multiple replicas of equal role, dubbed secondaries. The redundancy from multiple replicas provides better fault tolerance. Additionally, replication factor can be adjusted based on workload: Hot shards can have more replicas to spread load. Typically, these types of applications are read-only without strong consistency requirements. They fetch data from an external storage system, optionally process the data, cache results locally, and serve queries off local data. One real example is machine learning inference systems, which download trained models from remote storage and serve inference requests.
Primary-secondaries:
Each shard has multiple replicas of two roles — primary and secondary. These types of applications are typically storage systems with strict requirements on data consistency and durability, where the primary replica accepts write requests and drives replication among all replicas while secondaries provide redundancy and can optionally serve reads to reduce the load on the primary. One example is Zippy DB, which is a global key-value store with Paxos-based replication.
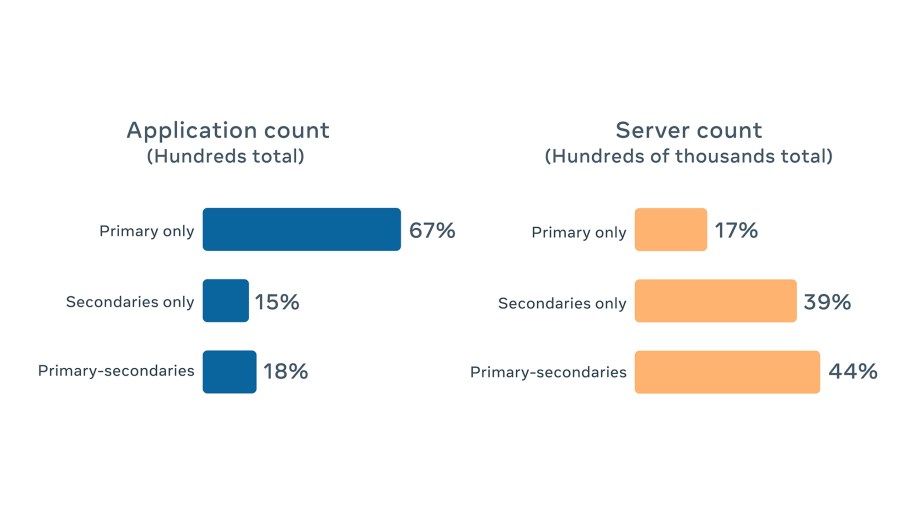
We found that the above three types can model most sharded applications at Facebook, with percentage distribution as of August 2020 shown below. Sixty-seven percent of applications are primary-only due to architectural simplicity and conceptual similarity to traditional ZooKeeper’s lock-based solutions. However, in terms of server count, primary-only accounts for only 17 percent, which means primary-only applications are on average smaller than applications of the other two types.
Building applications with Shard Manager
After application owners decide how to slice their workload/data into shards and which application type suits their needs, there are three straightforward, standardized steps in building a sharded application on Shard Manager, irrespective of use case.
- An application links a Shard Manager library and implements shard state transition interface with their business logic plugged in.
- An application owner provides intent-based specification to configure constraints. Shard Manager offers four major groups of out-of-the-box functionalities: fault tolerance, load balancing, shard scaling, and operational safety.
- Application clients use a common routing library to route shard-specific requests.
Shard state transition interface
Our shard state transition interface consists of a small but solid set of imperative primitives shown below, via which application-specific logic is plugged:
status add_shard(shard_id)
status drop_shard(shard_id)The add_shard call instructs a server to load the shard identified by the passed-in shard ID. Return value indicates the status of the transition, such as whether shard loading is in progress or runs into errors. Conversely, the drop_shard call instructs a server to drop a shard and stop serving client requests.
This interface gives applications full freedom of mapping shards to their domain-specific data. For storage service, the add_shard call typically triggers data transfer from a peer replica; for a machine learning inference platform, the add_shard call triggers the loading of a model from remote storage to local host.
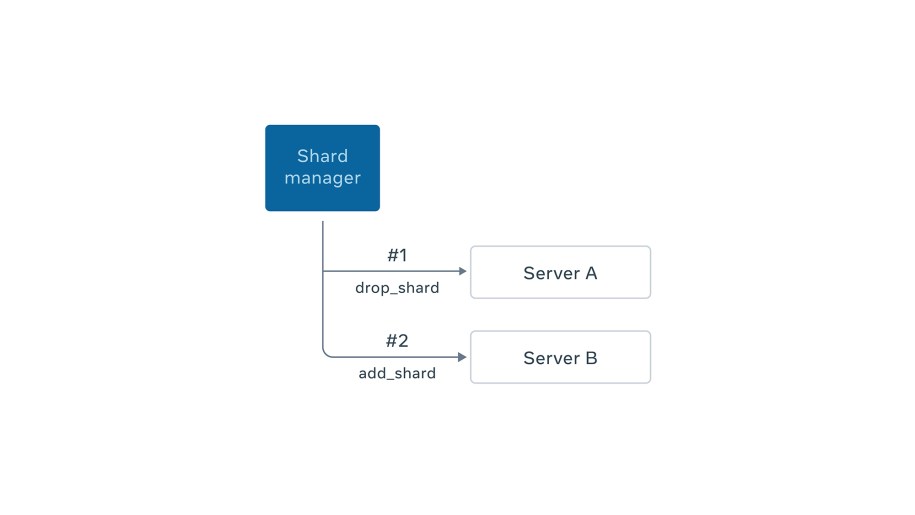
On top of the above primitives, Shard Manager constructs a high-level shard move protocol, illustrated below. Shard Manager decides to move a shard from server A, which is highly loaded, to the more lightly loaded server B to balance load. First, Shard Manager makes a drop_shard call to server A and waits for it to succeed. Second, it makes an add_shard call to server B. This protocol provides an at-most-one-primary guarantee.
The above two basic primitives are all that a typical application needs to implement to become sharded and achieve scalability. For sophisticated applications, Shard Manager supports more powerful interfaces, which are elaborated on below.
In the above protocol, the clients of the shard under transition experiences transient unavailability during the period when the shard is not on any server, which is not acceptable for user-facing applications. As a result, we developed a more sophisticated protocol that supports seamless ownership handoff and minimizes shard downtime.
For primary-secondaries applications, two additional primitives are provided, as shown below:
status change_role(shard_id, primary <-> secondary)
status update_membership(shard_id, [m1, m2, ...])change_roleis used to transition the role of a replica between secondary and primary.update_membershipinstructs the primary of a shard to validate and execute replica membership change, which is important for Paxos-based applications to maximize data correctness.
The above interfaces are the result of our thorough analysis and experience working with sharded applications. They turn out to be sufficiently generic to support most applications.
Intent-based specification of various functionalities
Fault tolerance
For distributed systems, failure is the norm rather than the exception, and knowing how to prepare for and recover from failure is essential to achieving high availability.
Replication: Redundancy via replication is a common strategy for improving fault tolerance. Shard Manager enables the configuration of replication factors on a per-shard basis. The benefit of replication is marginal if the failure of a single fault domain can take down all redundant replicas. Shard Manager supports spreading shard replicas across configurable fault domains, for instance, data center buildings for regional applications and regions for global applications.
Automatic failure detection and shard failover: Shard Manager can automatically detect server failures and network partition. After a failure is detected, it’s not always ideal to build replacement replicas immediately. Shard Manager enables applications to make an appropriate trade-off between the cost of building new replicas and acceptable unavailability via the configuration of failure detection latency and shard failover delay. Additionally, when network partitioning occurs, applications have the option of choosing between availability and consistency.
Failover throttling: To prevent cascading failures, Shard Manager supports failover throttling, which limits the rate of shard failover and protects the rest of the healthy servers from being suddenly overloaded in major outage scenarios.
Load balancing
Load balancing refers to the process of evenly distributing shards and workload thereof across application servers on a continual basis. It enables efficient use of resources and avoids hot spots.
Heterogeneous hardware and shards: At Facebook, we have multiple types and generations of hardware. Most applications need to run on heterogeneous hardware. The size and load of shards can vary for applications whose workload/data cannot be evenly sharded. Shard Manager load balancing algorithm takes fine-grained per-server and per-shard (replica) information into consideration and therefore supports both heterogeneous hardware and shards.
Dynamic load collection: A shard’s load can change over time due to its usage. The capacity available to applications can vary if it ties to a dynamic resource like available disk space. Shard Manager periodically collects per-replica load and per-server capacity from applications and instantiates load balancing.
Multi-resource balancing: Shard Manager supports simultaneously balancing multiple resources like compute, memory, and storage with varied user-configurable priorities. It makes sure the utilization of bottleneck resources falls within acceptable range, and that usage of less critical resources is balanced as much as possible.
Throttling: Similar to failover throttling, the number of shard moves generated by load balancing is throttled at the granularity of total moves and per-server moves.
The above versatile support for both spatial and temporal load variability suits the varying balancing needs of sharded applications.
Shard scaling
Lots of applications at Facebook serve requests from users directly or indirectly. Therefore, the traffic exhibits a diurnal pattern with a significant drop-off in request rate between peak and off-peak time.
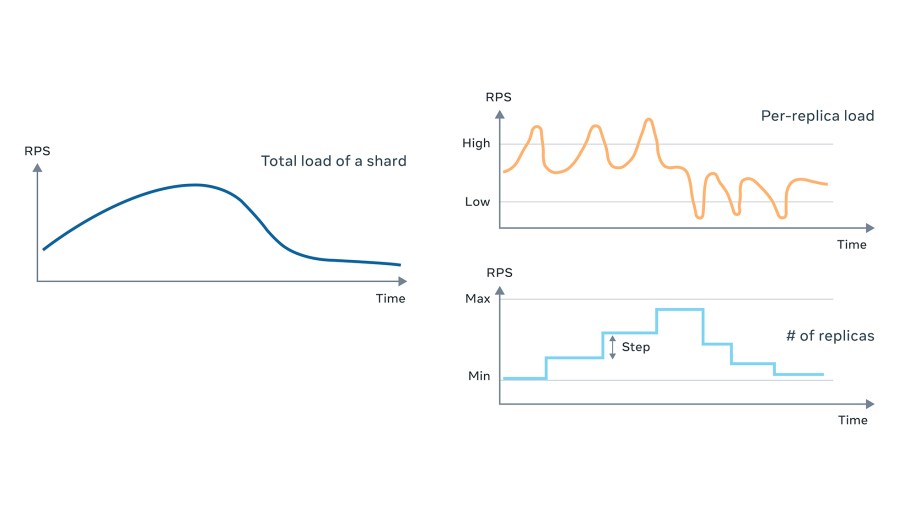
Elastic compute, which dynamically adjusts resource allocation based on workload change, is one solution for improving resource efficiency without sacrificing reliability. In reaction to real-time load change, Shard Manager can perform shard scaling, which means it can dynamically adjust the replication factor when the average per-replica load of a shard deviates from a user-configured acceptable range. Shard scaling throttling can be configured to limit the number of added or dropped replicas in a given period.
The image below illustrates the scaling process for one shard. Initially, the total load across all replicas increases, and therefore per-replica load increases. Once per-replica load exceeds the upper threshold, shard scaling kicks in and adds a sufficient number of new replicas to bring the per-replica load back to an acceptable range. Later, the shard load starts to decrease, and shard scaling reduces the replica count to free unneeded resources to be used by other hot shards or applications.
Operational safety
Apart from failures, operational events are also the norm rather than exception and are treated as first-class citizens to minimize their impact on reliability. Common operational events include binary updates, hardware repair and maintenance, and kernel upgrades. Shard Manager is codesigned with container management system Twine for seamless event handling. Twine aggregates the events, converts them to container life-cycle events like container stop/restart/move, and communicates them to Shard Manager Scheduler via the TaskControl interface.
Shard Manager Scheduler evaluates the disruptiveness and length of events, and makes necessary proactive shard moves to prevent the events from affecting reliability. Shard Manager guarantees the invariant that every shard must have at least one healthy replica. For Paxos-based applications with a majority quorum rule, Shard Manager supports a variant of the guarantee that ensures that the majority of replicas are healthy. Trade-offs between operational safety and efficiency vary by application and can be tuned via configuration, such as the upper limit of simultaneously affected shards.
The image below shows one example for an application with four containers and three shards. First, a short-lived maintenance operation like a kernel upgrade or security patch affecting Container 4 is requested, and Shard Manager allows the operation to immediately proceed because all shards still have sufficient replicas on the rest of servers. Next, a binary update is requested for Containers 1 to 3. Observing that updating any two containers concurrently would cause shard unavailability, Shard Manager applies the updates sequentially to the containers, one at a time.

Client request routing
We use a common routing library to route requests at Facebook. The routing library takes an application’s name and shard ID as input and returns a RPC client object via which RPC calls can be simply made, as illustrated in the following code. The magic of discovering where shards are allocated is hidden behind create_rpc_client.
rpc_client = create_rpc_client(app_name, shard_id)
rpc_client.foo(...)Shard Manager design and implementation
In this section, we will dive into how Shard Manager is built to support the functionalities we discussed. We will start by sharing the layering of our infrastructure and especially the role of Shard Manager.
Layering of the infrastructure stack
At Facebook, our overall infrastructure has been built with a layered approach with a clear separation of concerns across layers. This enables us to evolve and scale each layer independently and robustly. The image below shows the layering of our infrastructure. Each layer allocates and defines the scope that the adjacent upper layer operates in.
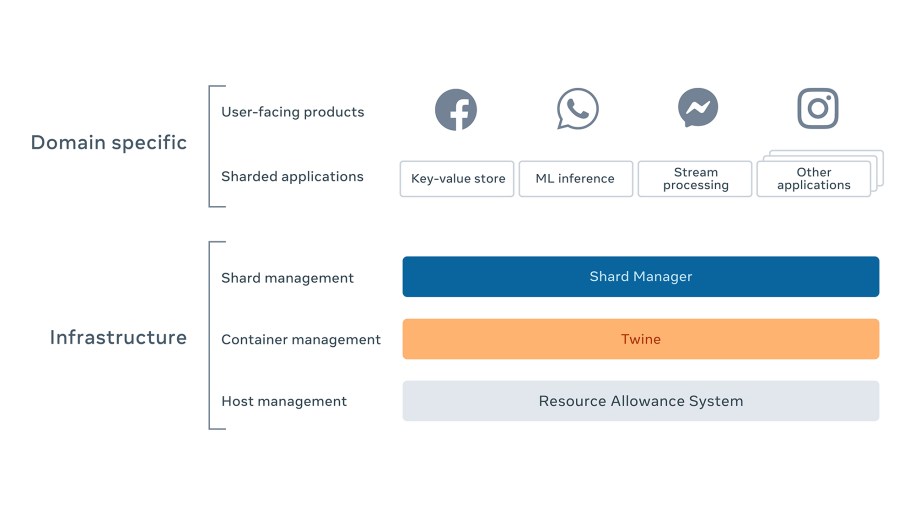
- Host management: The Resource Allowance System manages all physical servers and allocates capacity to organizations and teams.
- Container management: Twine gets capacity from the Resource Allowance System and allocates it to individual applications in the unit of containers.
- Shard management: Shard Manager allocates shards within containers provided by Twine, for sharded applications.
- Sharded applications: Within each shard, applications allocate and run the associated workload.
- Products: These are user-facing products, like mobile apps, that are powered by the sharded back-end applications.
Apart from the downward functional dependency of each layer on the adjacent lower layer, the whole infrastructure stack is codesigned and works collaboratively via signals and events propagating upward. For the Shard Manager layer specifically, TaskControl is our mechanism of achieving collaborative scheduling.
Designs
Central control plane
Shard Manager is a pure control plane service that monitors application states and orchestrates moving application data across servers in shards. The centralized global view enables Shard Manager to compute globally optimal shard allocation and ensure high availability by holistically coordinating all planned operational events. In the event that this central control plane is down, applications can continue to function in degraded mode with existing shard allocation.
Opaque shards with state transition interface
Shards are opaque to Shard Manager, and users can map it to any entity in their application, such as database instances, groups of logs, and buckets of data. We define the shard state transition interfaces that each application must implement. This clean delineation sets Shard Manager apart from application-specific data planes and provides huge flexibility in terms of use cases that can leverage Shard Manager.
Shard granularity sweet spot
Shard granularity is important. Granularity that is too coarse results in poor load balancing, whereas granularity that is too fine incurs unnecessary management overhead on the underlying infrastructure. Our deliberately chosen sweet spot of allocating hundreds of shards to each application server strikes a good balance between load-balancing quality and infrastructure cost.
Generic constrained optimization
One manifestation of use case diversity is the assorted ways in which applications want shards to be allocated to achieve fault tolerance and efficiency. We adopt a generic constrained optimization solver to achieve extensibility. When adding support for new requirements, Shard Manager just needs to internally formulate it as constraints and feed them into the solver to compute optimal shard allocation, with little complexity added to our codebase.
Architecture
This shows the architecture of Shard Manager, with various components explained below.
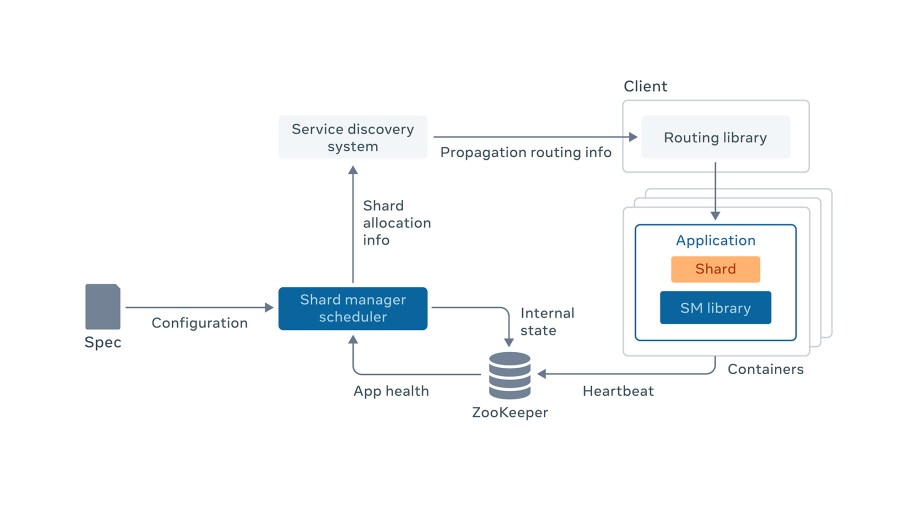
A specification, with all the information needed to manage an application, is provided by application owners to Shard Manager Scheduler.
Shard Manager Scheduler is the central service that orchestrates shard transitions and moves. It collects application states; monitors state changes like server join, server failure, and load change; adjusts shard allocation; and drives shard state transitions via RPC calls to application servers. Shard Manager Scheduler is internally sharded to scale out horizontally.
Applications link the Shard Manager library, which provides server membership and liveness check transparency via connection to ZooKeeper. Applications implement the shard state transition interface and are instructed by Shard Manager Scheduler for state transitions. Applications can measure and expose dynamic load information, which is collected by Shard Manager Scheduler.
Shard Manager Scheduler publishes a public view of the shard allocation to a highly available and scalable service discovery system, which propagates the information to application clients for routing of requests.
Application clients link a common routing library, which encapsulates the discovery of server endpoints on a per-shard basis. After endpoint discovery, client requests are directly sent to the application servers. Therefore, shard manager scheduler is not on the critical path of request serving.
Conclusions and upcoming challenges
Shard Manager offers a generic platform for building a sharded application. Users need only to implement a shard state transition interface and express sharding constraints via intent-based specifications. The platform is fully integrated with the rest of the Facebook ecosystem, which hides the complexity of the underlying infrastructure behind a holistic contract and allows our engineers to stay focused on the core business logic of their applications and products.
Shard Manager has evolved since its beginning nine years ago, but the journey is far from complete. We will continue pushing the envelope in providing best-in-class solutions for building sharded services at Facebook.
Despite our success, we are still expanding Shard Manager’s scale and functionalities on multiple fronts. Here are the various challenges we plan to tackle in next few years:
- Supporting tens of millions of shards per application to meet the demand from ever-growing, large applications by partitioning the applications internally into smaller independent partitions.
- Supporting more complex applications by providing higher modularity and pluggability for users to customize while keeping Shard Manager simple.
- Simplifying the onboarding experience for the long tail of small, simple applications for which current abstraction is too heavyweight.
By demonstrating the feasibility of building a generic sharding solution, we hope we can foster further discussion and help to collectively advance the field around this cutting-edge problem in the technical community.








