
There are thousands of distributed services running on millions of servers in Meta’s data centers. Part of ensuring the reliability of those services means making them resilient to power loss events as our data center fleet grows. To help increase resiliency, we built the Power Loss Siren (PLS) — a rack level, low latency, distributed power loss detection and alert system.
Power loss events can affect thousands of servers simultaneously, potentially causing degradation or downtime for many services used by Meta’s family of apps. PLS helps mitigate the impact of these events. It leverages existing in-rack batteries to notify services about impending power loss without requiring additional hardware, so that engineers or the services themselves can take action. PLS also features a simple API for services to implement mitigation handlers while servers run on battery power. With PLS support, services can failover proactively, rather than reactively after servers go down.
PLS has also simplified our physical infrastructure management. We hope the lessons we’ve learned over our four years developing PLS can help others mitigate data center power loss events at scale as well.
Understanding data center power loss events
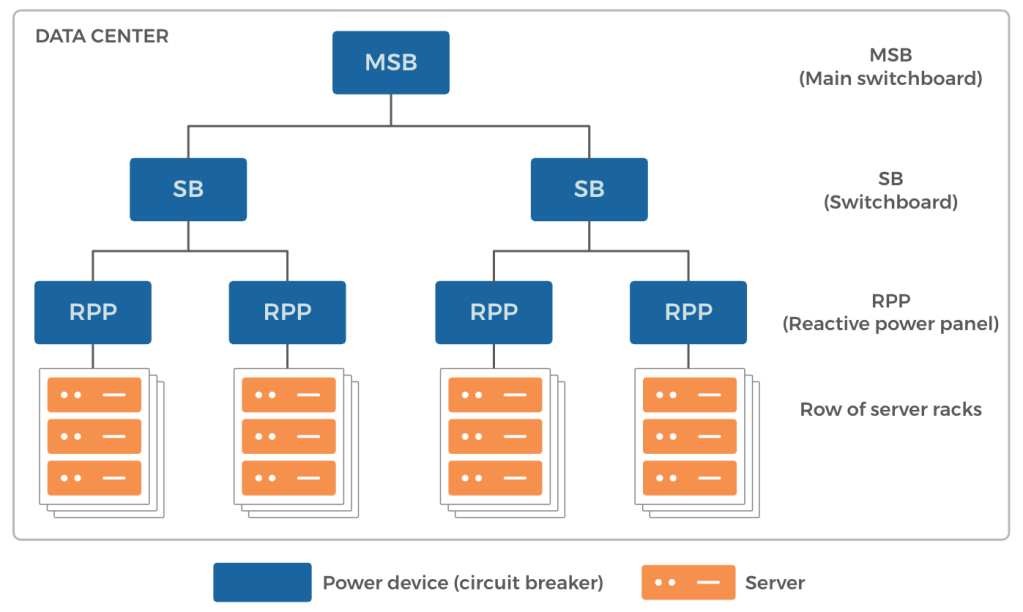
In Meta’s data centers, we deliver power to server racks through a treelike hierarchy of power devices. This structure can support up to a predetermined amount of IT load (server power). Using hierarchical power distribution helps with better fault isolation, preventing faults from traveling upstream. If one or more of these power devices suffer an outage, all the underlying server racks lose power. The higher in the hierarchy the power loss occurs, the larger the number of servers affected.
Power loss events can occur for various reasons, including:
- Device faults: Power devices have randomly occurring catastrophic failures or electrical short circuits. Most power loss events in data centers are caused by power device failures.
- Voltage sags: Disturbances in the utility power supply can cause voltage sags at the power device. This leads to current spikes at the circuit breaker and can trip it, causing power loss to server racks.
- Maintenance failures: Regular maintenance on data center power devices often requires switching power over to a reserve power device. There’s a brief power interruption during these kinds of open power transitions, at which time downstream servers are powered by in-rack batteries. But power transitions occasionally fail, resulting in a total power loss.
Power loss events contribute to a significant portion of all correlated unplanned server outages. Power loss events happen less often at higher-level power devices. However, bigger events affect many more servers.
The PLS architecture and event flow
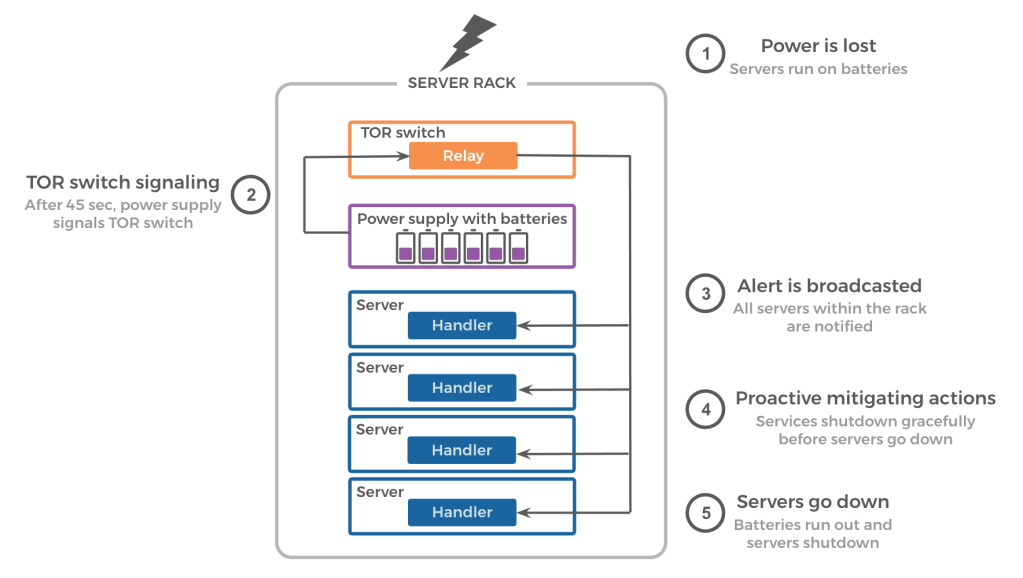
A server rack consists of several servers interconnected by a top-of-rack (TOR) switch. Racks also have power supply units and battery backup units. Power supply units convert input AC power to DC power for servers. Battery backup units can provide 90 seconds of backup power during input AC power loss.
PLS has two major components:
- PLS Relay (detection): PLS Relay is a monitoring daemon that runs on all rack switches. It continually monitors power supply units for input AC power loss. If an outage is detected, PLS relay alerts all servers within the rack about an impending power loss event at least 45 seconds in advance.
- PLS Handler (mitigation): PLS Handler is a listener daemon running on all servers. It receives alerts from the PLS Relay, while the entire rack runs on battery power. It then initiates a configurable handler to mitigate the impending server outage.
PLS Relay runs on all TOR switches, and PLS Handler runs on all servers. As such, both daemons need to be simple to maintain, resource efficient, and highly reliable in detecting power loss events. It’s also worth noting that all PLS detection software runs locally on the rack. Not having to depend on remote systems helps ensure high reliability and low latency in power loss detection and alerting. The service owners configure the mitigation handler, which varies depending on what services happen to be running on the server when a power loss occurs.
Here’s how the PLS mitigation flow works during a power loss event:
- Power loss: A power loss at an upstream power device causes server racks to lose input AC power. In-rack batteries discharge to continue supporting the switch and servers. As noted earlier, batteries can support rack power for 90 seconds.
- Rack switch signaling: If the rack’s input AC power isn’t restored within 45 seconds, power supplies assert a signal to the switch to indicate imminent power loss. The 45-second wait is to account for expected power transition during power device maintenance or utility power failover to backup generators.
- Alert broadcast: PLS Relay continually polls the power loss signal from the power supply. When it notices that the signal has been asserted, it sends a link-local UDP multicast to alert all servers.
- Mitigation action: PLS Handlers are continuously listening for UDP alerts and execute mitigation handlers configured by services running on the server.
- Server power loss: Finally, 90 seconds after initial rack AC power loss, batteries run out and all servers in the rack lose power.
How PLS improves service reliability
Here’s a look at how PLS helps mitigate the impact of power loss events on two of Meta’s services:
PLS and single primary databases
Meta’s user data storage (posts, likes, comments, etc.) is deployed as a geo-distributed MySQL system. Data is sharded, with each shard having a primary instance and multiple secondary instances. This forms a replica set, distributed globally across different data centers. A given server hosts multiple instances, which may be a mix of primary and secondary instances of different shards.
MySQL directs read actions (browsing posts, comments, etc.) to either a primary or a secondary instance. MySQL directs write actions (posts, likes, comments, etc.) to the primary instance. The primary asynchronously streams write actions to the shard’s secondaries. The primary instance also streams transaction logs to the log backup units (LBU). After completing the write to its own storage and receiving a write acknowledgement from at least one LBU, the primary instance sends a write success signal back to the client. MySQL allocates LBUs under a different root power device (MSB) to avoid data loss during unplanned primary outages.
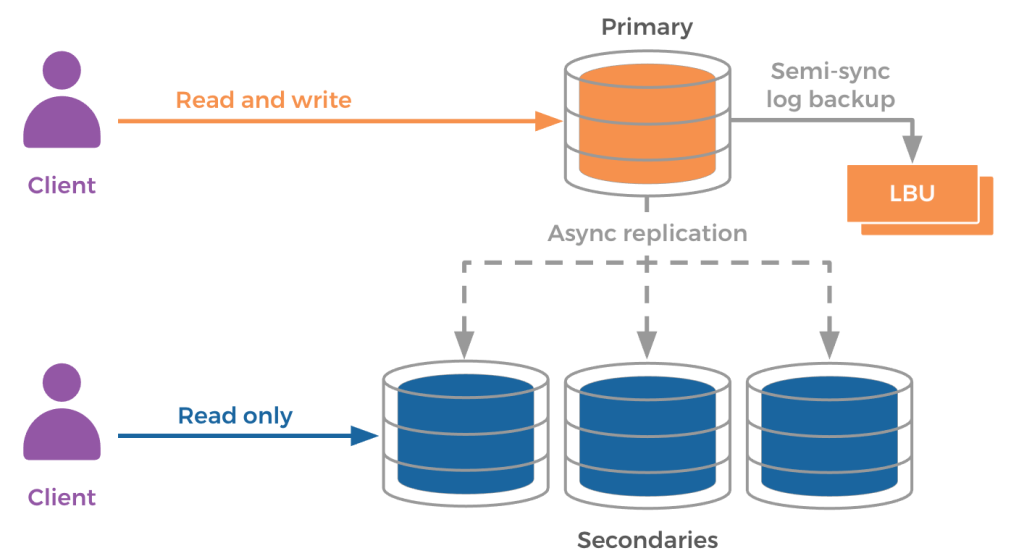
When an unplanned server outage occurs, all the primaries hosted on it become unavailable for writes. Without the primary, write actions fail. Recovery is automatic — the secondaries initiate a promotion sequence when they notice they’re not able to transmit heartbeats to the primary. For each unavailable primary, MySQL picks a remote secondary (in a different data center region) as the primary candidate. The candidate catches up to the latest update in the LBUs. Then, the candidate becomes the new primary. MySQL directs all new write requests to the newly elected primary. In total, failure detection by the secondaries, followed by promotion, takes on the order of tens of seconds.
A large-scale, unplanned outage that affects servers hosting primary shards can impact features like posting, liking, and commenting. MySQL uses PLS to proactively promote a remote secondary for every primary that is experiencing a power loss. Since PLS offers a high-quality signal about an impending power loss event, we don’t need to make multiple attempts at connecting to a dead server before deciding it’s unhealthy. As we prepare the remote secondary to take on the role of the primary, the previous primary still processes write requests since it’s running on battery power. There’s a small amount of downtime to switch roles from the old to the new primary, but it’s effectively invisible to the end user.
PLS and web servers
The web tiers at Meta consist of servers that serve all page loads on all platforms (Android, iOS, and web browser) for Meta and internal web applications. They have a presence in all Meta data centers. Web servers are stateless PHP servers that serve web content. A reverse proxy fronts the web tier, whose responsibilities include security (e.g., TLS handshake), load balancing, caching, compression, etc.
When an unplanned outage affects a web server, we lose all requests, whether queued or being processed. These manifest as timeouts — leading to longer latencies for page loads because of retries or even outright application errors.
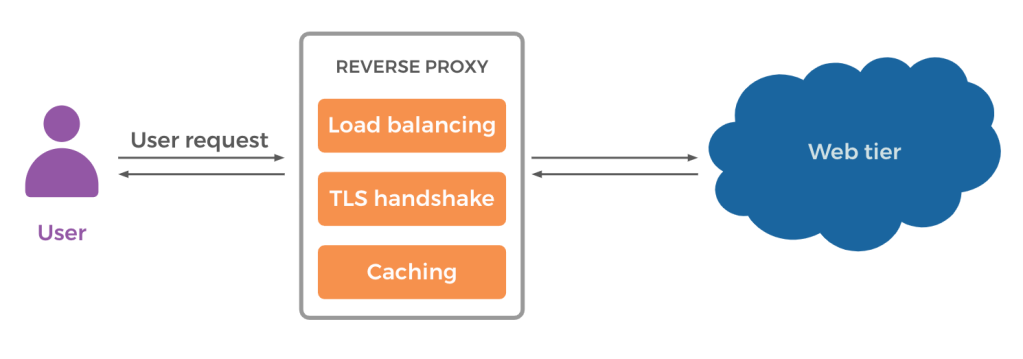
With PLS alerts, we stop sending new requests to the affected servers. To achieve this, the server begins a graceful shutdown. It also reports a bad health metric to the load balancer to avoid receiving any new requests. As a web server shuts down in response to PLS, it continues servicing requests either queued or being processed until the battery backup power runs out.
In large-scale power loss events, the peak error rate can spike to up to hundreds of thousands of requests per second. Overall, leveraging PLS signals reduces the peak error rate during power loss events to a few thousand errors per second (a 100x reduction).
How PLS simplifies physical infrastructure management
Historically, certain sections of Facebook’s data centers were built as dual-powered rows for server racks to support data storage (for higher reliability). These rows of server racks plug into two independent power outlets that possess independent power sources within the data center. If the primary power source suffered a power loss, switching infrastructure would automatically feed power from the secondary source.
Dual-powered rows protected services against the most common cause of power loss events — row power device failures. However, they didn’t solve other practical problems and forced certain capacity requirements. Specifically, they didn’t address:
- Limited power redundancy: Dual-powered rows only had redundant power sources up to the SB level of the power delivery tree. Although less frequent, a power loss at the MSB level would affect these rows.
- Additional server buffer requirements: To sustain services during power loss events, we allocate additional buffer server capacity. With dual-corded rows, all storage racks running MySQL are placed within the same row within the same MSB. This required sites to have an entire row’s worth of storage racks as buffer capacity in case the corresponding MSB lost power.
- Power underutilization: For power devices feeding a dual-powered row, the power budget for racks gets double counted because of the two pathways feeding the same row. Only one power source actively feeds the racks, while the other half is wasted.
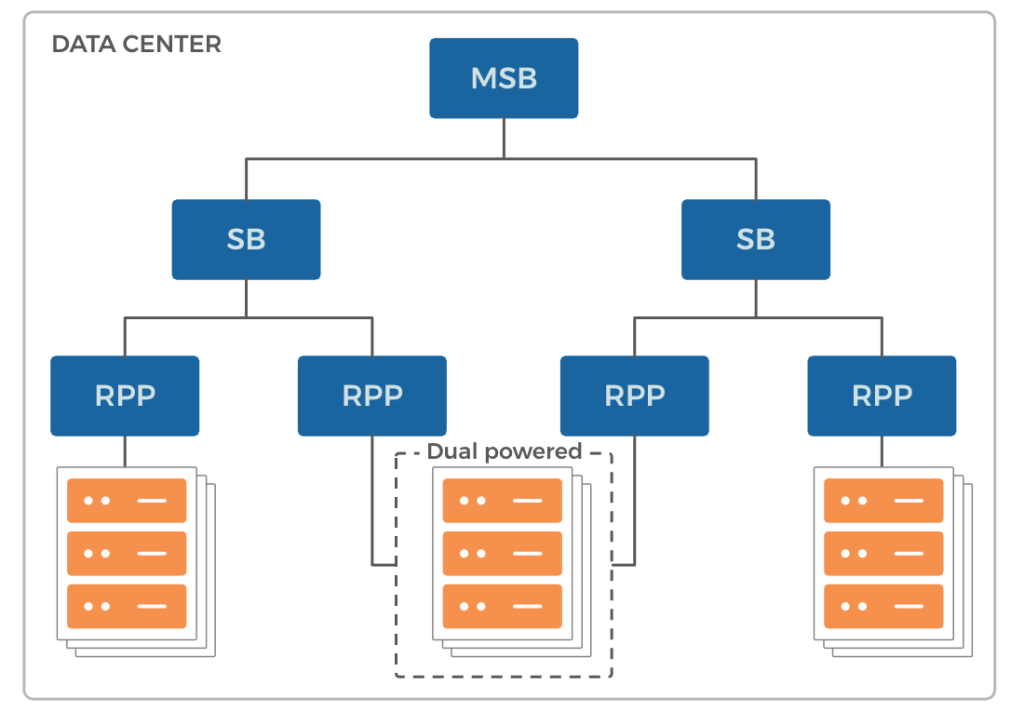
PLS support automatically handles row- and MSB-level power loss events. As a result, we no longer need to build and maintain dual-powered rows. Also, without the constraints to place storage racks hosting MySQL on dual-corded rows, we can uniformly distribute them across the data center. This improves fault tolerance and reduces additional buffer requirements.
Future work: Tackling the ongoing challenge of power loss events
As our data center fleet grows, so will our need to mitigate the impact of power loss events. With these challenges in mind, we are actively exploring more applications for PLS and onboarding new services to it. Some of our ongoing efforts include:
- Improving resource efficiency: Tectonic is Meta’s distributed file system service used for large-scale applications like media and data analytics storage. Presently, Tectonic flushes disk cache on every permanent write. This ensures durability against possible unplanned power loss events that would wipe unflushed disk caches. With PLS, flushes can be deferred until there’s an AC power loss. This would allow write coalescing — issuing larger writes to disk after buffering data in disk caches. Our preliminary experiments indicate there’s significant I/O efficiency potential here — about 13 percent reduction in disk utilization and an approximately 50 percent reduction in write latency.
- Handling data center–wide loss events: Currently, PLS can scale up to an MSB-sized power loss event for all our client services. In the current generation of our server racks, we had to design PLS to leverage the existing battery design already present on the racks. In future data center rack designs, we’re planning to increase battery capacity to handle data center–wide power loss events.








