
As our infrastructure has expanded, we have seen an exponential growth in failures that affect a subset of capacity in a data center. These may stem from software or firmware errors, or issues in the mechanical or electrical equipment in the data center. As our data center footprint grows, so does the frequency of such incidents. To enable our infrastructure to be resilient to these failures, we have started optimizing our workload placement, or how we place hardware, services, and data across our fleet.
In 2017, for example, there was an incident in our Forest City, North Carolina, data center where a snake crawled into the power infrastructure and caused a short in a main switchboard power device, and took down 3 percent of the data center’s capacity. Although 97 percent of capacity was not affected, this incident still caused user-visible errors. We had to redirect user traffic away from this entire data center.
Why would losing such a small amount of capacity in one data center cause more widespread problems? As we investigated, we realized it was due to unfortunate workload placement. It turned out, the 3 percent of servers that went down just happened to be running most of the capacity for some important software systems that supported user-facing products. To minimize the impact, we had to redirect traffic away from this data center. In this and other failure incidents, a fault that affected only a small percentage of a data center’s servers sometimes resulted in our losing an entire data center’s worth of capacity as we shifted user traffic away.
Facebook’s disaster recovery model accounts for this loss in capacity. In a pinch, we can continue to run our products if we lose one entire data center. We maintain and run a spare data center as a buffer. However, as our infrastructure expands, and as we build more data centers around the world, we are seeking an approach to fault tolerance that scales better. We must be able to survive the loss of a sub-data center fault domain without having to drain user traffic and lose the entire data center’s capacity.
Buffer capacity
A fault domain represents the amount of capacity we can lose without causing larger problems. We selected our fault domain based on the physical and logical design of our data center, and by considering the most common types of failures we see in our infra. Each data center comprises dozens of these fault domains.
To safeguard against the loss of a fault domain, which affects only a small portion of capacity in a data center, we need to purchase and maintain enough buffer capacity to cover what we lose. If we have enough, the loss of a fault domain simply means affected workloads would move to run on the buffer capacity. We would no longer need to redirect traffic out of the entire data center for sub-data center faults.
How much buffer we need depends on how our workloads are placed within a data center. Different workloads have different hardware needs. Some require high-compute machines, while others may need high-storage or high-memory machines. This heterogeneity means we would need to purchase more buffer capacity if hardware and services were not well spread out across fault domains.
Optimal workload placement
Imagine the following simplified scenario, where we have three different types of hardware across three fault domains. If the hardware is not spread evenly across all fault domains, as in the image below, we would need to maintain 150 machines as a buffer.
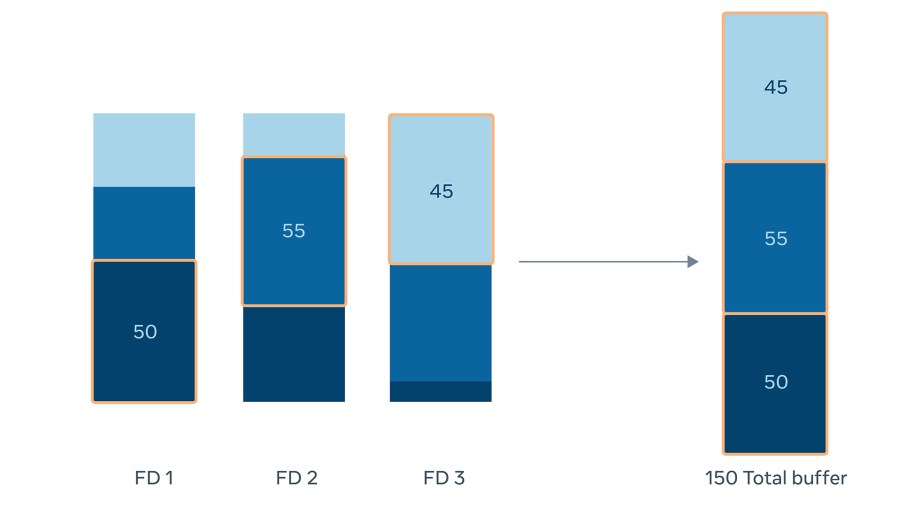
However, when we spread the same amount of hardware evenly across all fault domains, we need only 100 machines as a buffer, as shown below: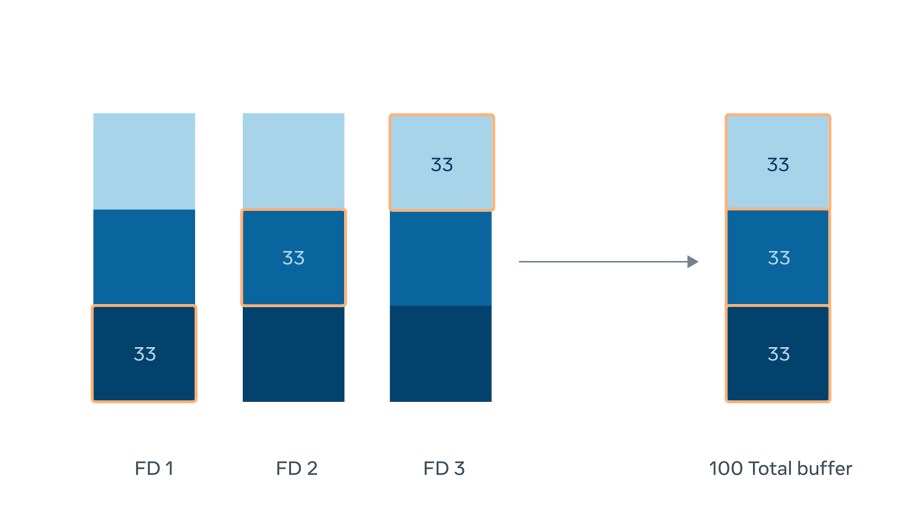
To keep buffer usage down in this way, we needed to ensure optimal placement and spread of our workloads across all fault domains. We must solve for this placement at multiple levels of our infrastructure stack and provide certain guarantees:
- Hardware must be well placed to give services enough flexibility to achieve good spread.
- Our services and workloads themselves must be spread evenly across this hardware.
- For stateful services, purely spreading service instances is not enough if their data shards are concentrated under one fault domain. We need to ensure good placement of the data as well.
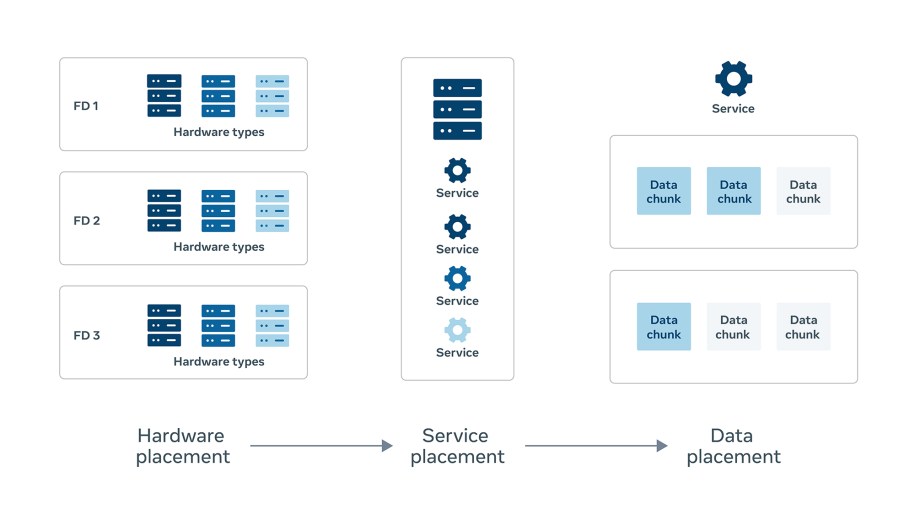 We have built systems to spread out our workloads across fault domains and provide these placement guarantees and invariants at each level of our infrastructure stack. With optimal placement, and by maintaining one fault domain’s worth of buffer capacity, we can tolerate sub-data center faults without redirecting traffic away from the entire data center.
We have built systems to spread out our workloads across fault domains and provide these placement guarantees and invariants at each level of our infrastructure stack. With optimal placement, and by maintaining one fault domain’s worth of buffer capacity, we can tolerate sub-data center faults without redirecting traffic away from the entire data center.
Hardware placement
Hardware is the first level where we must get placement right. Our data centers consist of many different types of server racks (like compute, storage, and flash/SSD), each of which meets the needs for different classes of services. To give our systems the flexibility to achieve optimal placement, we must ensure that each rack type is spread evenly across as many fault domains as possible.
Facebook’s hardware capacity planning runs on a quarterly cycle. Every three months, we determine how many racks and which rack types we need to purchase for each data center. Each data center consists of multiple data halls. When placing incoming racks, we fill a data hall with racks before moving on to the next one. Each quarter, we fill one or two data halls, cycling through the entire data center every few years.
Our systems map incoming racks to a precise physical location, down to their data hall, row, and position in their row. Data center space, power, network, thermal effects, and, of course, spread across fault domains are all factored in when deciding on this physical placement. However, there are dozens of constraints that must be satisfied for each rack as we determine its placement. We use integer linear programming systems to compute the best plan to ensure that we build an optimal placement solution.
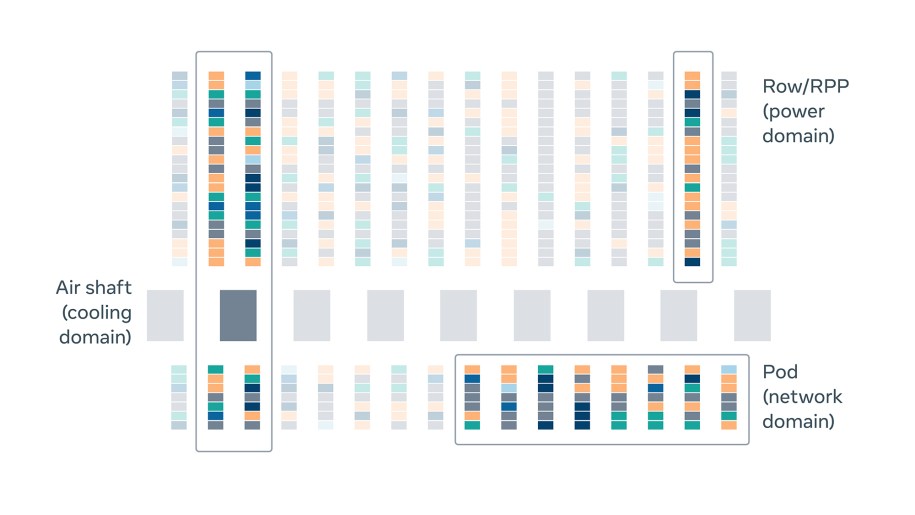 Spread
Spread
Having an even spread across fault domains is an important objective, because it allows our system to tolerate sub-data center faults. Our systems spread incoming capacity across all fault domains in the data halls that are receiving racks in that quarter, while also satisfying our other constraints and objectives. The diagram below clearly shows the difference between the spread of one of our rack types before and after we optimized our systems.
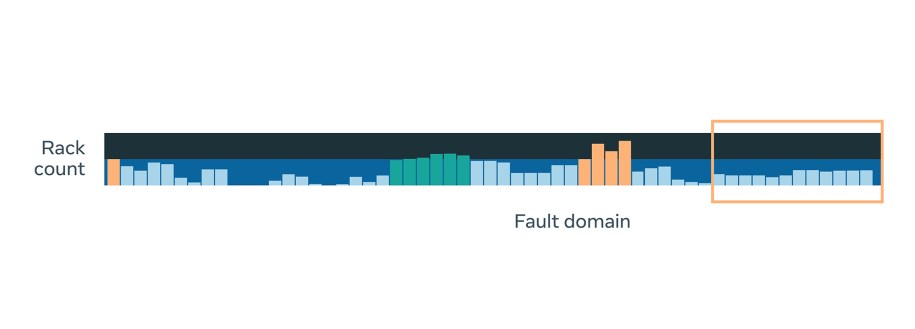
Challenges
While spread across fault domains is now much closer to optimal, there are still several factors that work against creating a perfectly even spread. Two such factors are:
- Changing demand for capacity: The racks we need to purchase each quarter are determined in part by the demand that different services and workloads have for hardware. This demand is uneven. We may need to purchase more compute racks in one quarter and more storage racks in the next. While we may still achieve even spread within the data hall that we are filling, this creates imbalance across different halls. This means a data hall that we filled two quarters ago may have a very different spread than one we are filling now.
- Evolving data center designs: Since our data centers designs are constantly evolving, data centers or data halls constructed at different times have different power hierarchies, network designs, and cooling infrastructures. These differences hinder our goal of even spread across fault domains, since each domain may support a different capacity.
We are constantly improving our placement systems, capacity planning processes, and data center designs to ensure that we are able to achieve optimal placement.
What about old or existing capacity?
While we ensure that all new capacity entering our data centers is optimally placed, there are still many older data halls or fault domains that were filled years ago. This older capacity was not placed to optimize for even spread, or to satisfy other, newer constraints. To alleviate this and achieve fault tolerance without an inordinate amount of buffer capacity, we perform physical rack moves.
Our systems compute moves that are required to achieve good placement in these older parts of our data centers. This computation considers all the latest objectives and constraints, including even spread across fault domains. Performing these rack moves is not easy. They involve coordination across many different teams, including teams on site that perform the physical moves, service owners that drain the racks of any workloads they are currently running, and teams that build automation for various data center processes.
With the combination of our systems ensuring that new capacity is well placed, and performing the required rack moves for older capacity, we can achieve optimal hardware placement.
Service placement
Once hardware is well placed, we need to ensure that services are as well. Services and workloads also need to be evenly spread across fault domains while satisfying other constraints. We need to not only ensure that newly allocated capacity is placed correctly, but also fix older, existing capacity. This is the next step toward tolerating the loss of a fault domain without impractical amounts of buffer capacity.
New service capacity
Service owners request additional capacity as their workloads grow and expand. When allocating this new service capacity, our systems consider multiple constraints and objectives. As with hardware placement, we prioritize service spread across fault domains. But we must also satisfy other constraints, such as specific hardware requirements or affinity between two or more services. Some of these are specific to certain services or workloads and may work against our goal of an even spread.
- Specific hardware requirements: Some services have very specific requirements for what hardware they run on. They not only need a specific rack type (compute, storage, etc.) but also may be optimized for, and require, a specific CPU generation. This presents a problem for optimal spread across fault domains because a particular CPU generation may only be present in a few data halls, depending on when those racks were purchased. This limits the spread we can achieve for these services.
- Service affinities: Our infrastructure contains some groups of services that work closely together. These services might exchange a lot of network traffic, for example, or need reliably low latency for their communication. For these services, it’s sometimes advantageous to colocate them in the same network domain in a data center. Once again, this need works against the goal of even spread across fault domains, since it limits where we can place these services.
We are working with services to help understand these requirements, evolve our placement systems to consider these effectively, and support any extra buffer we may need.
Continuous rebalancing to maintain optimal workload placement
Our placement-aware service allocation systems will ensure new capacity is placed well. However, service capacity that was allocated before these considerations was not spread evenly across fault domains. To remedy this, we have had to shift services around, executing moves and swaps to rebalance them evenly across fault domains. We need to execute hundreds of thousands of these moves to fix the placement of such older service capacity.
This rebalancing is not a one-time event, though. Our infrastructure is constantly in flux. New data center capacity is brought up, old capacity is decommissioned, and machines suffer failures. We need to watch for these changes in our infrastructure and react to re-achieve optimal placement. For example, when a new data hall is turned up in a data center, we need to consider these new fault domains, and ensure that we balance existing service capacity across these new fault domains as well as the older ones they currently occupy.
Data placement
With good hardware and service placement, and with sufficient buffer capacity, workloads that do not need to maintain state will be able to tolerate sub-data center faults. But this is not enough for stateful services, like blob storage or data warehouses. They need to ensure that their data is thoughtfully placed as well. It’s not enough that the hardware and service instances are spread evenly if all the master shards or replicas of data are under the same fault domain.
Failures cause challenges for stateful services in multiple ways:
- Some stateful services may choose to fail in place. That is, instead of moving to buffer capacity when a failure occurs, they will assimilate and run their buffer capacity as part of normal operation. When a failure happens, they can tolerate the loss of one fault domain without needing any data migration. However, they must be careful to spread data shards evenly. This strategy will not work if all replicas of a shard are under the same fault domain, for example.
- Other stateful services may choose to migrate data to buffer capacity when a failure occurs. Migrating data or rebuilding it from other sources is an expensive and cumbersome operation. It may consume precious resources, like I/O or network bandwidth. If possible, it’s preferable to place shards such that, when a fault domain is lost, the number of shards requiring these expensive operations is minimized.
Shard Manager, our centralized replica management system, is fault domain aware. When deciding how to assign shards to different service instances, its algorithms achieve the best possible spread of shards across fault domains. This helps stateful services survive sub-data center faults without interruption.
Sub-data center fault tolerance
With optimal placement of hardware, services, and data, and with one fault domain’s worth of buffer capacity, workloads are set up to tolerate sub-data center faults without any impact on people who use Facebook.
To see how this works in the case of a failure, let us consider services running across four fault domains.
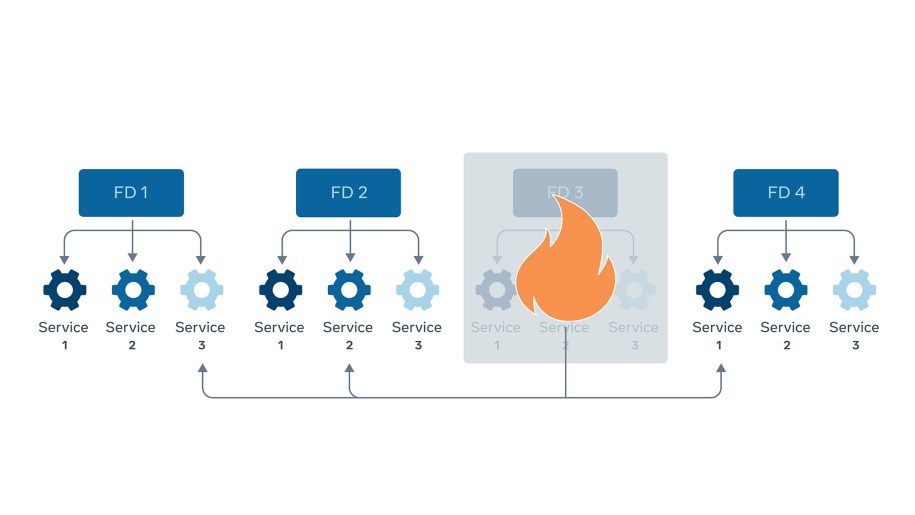 When FD3 fails, workloads running under it will need to move to run on the buffer capacity placed in other fault domains. The buffer capacity is pre-allocated to services and is itself spread across fault domains. So, services don’t need to request or provision it at the time of failure. They can immediately fail over to this capacity and continue service traffic with only minimal interruption.
When FD3 fails, workloads running under it will need to move to run on the buffer capacity placed in other fault domains. The buffer capacity is pre-allocated to services and is itself spread across fault domains. So, services don’t need to request or provision it at the time of failure. They can immediately fail over to this capacity and continue service traffic with only minimal interruption.
Infrastructure as a Service
Optimal placement allows us to abstract the data center and resources away from workloads, while providing a set of guarantees around failures, maintenance, power, network, and other areas. It allows us to provide our infrastructure as a service.
These placements also allow us to operate our infrastructure in a predictable manner and make other processes more efficient. For example, if we can tolerate the loss of any one fault domain, we can use this concept to streamline and improve how we perform maintenance in our data centers.
We can define maintenance as any event that leads to a loss in capacity. It can span the range from physical or mechanical device repairs or upkeep work to software maintenance like kernel or firmware upgrades.
The old way of performing such maintenance involved a manual and time-consuming process. To upgrade the firmware on a top-of-rack switch, for example, we would have to manually reach out to every service owner that had software running on that switch. They would need to be notified of the maintenance schedule and vacate this capacity by migrating their software to another rack.
With the fault tolerance that optimal placement enables, we can simply treat maintenance as another form of sub-data center failure. Since we can tolerate the loss of any one fault domain, we can simulate a failure and perform maintenance on all the infrastructure under that fault domain together.
We can then cycle through each fault domain in a data center and batch process maintenance for all capacity under each fault domain. This helps us perform data center and capacity maintenance in a predictable manner and at a greater speed than before.
Conclusion
Our placement systems help us provide strong assurances about how we run workloads in our data centers. With thoughtful and optimal placement of hardware, services, and data, our systems can tolerate sub-data center faults without the need to maintain an additional data center’s worth of buffer capacity.
We are still early in our quest for optimal placement. Our current primary goal is to spread workloads evenly across fault domains. But in the future, we can use the same systems to optimize for other aspects of our data center. For example, we can reduce network bandwidth utilization by considering network domains when placing workloads. Or, we can avoid thermal hotspots in our data center by avoiding placing workloads that run hot in tight clusters. With the fine control that our placement systems provide, we can even start stacking complementary workloads on the same machine to use our resources more efficiently.








