
- We’re sharing insights into Meta’s Capacity Efficiency Program, where we’ve built an AI agent platform that helps automate finding and fixing performance issues throughout our infrastructure.
- By leveraging encoded domain expertise across a unified, standardized tool interface these agents help save power and free up engineers’ time away from addressing performance issues to innovating on new products.
We’ve built a unified AI agent platform that encodes the domain expertise of senior efficiency engineers into reusable, composable skills. These agents now automate both finding and fixing performance issues, recovering hundreds of megawatts (MW) of power and compressing hours of manual regression investigation into minutes, enabling the program to scale MW delivery across a growing number of product areas without proportionally scaling headcount.
On defense, FBDetect, Meta’s in-house regression detection tool, catches thousands of regressions weekly; faster automated resolution means fewer megawatts wasted compounding across the fleet. On offense, AI-assisted opportunity resolution is expanding to more product areas every half, handling a growing volume of wins that engineers would never get to manually. Together, this is how Meta’s Capacity Efficiency Program keeps growing MW delivery without proportionally growing the team. The end goal is a self-sustaining efficiency engine where AI handles the long tail.
Here’s how it works and where we’re headed:
- Efficiency at hyperscale requires both offense (proactively finding optimizations) and defense (catching and mitigating regressions that make it to production); AI can accelerate both.
- We’ve built a unified platform where standardized tool interfaces combine with encoded domain expertise to automate investigation on both sides.
- These AI systems are now the infrastructure for the Capacity Efficiency program, which has recovered hundreds of megawatts of power, enough to power hundreds of thousands of American homes for a year.
- Automating diagnoses can compress ~10 hours of manual investigation into ~30 minutes, while AI agents fully automate the path from efficiency opportunity to ready-to-review pull request.
Introducing the Capacity Efficiency Program
When the code you ship serves more than 3 billion people, even a 0.1% performance regression can translate to significant additional power consumption.
In Meta’s Capacity Efficiency organization, we see efficiency as a two-sided effort:
- Offense: searching for opportunities (proactive code changes) to make our existing systems more efficient, and deploying them.
- Defense: monitoring resource usage in production to detect regressions, root-cause them to a pull request, and deploy mitigations.
These systems worked well and have played an important role in Meta’s efficiency efforts for years. However, actually resolving the issues they surface introduces a new bottleneck: human engineering time.
This human engineering time can be spent on any of the following activities:
- Querying profiling data to find opportunities to optimize hot functions.
- Reviewing an efficiency opportunity’s description, documentation, and past examples to understand the best approach for implementing an optimization.
- Checking recent code and configuration deployments that could have caused a step change in resource usage.
- Looking through recent internal discussions about launches that might have been related to a regression.
Many engineers at Meta use our efficiency tools to work on these problems every day. But no matter how high-quality the tooling is, engineers have limited time to address performance issues when innovating on new products is our top priority.
We started asking: What if AI could handle investigation and resolution?
Offense and Defense Share the Same Structure
The breakthrough was realizing that both problems share the same structure:
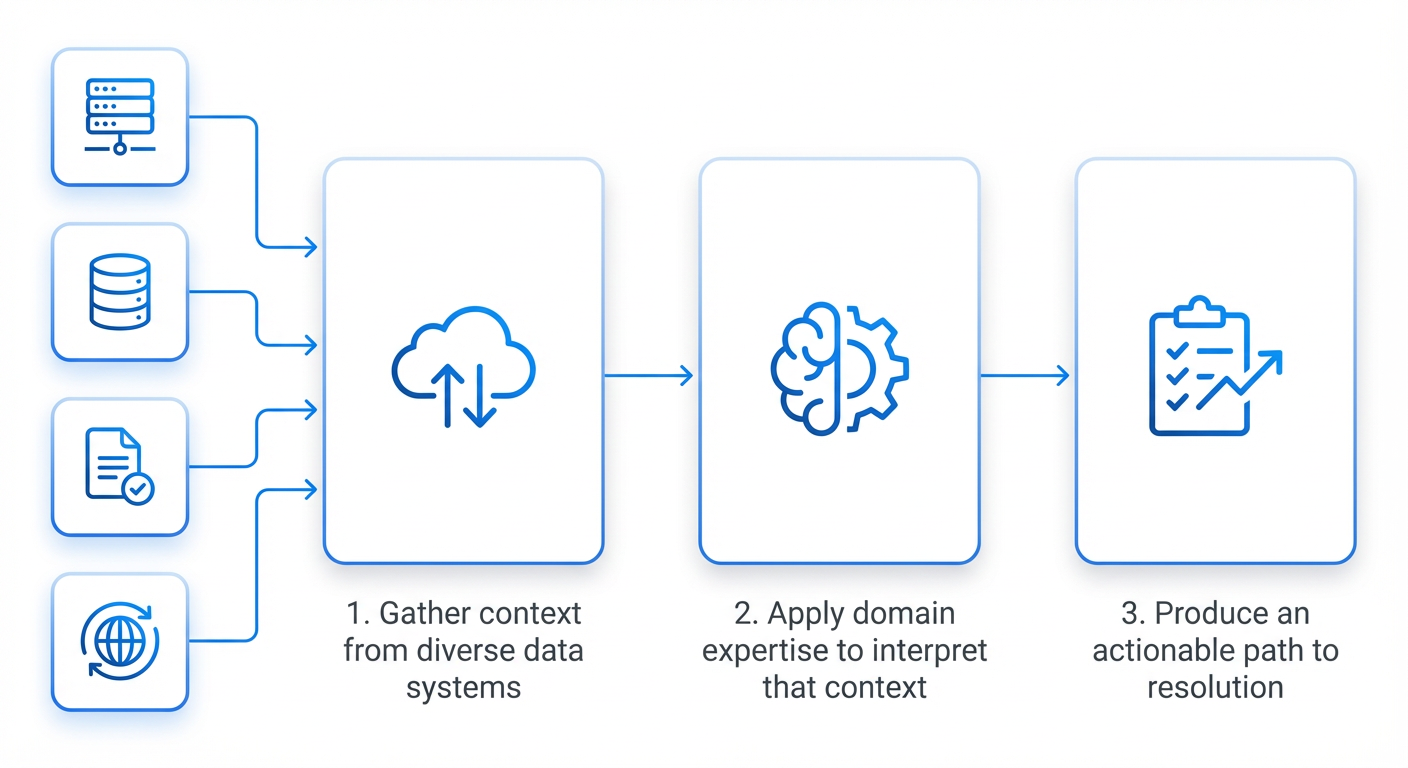 This meant we didn’t need two separate AI systems. We needed one platform that could serve both.
This meant we didn’t need two separate AI systems. We needed one platform that could serve both.
We built it on two layers:
- MCP Tools: These are standardized interfaces for LLMs to invoke code. Each tool does one thing: query profiling data, fetch experiment results, retrieve configuration history, search code, or extract documentation.
- Skills: These encode domain expertise about performance efficiency. A skill can tell an LLM which tools to use and how to interpret results. It captures reasoning patterns that experienced engineers developed over years, such as “consult the top GraphQL endpoints for endpoint latency regressions” or “look for recent schema changes if the affected function handles serialization”
Together, tools and skills promote a generalized language model into something that can apply the domain expertise typically held by senior engineers. The same tools can power both offense and defense. Only the skills differ.
Defense: Catching Regressions Before They Compound
FBDetect is Meta’s in-house regression detection tool that can catch performance regressions as small as 0.005% in noisy production environments. It analyzes time series data like this:
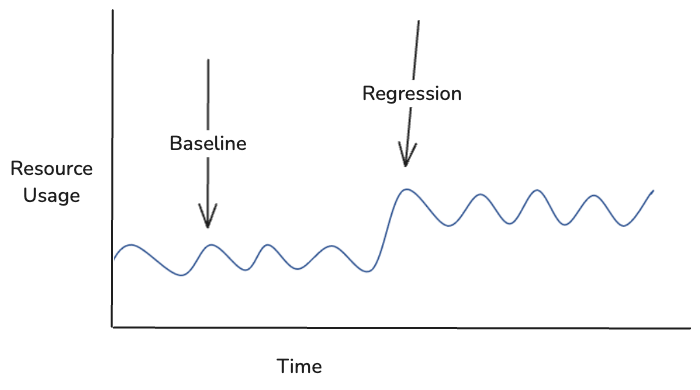
When FBDetect finds a regression, we immediately attempt to root-cause it to a code or configuration change; this is a vital first step to understand what happened. It’s done primarily with traditional techniques such as correlating regression functions with recent pull requests. After a root cause is determined, engineers are typically notified and expected to take action, such as optimizing the recent code change. We’ve added an additional feature to make this faster:
AI Regression Solver
Our AI Regression Solver is the newest and most promising component of FBDetect, which produces a pull request to fix forward the regression automatically. Traditionally, root-causes (pull requests) that created performance regressions were either rolled back (slowing engineering velocity) or ignored (increasing infrastructure resource use unnecessarily).
Now, our in-house coding agent is activated to do the following:
- Gather context with tools: find the symptoms of the regression, such as the functions that regressed; look up the root cause (a pull request) of the regression, including the exact files and lines changed.
- Apply domain expertise with skills: use regression mitigation knowledge for the particular codebase, language, or regression type. For example, regressions from logging can be mitigated by increasing sampling.
- Create a resolution: produce a new pull request and send it to the original root cause author for review.
Offense: Turning Opportunities Into Shipped Code
On the offensive side, “efficiency opportunities” are proposed conceptual code changes that are believed to improve performance of existing code. We built a system where engineers can view an opportunity and request an AI-generated pull request that implements it. What used to require hours of investigation now takes minutes to review and deploy.
The pipeline mirrors the defensive AI Regression Solver:
- Gather context with tools: The AI agent looks up:
- Opportunity metadata.
- Documentation explaining the optimization pattern.
- Examples showing how similar opportunities were resolved.
- The specific files and functions involved.
- Validation criteria for confirming the fix works.
- Apply domain expertise with skills: use expert engineers’ knowledge on a specific type of efficiency opportunity, encoded into a skill. For example, memoizing a given function to reduce CPU usage.
- Create resolution: produce a candidate fix with guardrails, verify syntax and style, confirm it addresses the right issue. Surface the generated code in the engineer’s editor, ready to apply with one click.
Importantly, we use the same tools as defense: profiling data, documentation, code search. What differs is the skills.
One Platform, Compounding Returns
Our unified architecture with shared tools and data sources has been a clean abstraction. Each existing and new agent has an easy way to gather context about performance with the interfaces we’ve made, without the need to reinvent the wheel.
This post focused on our first use cases: performance regressions and opportunities. Within a year, the same foundation powered additional applications: conversational assistants for efficiency questions, capacity planning agents, personalized opportunity recommendations, guided investigation workflows, and AI-assisted validation. Each new capability requires few to no new data integrations since they can just compose existing tools with new skills.
Impact
The results of the Capacity Efficiency program are significant: We’ve recovered hundreds of megawatts of power. The AI systems for both offense and defense contribute to supporting this effort.
But the deeper change is in how offense and defense reinforce each other: Engineers who spent mornings on defensive triage now review AI-generated analyses in minutes. Engineers using our efficiency tools can now get AI-assisted code instead of starting from scratch. The daunting question of “where do I even start?” has been replaced by reviewing and deploying high-impact fixes.








