
At Facebook we use MySQL to manage many petabytes of data, along with the InnoDB storage engine that serves social activities such as likes, comments, and shares. While InnoDB provides great performance and reliability for a variety of workloads, it has inefficiencies on space and write amplification when used with flash storage. A few years ago, we built RocksDB, an embeddable, persistent key-value store for fast storage that has several advantages compared with InnoDB for space efficiency.
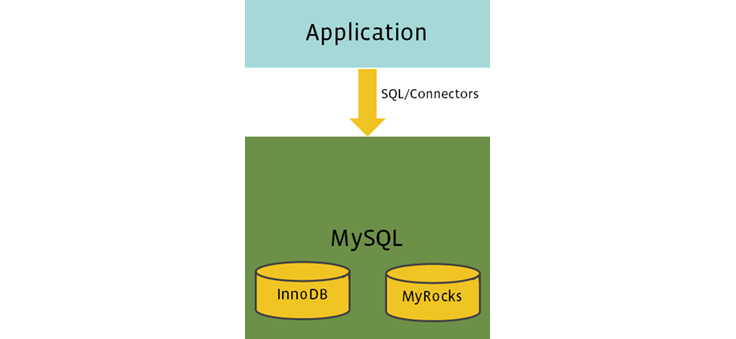
Despite its advantages, RocksDB does not support replication or an SQL layer, and we wanted to continue using those features from MySQL. This led us to build MyRocks, a new open source project that integrates RocksDB as a new MySQL storage engine. With MyRocks, we can use RocksDB as backend storage and still benefit from all the features in MySQL.
While there are some databases at Facebook that will still use InnoDB, we’re in the process of migrating to MyRocks on our user database (UDB) tier. After deploying MyRocks to this database tier in one of our data center regions, we were able to use 50 percent less storage for the same amount of data compared with compressed InnoDB. Ultimately this will allow us to use half as many UDB servers. By sharing MyRocks with the community through open source, we hope that others can take advantage of these efficiencies.
MySQL & InnoDB
There are many reasons why we use MySQL at Facebook. MySQL is amenable to automation, making it easy for a small team to manage thousands of MySQL servers while providing high-quality service. The automation includes backup, restore, failover, schema changes, and replacing failed hardware. MySQL also has flexible and extensible replication features, including asynchronous replication and lossless semi-synchronous replication, which makes it possible to do failover without losing data.
MySQL with InnoDB is effective for online transaction processing (OLTP) workloads with high concurrency and many short-running operations. Most of the SQL statements we use — insert, update, delete, point lookup, and range scan with index-only read — are done in less than 1 millisecond when using flash storage. Overall, we’ve experienced many benefits with MySQL and InnoDB.
However, there are also some inefficiencies with InnoDB. For example, although flash storage devices are widely used for OLTP workloads, we are limited to less storage. While our database engineering team worked to make compressed InnoDB performant for read-write workloads, which reduced the size of our UDB tier by approximately 40 percent, we wanted to make further improvements beyond what was possible with InnoDB.
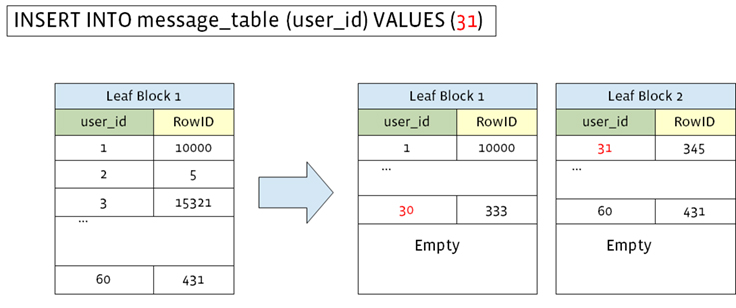
Flash is also limited by write endurance. For our common workloads, where index values are stored in leaf nodes and sorted by keys, the database working set doesn’t fit in memory and keys are updated in a random pattern, leading to a write amplification. In the worst case, updating one row requires a number of page reads, makes several pages dirty, and forces many dirty pages to be written back to storage. In addition, InnoDB writes dirty pages to storage twice to support recovery from partial page writes on unplanned machine failure. We also implement online defragmentation, which periodically scans InnoDB leaf pages where indexes are only 50 percent full and rewrites them, which further increases write amplification.
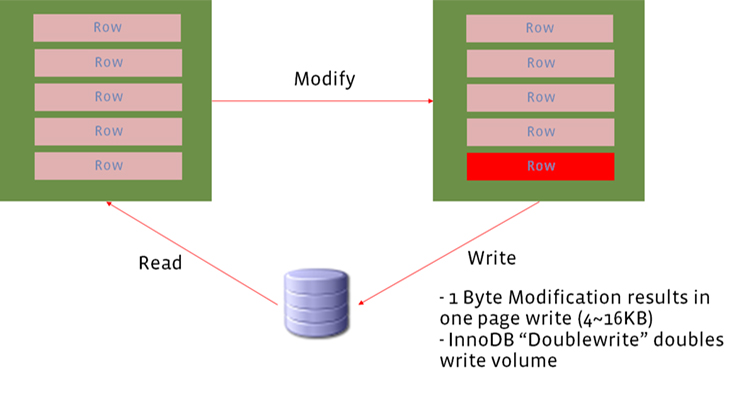
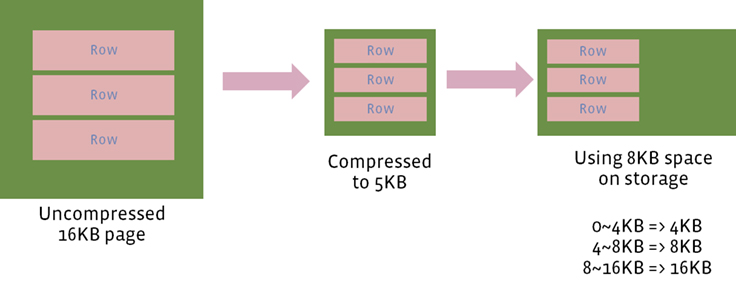
Finally, InnoDB is constrained by a fixed compressed page size. The fragmentation and compression alignment results in extra unused space because the leaf nodes are not full. Assume a table with a compressed page size of 8 KB. A 16 KB in-memory page compressed to 5 KB still uses 8 KB on storage. In addition, each entry in the primary key index has 13 bytes of metadata (6 byte transaction id + 7 byte rollback pointer), and the metadata is not compressed, making the space overhead significant for small rows.
In short, InnoDB is great for performance and reliability, but there are some inefficiencies on space and write amplification with flash. To help optimize for more storage efficiency, we decided to investigate an alternative space- and write-optimized database technology.
MyRocks: A RocksDB storage engine with MySQL
RocksDB is an embedded database, written in C++, and widely used on its own within Facebook. We wanted to continue to use MySQL while benefiting from the storage efficiency of RocksDB. When we started researching the RocksDB and MySQL integration in 2014, we found that it had several advantages compared with InnoDB.
Some noteworthy advantages include:
- Compression efficiency: One of the biggest reasons RocksDB compresses better than InnoDB is that it does not use fixed page sizes. When a page is compressed to 5 KB, it will use only 5 KB of storage, compared with 8 KB with InnoDB.
- Append-only and compaction: RocksDB uses a smaller number of sequential reads and writes because access patterns for writes are maintained in a persistent key-value store based on log-structured merge-trees (LSM), derived from LevelDB. This allows us to use less storage I/O capacity per update because we no longer need to do a large number of random reads and writes that other indexing structures, such as B+ Tree, would require.
- Prefix key encoding and zero-filling metadata: We frequently use multi-column indexes to support covering secondary indexes. RocksDB trims identical prefix bytes when possible, which can save a lot of space. In addition, RocksDB has metadata per key/value, whereas InnoDB has metadata per record. InnoDB metadata is 13 bytes per record (6 byte transaction identifier and 7 byte rollback pointer), and is not compressed. RocksDB metadata consists of 7 byte sequence identifier and 1 byte operation type identifier, and is compressed. RocksDB also replaces the sequence identifier with the value zero when it is not needed to resolve multi-version concurrency control (MVCC) visibility.
MyRocks integrates RocksDB as a new MySQL storage engine, and its architecture provides added features that weren’t previously available with InnoDB, including:
- Faster replication: MyRocks replication is faster than InnoDB for a couple of reasons. MyRocks doesn’t need random reads for updating secondary keys, unless the index is unique. Also, with the row-based binary logging format, MyRocks does not need random reads for updating primary keys, and does not even need to check uniqueness. The second feature is called read-free replication, which is an option that can be enabled in MyRocks.
- Faster data loading: With faster data loading enabled for a session, MyRocks writes data directly onto the bottommost level, which avoids all compaction overheads. Since compactions use both CPU and I/O for decompressing, compressing, and writing data, avoiding compactions by bulk loading is optimal.
Benchmarks
To evaluate database performance for workloads similar to those of Facebook’s production MySQL deployment, we ran LinkBench for three instances — MyRocks (compressed), InnoDB (uncompressed), and InnoDB (compressed, 8 KB page size) — on the same spec machines running PCI-Express flash for more than 24 hours. We found that MyRocks was two times smaller than InnoDB compressed, showed competitive QPS compared with both compressed and uncompressed InnoDB, and wrote orders of magnitude less than InnoDB.
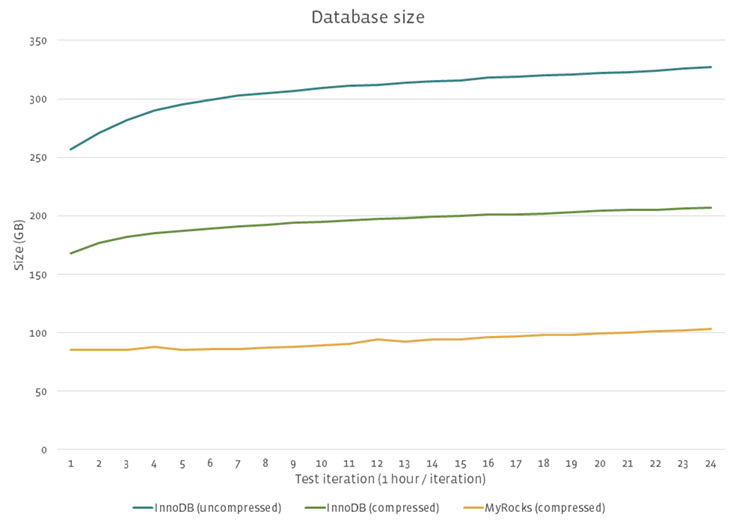
The MyRocks instance size was 3.5 times smaller than InnoDB uncompressed, and two times smaller than InnoDB compressed. MyRocks is heavily optimized for space efficiency; fragmentation, compression size alignment, prefix encoding, and metadata space optimization were some of the factors between the space differences.
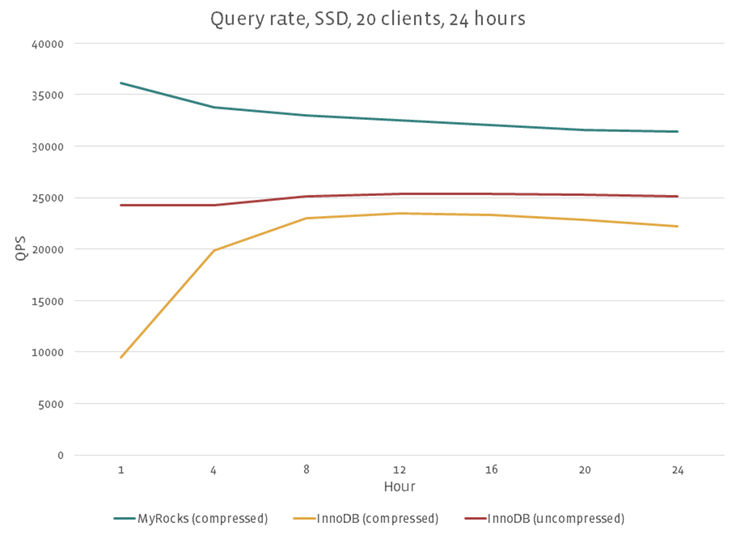
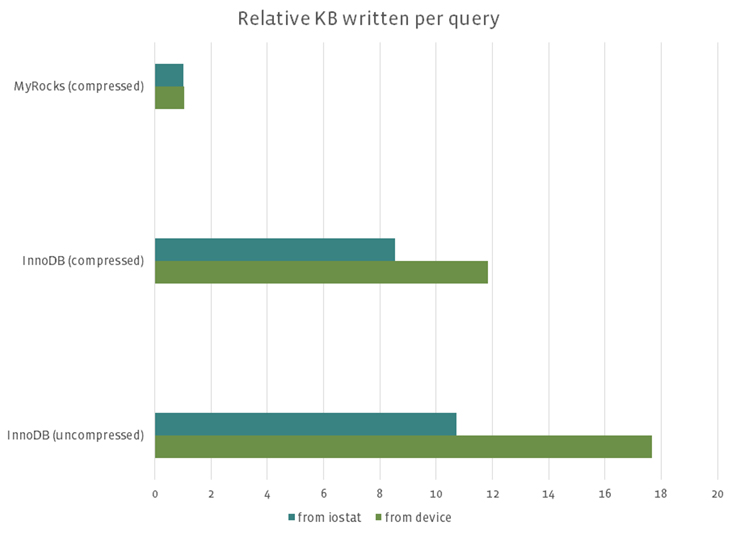
This graph shows how many bytes were relatively written from OS metrics (iostat) and flash device metrics (depending on storage devices). This does not include binary logs and relay logs. MyRocks wrote orders of magnitude less than InnoDB. Flash-written bytes were larger than iostat bytes written, because flash internally does garbage collection and needs extra writes, which is not visible from operating systems.
The write amplification difference also affects flash storage. Lower write amplification allows you to use more affordable flash, or to use the same flash for a longer period of time. Also, it is common to use less space than available (provisioning some space for flash garbage collections), to get better steady-state write throughput. With low write amplification databases like MyRocks, it is possible to allocate more user space without hurting steady-state write throughput.
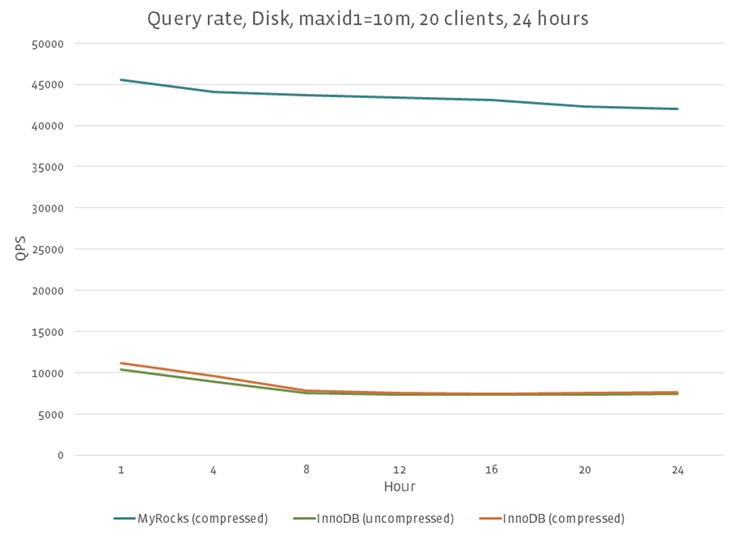
We also ran LinkBench on HDD, and MyRocks was more than six times faster than InnoDB. Note that scores heavily depended on workload characteristics. LSM databases handle random writes well on HDD while B+Tree doesn’t. If your workload doesn’t have many random writes, QPS differences will be much smaller in MyRocks. On HDD, QPS is a more relevant consideration for deciding which database to use, so it’s important to understand your workloads and run proper tests to evaluate databases.
We are in the process of running other benchmark tools, such as tpcc-mysql, and you can also run any benchmark tool that supports MySQL. Feel free to publish benchmark scores or file bug reports if you uncover anything interesting.
Migrating from InnoDB to MyRocks in production
To run MyRocks in production, it’s necessary to migrate existing InnoDB databases to MyRocks without downtime, losing data, and returning inaccurate results. It’s also important to migrate each instance quickly, since we have many instances to migrate. Migration steps include:
- Create an empty MyRocks instance with MyRocks tables for our main MySQL database schema.
- Stop one of the InnoDB secondary instances, do a logical dump from it, and pipe the output into the MyRocks instance.
- Start both InnoDB and MyRocks replication secondaries.
The migration uses a logical dump from InnoDB followed by a load into MyRocks. Concurrent with that is a continuous data integrity verification.
Since MySQL replication is logical, it is possible to use different storage engines between a primary and secondary. For example, it’s possible to deploy InnoDB on a primary with two InnoDB secondaries, and one MyRocks secondary.
Verifying data consistency online
Throughout this migration, we need to make sure that MyRocks instances do not lose data or return incorrect results. To help solve for this, we created a tool that confirms data and query correctness, and runs without affecting online services. We’re able to take consistent snapshots of the same global transaction ID (GTID) positions from both InnoDB and MyRocks instances, then execute queries for target tables, and verify that result sets are the same. We continually run two correctness checks in production: full index checksum and shadow query correctness. With the full index checksum test, our tool runs full index scans from two instances and compares row counts and column checksum. The shadow query correctness test captures SELECT statements from production instances, replays the queries on both MyRocks and InnoDB instances, and then ensures that results are the same.
Running MyRocks as primary
Migrating from InnoDB to MyRocks on a primary is more complicated. MyRocks does not support gap lock. This means row-based binary logging for replication is needed on primary. In addition to that, before promoting MyRocks as primary, it is necessary to rewrite queries relying on gap lock. To make it easier, we added an option to our InnoDB instances to log and/or return errors for queries relying on gap lock.
Current target use cases
It is important to note that we are not planning to migrate all existing InnoDB databases to MyRocks. InnoDB is a long-standing standard MySQL storage engine and has many different use cases. MyRocks is a new storage engine with better compression than InnoDB but a limited feature set. We’re in the process of migrating from InnoDB to MyRocks on our main MySQL database tier at Facebook, where we’ll use less storage for the same amount of data. But there are many other critical database tiers, too, and we’ll continue to use InnoDB for most of them.
Future works
Our work on MyRocks has been centered on making storage savings efficient. In looking ahead, we’ll be focused on building out more complete features to support MyRocks. For example, it lacks features like foreign keys, online DDL, automatic deadlock detection (we use short lock wait timeouts), and native partitioning. It also lacks interesting features that are native in InnoDB like FULLTEXT and SPATIAL indexes. Some applications need these features, and they will allow MyRocks to become an all-purpose storage engine. The good news is that MyRocks is open source, and anyone can download, use, and contribute to it to take advantage of some of the storage savings efficiencies we’ve built.
MyRocks is a combination of RocksDB — a fork from Google’s LevelDB — and MySQL v5.6 from Oracle with extensions added.
In an effort to be more inclusive in our language, we have edited this post to replace the terms “master” and “slave” with “primary” and “secondary”.








