
- In recent years, Meta’s data management systems have evolved into a composable architecture that creates interoperability, promotes reusability, and improves engineering efficiency.
- We’re sharing how we’ve achieved this, in part, by leveraging Velox, Meta’s open source execution engine, as well as work ahead as we continue to rethink our data management systems.
Data is at the core of every product and service at Meta. To efficiently process data generated by billions of people, Data Infrastructure teams at Meta have built a variety of data management systems over the last decade, each targeted to a somewhat specific data processing task. Today, our data engines support workloads such as offline processing of large datasets (ETL), interactive dashboard generation, ad hoc data exploration, and stream processing as well as more recent feature engineering and data preprocessing systems that support our rapidly expanding AI/ML infrastructure.
Over time, these divergent systems created a fragmented data environment with little reuse across systems, which eventually slowed our engineering innovation. In many cases, it forced our engineers to reinvent the wheel, duplicating work and reducing our ability to quickly adapt systems as requirements evolved.
More importantly, the byproducts of this fragmentation – incompatible SQL and non-SQL APIs, and inconsistent functionality and semantics – impacted the productivity of internal data users who are commonly required to interact with multiple, distinct data systems, each with their own quirks, to finish a particular task. Fragmentation also eventually translated to high costs of ownership for running these data systems. To economically support our fast-paced environment where products are constantly evolving and generating additional requirements to our data systems, we needed more agility. We needed to change our thinking to be able to move faster.
A few years ago we embarked on a journey to address these shortcomings by rethinking how our data management systems were designed. The rationale was simple: Instead of individually developing systems as monoliths, we would identify common components, factor them out as reusable libraries, and leverage common APIs and standards to increase the interoperability between them. We would create teams that cooperate horizontally by developing shared components, concentrating our specialists in fewer but more focused teams, thus amplifyinging the impact of the teams’ work.
This ambitious program had a three-fold goal: (a) to increase the engineering efficiency of our organization by minimizing the duplication of work; (b) to improve the experience of internal data users through more consistent semantics across these engines, and ultimately, (c) to accelerate the pace of innovation in data management.
Building on similarities
With time, the evolution of these ideas gave birth to the trend now called the “composable data management system.” We have recently published this vision in a research paper in collaboration with other organizations and key leaders in the community facing similar challenges. In the paper, we make the observation that in many cases the reusability challenges are not only technical but commonly also cultural and even economic. Moreover, we discuss that while at first these specialized data systems may seem distinct, at the core they are all composed of a similar set of logical components:
- A language frontend, responsible for parsing user input (such as a SQL string or a dataframe program) into an internal format;
- An intermediate representation (IR), or a structured representation of computation, usually in the form of a logical and/or a physical query plan;
- A query optimizer, responsible for transforming the IR into a more efficient IR ready for execution;
- An execution engine library, able to locally execute query fragments (also sometimes referred to as the “eval engine”); and
- An execution runtime, responsible for providing the (often distributed) environment in which query fragments can be executed.
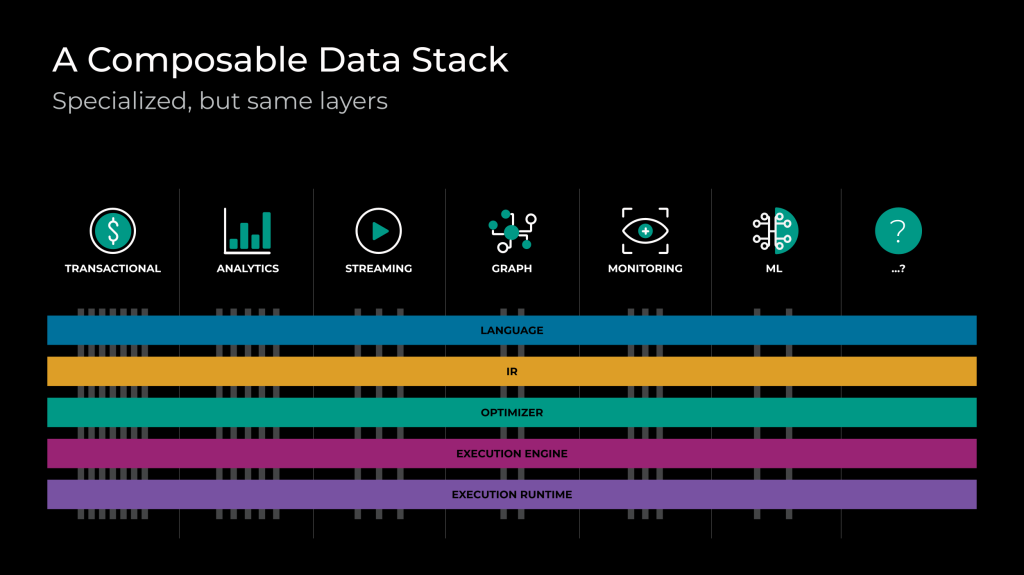 We have also highlighted that, beyond having the same logical components, the data structures and algorithms used to implement these layers are largely consistent across systems. For example, there is nothing fundamentally different between the SQL frontend of an operational database system and that of a data warehouse, or between the expression evaluation engines of a traditional columnar DBMS and that of a stream processing engine, or between the string, date, array, or JSON manipulation functions across database systems.
We have also highlighted that, beyond having the same logical components, the data structures and algorithms used to implement these layers are largely consistent across systems. For example, there is nothing fundamentally different between the SQL frontend of an operational database system and that of a data warehouse, or between the expression evaluation engines of a traditional columnar DBMS and that of a stream processing engine, or between the string, date, array, or JSON manipulation functions across database systems.
Often, however, data systems do require specialized behavior. For example, stream processing systems have streaming-specific operators, and machine learning (ML) data preprocessing systems may have tensor-specific manipulation logic. The rationale is that reusable components should provide the common functionality (the intersection), while providing extensibility APIs where domain-specific features can be added. In other words, we need a mindset change as we build data systems as well as organize the engineering teams that support them: We should focus on the similarities, which are the norm, rather than on the differences, which are the exceptions.
Decomposition begins
If one were to start building data systems from scratch, there is little disagreement that reusable components are more cost effective and maintainable in the long run. However, most of our existing data systems are stable and battle-tested, and are the result of decades of engineering investment. From a cost perspective, refactoring and unifying their components could be impractical.
Yet, scale drives innovation, and to support the growing needs from our products and services, we are constantly improving the efficiency and scalability of our existing data engines. Since the execution engine is the layer where most computational resources are spent, often we have found ourselves re-implementing execution optimizations already available in a different system, or porting features across engines.
With that in mind, a few years ago we decided to take a bolder step: Instead of individually tweaking these systems, we started writing a brand new execution-layer component containing all the optimizations we needed. The strategy was to write it as a composable, reusable, and extensible library, which could be integrated into multiple data systems, therefore increasing the engineering efficiency of our organization in the long run.
Composable Execution: Velox
This is how Velox started. We created Velox in late 2020 and made it open source in 2022.
By providing a reusable, state-of-the-art execution engine that is engine- and dialect-agnostic (i.e, it can be integrated with any data system and extended to follow any SQL-dialect semantic), Velox quickly received attention from the open-source community. Beyond our initial collaborators from IBM/Ahana, Intel, and Voltron Data, today more than 200 individual collaborators from more than 20 companies around the world participate in Velox’s continued development.
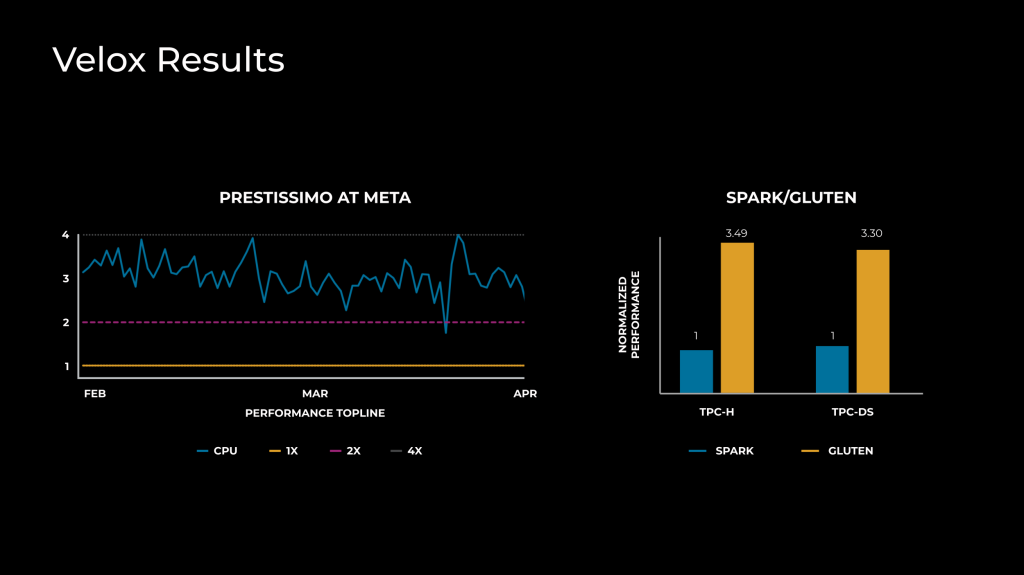
Velox is currently in different stages of integration with more than 10 data systems at Meta. For example, in our Velox integration with Presto (a project cleverly named “Prestissimo”), we have seen 3-10x efficiency improvements in deployments running production workloads. In the Apache Gluten open source project created by Intel, where Velox can be used as the execution engine within Spark, a similar 3x efficiency gain has been observed on benchmarks. We have also seen engineering-efficiency improvements as new systems such as internal time-series databases and low-latency interactive engines were developed in record time by reusing the work done by a small group of focused database execution specialists.
With Velox, we intend to commoditize execution in data management by providing an open, state-of-the-art implementation. Beyond the novel composability aspect, in general lines, Velox extensively leverages the following data processing techniques to provide superior performance and efficiency:
- Columnar and vectorized execution: Velox decomposes large computations into concise and tight loops, as these provide more predictable memory access patterns and can be more efficiently executed by modern CPUs.
- Compressed execution: In Velox, columnar encodings have dual applicability: data compression and processing efficiency. For example, dictionary encoding can be used not only to more compactly represent the data, but also to represent the output of cardinality-reducing or increasing operations such as filters, joins, and unnests.
- Lazy materialization: As many operations can be executed just by wrapping encodings around the data, the actual materialization (decoding) can be delayed and at times completely avoided.
- Adaptivity: In many situations, Velox is able to learn when applying computations over successive batches of data, in order to more efficiently process incoming batches. For example, Velox keeps track of the hit rates of filters and conjuncts to optimize their order; it also keeps track of join-key cardinality to more efficiently organize the join execution; it learns column access patterns to improve prefetching logic, among other similar optimizations.
By being composable, Velox enabled us to write and maintain this complex logic once and then benefit from it multiple times. It also allowed us to build a more focused team of data execution specialists who were able to create a far more efficient execution component than what was possible with bespoke systems, due to investment fragmentation. By being open source, Velox allowed us to collaborate with the community while building these features, and to more closely partner with hardware vendors to ensure better integration with evolving hardware platforms.
System-wide integration: Open standards and Apache Arrow
To continue decomposing our monolithic systems into a more modular stack of reusable components, we had to ensure that these components could seamlessly interoperate through common APIs and standards. Engines had to understand common storage (file) formats, network serialization protocols, and table APIs, and have a unified way of expressing computation. Often, these components had to directly share in-memory datasets with each other, such as when transferring data across language boundaries (from C++ to Java or Python) for efficient UDF support. As much as possible, our focus was to use open standards in these APIs.
Yet, while creating Velox, we made the conscious design decision to extend and deviate from the open-source Apache Arrow format (a widely adopted in-memory columnar layout) and created a new columnar layout called Velox Vectors. Our goal was to accelerate data-processing operations that commonly occur in our workloads in ways that had not been possible using Arrow. The new Velox Vectors layout provided the efficiency and agility we needed to move fast, but in return it created a fragmented space with limited component interoperability.
To reduce fragmentation and create a more unified data landscape for our systems and the community, we partnered with Voltron Data and the Arrow community to align and converge the two formats. After a year of work, three new extensions inspired by Velox Vectors were added to new Apache Arrow releases: (a) StringView, (b) ListView, and (c) Run-End-Encoding (REE). Today, new Arrow releases not only enable efficient (i.e., zero-copy) in-memory communication across components using Velox and Arrow, but also increase Arrow’s applicability in modern execution engines, unlocking a variety of use cases across the industry.
This work is described in detail in our blog, Aligning Velox and Apache Arrow: Towards composable data management.
Future directions
To continue our journey towards making systems more sustainable in the long-term through composability, as well as adaptable to current and future trends, we have started investing in two new avenues. First, we have witnessed how the inflexibility of current file formats can limit the performance of large training tables for AI/ML. In addition to their massive size, these tables are often (a) much wider (i.e, containing thousands of column/feature streams), (b) can benefit from novel, more flexible and recursive encoding schemes, and (c) need parallel and more efficient decoding methods to feed data-hungry trainers. To address these needs, we have recently created and open sourced Nimble (formerly known as Alpha). Nimble is a new file format for large datasets aimed at AI/ML workloads, but that also provides compelling features for traditional analytic tables. Nimble is meant to be shared as a portable and easy-to-use library, and we believe it has the potential to supersede current mainstream analytic file formats within Meta and beyond.
Second, AI/ML compute requirements are rapidly driving innovation in data center design, steadily driving heterogeneity. To better leverage new hardware platforms, we believe AI/ML and data management systems should continue to converge through hardware-accelerated data systems, and that while fragmentation has historically hindered the adoption of hardware accelerators in data management, composable data systems will provide just about the right architecture. With Velox, we have seen that the first 3-4x efficiency improvements in data management can come purely from software techniques; moving forward, we believe that the next 10x efficiency wins will come from hardware acceleration. Although for now in this ongoing explorational effort there exist more challenges and open questions than answers, two things are well understood: Composability is paving the way for widespread hardware acceleration and other innovations in data management, and working in collaboration with the open-source community will increase our chances of success in this journey.
We believe that the future of data management is composable and hope more individuals and organizations will join us in this effort.








