
- Meta is introducing Velox, an open source unified execution engine aimed at accelerating data management systems and streamlining their development.
- Velox is under active development. Experimental results from our paper published at the International Conference on Very Large Data Bases (VLDB) 2022 show how Velox improves efficiency and consistency in data management systems.
- Velox helps consolidate and unify data management systems in a manner we believe will be of benefit to the industry. We’re hoping the larger open source community will join us in contributing to the project.
Meta’s infrastructure plays an important role in supporting our products and services. Our data infrastructure ecosystem is composed of dozens of specialized data computation engines, all focused on different workloads for a variety of use cases ranging from SQL analytics (batch and interactive) to transactional workloads, stream processing, data ingestion, and more. Recently, the rapid growth of artificial intelligence (AI) and machine learning (ML) use cases within Meta’s infrastructure has led to additional engines and libraries targeted at feature engineering, data preprocessing, and other workloads for ML training and serving pipelines.
However, despite the similarities, these engines have largely evolved independently. This fragmentation has made maintaining and enhancing them difficult, especially considering that as workloads evolve, the hardware that executes these workloads also changes. Ultimately, this fragmentation results in systems with different feature sets and inconsistent semantics — reducing the productivity of data users that need to interact with multiple engines to finish tasks.
In order to address these challenges and to create a stronger, more efficient data infrastructure for our own products and the world, Meta has created and open sourced Velox. It’s a novel, state-of-the-art unified execution engine that aims to speed up data management systems as well as streamline their development. Velox unifies the common data-intensive components of data computation engines while still being extensible and adaptable to different computation engines. It democratizes optimizations that were previously implemented only in individual engines, providing a framework in which consistent semantics can be implemented. This reduces work duplication, promotes reusability, and improves overall efficiency and consistency.
Velox is under active development, but it’s already in various stages of integration with more than a dozen data systems at Meta, including Presto, Spark, and PyTorch (the latter through a data preprocessing library called TorchArrow), as well as other internal stream processing platforms, transactional engines, data ingestion systems and infrastructure, ML systems for feature engineering, and others.
Since it was first uploaded to GitHub, the Velox open source project has attracted more than 150 code contributors, including key collaborators such as Ahana, Intel, and Voltron Data, as well as various academic institutions. By open-sourcing and fostering a community for Velox, we believe we can accelerate the pace of innovation in the data management system’s development industry. We hope more individuals and companies will join us in this effort.
An overview of Velox
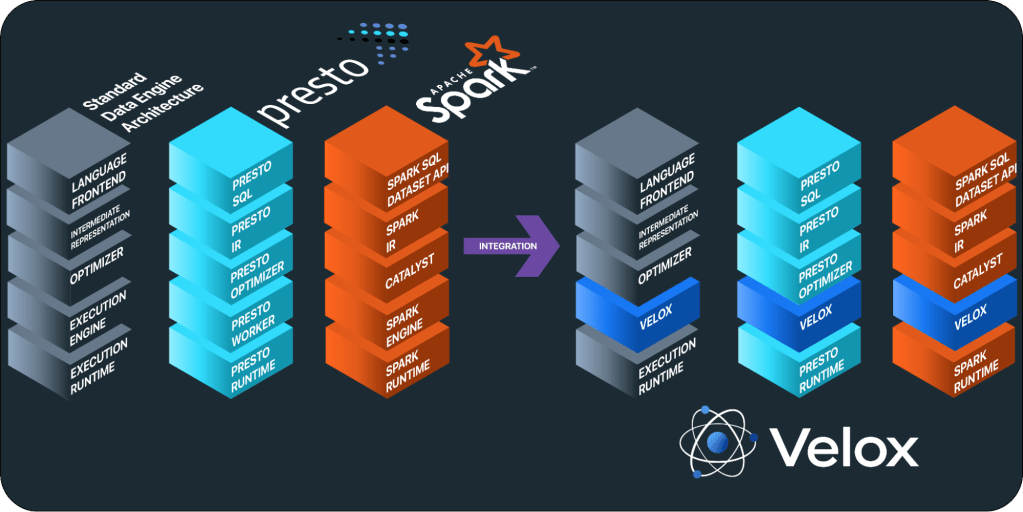
While data computation engines may seem distinct at first, they are all composed of a similar set of logical components: a language front end, an intermediate representation (IR), an optimizer, an execution runtime, and an execution engine. Velox provides the building blocks required to implement execution engines, consisting of all data-intensive operations executed within a single host, such as expression evaluation, aggregation, sorting, joining, and more — also commonly referred to as the data plane. Therefore, Velox expects an optimized plan as input and efficiently executes it using the resources available in the local host.
Velox leverages numerous runtime optimizations, such as filter and conjunct reordering, key normalization for array and hash-based aggregations and joins, dynamic filter pushdown, and adaptive column prefetching. These optimizations provide optimal local efficiency given the available knowledge and statistics extracted from incoming batches of data. Velox is also designed from the ground up to efficiently support complex data types due to their ubiquity in modern workloads, and hence extensively relies on dictionary encoding for cardinality-increasing and cardinality-reducing operations such as joins and filtering, while still providing fast paths for primitive data types.
The main components provided by Velox are:
- Type: a generic type system that allows developers to represent scalar, complex, and nested data types, including structs, maps, arrays, functions (lambdas), decimals, tensors, and more.
- Vector: an Apache Arrow–compatible columnar memory layout module supporting multiple encodings, such as flat, dictionary, constant, sequence/RLE, and frame of reference, in addition to a lazy materialization pattern and support for out-of-order result buffer population.
- Expression Eval: a state-of-the-art vectorized expression evaluation engine built based on vector-encoded data, leveraging techniques such as common subexpression elimination, constant folding, efficient null propagation, encoding-aware evaluation, dictionary peeling, and memoization.
- Functions: APIs that can be used by developers to build custom functions, providing a simple (row by row) and vectorized (batch by batch) interface for scalar functions and an API for aggregate functions.
- A function package compatible with the popular PrestoSQL dialect is also provided as part of the library.
- Operators: implementation of common SQL operators such as TableScan, Project, Filter, Aggregation, Exchange/Merge, OrderBy, TopN, HashJoin, MergeJoin, Unnest, and more.
- I/O: a set of APIs that allows Velox to be integrated in the context of other engines and runtimes, such as:
- Connectors: enables developers to specialize data sources and sinks for TableScan and TableWrite operators.
- DWIO: an extensible interface providing support for encoding/decoding popular file formats such as Parquet, ORC, and DWRF.
- Storage adapters: a byte-based extensible interface that allows Velox to connect to storage systems such as Tectonic, S3, HDFS, and more.
- Serializers: a serialization interface targeting network communication where different wire protocols can be implemented, supporting PrestoPage and Spark’s UnsafeRow formats.
- Resource management: a collection of primitives for handling computational resources, such as CPU and memory management, spilling, and memory and SSD caching.
Velox’s main integrations and experimental results
Beyond efficiency gains, Velox provides value by unifying the execution engines across different data computation engines. The three most popular integrations are Presto, Spark, and TorchArrow/PyTorch.
Presto — Prestissimo
Velox is being integrated into Presto as part of the Prestissimo project, where Presto Java workers are replaced by a C++ process based on Velox. The project was originally created by Meta in 2020 and is under continued development in collaboration with Ahana, along with other open source contributors.
Prestissimo provides a C++ implementation of Presto’s HTTP REST interface, including worker-to-worker exchange serialization protocol, coordinator-to-worker orchestration, and status reporting endpoints, thereby providing a drop-in C++ replacement for Presto workers. The main query workflow consists of receiving a Presto plan fragment from a Java coordinator, translating it into a Velox query plan, and handing it off to Velox for execution.
We conducted two different experiments to explore the speedup provided by Velox in Presto. Our first experiment used the TPC-H benchmark and measured close to an order of magnitude speedup in some CPU-bound queries. We saw a more modest speedup (averaging 3-6x) for shuffle-bound queries.
Although the TPC-H dataset is a standard benchmark, it’s not representative of real workloads. To explore how Velox might perform in these scenarios, we created an experiment where we executed production traffic generated by a variety of interactive analytical tools found at Meta. In this experiment, we saw an average of 6-7x speedups in data querying, with some results increasing speedups by over an order of magnitude. You can learn more about the details of the experiments and their results in our research paper.
Spark — Gluten
Velox is also being integrated into Spark as part of the Gluten project created by Intel. Gluten allows C++ execution engines (such as Velox) to be used within the Spark environment while executing Spark SQL queries. Gluten decouples the Spark JVM and execution engine by creating a JNI API based on the Apache Arrow data format and Substrait query plans, thus allowing Velox to be used within Spark by simply integrating with Gluten’s JNI API.
Gluten’s codebase is available on GitHub.
TorchArrow
TorchArrow is a dataframe Python library for data preprocessing in deep learning, and part of the PyTorch project. TorchArrow internally translates the dataframe representation into a Velox plan and delegates it to Velox for execution. In addition to converging the otherwise fragmented space of ML data preprocessing libraries, this integration allows Meta to consolidate execution-engine code between analytic engines and ML infrastructure. It provides a more consistent experience for ML end users, who are commonly required to interact with different computation engines to complete a particular task, by exposing the same set of functions/UDFs and ensuring consistent behavior across engines.
TorchArrow was recently released in beta mode on GitHub.
The future of database system development
Velox demonstrates that it is possible to make data computation systems more adaptable by consolidating their execution engines into a single unified library. As we continue to integrate Velox into our own systems, we are committed to building a sustainable open source community to support the project as well as to speed up library development and industry adoption. We are also interested in continuing to blur the boundaries between ML infrastructure and traditional data management systems by unifying function packages and semantics between these silos.
Looking at the future, we believe Velox’s unified and modular nature has the potential to be beneficial to industries that utilize, and especially those that develop, data management systems. It will allow us to partner with hardware vendors and proactively adapt our unified software stack as hardware advances. Reusing unified and highly efficient components will also allow us to innovate faster as data workloads evolve. We believe that modularity and reusability are the future of database system development, and we hope that data companies, academia, and individual database practitioners alike will join us in this effort.
In-depth documentation about Velox and these components can be found on our website and in our research paper “Velox: Meta’s unified execution engine.”
Acknowledgements
We would like to thank all contributors to the Velox project. A special thank-you to Sridhar Anumandla, Philip Bell, Biswapesh Chattopadhyay, Naveen Cherukuri, Wei He, Jiju John, Jimmy Lu, Xiaoxuang Meng, Krishna Pai, Laith Sakka, Bikramjeet Vigand, Kevin Wilfong from the Meta team, and to countless community contributors, including Frank Hu, Deepak Majeti, Aditi Pandit, and Ying Su.








