
- Sapling is a new Git-compatible source control client.
- Sapling emphasizes usability while also scaling to the largest repositories in the world.
- ReviewStack is a demonstration code review UI for GitHub pull requests that integrates with Sapling to make reviewing stacks of commits easy.
- You can get started using Sapling today.
Source control is one of the most important tools for modern developers, and through tools such as Git and GitHub, it has become a foundation for the entire software industry. At Meta, source control is responsible for storing developers’ in-progress code, storing the history of all code, and serving code to developer services such as build and test infrastructure. It is a critical part of our developer experience and our ability to move fast, and we’ve invested heavily to build a world-class source control experience.
We’ve spent the past 10 years building Sapling, a scalable, user-friendly source control system, and today we’re open-sourcing the Sapling client. You can now try its various features using Sapling’s built-in Git support to clone any of your existing repositories. This is the first step in a longer process of making the entire Sapling system available to the world.
What is Sapling?
Sapling is a source control system used at Meta that emphasizes usability and scalability. Git and Mercurial users will find that many of the basic concepts are familiar — and that workflows like understanding your repository, working with stacks of commits, and recovering from mistakes are substantially easier.
When used with our Sapling-compatible server and virtual file system (we hope to open-source these in the future), Sapling can serve Meta’s internal repository with tens of millions of files, tens of millions of commits, and tens of millions of branches. At Meta, Sapling is primarily used for our large monolithic repository (or monorepo, for short), but the Sapling client also supports cloning and interacting with Git repositories and can be used by individual developers to work with GitHub and other Git hosting services.
Why build a new source control system?
Sapling began 10 years ago as an initiative to make our monorepo scale in the face of tremendous growth. Public source control systems were not, and still are not, capable of handling repositories of this size. Breaking up the repository was also out of the question, as it would mean losing monorepo’s benefits, such as simplified dependency management and the ability to make broad changes quickly. Instead, we decided to go all in and make our source control system scale.
Starting as an extension to the Mercurial open source project, it rapidly grew into a system of its own with new storage formats, wire protocols, algorithms, and behaviors. Our ambitions grew along with it, and we began thinking about how we could improve not only the scale but also the actual experience of using source control.
Sapling’s user experience
Historically, the usability of version control systems has left a lot to be desired; developers are expected to maintain a complex mental picture of the repository, and they are often forced to use esoteric commands to accomplish seemingly simple goals. We aimed to fix that with Sapling.
A Git user who sits down with Sapling will initially find the basic commands familiar. Users clone a repository, make commits, amend, rebase, and push the commits back to the server. What will stand out, though, is how every command is designed for simplicity and ease of use. Each command does one thing. Local branch names are optional. There is no staging area. The list goes on.
It’s impossible to cover the entire user experience in a single blog post, so check out our user experience documentation to learn more.

Below, we’ll explore three particular areas of the user experience that have been so successful within Meta that we’ve had requests for them outside of Meta as well.
Smartlog: Your repo at a glance
The smartlog is one of the most important Sapling commands and the centerpiece of the entire user experience. By simply running the Sapling client with no arguments, sl, you can see all your local commits, where you are, where important remote branches are, what files have changed, and which commits are old and have new versions. Equally important, the smartlog hides all the information you don’t care about. Remote branches you don’t care about are not shown. Thousands of irrelevant commits in main are hidden behind a dashed line. The result is a clear, concise picture of your repository that’s tailored to what matters to you, no matter how large your repo.

Having this view at your fingertips changes how people approach source control. For new users, it gives them the right mental model from day one. It allows them to visually see the before-and-after effects of the commands they run. Overall, it makes people more confident in using source control.
We’ve even made an interactive smartlog web UI for people who are more comfortable with graphical interfaces. Simply run sl web to launch it in your browser. From there you can view your smartlog, commit, amend, checkout, and more.
Fixing mistakes with ease
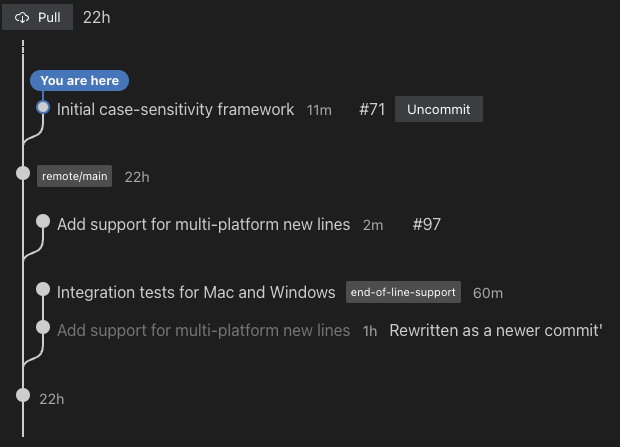
The most frustrating aspect of many version control systems is trying to recover from mistakes. Understanding what you did is hard. Finding your old data is hard. Figuring out what command you should run to get the old data back is hard. The Sapling development team is small, and in order to support our tens of thousands of internal developers, we needed to make it as easy as possible to solve your own issues and get unblocked.
To this end, Sapling provides a wide array of tools for understanding what you did and undoing it. Commands like sl undo, sl redo, sl uncommit, and sl unamend allow you to easily undo many operations. Commands like sl hide and sl unhide allow you to trivially and safely hide commits and bring them back to life. There is even an sl undo -i command for Mac and Linux that allows you to interactively scroll through old smartlog views to revert back to a specific point in time or just find the commit hash of an old commit you lost. Never again should you have to delete your repository and clone again to get things working.

See our UX doc for a more extensive overview of our many recovery features.
First-class commit stacks
At Meta, working with stacks of commits is a common part of our workflow. First, an engineer building a feature will send out the small first step of that feature as a commit for code review. While it’s being reviewed, they will start on the next step as a second commit that will later be sent for code review as well. A full feature will consist of many of these small, incremental, individually reviewed commits on top of one another.
Working with stacks of commits is particularly difficult in many source control systems. It requires complex stateful commands like git rebase -i to add a single line to a commit earlier in the stack. Sapling makes this easy by providing explicit commands and workflows for making even the newest engineer able to edit, rearrange, and understand the commits in the stack.
At its most basic, when you want to edit a commit in a stack, you simply check out that commit, via sl goto COMMIT, make your change, and amend it via sl amend. Sapling automatically moves, or rebases, the top of your stack onto the newly amended commit, allowing you to resolve any conflicts immediately. If you choose not to fix the conflicts now, you can continue working on that commit, and later run sl restack to bring your stack back together once again. Inspired by Mercurial’s Evolve extension, Sapling keeps track of the mutation history of each commit under the hood, allowing it to algorithmically rebuild the stack later, no matter how many times you edit the stack.
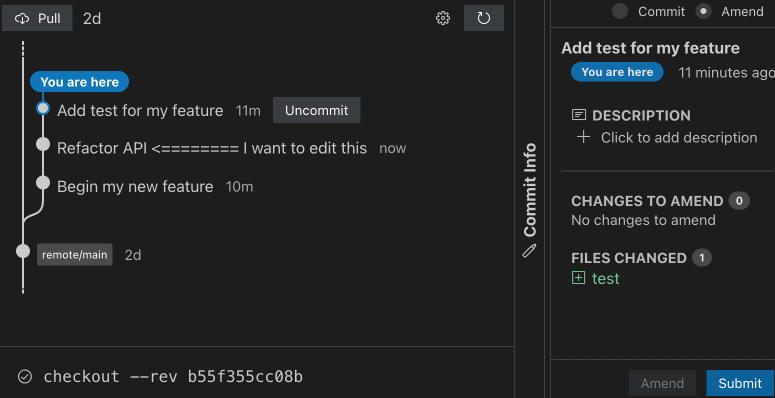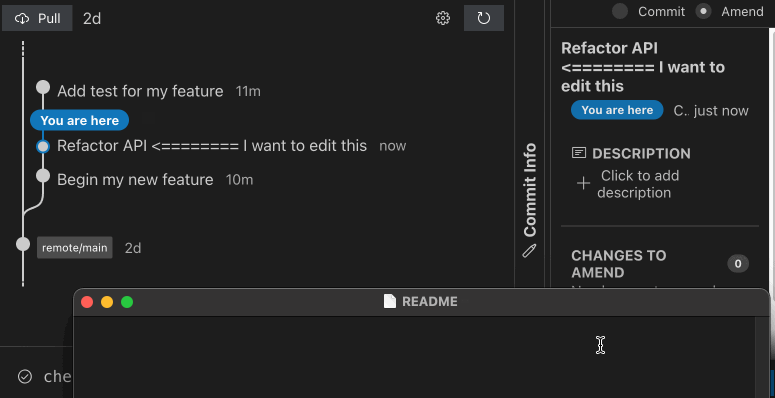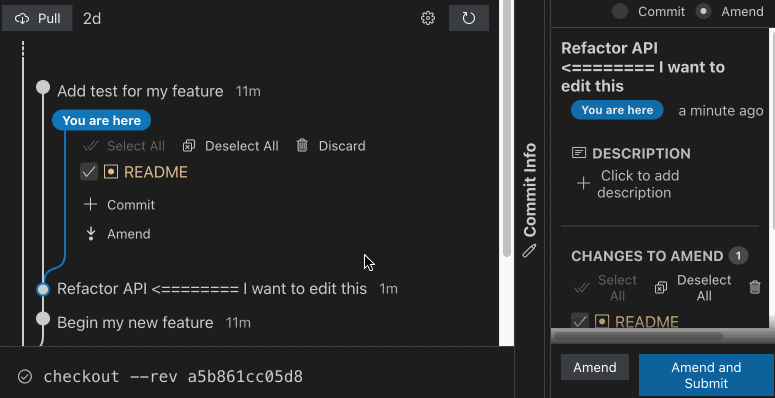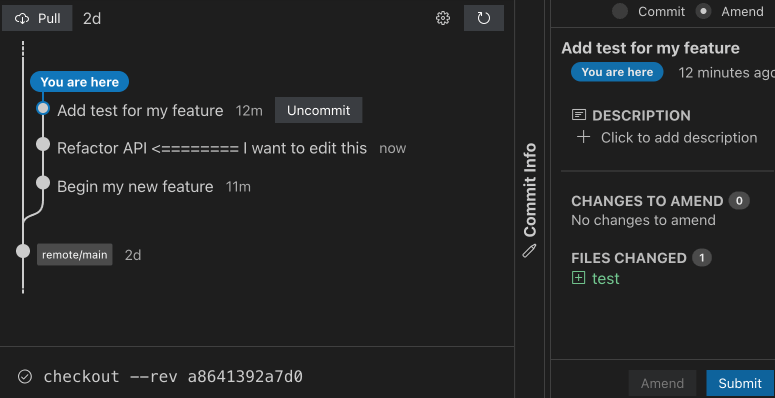
Beyond simply amending and restacking commits, Sapling offers a variety of commands for navigating your stack (sl next, sl prev, sl goto top/bottom), adjusting your stack (sl fold, sl split), and even allows automatically pulling uncommitted changes from your working copy down into the appropriate commit in the middle of your stack (sl absorb, sl amend –to COMMIT).
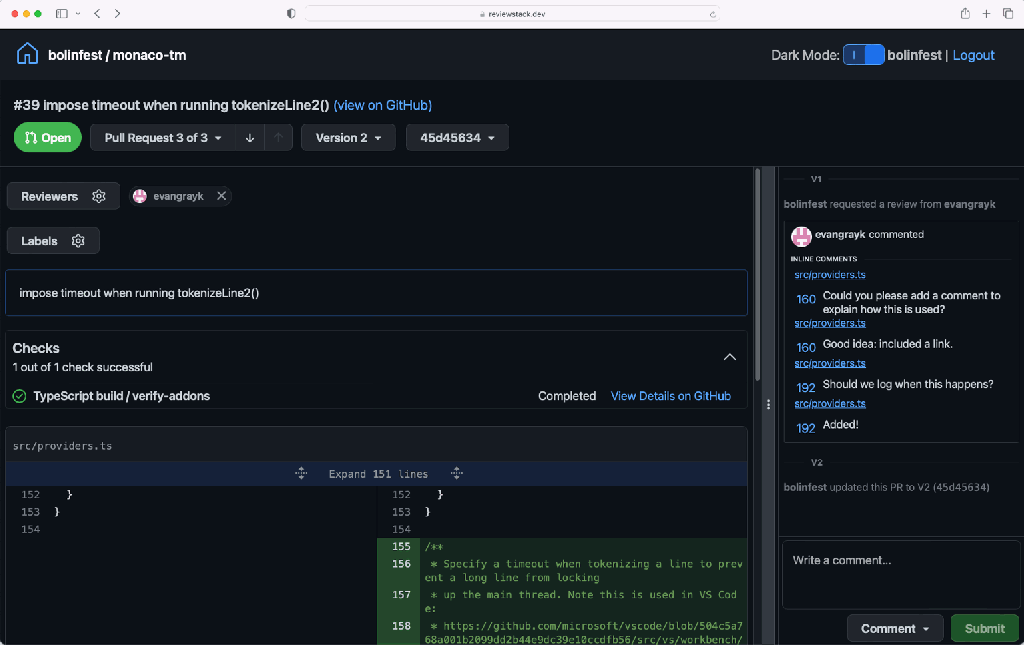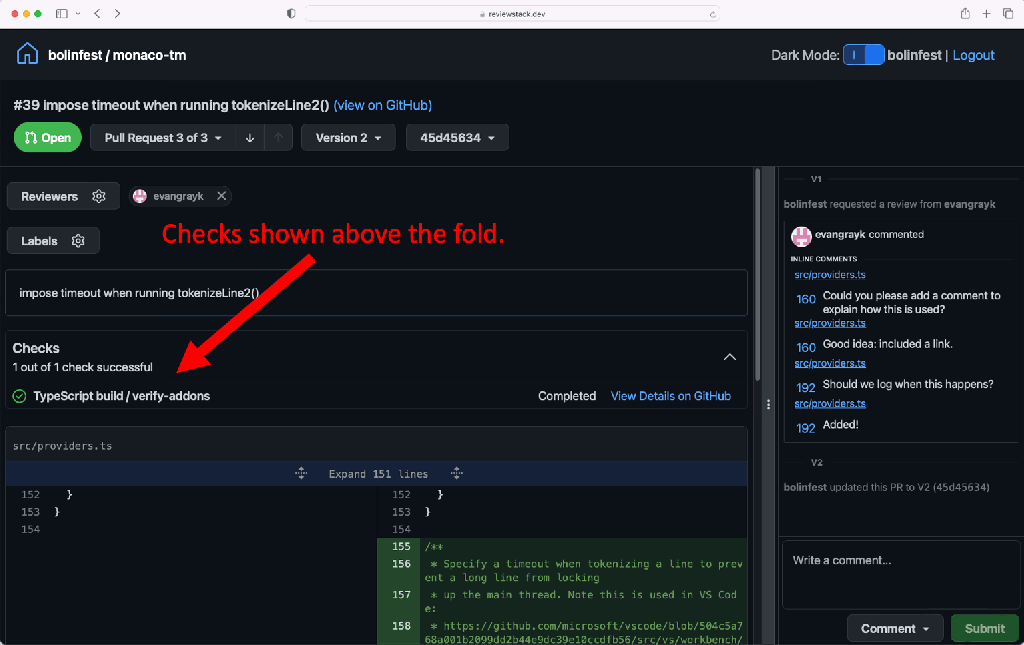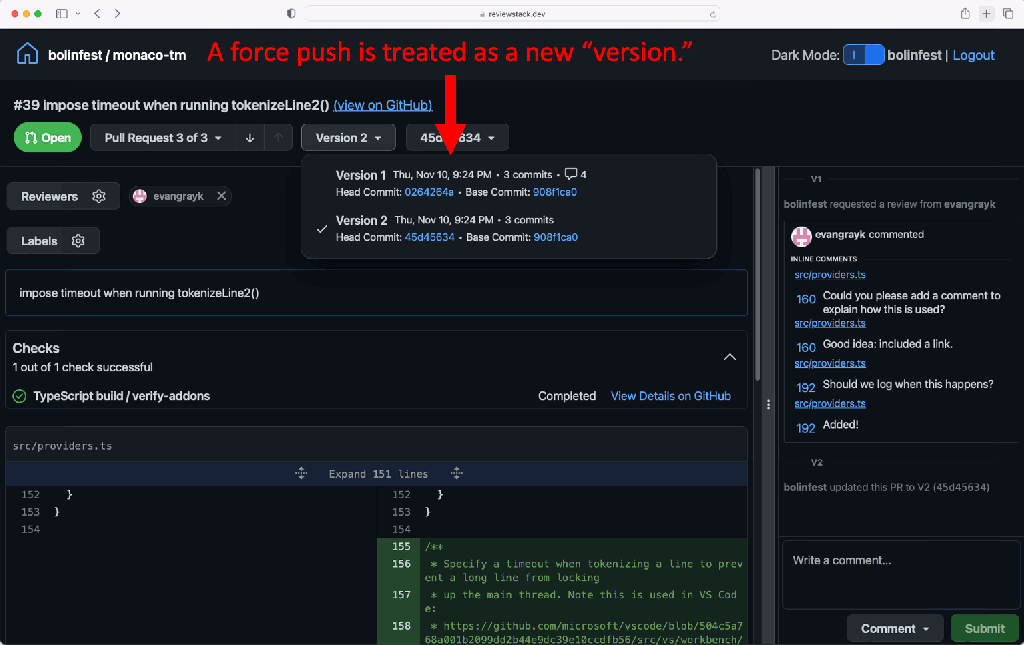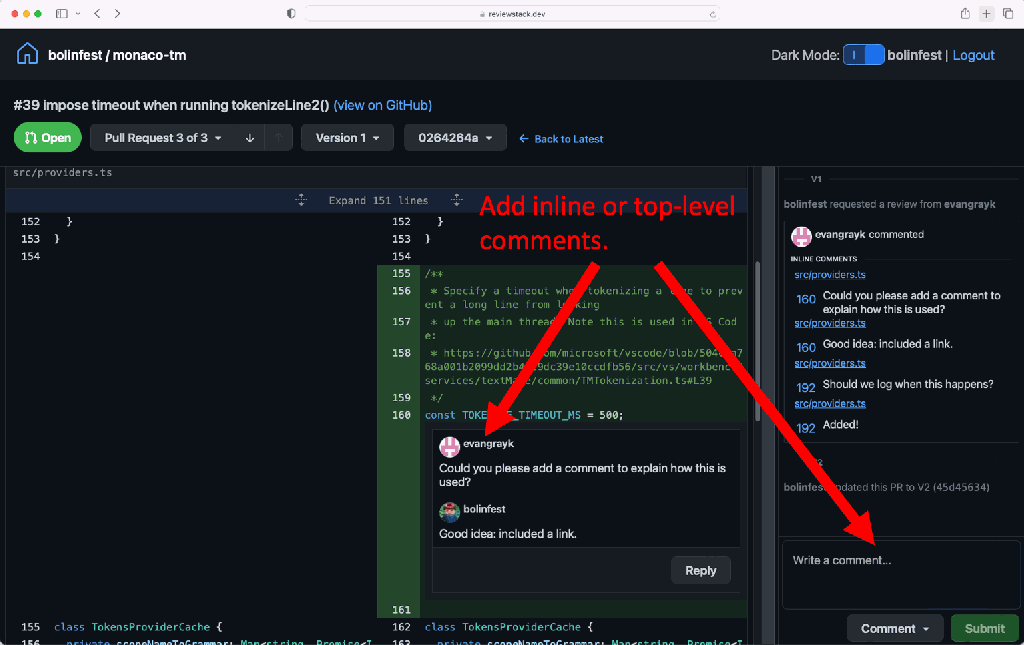
ReviewStack: Stack-oriented code review
Making it easy to work with stacks has many benefits: Commits become smaller, easier to reason about, and easier to review. But effectively reviewing stacks requires a code review tool that is tailored to them. Unfortunately, many external code review tools are optimized for reviewing the entire pull request at once instead of individual commits within the pull request. This makes it hard to have a conversation about individual commits and negates many of the benefits of having a stack of small, incremental, easy-to-understand commits.
Therefore, we put together a demonstration website that shows just how intuitive and powerful stacked commit review flows could be. Check out our example stacked GitHub pull request, or try it on your own pull request by visiting ReviewStack. You’ll see how you can view the conversation and signal pertaining to a specific commit on a single page, and you can easily move between different parts of the stack with the drop down and navigation buttons at the top.
Scaling Sapling
Note: Many of our scale features require using a Sapling-specific server and are therefore unavailable in our initial client release. We describe them here as a preview of things to come. When using Sapling with a Git repository, some of these optimizations will not apply.
Source control has numerous axes of growth, and making it scale requires addressing all of them: number of commits, files, branches, merges, length of file histories, size of files, and more. At its core, though, it breaks down into two parts: the history and the working copy.
Scaling history: Segmented Changelog and the art of being lazy
For large repositories, the history can be much larger than the size of the working copy you actually use. For instance, three-quarters of the 5.5 GB Linux kernel repo is the history. In Sapling, cloning the repository downloads almost no history. Instead, as you use the repository we download just the commits, trees, and files you actually need, which allows you to work with a repository that may be terabytes in size without having to actually download all of it. Although this requires being online, through efficient caching and indexes, we maintain a configurable ability to work offline in many common flows, like making a commit.
Beyond just lazily downloading data, we need to be able to efficiently query history. We cannot afford to download millions of commits just to find the common ancestor of two commits or to draw the Smartlog graph. To solve this, we developed the Segmented Changelog, which allows the downloading of the high-level shape of the commit graph from the server, taking just a few megabytes, and lazily filling in individual commit data later as necessary. This enables querying the graph relationship between any two commits in O(number-of-merges) time, with nothing but the segments and the position of the two commits in the segments. The result is that commands like smartlog are less than a second, regardless of how big the repository is.
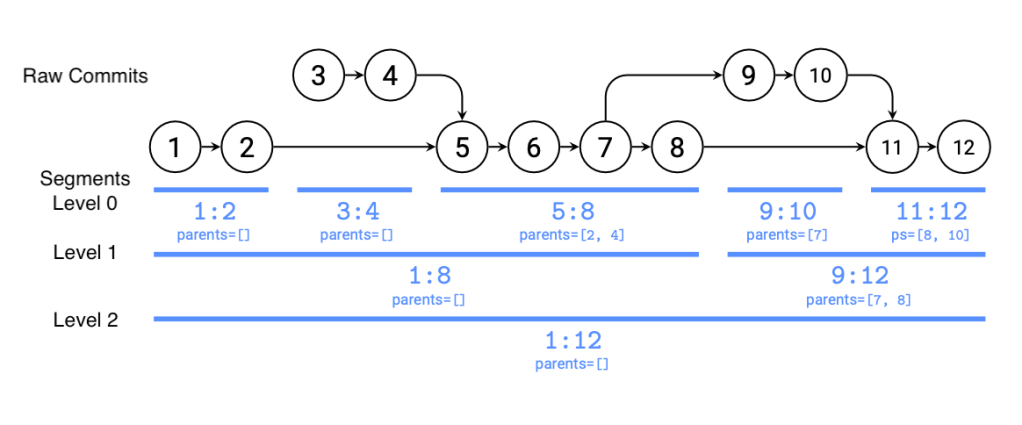
Segmented Changelog speeds up other algorithms as well. When running log or blame on a file, we’re able to bisect the segment graph to find the history in O(log n) time, instead of O(n), even in Git repositories. When used with our Sapling-specific server, we go even further, maintaining per-file history graphs that allow answering sl log FILE in less than a second, regardless of how old the file is.
Scaling the working copy: Virtual or Sparse
To scale the working copy, we’ve developed a virtual file system (not yet publicly available) that makes it look and act as if you have the entire repository. Clones and checkouts become very fast, and while accessing a file for the first time requires a network request, subsequent accesses are fast and prefetching mechanisms can warm the cache for your project.
Even without the virtual file system, we speed up sl status by utilizing Meta’s Watchman file system monitor to query which files have changed without scanning the entire working copy, and we have special support for sparse checkouts to allow checking out only part of the repository.
Sparse checkouts are particularly designed for easy use within large organizations. Instead of each developer configuring and maintaining their own list of which files should be included, organizations can commit “sparse profiles” into the repository. When a developer clones the repository, they can choose to enable the sparse profile for their particular product. As the product’s dependencies change over time, the sparse profile can be updated by the person changing the dependencies, and every other engineer will automatically receive the new sparse configuration when they checkout or rebase forward. This allows thousands of engineers to work on a constantly shifting subset of the repository without ever having to think about it.
To handle large files, Sapling even supports using a Git LFS server.
More to Come
The Sapling client is just the first chapter of this story. In the future, we aim to open-source the Sapling-compatible virtual file system, which enables working with arbitrarily large working copies and making checkouts fast, no matter how many files have changed.
Beyond that, we hope to open-source the Sapling-compatible server: the scalable, distributed source control Rust service we use at Meta to serve Sapling and (soon) Git repositories. The server enables a multitude of new source control experiences. With the server, you can incrementally migrate repositories into (or out of) the monorepo, allowing you to experiment with monorepos before committing to them. It also enables Commit Cloud, where all commits in your organization are uploaded as soon as they are made, and sharing code is as simple as sending your colleague a commit hash and having them run sl goto HASH.
The release of this post marks my 10th year of working on Sapling at Meta, almost to the day. It’s been a crazy journey, and a single blog post cannot cover all the amazing work the team has done over the last decade. I highly encourage you to check out our armchair walkthrough of Sapling’s cool features. I’d also like to thank the Mercurial open source community for all their collaboration and inspiration in the early days of Sapling, which started the journey to what it is today.
I hope you find Sapling as pleasant to use as we do, and that Sapling might start a conversation about the current state of source control and how we can all hold the bar higher for the source control of tomorrow. See the Getting Started page to try Sapling today.








