
- We’re sharing how we streamline system reliability investigations using a new AI-assisted root cause analysis system.
- The system uses a combination of heuristic-based retrieval and large language model-based ranking to speed up root cause identification during investigations.
- Our testing has shown this new system achieves 42% accuracy in identifying root causes for investigations at their creation time related to our web monorepo.
Investigation is a critical part of ensuring system reliability, and a prerequisite to mitigating issues quickly. This is why Meta is investing in advancing our suite of investigation tooling with tools like Hawkeye, which we use internally for debugging end-to-end machine learning workflows.
Now, we’re leveraging AI to advance our investigation tools even further. We’ve streamlined our investigations through a combination of heuristic-based retrieval and large language model (LLM)-based ranking to provide AI-assisted root cause analysis. During backtesting, this system has achieved promising results: 42% accuracy in identifying root causes for investigations at their creation time related to our web monorepo.
Investigations at Meta
Every investigation is unique. But identifying the root cause of an issue is necessary to mitigate it properly. Investigating issues in systems dependent on monolithic repositories can present scalability challenges due to the accumulating number of changes involved across many teams. In addition, responders need to build context on the investigation to start working on it, e.g., what is broken, which systems are involved, and who might be impacted.
These challenges can make investigating anomalies a complex and time consuming process. AI offers an opportunity to streamline the process, reducing the time needed and helping responders make better decisions. We focused on building a system capable of identifying potential code changes that might be the root cause for a given investigation.
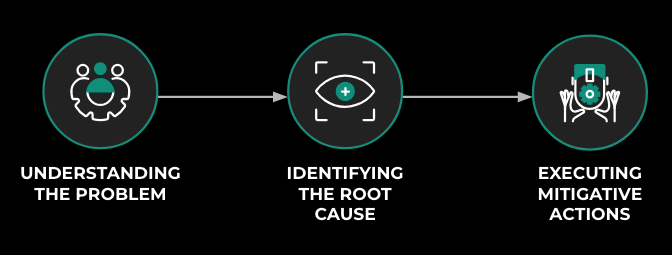
Our approach to root cause isolation
The system incorporates a novel heuristics-based retriever that is capable of reducing the search space from thousands of changes to a few hundred without significant reduction in accuracy using, for example., code and directory ownership or exploring the runtime code graph of impacted systems. Once we have reduced the search space to a few hundred changes relevant to the ongoing investigation, we rely on a LLM-based ranker system to identify the root cause across these changes.
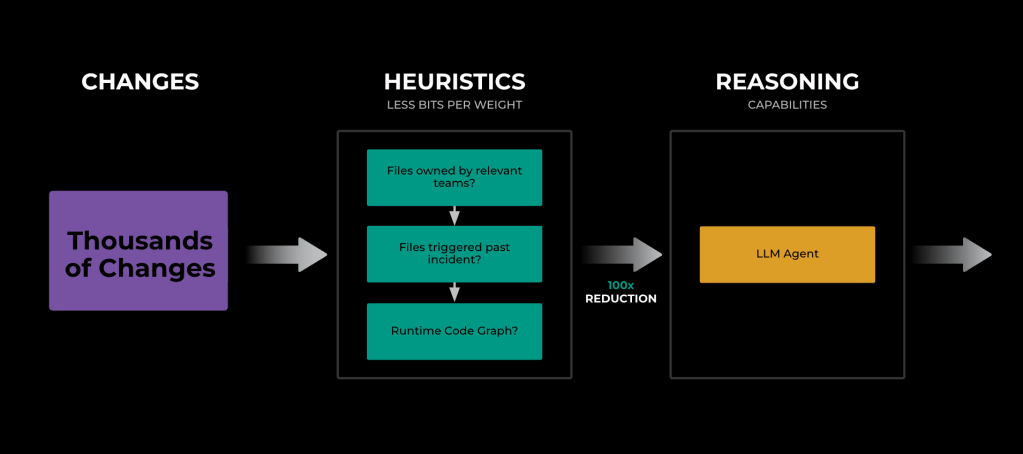
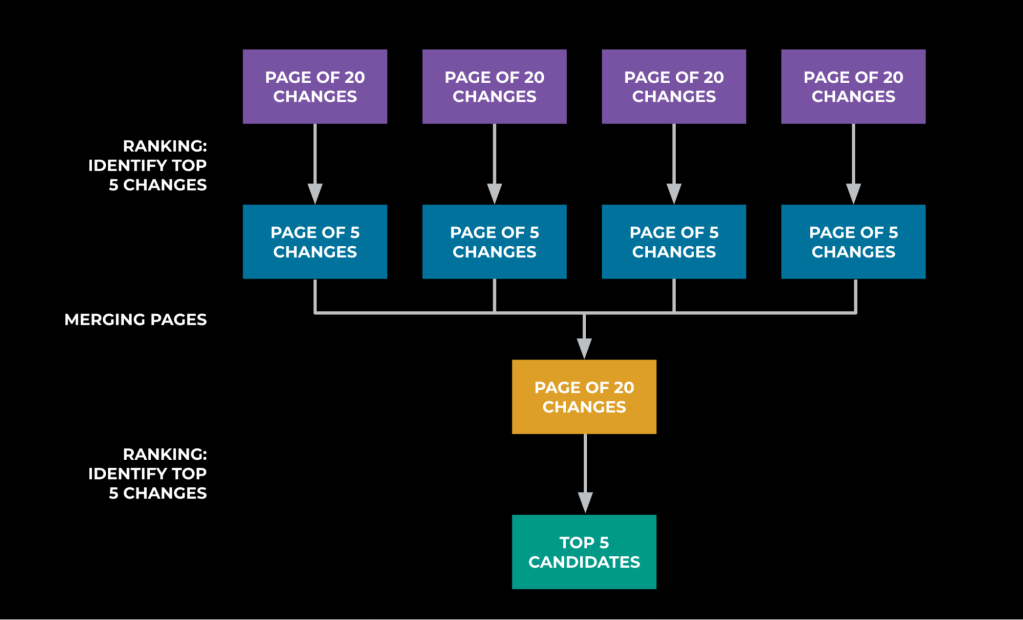
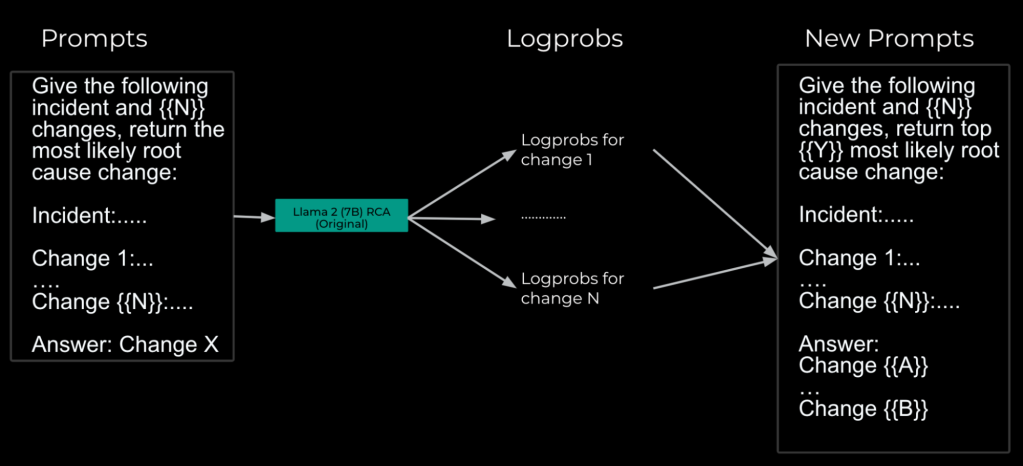
The ranker system uses a Llama model to further reduce the search space from hundreds of potential code changes to a list of the top five. We explored different ranking algorithms and prompting scenarios and found that ranking through election was most effective to accommodate context window limitations and enable the model to reason across different changes. To rank the changes, we structure prompts to contain a maximum of 20 changes at a time, asking the LLM to identify the top five changes. The output across the LLM requests are aggregated and the process is repeated until we have only five candidates left. Based on exhaustive backtesting, with historical investigations and the information available at their start, 42% of these investigations had the root cause in the top five suggested code changes.
Training
The biggest lever to achieving 42% accuracy was fine-tuning a Llama 2 (7B) model using historical investigations for which we knew the underlying root cause. We started by running continued pre-training (CPT) using limited and approved internal wikis, Q&As, and code to expose the model to Meta artifacts. Later, we ran a supervised fine-tuning (SFT) phase where we mixed Llama 2’s original SFT data with more internal context and a dedicated investigation root cause analysis (RCA) SFT dataset to teach the model to follow RCA instructions.
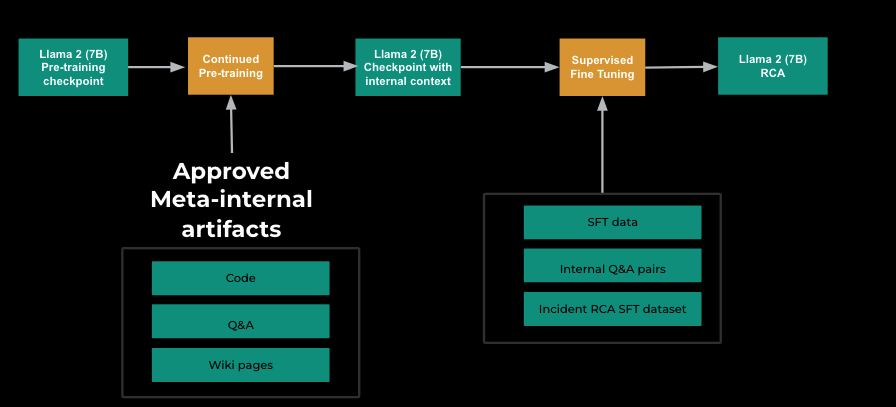
Our RCA SFT dataset consists of ~5,000 instruction-tuning examples with details of 2-20 changes from our retriever, including the known root cause, and information known about the investigation at its start, e.g., its title and observed impact. Naturally, the available information density is low at this point, however this allows us to perform better in similar real-world scenarios when we have limited information at the beginning of the investigation.
Using the same fine-tuning data format for each possible culprit then allows us to gather the model’s llog probabilities(logprobs) and rank our search space based on relevancy to a given investigation. We then curated a set of similar fine-tuning examples where we expect the model to yield a list of potential code changes likely responsible for the issue ordered by their logprobs-ranked relevance, with the expected root cause at the start. Appending this new dataset to the original RCA SFT dataset and re-running SFT gives the model the ability to respond appropriately to prompts asking for ranked lists of changes relevant to the investigation.
The future of AI-assisted Investigations
The application of AI in this context presents both opportunities and risks. For instance, it can reduce effort and time needed to root cause an investigation significantly, but it can potentially suggest wrong root causes and mislead engineers. To mitigate this, we ensure that all employee-facing features prioritize closed feedback loops and explainability of results. This strategy ensures that responders can independently reproduce the results generated by our systems to validate their results. We also rely on confidence measurement methodologies to detect low confidence answers and avoid recommending them to the users – sacrificing reach in favor of precision.
By integrating AI-based systems into our internal tools we’ve successfully leveraged them for tasks like onboarding engineers to investigations and root cause isolation. Looking ahead, we envision expanding the capabilities of these systems to autonomously execute full workflows and validate their results. Additionally, we anticipate that we can further streamline the development process by utilizing AI to detect potential incidents prior to code push, thereby proactively mitigating risks before they arise.
Acknowledgements
We wish to thank contributors to this effort across many teams throughout Meta, particularly Alexandra Antiochou, Beliz Gokkaya, Julian Smida, Keito Uchiyama, Shubham Somani; and our leadership: Alexey Subach, Ahmad Mamdouh Abdou, Shahin Sefati, Shah Rahman, Sharon Zeng, and Zach Rait.








