
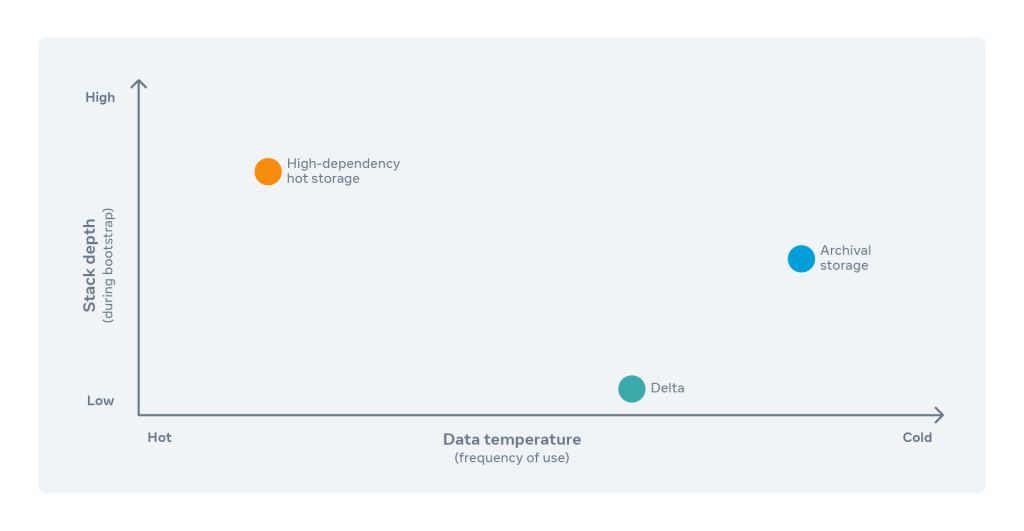
Over the years, Meta has invested in a number of storage service offerings that cater to different use cases and workload characteristics. Along the way, we’ve aimed to reduce and converge the systems in the storage space. At the same time, having a dedicated solution for critical package workload makes everyone happier. Having this in place is necessary for our disaster recovery and bootstrap strategy. This realization, coupled with a business need to provide storage for Meta’s build and distribution artifacts, led to the inception of a new object storage service — Delta.
Consider Delta’s positioning in the Meta infrastructure stack (below). It belongs at the very bottom, providing the basic primitive required for the availability and recoverability of the rest of the infrastructure. For bootstrap systems, complexity should be introduced only if it makes the solution more reliable. We’re only minimally concerned with the performance and efficiency of the solution. Another consideration for bootstrap systems involves the bootstrap itself. This process, by which engineers can access a small set of machines and restore the rest of our infrastructure, helps us get the product back up and working for people using it. Lastly, the bootstrap data needs to be backed up for recovery in case disaster strikes.
In this post, we will discuss the goals for Delta, the main concepts that govern Delta’s architecture, Delta’s production use cases, its evolution as a recovery provider, and future work items.
What is Delta?
Delta is a simple, reliable, scalable, low-dependency object storage system. It features only four high-level operations: put, get, delete, and list. Delta trades latency and storage efficiency in favor of simplicity and reliability. Since it’s horizontally scalable, Delta takes on minimal dependencies with appropriate failover strategies for soft dependencies in place.
Delta is not a:
- General purpose storage system: Delta’s core tenets are resiliency and data protection. It’s designed specifically to be used by low-dependency systems.
- Filesystem: Delta acts as a simple object storage system. It doesn’t intend to expose filesystem semantics like Posix etc.
- System optimized for maximum storage efficiency: With resiliency as its primary tenet and focus on critical systems, Delta doesn’t intend to optimize for storage efficiency, latency, or throughput.
Delta’s architecture
Delta has productionized chain replication, an approach to coordinating clusters of fail-stop storage servers. It intends to support large-scale storage services that exhibit high throughput and availability, without sacrificing strong consistency guarantees.
Before diving deeper into how Delta leverages chain replication to replicate client data, let’s first explore the basics of chain replication.
Chain replication
Fundamentally, chain replication organizes servers in a chain in a linear fashion. Much like a linked list, each chain involves a set of hosts that redundantly store replicas of objects.
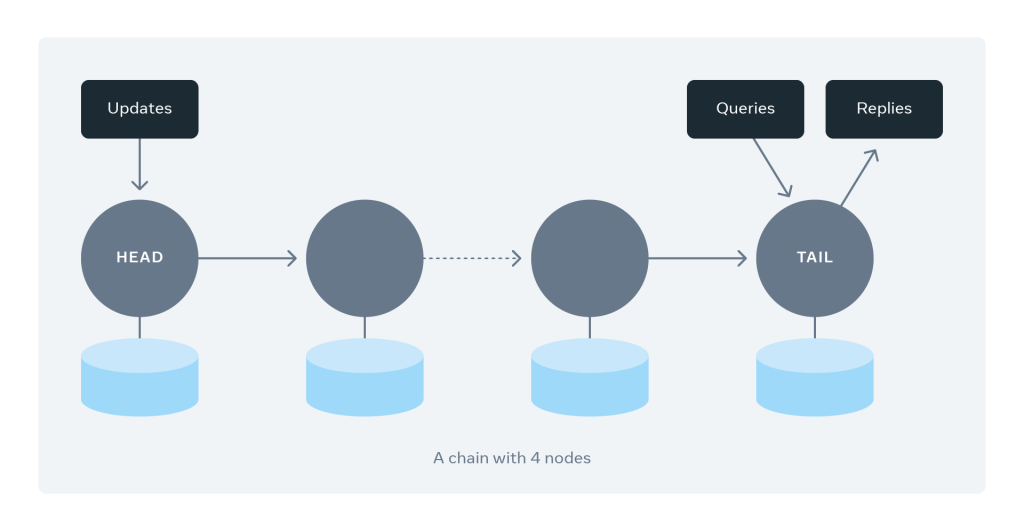
Each chain contains a sequence of servers. We call the first server the head and the last one the tail. The figure below shows an example of a chain with four servers. Each write request gets directed to the head server. The update pipelines from the head server to the tail server through the chain. Once all the servers have persisted the update, the tail responds to the write request. Read requests are directed only to tail servers. What a client can read from the tail of the chain replicates across all servers belonging to the chain, guaranteeing strong consistency.
Chain replication vs. quorum replication
Now that we have provided an overview of what chain replication entails, let’s explore how chain replication fares against other widely used replication strategies.
- Storage efficiency: Chain replication clearly does not offer the most storage-efficient replication strategy. We store redundant copies of the whole data set on all hosts in a chain. A comparatively efficient approach would involve intelligently replicating fragments of data using erasure coding techniques.
- Fault tolerance: In an optimal bucket layout, chain replication can provide similar or better fault tolerance than quorum-based replication mechanisms. Why? A chain with `n` nodes can tolerate failures up to `n – 2` nodes without compromising on availability. On the contrary, for quorum-based replication systems, at least `w` hosts must be available to serve writes. Additionally, `r` hosts must be available to serve reads. Here `w` and `r` represent the write quorum size and read quorum size, respectively.
- Performance: In replication strategies (like primary backup), all backup servers can serve reads. This increases read throughput. In the native idea of chain replication, only the chain tail can serve reads. (We optimized this bit and will share details in the apportioned queries section later in this post.) Much like quorum-based replication mechanisms, in chain replication all writes are directed to the primary (the head of the chain). But in chain replication, writes are only responded to after all hosts in the chain have acknowledged the update. Thus, chain replication has higher write latency on average in comparison with quorum-based replication mechanisms.
- Quorum consensus: Quorum-based systems need complex consensus and leader election mechanisms to maintain quorum in the system. In contrast, the scope of quorum consensus in a chain-replication based system gets narrowed down to the much simpler, chain-host mapping. For example, the chain head always serves as a leader for processing writes, without the need for an explicit leader election.
Considering the above differences, chain replication clearly fails to offer the most storage-efficient way to replicate data across machines. Additionally, it yields higher average write latency in comparison to quorum-based systems, as we consider writes successful only when all links in a chain have persisted the update. However, it’s very simple while offering similar fault tolerance and consistency guarantees.
The anatomy of a Delta bucket
Now that we have a preliminary understanding of chain replication, let’s talk about how Delta leverages it to replicate data across multiple servers.
Each Delta bucket above includes several chains. Each chain usually consists of four or more servers, which can vary based on the desired replication factor. Each chain itself acts as a replica set and serves a slice of data and traffic. It can be thought of as a logical shard of a client data set. Servers in a particular chain get spread across different failure domains (power, network, etc.). Doing so guarantees durability and availability of client data if servers in one or more failure domains remain unavailable. We maintain a bucket config, the authoritative chain-host mapping for the layout of the bucket. When we add or remove servers and chains from the bucket, the bucket config gets appropriately updated.
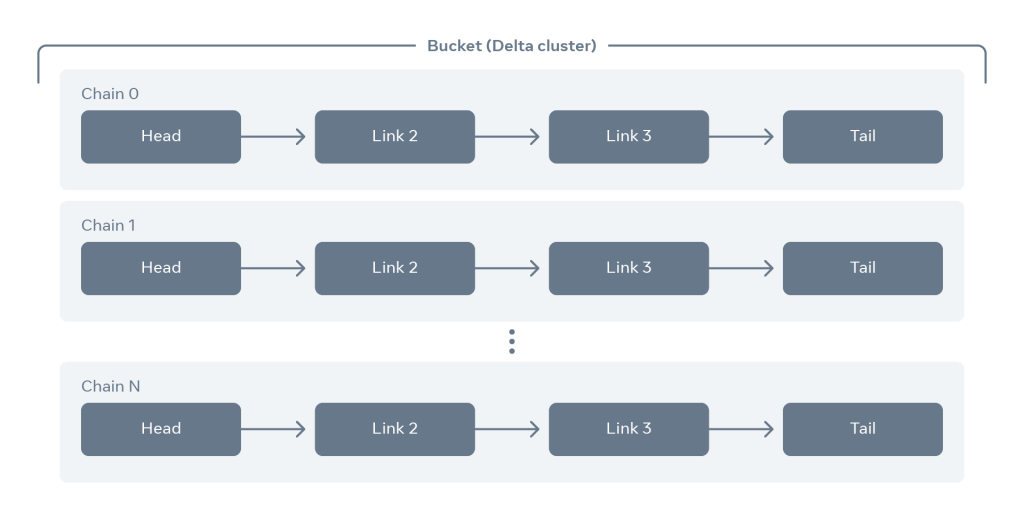
When clients access an object within a Delta bucket, a consistent hash of the object name selects the appropriate chain. Writes are always directed to the head of the appropriate chain. It writes the data to the local storage and forwards the write to the next host in the chain. The write is acknowledged only after the last host in the chain has durably stored the data on local media. Reads are always directed to the tail of the appropriate chain. This guarantees that only fully replicated data is visible and readable, thereby guaranteeing strong consistency.
Delta supports horizontal scalability by adding new servers into the bucket and smartly rebalancing chains to the newly added servers without affecting the service’s availability and throughput. As an example, one tactic is to have servers with the most chains transfer some chains to new servers as a way to rebalance the load. New bucket layouts would still follow the desirable failure-domain distribution, etc., and are employed while rebalancing chains and expanding bucket capacity.
Failure and recovery modes in Delta
Failures can stem from hosts going down, networks being partitioned, planned maintenance activities, operational mishaps, or other unintended events. In a suitable implementation of chain replication, we assume servers to be fail-stop. In other words:
- Each server halts in response to a failure rather than making erroneous state transitions.
- A server’s halted state can be detected by the environment.
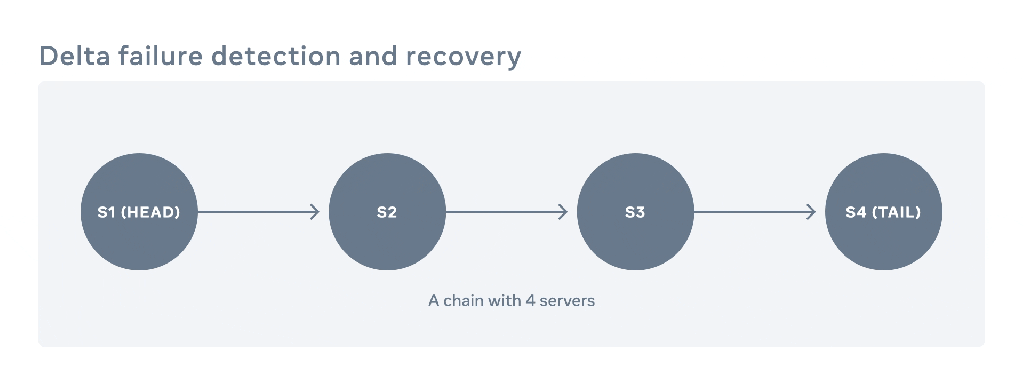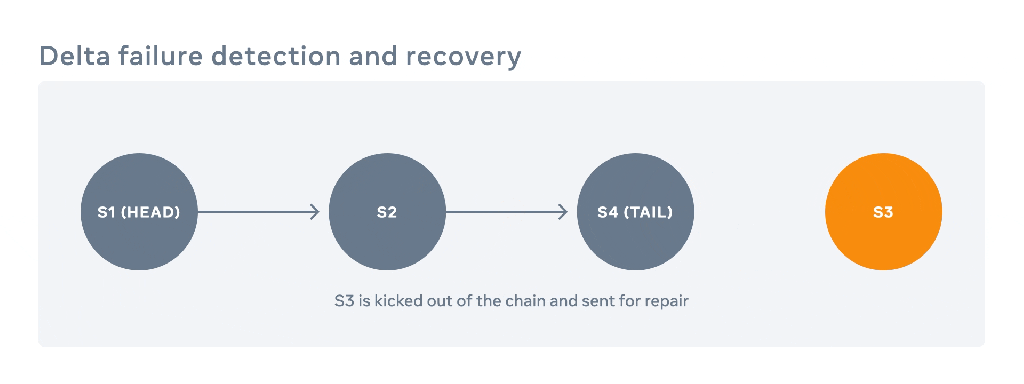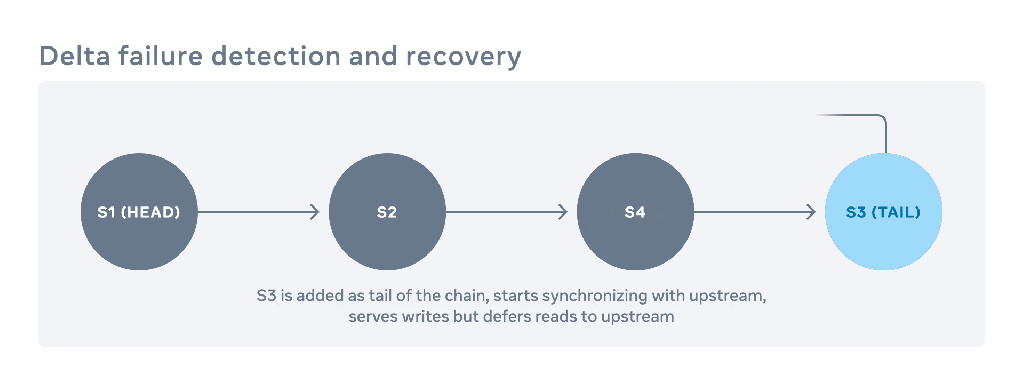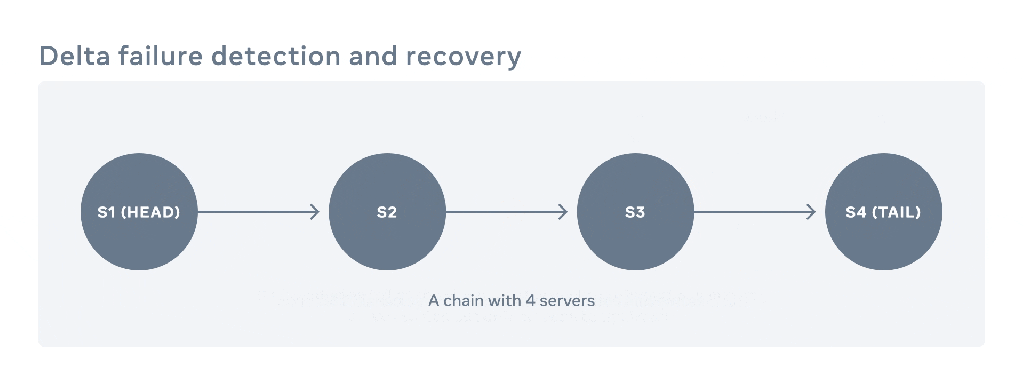
Consider a Delta bucket with `n` chains, with each chain comprising >1 host. In the event of any host misbehaving or getting partitioned from the network, the other sibling hosts (upstream/downstream) sharing a chain with the culprit host would be able to detect the suspicious host and report this behavior.
Sibling hosts can detect the erroneous behavior of misbehaving hosts by simple heartbeats or by encountering failures in transmitting acknowledgments/requests up/down the chain. If multiple hosts suspect a particular target host, the latter gets kicked out of all its chains and sent for repair. The bucket config gets updated appropriately.
Some decisions and trade-offs must occur when detecting unhealthy behavior in a host:
- Timeout settings: We conducted several performance tests to arrive at the right timeout settings. We need to carefully assess the timeout between individual links in a chain before suspecting a host. We can’t set the timeout too short because servers can always experience transient network issues. We can’t set the timeout too long, either, because doing so would negatively affect operation latency. Not only that, but clients may also timeout while awaiting a valid response.
- Suspicious host voting settings: We need to assess how many hosts should vote for a particular one being unhealthy before the suspected host is kicked out of its chains. The limit can’t be one since it’s always possible for two hosts in a chain to vote each other as unhealthy. This would cause both hosts to be disabled from their chains. The limit can’t be too large, either, as this would lead to the unhealthy host staying in the fleet for an extended period and negatively impacting service performance. Each host belongs to multiple chains and is guaranteed frequent connections with upstream and downstream nodes in their chains. As a result, setting the suspicion voting limit to two has worked well for us. Additionally, we have automated the faulty host repair flow. This provides us with the flexibility to configure sensitive thresholds and have more false positives.
Once the faulty host recovers, it can be added back to all the chains that it served prior to getting kicked out of the bucket. New hosts are always added to the rear end of the chains. Upon being added back to the chains, this host must synchronize itself with all the updates on the chain that occurred while it was not part of the chain. This process consists of scanning the objects on the upstream host and copying those not present or that have an obsolete version. Notably, during this interval of reconstruction, the host can still accept new writes from upstream. However, until it’s fully synchronized with the upstream host, it must defer reads to upstream.
We use this process for adding both suspected hosts as well as introducing new capacity to a Delta bucket.
How Delta has evolved over time
Apportioned queries
As evident from the above description, there are a few major inefficiencies with serving reads in chain replication.
- The tail, the only node serving both reads and writes, can become a hotspot.
- Considering that the tail serves all reads, the tail of the chain limits read throughput.
In order to mitigate these limitations, we can let all nodes in the chain serve reads via the idea of chain replication with apportioned queries.
The basic idea? Each node serves read requests. But before responding to client read requests, it does a crucial check. It verifies whether the requested object’s local copy is clean or has been committed by all the servers in the chain. It may alternatively assess it as dirty, meaning the object does not replicate to all servers in the chain. The server can just return the last committed version of the object back to the client. This ensures that clients get only the object version that has been committed by all servers in the chain, thereby retaining chain replication’s strong consistency guarantees. The tail node would serve as the authority of the latest clean version for a particular object.
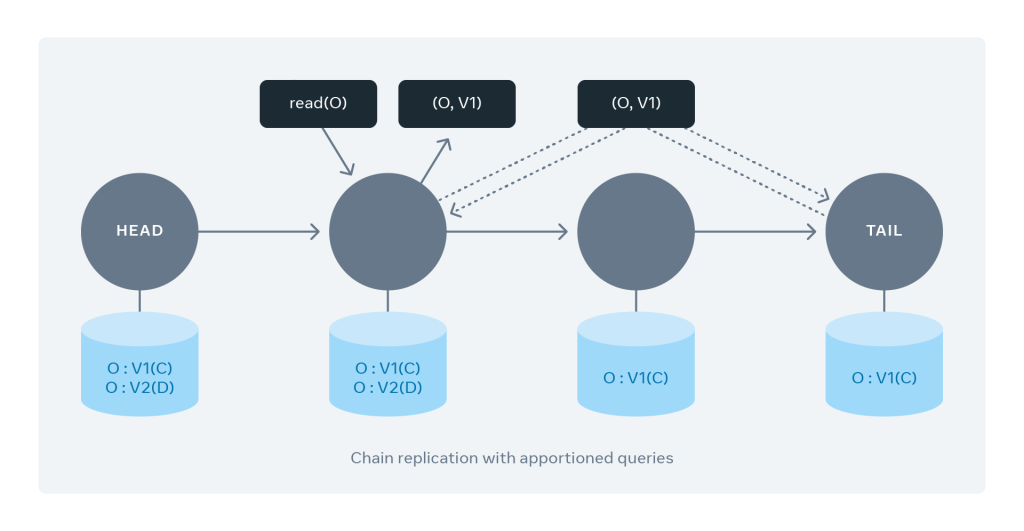
As explained above, each non-tail link in the chain makes an additional network call to the chain tail. It does so to fetch the clean version of an object before responding to the client reads. This additional network call to the tail link offers great value. Why? It helps scale the read throughput and chain bandwidth linearly with the chain length. Additionally, these object version check calls are cheaper in comparison with serving actual client reads. Hence, they don’t negatively affect client latency in a significant way.
Automated repair
While hardware failures or network partitions may seem rare, they occur fairly frequently in large clusters. As such, failure detection, host repair, and recovery should be automated to avoid frequent manual interventions.
We built out a control plane service (CPS) responsible for automating Delta’s fleet management. Each instance of the CPS gets configured to monitor a list of Delta buckets. Its primary function includes repairing chains that have missing links.
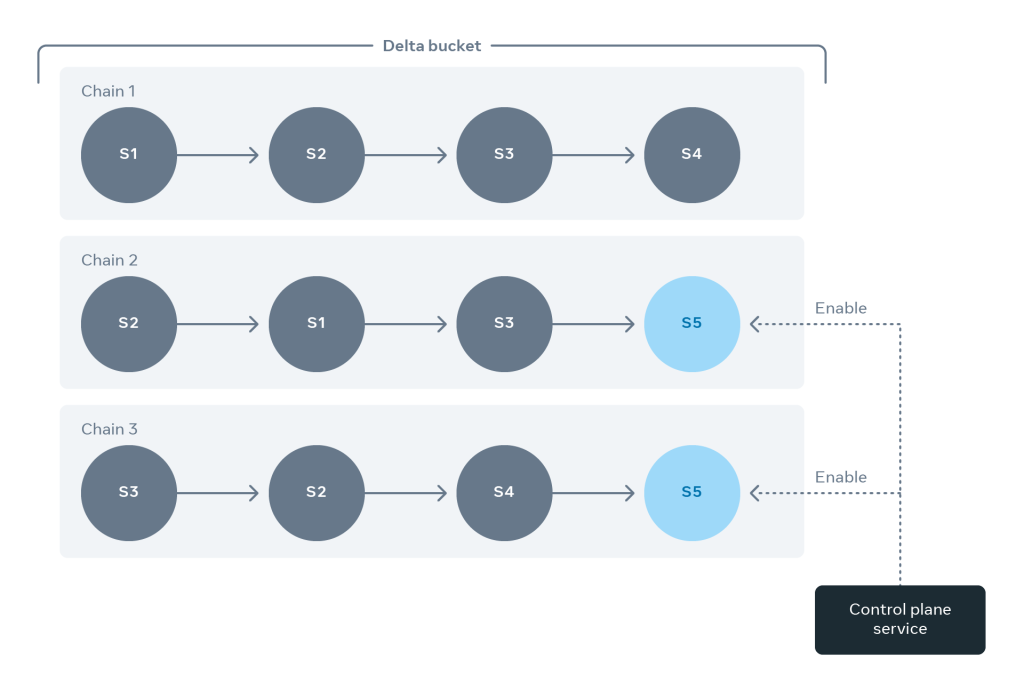
When repairing chains, the CPS applies a few techniques to achieve maximum efficiency:
- When repairing a bucket, the CPS must maintain the failure domain distribution of all chains in the bucket layout. This ensures that the bucket hosts are spread evenly across all failure domains.
- The CPS must ensure a uniform chain distribution on all servers. In this way, we avoid a few servers getting overloaded by hosting significantly more chains in contrast to other hosts.
- When a chain has a missing link, the CPS would prioritize repairing the chain with the original host rather than a new one. Why is that? Resyncing all chain contents to a new host gets compute-intensive in comparison with syncing partial chain contents to the original host once it returns from repair.
- Before enabling a host to a chain, the CPS would perform detailed sanity checks to ensure that a healthy host gets added back to the bucket.
- Apart from managing the servers in the bucket, the CPS would also maintain a pool of healthy standby servers. In the event of a chain missing more than 50 percent of its hosts, the CPS would add a fresh standby host to the chain. This ensures that no severely underhosted chain jeopardizes the availability of the bucket. While doing this, the CPS would attempt to apply all the above principles in a best-effort manner.
Global replication
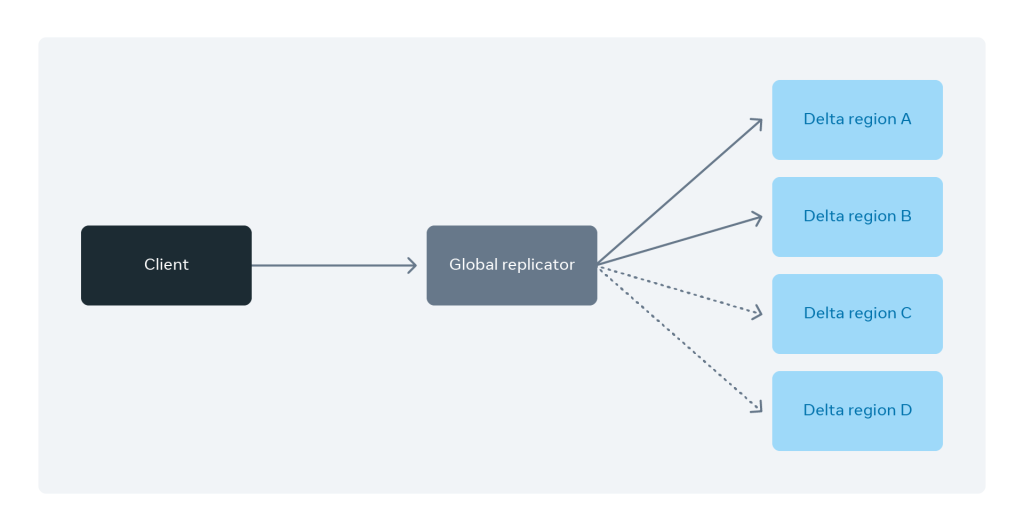
In Delta’s original implementation, when Delta clients wanted to store a blob in multiple regions due to data safety considerations, they made a request to each region. This is clearly not ideal from a user point of view. Delta’s users should not be in the business of tracking object location(s) while being able to control the level of redundancy and geo-distribution preferences. A client app should be able to just put an object to the store once and expect the underlying service fabric to propagate the change everywhere. The same goes for retrievals. In the steady state, the clients can expect to just get an object by submitting a request and letting the service retrieve it from the most optimal source available at the moment.
As our service evolved, we introduced global replication to client regions. This is done in a hybrid fashion — a combination of synchronously replicating blobs to a few regions and asynchronously replicating blobs to the remaining set of regions. Replicating to a few regions synchronously reduces the client latency while ensuring that other regions get the blob in an eventually consistent manner. Imagine that a particular region experiences a network partition or outage. The system would be intelligent enough to exclude that region from participating in geo-replication until it returns. Then that region could be asynchronously backfilled with the missing blobs.
How Delta handles disaster recovery
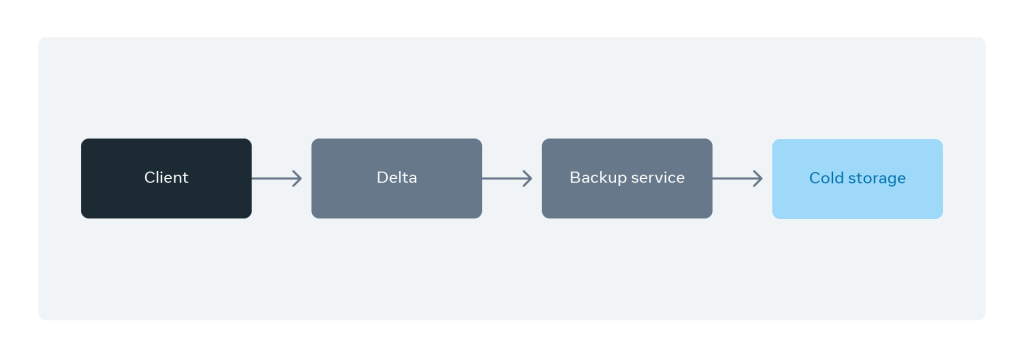
One of Delta’s key tenets is to be as low-dependency as possible. Along with having minimal dependencies, we also invested in having a reliable disaster recovery story.
As of now, we have integrated with archival services to continuously back up client blobs to cold storage. Additionally, we have developed the ability to continuously restore objects from these archival services. Out-of-box integration with archival services provides us with reliable recoverability guarantees in severely degraded environments. We have several partner teams that have integrated with our service because of our disaster recovery guarantees.
What’s next for Delta?
Looking ahead, we are working on a centralized backup and restore service for core infrastructure services within Meta based on Delta storage. Any reliable stateful service must be able to produce a snapshot of its internal state (backups) and rehydrate the internal state from a snapshot (restore). Our ultimate goal is to position ourselves as a gateway to all archival services and provide a centralized backup offering to our clients. Additionally, we also plan on investing heavily toward improving the reliability of Delta’s disaster preparedness and recovery story. This will help us serve as a reliable and robust recovery provider for our users.








