
One of the biggest questions faced by the recommendation systems community is whether recommendation systems should be solely evaluated by their predictive accuracy, or also focus on other factors such as preference broadening. In order to appreciate the importance of this question, let us look at a couple of simulated scenarios in a dynamic setting.
User preferences in a dynamic setting
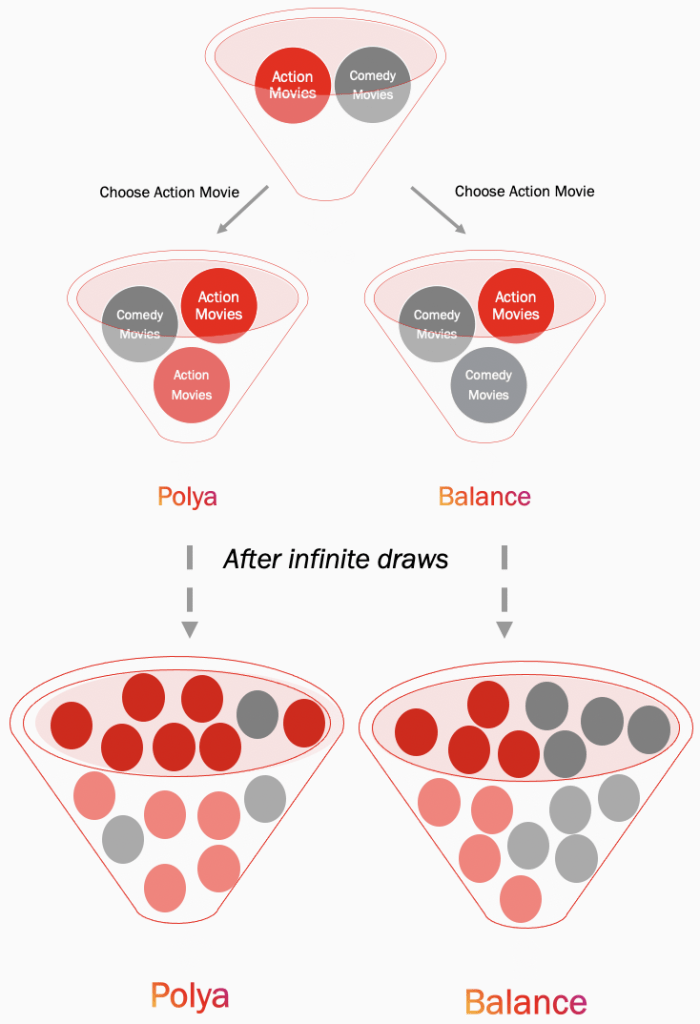
Imagine we have an equal preference towards action movies and comedy movies. Now, suppose these preferences are denoted by two marbles in an urn, red and gray (meaning initially they are equally preferred). The color red denotes action movies and the color gray denotes comedy movies. Next, let us consider two simple models of how our preferences could evolve dynamically.
Personalize: In this model, we randomly draw a marble from the urn and watch a movie from the corresponding genre. After drawing the marble, we place it back and add another marble of the same color. So, if we picked a red marble in the first instance, in the next instance the urn has two red marbles and one gray marble. This model positively reinforces our choices, meaning showing us more of what we like. Eventually after thousands of draws, the urn will be full of one kind of marble and it will be very hard to draw the other kind, even randomly. This process is known as the Polya process. Polya processes are an excellent toy model for understanding self-reinforcing dynamical systems. They have equally likely path dependent outcomes. Meaning, if everything is equally likely, after 100 draws, the probability that the urn contains 85 red marbles is equal to the probability that it contains 1 red marble. But no matter which path is chosen, at equilibrium state (after infinite draws) one choice heavily dominates the other one. Analogically speaking, if a user is simply shown more of what she prefers currently, she could be stuck in a small universe of choices.
Balance: In the second model, we draw a marble randomly from the urn, place it back, and add another marble of the opposite color. So, if we picked a red marble in the first instance, in the next instance the urn has one red marble and two gray marbles. This model negatively reinforces our choices, meaning showing us less of what we like. Eventually after infinite draws the urn converges to equal proportions of each color. This process is known as the balancing process. Balancing processes are an excellent toy model for self-balancing dynamical systems. Analogically speaking, if we diversify aggressively based on a user’s current preferences, we would expose her to a large set of possible choices but would never really engage her in the short run.
Theoretically, on one hand we could have a Polya process-based system which would engage a user heavily in the short run but would lead to boredom, loss of engagement and lack of preference broadening in the long run. On the other hand, we could have a balancing process based system which doesn’t lead to any immediate engagement but is good for maintaining long term preferential diversity. So, which way do we lean? We’ll outline some practical methods that machine learning practitioners can follow to take the proverbial “middle path” between these extremes in creating wholesome experiences in the long run with minor short term trade-offs.
But before that, let’s discuss some basics.
What are preferences like in the real world?
In our toy models, using a simplistic argument we could denote preferences simply as marbles in an urn: static, precise, and single-dimensional. In reality, preferences have all the following complexities:
- Multidimensional: A user is equally likely to have a deeper engagement with a “dark comedy” which contains both the elements of a dark thriller and a general comedy.
- Soft: A user may display varying degree of affinity towards content types, meaning 35 percent affinity towards comedy and 99 percent towards sports.
- Contextual: Preferences are contextual in terms of previous set of choices made, the way choices are presented, current trends and a plethora of other factors.
- Dynamic: Most importantly, preferences change over a period of time. A person who loves historical documentaries currently, may not find them engaging a month later.
Philosophically the problem of diversifying recommendations sounds similar to the explore-exploit tradeoff. In reinforcement learning settings optimality of choices/paths and rewards could be reasonably well defined. But the hidden rules of human preferences and psyche could change after every session.
Given these complexities, it is challenging to come up with a closed form solution to this optimization problem or even be able to define a single objective function. Below we will discuss some practical heuristics that could help us provide a more diversified user experience given rigorous quantitative and qualitative evaluations.
Practical methods of diversification
- Author level diversity: What should one do if the same author keeps appearing in a single user’s session multiple times? Simple stratification to pick ranking candidates from different authors might improve overall user experience.
- Media type level: For a heterogeneous platform which supports many media types, like photos, albums, short-videos, long-videos etc., if possible it is best to diversify the media types from a sequence perspective. Example: If the ranking algorithm picks three videos followed by two photos to be shown, it is advisable to intermix the photos and videos if it doesn’t hurt the overall quantitative/qualitative metrics.
- Semantic diversity: A user may get recommended basketball videos from multiple authors in the same session. This is the most challenging kind of diversity to maintain. The best way to diversify at a content level is to first design a high quality content understanding system. At Instagram we have built some of the state-of-art photo understanding, video understanding and text understanding systems at scale. They can provide both granular and general understanding of a media item. Example: A photo could be about birds, sunset and a tiger at a granular level. It could also be about nature and wildlife photography at a higher semantic level. If we could classify a user’s preferences as a cloud of concepts (with affinities) it then becomes easier to sample across different concepts and hence provide a more diverse experience.
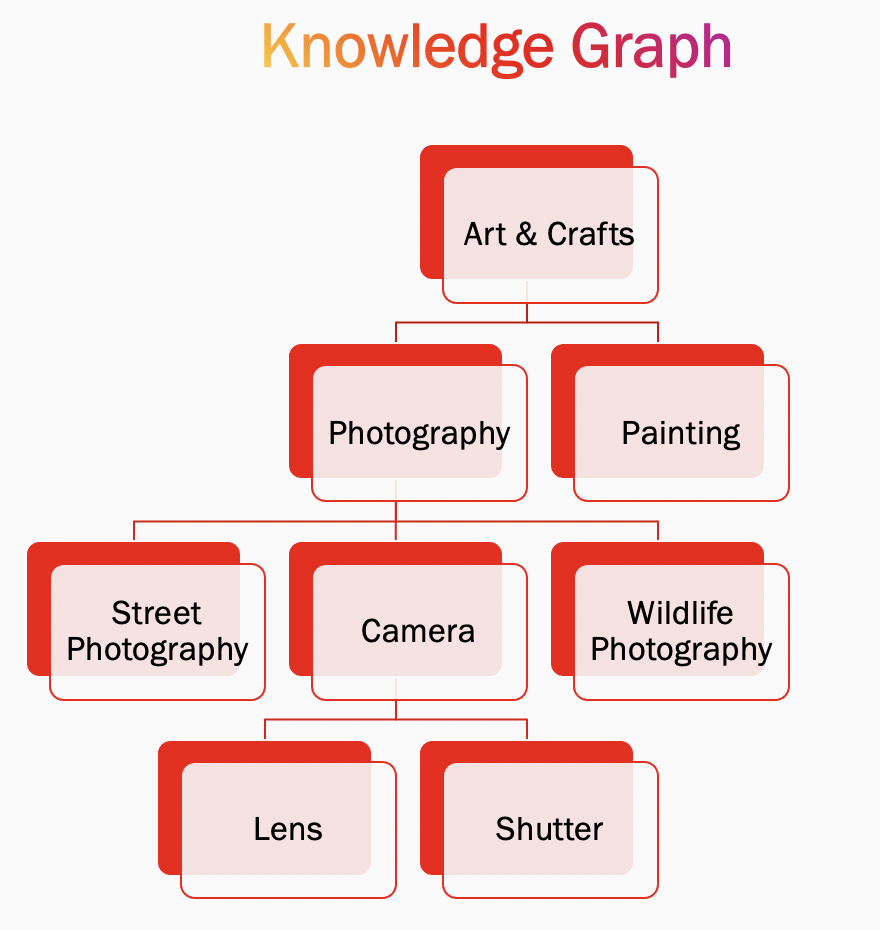
- Exploring similar semantic nodes: Most content understanding systems represent knowledge in the form for a graph or a tree. For example, Wildlife Photography could be a lower level concept leading up to Photography, which in turns leads up to Arts & Crafts. Once we know the major concepts that a user is generally interested in, we could explore the following avenues:
- Explore the parents, siblings, and children of concepts: If a user is interested in wildlife photography, it is likely the they might be interested in the head concept photography, a sibling of the head concept say painting, sibling concepts like street photography or child concepts of another sibling like lens. Exploring these concepts on users — based on machine learning centric evidence that similar users love them too — could definitely lead to a more diversified experience.
- Tail matters: A user may have never been exposed to thousands of niche concepts (Example: Manga, folk dance festivals, hard science fiction) that similar people may have found interesting. Exploring them might lead to a more diversified experience.
- Multimodal items: Items which capture multiple modes are typically good candidates for exploration. For example, if a user is highly interested in machine learning and wildlife photography, perhaps a blog post about applying ML techniques for wildlife preservation might be of very high interest to them.
- Maintaining long and short term preferences: We all have things we are generally interested in, and perhaps a few things we are heavily interested in at a given point of time. Maintaining two separate priority queues denoting a user’s long and short term interests could lead to better diversification in the long run.
- Utilizing explore-exploit tradeoff algorithms: The explore-exploit trade-off techniques from reinforcement learning can provide a systematic mechanism to diversify user preferences. Here are a couple of examples:
- Epsilon-greedy: In this method we personalize without any semantic diversification but every once in a while we simply expose the user to a near-similar item randomly.
- Upper confidence bound: Let us say we know that a user has shown moderate engagement towards some concepts but has not been exposed to them enough. We could thus explore all the moderate interest concepts on a user, sufficient number of times, before we have enough confidence about excluding them.
- Qualitative trade off computation: We at Instagram value qualitative measures like user satisfaction and sentiment just as much as we value quantitative metrics like ROC-AUC or NDCG. We conduct qualitative research, user surveys, diary studies etc. to figure out the general tolerance for repetitiveness and appetite for diversity. We take many of our eventual model deployment decisions based on how much qualitative confidence we have on a certain modeling approach.
- Negative Guardrails: Users dislike any kind of repetitiveness themselves and will provide explicit negative feedback some times (not always). Negative feedback involves user actions such as; clicking on “not interested” or clicking on “show fewer videos like these” buttons. We account for these negative signals and use them as our guardrails. We have built specific ML models which reduce negative feedback. We tune these models on offline simulations and insights derived from user satisfaction surveys.
Parting Words
Being solely driven by machine learning-centric metrics like NDCG or product-centric metrics like number of likes could lead to eventual boredom and disengagement. Keeping these factors in mind, we recommend optimizing for long term user satisfaction. If you want to learn more about this work or are interested in joining one of our engineering teams, please visit our careers page, follow us on Facebook.








