
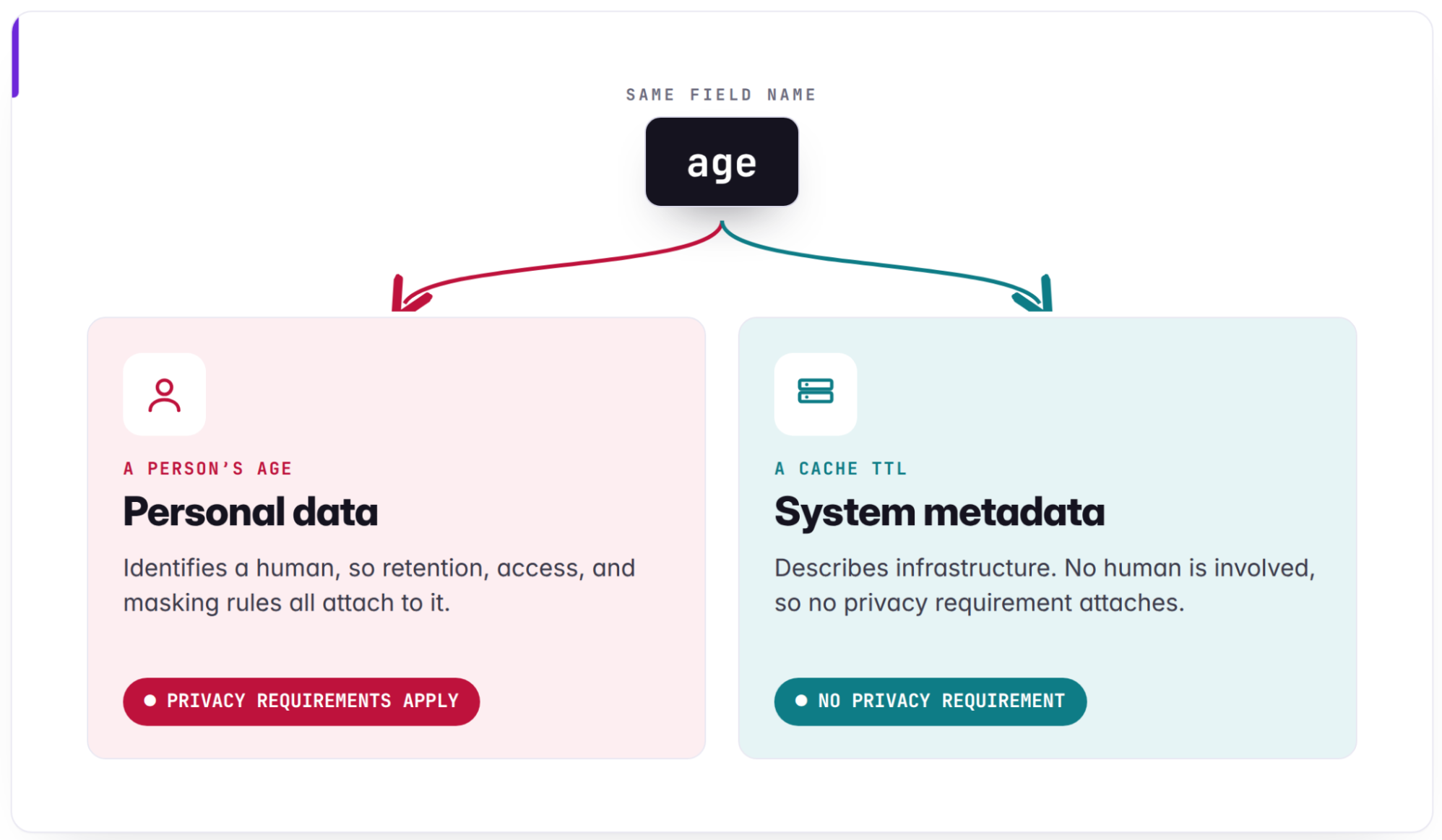
Privacy controls — systems that enforce retention, access, allowed-purpose, downstream-sharing, or anonymization policies — require a reliable understanding of data to function. Before such a control can operate effectively, it must know exactly what it is looking at. This can be complex, as demonstrated by a field simply named “age“: In one context, it might describe a person and require strict protections, while in another, it could be a cache time-to-live (TTL) numerical value in an infrastructure pipeline.
This is the everyday problem behind privacy-aware infrastructure (PAI): The inputs are noisy and probabilistic, but the outputs need to be precise enough to drive enforcement.
AI-native products make that problem harder. They introduce new data modalities, faster iteration cycles, derived features, embeddings, multimodal inputs, and changing policy interpretations. Manual review remains important for judgment and accountability, but it cannot keep up with the volume and pace of change.
At Meta, we apply a hybrid pattern for asset classification at scale:
- Build a rich context before asking a model to reason.
- Use LLMs to handle ambiguity, cold start, and novelty.
- Keep human-reviewed labels separate from model-generated recommendations.
- Distill stable behavior into deterministic, versioned rules for routine enforcement.
The end goal is not “LLMs everywhere.” Instead, it is a system that can learn from ambiguous signals while moving production enforcement toward logic that is low latency, replayable, and easier to audit.
The LLM does not make the production decision in the common case, deterministic rules do. We use LLMs deliberately and narrowly, to interpret novel or ambiguous assets, and then to distill what they learn into versioned human-reviewed deterministic rules, which steadily shrinks the LLM’s role in production over time. Humans stay in the loop where it matters most. People adjudicate the reviewed reference labels, and they review and approve rule promotions that could change how protection is enforced.
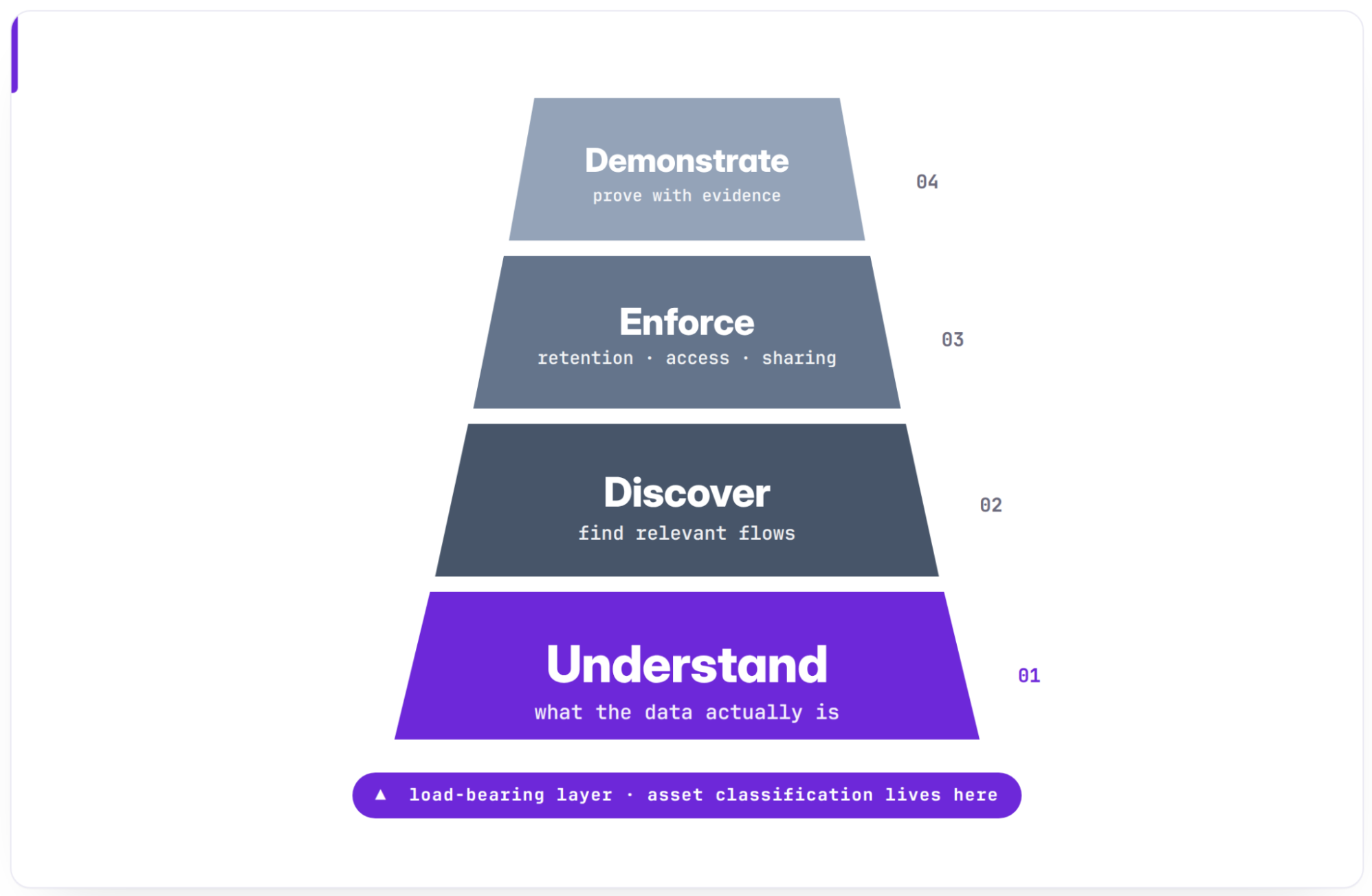
PAI addresses four operational concerns:
- Understand what data exists and how it is governed.
- Discover which data flows are relevant to a policy question.
- Enforce retention/access/purpose/sharing constraints.
- Demonstrate compliance through verifiable evidence.
Asset classification sits at the understand layer. It provides the foundation that every downstream concern depends on.
Why Asset Classification Matters
Asset classification is the foundation for many privacy controls. Before a system can enforce retention, access, allowed-purpose, downstream-sharing, or anonymization policies, it needs a reliable view of what the asset is and how it should be governed.
An asset can be more than a table or column. It can be a nested field inside a payload, a log key, an event parameter, an API field, a machine learning (ML) feature, an embedding, or a derived dataset produced by an intermediate pipeline. That breadth matters because AI-native systems often transform data across many representations. A single source signal can move through pipelines, become a feature, appear in a model-training workflow, or be joined with other derived signals. Classification has to follow the meaning of the data, not just its shape.
There are four recurring challenges:
First, noisy and weak signals: Dozens of context fields are fetched per asset, which forces the model to rediscover what matters each time. High token usage dilutes attention, and decision boundaries get buried in irrelevant or misleading fields. A field called age in a caching pipeline is a concrete example: Without code resolution and lineage analysis, a classifier will trigger false restrictions on the entire pipeline.
Second, the relevant context is distributed. Code, lineage, ownership, semantic annotations, documentation, and usage patterns often live in different systems. A good classifier needs to assemble that context before making a decision.
Third, requirements evolve. Product teams move quickly, and policy interpretation can change as new product capabilities appear. A static rule set or periodic manual review process can leave gaps between reviews.
Fourth, classification is only useful if it feeds enforcement. A false positive can trigger unnecessary restrictions downstream. A false negative can leave a protection gap. The classifier sits near the front of the enforcement pipeline, so its error profile affects every system that depends on it.
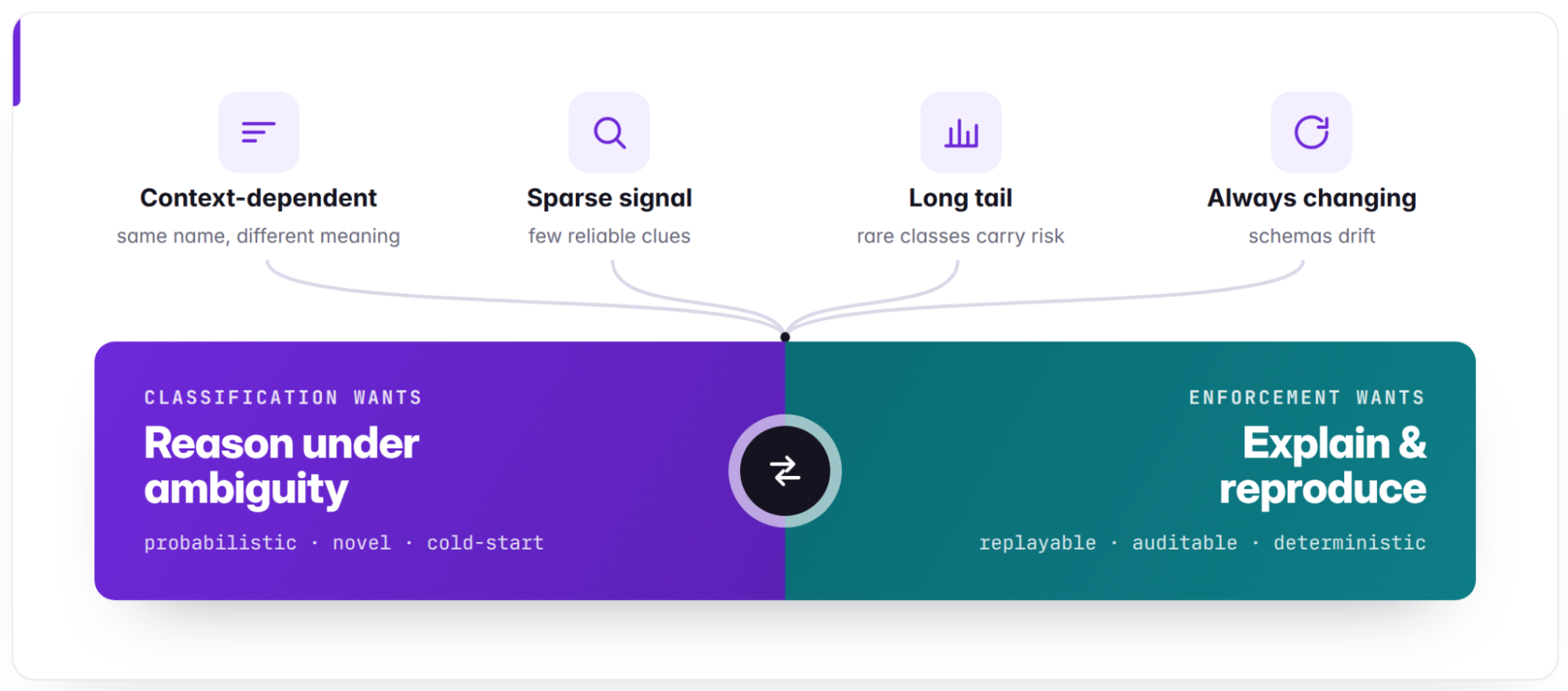
This creates the central tension: Classification needs to reason under ambiguity, but enforcement needs decisions that can be explained and reproduced later.
The Pattern
Our approach is built around three principles that emerged from building and operating the system:
First, context beats prompts. Most classification failures were not caused by weak instructions; they were caused by weak or missing evidence. Hours of prompt optimization produced marginal improvement when the model was reasoning over raw, noisy fields. Structuring context into evidence briefs, with supporting signals, contradicting signals, provenance, and masked circular fields, produced much larger accuracy improvements. The practical lesson is simple: Focus on what goes into the model before optimizing how you ask.
Second, decouple evaluation from optimization. LLM outputs are useful recommendations, but they cannot become their own ground truth. The evaluation loop needs to stay independent from the classifier: different models, different prompt strategies, frozen reference sets, human-reviewed labels, and regression gates. If evaluation and optimization share the same loop, the system can end up measuring drift instead of progress.
Third, distill stable behavior into deterministic rules. LLMs are useful for ambiguity, cold start, and new patterns. They are not the right default enforcement mechanism at scale. When the system finds stable, validated patterns, those patterns should become versioned, auditable rules that run without the LLM. Over time, the classifier should progressively shrink its own LLM surface area, leaving model inference for novel or ambiguous assets while routine enforcement becomes deterministic, low-latency, and replayable.
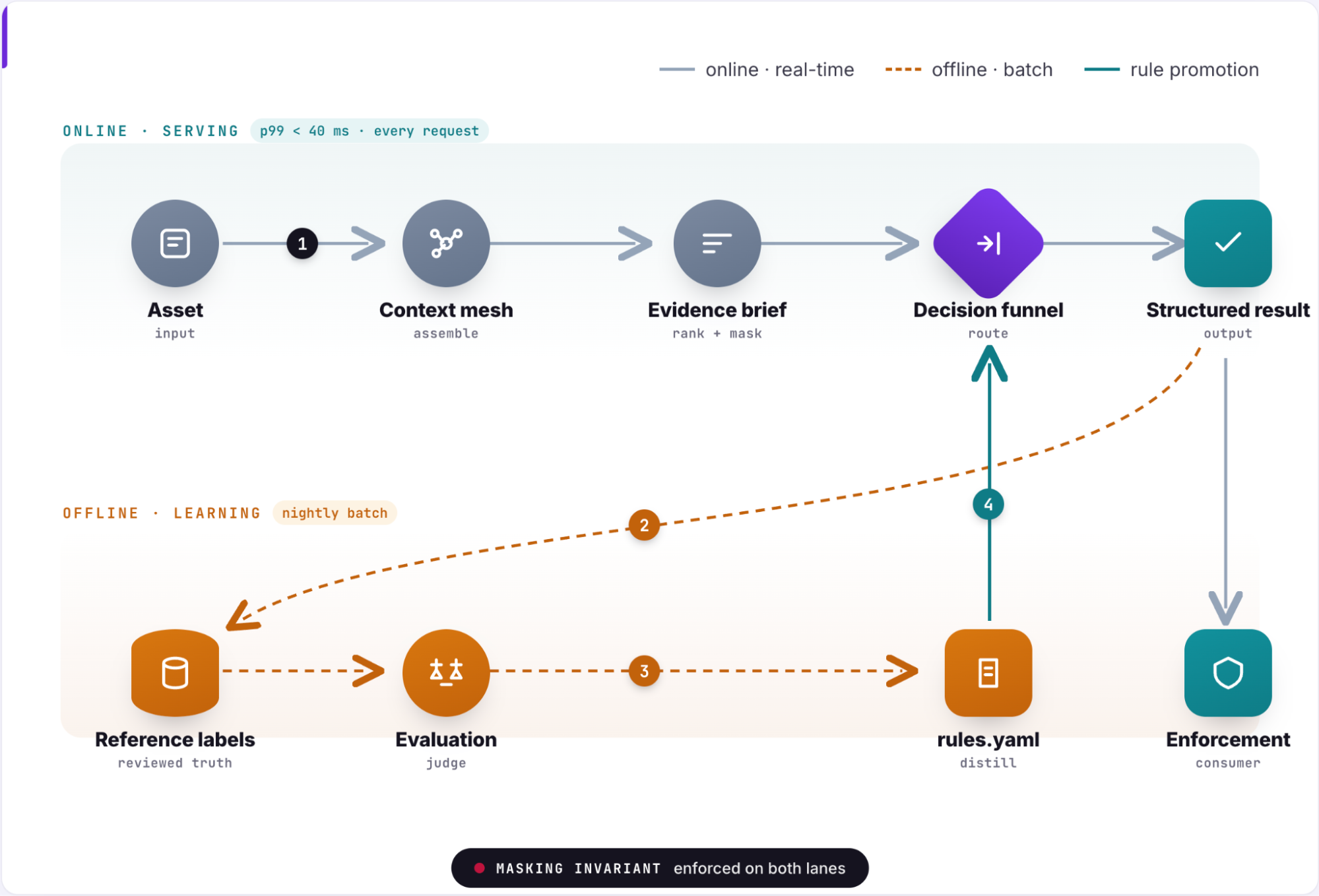
These principles translate into a concrete operating pattern: Define a stable classification contract, build a context mesh, route decisions through a deterministic-first funnel, and keep the learning loop safe with independent evaluation and reviewed labels.
To execute on this pattern, we break the work down into seven practical stages. These stages transform the high-level architecture into a concrete, repeatable process.
The rest of this post walks through those pieces using asset classification as the case study.
1.) Start With the Contract
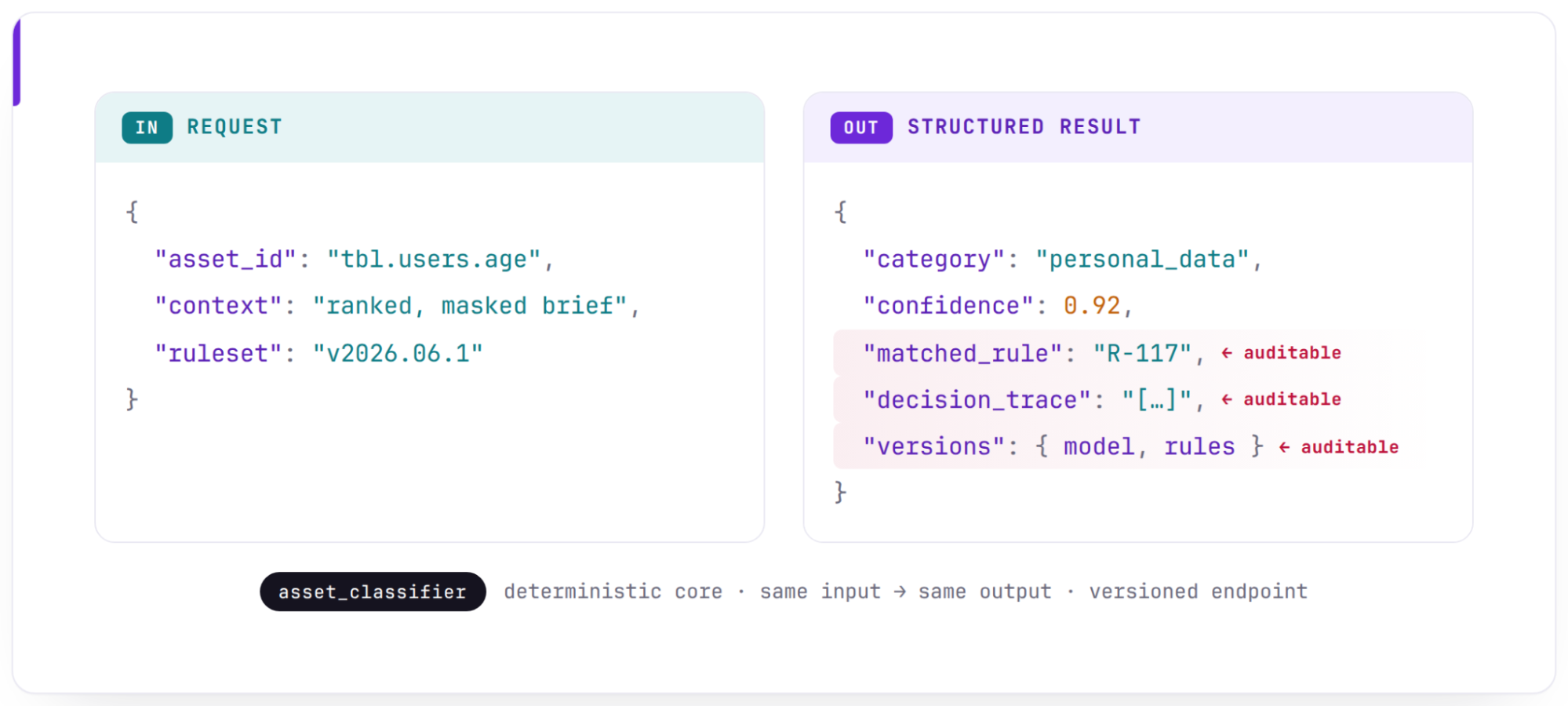
A classifier should behave like a platform service. That means its contract should be small, explicit, and stable. For each asset, the classifier receives an identifier and a bundle of context. It returns a structured result with:
- A category from the classifier’s taxonomy.
- A confidence score – a raw model self-assessment whose calibration we evaluate against reviewed labels (see below).
- A decision trace showing which evidence influenced the result.
- The rule that matched, if the decision came from deterministic logic.
- Version information for the context, rules, and prompt used to make the decision.
The taxonomy is domain-specific. One classifier might distinguish user data from operational data. Another might classify whether an asset is eligible for a particular AI-training use case. We avoid forcing every classifier into one universal taxonomy. Instead, each classifier owns one scoped question, and downstream systems compose the answers when they need multiple facets.
That scoping is important. A narrow classifier is easier to evaluate, easier to debug, and easier to govern. It also makes the decision trace more meaningful because the classifier is explaining one decision, not trying to solve every policy question at once.
2.) Build Context Before Prompting
Most classification failures are not prompt failures. They are context failures. If the only signal is a field name, the model has to guess. If the system can also provide code references, lineage, ownership, semantic annotations, and nearby usage, the model can reason from better evidence.
In practice, the context mesh may include:
- Source-code resolution, including where a field is defined or used.
- Ownership and organizational metadata.
- Semantic annotations, such as data type or origin.
- Lineage signals that show where data came from and where it flows.
- ML heuristic outputs from scanners or embedding-based classifiers.
- Code search results that show references, logging declarations, or call sites.
The point is not to pass everything to the LLM. More context is not automatically better. Some fields are redundant. Some are noisy. Some can create circular reasoning if they already encode the label we are trying to predict.
So the system creates an evidence brief – a compact summary of the strongest supporting signals, contradicting signals, and provenance chains. Instead of asking the model to sift through raw context, we ask it to reason over the evidence that is most relevant to the classification decision.
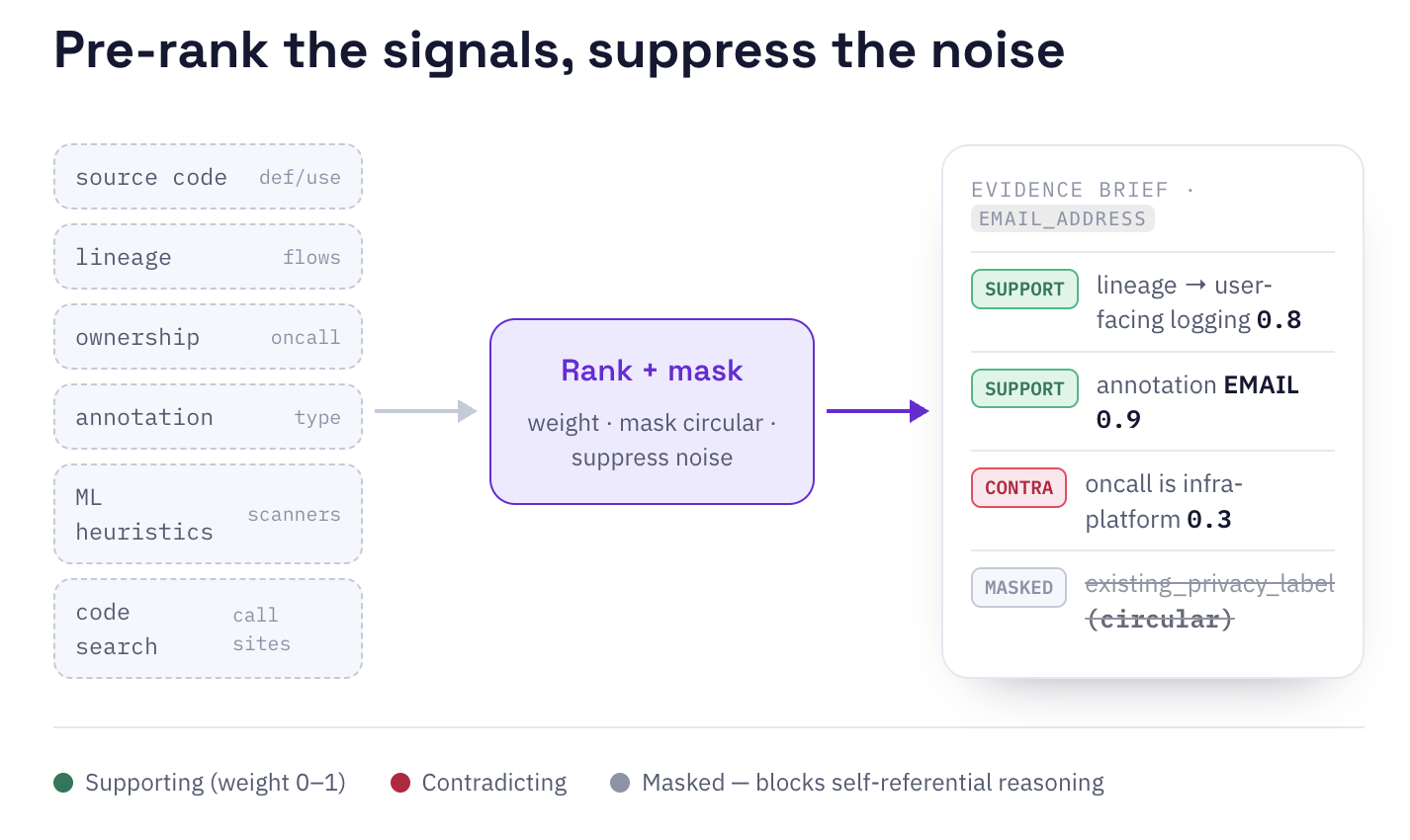
Without this structuring, the model receives dozens of raw fields per asset and must rediscover what matters leading to high token consumption, diluted attention, and decision boundaries buried in noise. The evidence brief solves this by pre-ranking signals. For a field like user_payload.email_address, an evidence brief might say:
- Supporting signal: Lineage connects the asset to a user-facing logging pipeline (weight 0.8).
- Supporting signal: Semantic annotation indicates EMAIL-like data (weight 0.9).
- Contradicting signal: Ownership metadata points to an infrastructure team, not a user-facing product (weight 0.3).
- Suppressed signal: An existing privacy label was removed to avoid circular reasoning.
That last point matters. A model should not be allowed to “discover” the correct answer by reading a field that already contains the answer. Masking is not just prompt hygiene, it is a system invariant. Fields masked from the LLM are also blocked from learned rule distillation so the model cannot smuggle the answer into a rule by way of a circular field. Deterministic rules that use high-risk fields require explicit review.
Over time, the system can also learn which context fields are useful. Fields that consistently improve classification can be prioritized. Fields that are unstable, redundant, or harmful can be suppressed. This turns signal quality from a matter of intuition into something measurable.
3.) Use a Decision Funnel
Once the context is assembled, the classifier routes the asset through a decision funnel.
The first path is deterministic. If a known, versioned rule matches the asset, the classifier can return a decision quickly and with a clear explanation. Deterministic rules work well for stable patterns – a well-understood namespace, a semantic annotation with high precision, or a combination of signals that has been validated over time.
The second path is LLM-based. If the asset is novel, ambiguous, or outside current rule coverage, the classifier asks the model to reason over the evidence brief. The model returns a candidate label, confidence indicators, a decision path, and cited evidence.
In our production deployment, Figure 7 shows how cheap deterministic rules resolve the large majority of traffic, roughly 85%, in single-digit milliseconds. The LLM is reserved as a fallback for the roughly 15% that is novel or ambiguous. That path is slower — on the order of seconds — and roughly 400 times the compute cost, so it is budgeted separately. Both paths emit the identical result schema. The masking invariant is enforced on each.
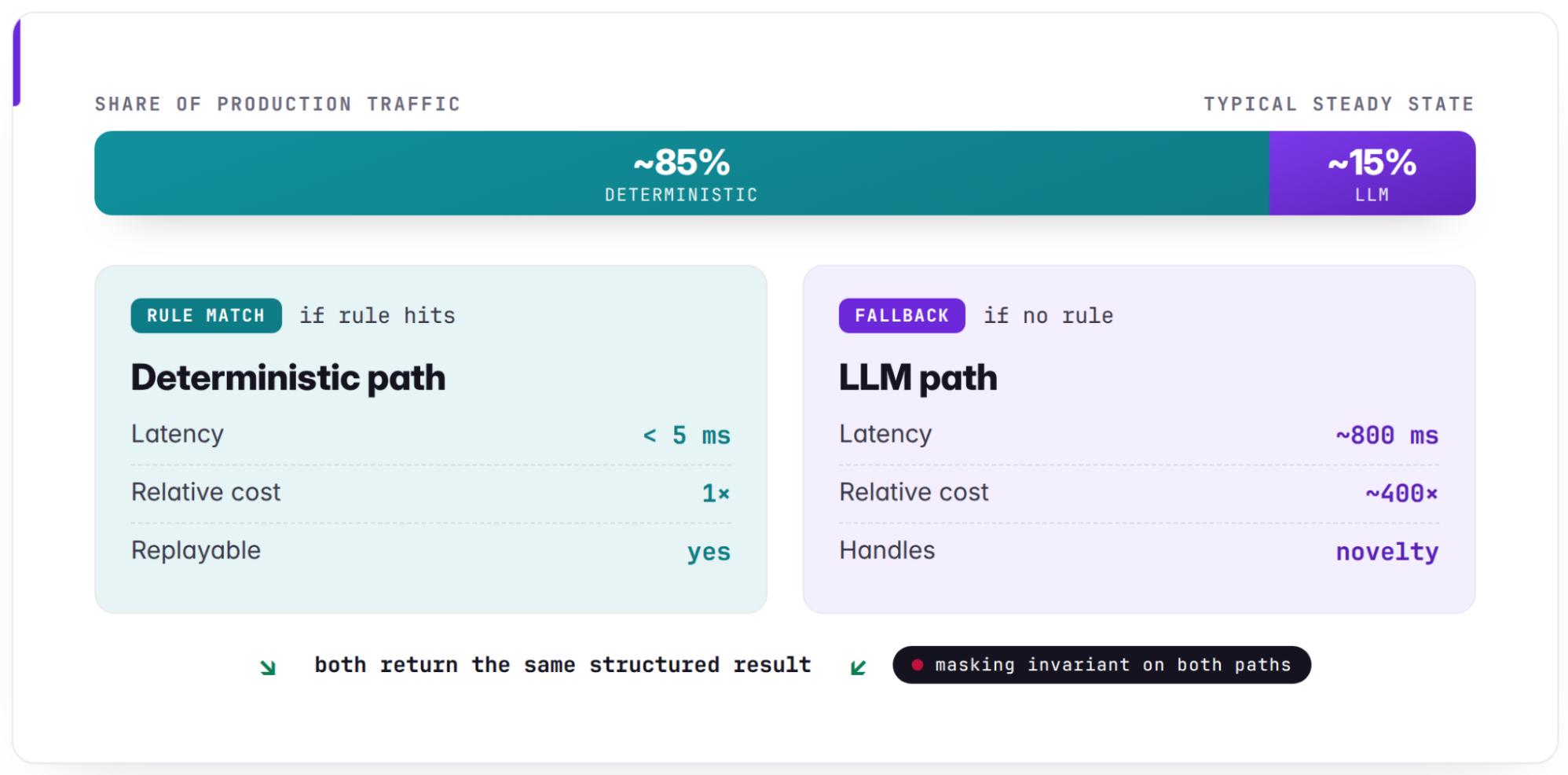
That confidence deserves a careful read. The raw score is a model self-assessment, a number the model produces from its own judgment, not an inherent probability of being correct. So we evaluate its calibration against reviewed labels. Raw scores are compared to the correctness rate actually observed on the human-reviewed reference set, which tells us how well a given score tracks a real probability of being right. Confidence-based routing in the funnel, for example, accept automatically versus route to human review, should use calibrated scores where that calibrated path is enabled, rather than the raw number
Both paths emit the same result format. Downstream enforcement systems do not need to know whether a decision came from a rule or from model-based reasoning. They receive a category, confidence, trace, and versioned decision metadata.
This split is what makes the pattern practical. LLMs are useful for ambiguity and cold start. Rules are better for routine enforcement. The more stable behavior we can distill into rules, the less often the serving path needs model inference.
Rule coverage becomes an important operational metric. If coverage rises while quality holds steady, the classifier is moving toward a healthier steady state: fewer routine calls to the model, lower resource use, lower latency, and decisions that are easier to replay.
A critical system invariant: Fields masked from the LLM are also blocked from learned rule distillation, so a masked signal cannot re-enter the decision through an automatically distilled rule. In one production deployment, a subtle bug in how masked context was handled during rule evaluation caused rules to silently fall through to LLM fallback, so rule coverage appeared to plateau even as the rule set grew. Fixing that handling immediately increased rule coverage and cut LLM inference calls significantly.
The lesson: Masking is not a prompt-engineering concern, it is a system invariant. And deterministic rules that rely on high-risk fields require explicit review rather than inheriting masking implicitly.
4.) Solve Cold Start Deliberately
On day zero, a classifier has a hard problem: There may be millions of assets and very few reviewed labels. Random sampling is not enough. The categories that matter most for privacy can be rare, and rare categories are easy to miss if you wait for examples to appear naturally.
Instead, we seed the process with policy-guided examples:
- Rare sensitive categories.
- Borderline cases where policy interpretation is difficult.
- Negative examples that look sensitive but are not.
- Assets where context signals disagree.
The goal is not to eliminate human review. It is to focus human attention on the cases where judgment matters most.
5.) Keep the Learning Loop Safe
Once the classifier is live, it needs to improve without grading its own homework.
We separate two loops:
The reference loop produces reviewed labels. These labels are append-only, versioned, and tracked with provenance. If a label changes, the history is preserved rather than overwritten. Model-generated labels are useful recommendations, but they do not become reference labels automatically. Humans adjudicate uncertain or high-risk cases, and those adjudicated labels become the reference set for evaluation.
The optimization loop improves prompts, routing, context usage, and candidate rules. It can evolve quickly, but it is evaluated against the reviewed reference set, not against labels produced by the same model it is trying to optimize. This distinction matters: A classifier that trains or validates itself on its own predictions can appear to improve while drifting away from the policy intent.
For quality control, we use a multi-panel judge – three independent LLM evaluations, each with a different prompt strategy. One classifies directly from evidence. One critiques the reasoning first, then classifies. One focuses exclusively on metadata signals, such as on-call, lineage, and semantic annotations, while ignoring names and descriptions. All three share a single judge model, a larger reasoning model deliberately different from the classifier model.
The three judges share one scaffold and differ only in how they are asked to reason. The skeleton below is illustrative, not the literal production prompts, but it shows the structure. Each judge receives the same masked evidence brief, the masking invariant still holds, and each returns a structured verdict.
# Shared scaffold (all three judges)
INPUT = masked_evidence_brief # pre-existing privacy label removed; masking invariant holds
OUTPUT = {label, rationale, confidence}
JUDGE_MODEL = larger reasoning model, deliberately != classifier model
# V1 - direct-from-evidence
verdict_1 = judge(brief, instruction="Classify the asset directly from the evidence.")
# V2 - critique-then-classify
verdict_2 = judge(brief, instruction="First critique the supporting and contradicting signals, then classify.")
# V3 - metadata-only
verdict_3 = judge(brief, instruction="Use ONLY metadata signals (on-call, lineage, semantic annotations). Ignore names and descriptions.")
# Aggregate
final_label = majority_vote(verdict_1, verdict_2, verdict_3)
Agreement = cohens_kappa(verdict_1, verdict_2, verdict_3) # inter-rater reliability
Results aggregate by majority vote. We track panel agreement across the three judge framings as a stability signal, while Cohen’s kappa (κ) compares the judge consensus against the reference labels (or against the classifier output), providing a statistical signal about classification reliability. These kappa scores drive structured loop decisions: Continue when the system is healthy, WidenAudit when label noise is suspected, FreezeAndAudit when quality declines for two or more iterations, and DataProblem when labels or taxonomy appear fundamentally broken and the system should halt and escalate. This prevents the iteration loop from shipping regressions to production.
For imbalanced taxonomies, we use metrics that expose rare-class failures. Accuracy alone can be misleading: A classifier that labels everything as non-sensitive may look accurate if sensitive assets are rare. Matthews correlation coefficient, macro F1, per-class recall, balanced accuracy, and calibration checks give a more complete picture.
We also look for fragile decisions. One useful test is counterfactual masking: Remove one context field at a time and classify again. If the decision flips when a single weak signal disappears, the asset is flagged for review. The original prediction may still be correct, but the reasoning may be too brittle for confident automation.
When quality drops, the system should slow down or stop. That can mean widening the audit sample, freezing optimization, or escalating a taxonomy or labeling problem for human review. A learning system needs brakes, not just accelerators.
6.) Distill Stable Behavior Into Rules
Even a strong LLM classifier should not be the default enforcement path forever. This distillation (not autonomous decision-making) is where we concentrate the model’s value. Any rule that could change how sensitive data is protected is reviewed and approved by a person before it goes live.
As the system collects reviewed labels and decision traces, it can identify patterns that are stable enough to encode as deterministic rules. A rule might capture a high-precision semantic annotation, a reliable ownership and lineage combination, or a repeated pattern across a class of assets.
Candidate rules go through validation before they affect serving decisions. A typical flow looks like this:
- Propose a rule from stable context and label patterns.
- Test it against a held-out reviewed set.
- Run it in shadow mode on production-like traffic without changing serving behavior.
- Promote it only if quality, coverage, and regression checks clear the required gates.
- Retire or revise it if the pattern becomes stale or quality degrades.
Distillation operates in stages of increasing complexity:
Stage 1: Field-based rules. Extract single-field patterns (exact match, keyword, numeric range, value-set membership, namespace patterns), with a minimum support of two assets and minimum purity of 80%.These are candidate-mining thresholds for surfacing rules to evaluate, not promotion thresholds. Every candidate from any stage still has to clear holdout validation, a higher dev-precision bar, shadow mode, and human review where protection could change before it can serve.
Stage 2: Composite rules. For uncovered categories, search for conjunctions (e.g., “on-call contains X AND semantic type is ACCOUNT_ID”) under stricter gates — 95% purity, 10 examples minimum, and a stability check on 50% subsamples.
Stage 3 (optional): LLM-assisted rule generation. The model proposes custom conditions combining lineage depth with ownership patterns that manual heuristics miss, gated by rollout controls and default-off. Each candidate rule then proceeds through: holdout validation → blacklist if failed (bounded-TTL) → shadow mode (log, don’t apply) → promote to rules.yaml only if quality gates clear. Promoted rules shrink the LLM surface area.
The important principle is that deterministic rules should not quietly reduce protection. Rule promotion needs safeguards that are designed to catch regressions, especially for sensitive classes.
Validated rules are exported to Python, SQL, JSON, or Hack for deployment in production systems with zero LLM dependency. We manage these rollouts using compare-and-swap (CAS) semantics: We write immutable rule and prompt versions, then activate them via a lease-guarded compare-and-swap on the published pointer (atomic within our single-writer model). This ensures the production path remains a deterministic engine, while the LLM is reserved solely for novel assets that lack rule coverage.
This is what makes the hybrid approach sustainable. LLMs help the system learn. Deterministic rules help the system enforce.
7.) Automate the Right Things
Automation is necessary, but the boundary matters.
We automate context acquisition, evidence brief generation, candidate classification, evaluation runs, failure analysis, and candidate rule proposal. These are high-volume tasks where automation can reduce manual toil and make the process more consistent.
We keep human review in the places where judgment matters – ambiguous policy interpretation, reviewed reference labels, high-risk disagreements, and promotion decisions that could materially affect protection. This is a routing policy, not a prompt.
A decision is escalated for human review when any of the following hold:
- Low calibrated confidence. The calibrated confidence falls below the auto-accept threshold, so the decision is not safe to ship automatically.
- Judge-panel disagreement. The three independent judges produce no clear majority, or inter-rater agreement (Cohen’s kappa) is low, a signal that the case is genuinely ambiguous.
- High-cost rare class. The candidate is a rare sensitive category where a false negative is expensive, so the asymmetric error cost warrants a human check even at moderate confidence.
- Fragile reasoning. Counterfactual masking flips the label when a single weak signal is removed.The prediction may still be right, but the reasoning is too brittle for confident automation.
- Protection-reducing rule promotion. A candidate rule would change enforcement for a sensitive class in a way that could reduce protection. Deterministic rules should not quietly weaken it.
- Controller escalation. The tuning controller enters Pausing or Diagnosing, indicating a quality concern or a fundamental labeling or taxonomy problem that a human must resolve.
That balance is deliberate. Privacy-aware infrastructure should not hide uncertainty. If the model, judge, or evaluation loop disagrees, the system should surface that disagreement as a useful signal. Sometimes the right answer is not a better prompt. Sometimes the right answer is clearer policy guidance, better labels, or a narrower taxonomy.
The best automation in this space does not replace people. It concentrates human attention on the hardest cases, records the reasoning, and turns stable learning into repeatable enforcement over time.
What We Learned

Context Quality Beats Prompt Quality
When classification stalls, it is tempting to keep tuning the prompt. In our experience, better context often matters more. Code resolution, lineage, ownership, and semantic annotations can change the decision space in a way prompt edits cannot.
The practical lesson is simple: Before asking whether the model needs a better instruction, ask whether it has the evidence a human reviewer would need. We saw this with a field named age in a caching pipeline. It was a cache TTL, not a person’s age, and prompt-only changes did not fix it reliably, adding code resolution and lineage did. Once the model could see that the field resolved to a TTL, the false positive went away.
Determinism Means Replayability
The goal is not to make an LLM produce the same text every time. The goal is to reproduce a decision later using the same versioned inputs, context, and logic.
That is why versioning matters. A useful decision trace should tell us what evidence was used, which rule or prompt version was active, and how the decision can be replayed during debugging, incident review, or audit support. In one review, we replayed a single past classification from its stored decision trace and the pinned context, rule, and prompt versions, and reconstructed exactly why the asset received the label it did, without rerunning the LLM.
Accuracy Alone Is Not Enough
For imbalanced taxonomies, accuracy can hide the failures that matter most. If a sensitive category is rare, a classifier can look good while missing too many examples of that category.
Balanced metrics, per-class recall, calibration checks, and review of false negatives are all part of the quality picture. No single metric carries the whole story. We saw a classifier that labeled almost everything non-sensitive show a high overall accuracy while its per-class recall on a rare sensitive category stayed low. Matthews correlation coefficient and macro F1 surfaced the gap that accuracy hid, and the misses became the cases we routed back for review.
Keep Recommendation Separate From Truth
Model-generated labels are useful, but they should not automatically become reference labels. The reference set needs reviewed provenance, and holdout evaluation should not be contaminated by the same model outputs being evaluated.
This separation adds friction by design. It is the friction that prevents a self-reinforcing loop from looking better while becoming less grounded. We saw the pattern directly. An optimization run scored against the same model’s earlier labels appeared to improve, but when we re-evaluated it against the frozen human-reviewed reference set, the apparent gains turned out to drift away from policy intent.
Coverage Is Not Correctness
Higher automation coverage is only useful if quality holds. A classifier can auto-resolve more assets while becoming less reliable on the cases that matter.
That is why coverage should be tracked alongside recall, precision, regression checks, and robustness tests. The goal is not to classify more assets automatically at any cost. It is to automate the cases that are stable enough to automate. In one case, promoting a broad rule lifted automation coverage but dropped shadow-mode per-class recall on a sensitive class. Because we track coverage alongside recall, we caught the regression and narrowed the rule before it reached serving.
Distillation Is the Production Model
LLMs are useful for ambiguity, cold start, and new patterns. Deterministic logic is better for the routine path where decisions need to be fast, explainable, and reproducible.
The sustainable model is a funnel: Let LLMs help discover and reason, then distill stable patterns into versioned rules that enforcement systems can run efficiently.
Self-Regulation Is Architectural, Not Operational
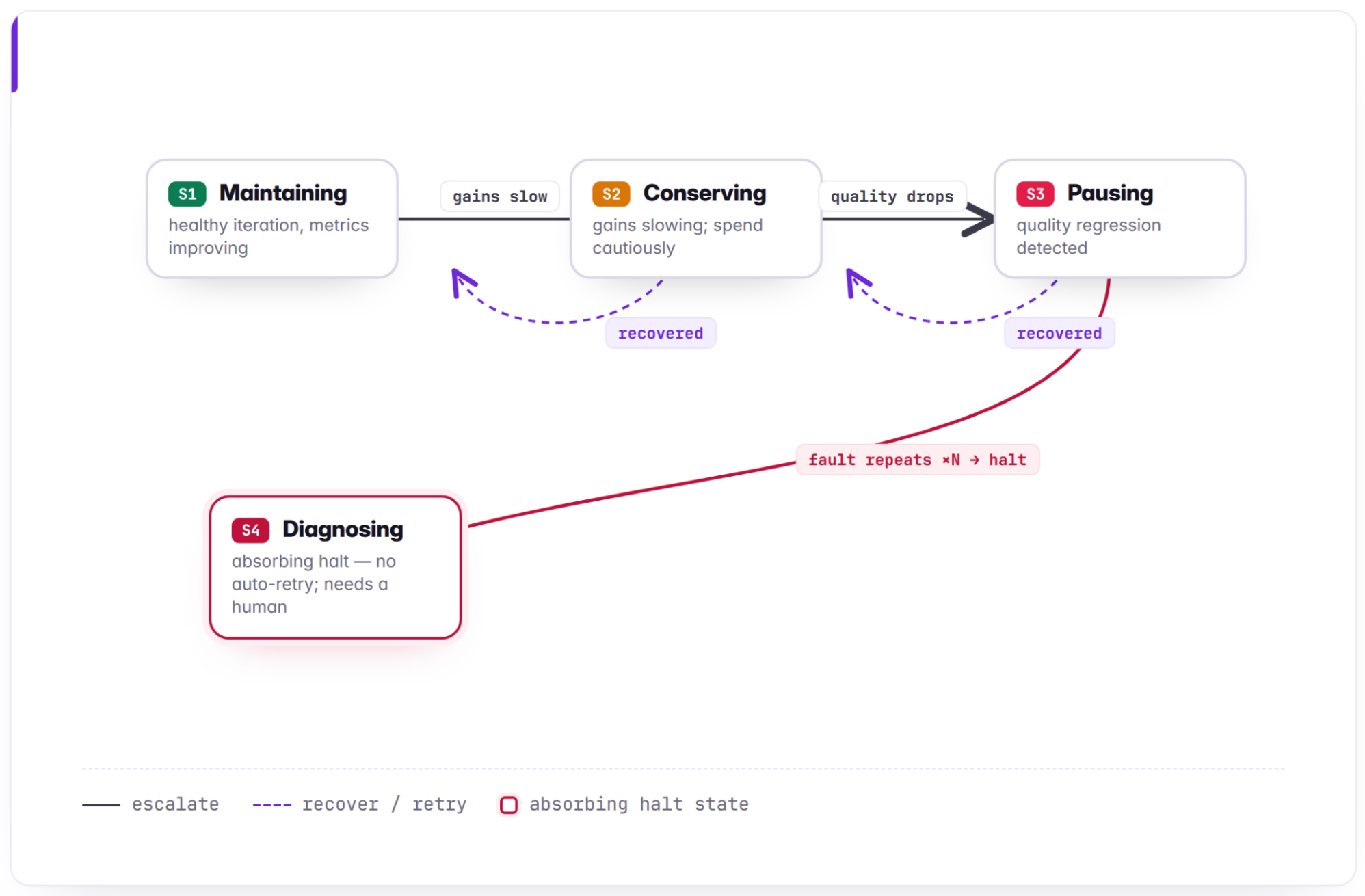
A learning system that does not know when to stop is a potential liability. We built a tuning controller that transitions through regimes:
- Observing (gathering signal).
- Maintaining (healthy iteration).
- Conserving (gains slowing).
- Pausing (quality concerns).
- Diagnosing (halt for fundamental issues).
In practice, the oscillation detector identifies stalled optimization, classifiers cycling between two candidate prompts without improving, and terminates them early, saving thousands of wasted classification calls per stalled run. This self-regulation was designed into the architecture from the start; retrofitting it would have been significantly harder.
Upcoming Directions
Three directions follow from this work:
- Migrate legacy classifiers to this system, replacing ad-hoc heuristics with the full context-mesh + distillation pipeline.
- Expand to other PAI workflows: The same pattern (context → LLM reasoning → distillation → deterministic enforcement) applies to lineage validation, purpose-boundary checking, and retention policy assignment.
- Apply beyond privacy: Early experiments suggest these techniques generalize to agent observability and oversight, where the same tension exists between probabilistic reasoning and auditable enforcement.
AI-Native Products Raise the Bar for PAI
AI-native products raise the bar for privacy-aware infrastructure. They create new data modalities, faster iteration cycles, and more ambiguous signals. At the same time, privacy enforcement still needs decisions that are consistent, explainable, and reproducible.
Asset classification shows how to bridge that gap. Start with a clear contract. Build rich context. Use LLMs for novelty and ambiguity. Keep reviewed labels separate from model recommendations. Evaluate with metrics that expose rare-class failures. Distill stable behavior into deterministic, versioned rules.
That pattern lets the system learn from ambiguity without making ambiguity the foundation of enforcement.
The pattern also generalizes beyond our own use. A separate enforcement team compared this pattern against three alternatives head-to-head and chose it for their classification layer, independently of our work. In their evaluation, deterministic-first classification with LLM fallback produced more consistent, debuggable, and auditable decisions than end-to-end LLM approaches. Two teams independently arriving at the same trade-off (reasoning with LLMs, enforcing with rules) suggests a robust pattern.
The broader lesson is that privacy-aware infrastructure is not a tax on engineering. It is a driving force for better architecture: clearer contracts, richer context, stronger evaluation, safer publication, and systems that know when to ask for human judgment.
Acknowledgements
The authors would like to acknowledge the contributions of many members of the Privacy-Aware Infrastructure team who have played a crucial role in the work described here. In particular, we extend special thanks to Alex Basiuk, Dionisios Sotirios Krongos, Fanghao Song, Kartikey Sachdeva, and Loka Potnuru for their foundational contributions to classifier analysis, runtime feature migration, scanner hardening, false-positive reduction, and age-flow precision improvements — as well as the broader PAI team for context enrichment and evaluation.
We are also grateful to Dave Kurtzberg, Inchara Shivalingaiah, Juemin Wei, Nithya Arumugam, Zhe Wang, and team for independently validating the classification pattern within their autonomous remediation pipeline, to Jonathan Bergeron for sponsorship and support throughout, and to Deborah Davis for editorial guidance throughout.








