
- We’re introducing SilverTorch, a reimagining of recommendation systems that unifies all retrieval components for user generated content under a unified architecture.
- SilverTorch shows up to 23.7x higher throughput compared to the state-of-the-art approaches. It’s also showing 20.9x more compute cost efficiency compared to a CPU-based solution while also improving accuracy.
- Our research paper, “SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs,” accepted to the full paper track at SIGIR 2026, contains full technical details.
The retrieval system within industry recommendation systems have consisted of microservices stitched together, with neural networks inconsistently integrated. Our recommendation can scale to serve people across multiple platforms. Retrieval is responsible for narrowing from millions of pieces of content (e.g., reels and photos) down to thousands before passing them to ranking systems, all in less than 100 milliseconds.
However, the microservice based design had hard constraints on model complexity and the number of candidates evaluated, ultimately creating a ceiling on the quality of recommendations that people on our platforms see.
To break through this ceiling, we’ve fully reimagined our retrieval ecosystem into a unified model-based system – SilverTorch.
SilverTorch operates under a new paradigm we call Index as Model. We’ve built our retrieval system as a single neural network and now express different microservices as model modules within this integrated neural network. Under Index as Model previous microservice-based item indices used for retrieval become a tensor inside the model. As a user opens up their app, one request flows through a SilverTorch model, completes all critical retrieval functions (searching for items similar to the user’s interests, filtering for eligibility, reranking and scoring engagement likelihood against multiple user engagement actions), and returns a list of high-quality content candidates to ranking. This new design effectively allows us to increase modeling complexity and the number of candidates evaluated without breaking the sub-100 milliseconds bar.
SilverTorch makes retrieval significantly more efficient, runs at scale, and enables better recommendations.
- Higher throughput, lower total cost of ownership (TCO). In an 80M-item end-to-end evaluation, SilverTorch served 23.7× more requests per second than a strong traditional multi-service baseline built on the same model architecture, while improving estimated TCO efficiency by 20.9×.
- Proven at scale. Results show SilverTorch can scale across a family of apps as the major retrieval system behind the feed and video content people see.
- Better recommendations. By making neural reranking and multi-task scoring practical within tight latency budgets, SilverTorch has consistently enabled retrieval quality improvements that would have been impractical under a microservices architecture.
Moving From Microservice Mesh to One Integrated Neural Network
The Microservice Paradigm We Replaced
Traditional recommendation retrieval is built as a mesh of microservices. When a user opens a social media platform, the request hits an orchestrator, which fans out to a user-tower model service (which computes a vector representation of the user’s interests, called a “user embedding”), a combined retrieval service (which finds and filters candidate items based on similarity to the user vector and eligibility rules like language and geography), and a scoring service (which ranks the survivors). The orchestrator merges results and hands them downstream. Each service has its own codebase, often in a different programming language, with its own deployment lifecycle.
This worked well in the CPU era. But as retrieval systems grew in scale and sophistication, three problems compounded into structural limits that no component-level optimization can fix:
- Latency lost to data movement. Every hop between services costs network round-trip time and serialization overhead, eating into our sub-100-millisecond retrieval budget that should fund actual computation. And because filtering, search, and scoring are designed independently, they cannot be jointly optimized.
- Version inconsistency. The user-tower model, the item index, and the filtering rules each update on their own cadence. When the user model ships v2 but the item index is still on v1, the system queries v1 embeddings with v2 user representations — creating quality gaps no downstream ranking can recover.
- Siloed development environments. Machine learning (ML) engineers write PyTorch. Infrastructure engineers write C++. Different release cycles, different testing setups, different mental models. Every retrieval improvement requires translating an idea between two environments — weeks or months per cycle.
Component-level optimizations like Faiss-GPU help by making the specific microservice faster, but they don’t resolve the underlying structural limits. The architecture is still a system of services with artifacts handed between them.
The Shift: All Components Are Model Modules
SilverTorch rethinks the paradigm from the ground up. Instead of designing a microservices system and inserting neural networks into it, we start with the neural network and design outward. We call this Index as Model: Every retrieval component — the item index, eligibility filter, scoring layer and user tower — becomes a tensor or operator inside a single PyTorch model. That means one artifact to deploy, one forward pass to run and one source of truth for what’s in the system.
Inside the Model
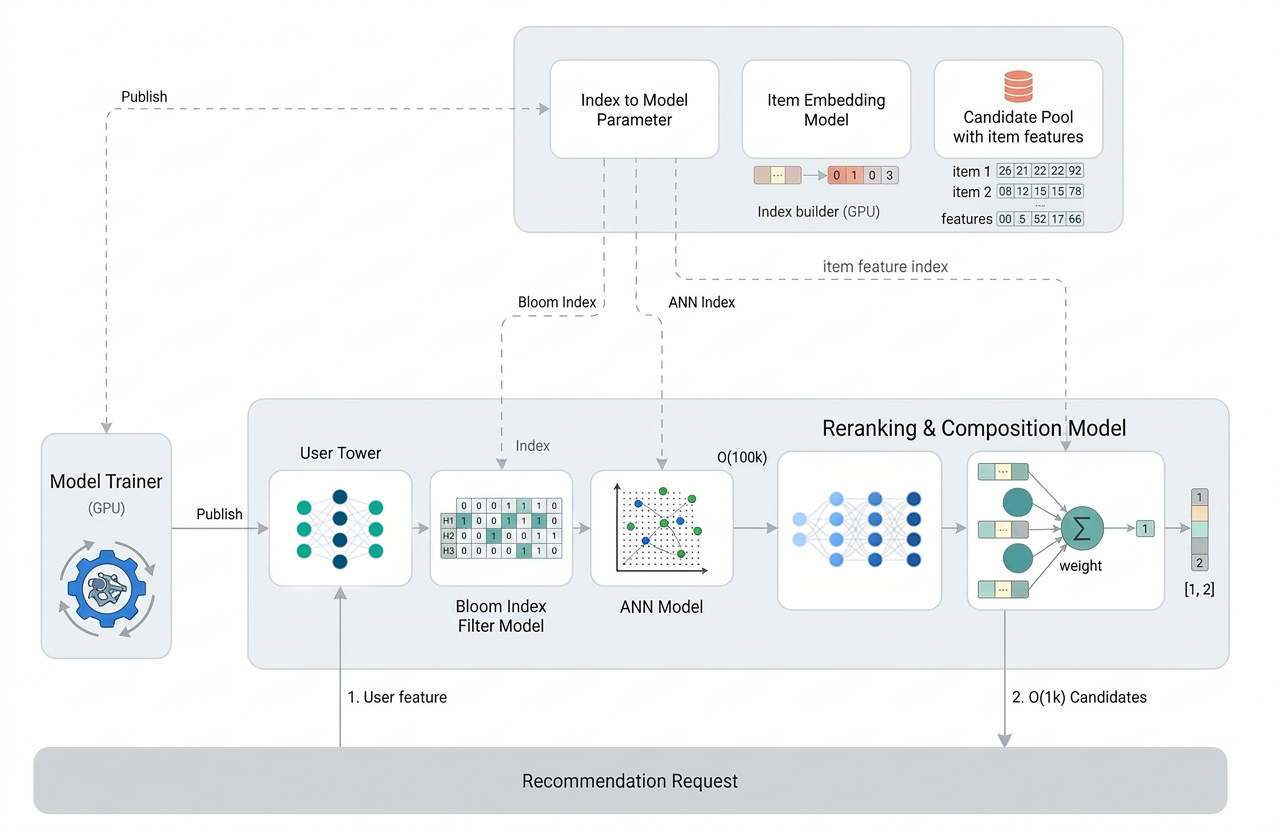
Inside this single neural network, different regions of the network handle different jobs. Approximate nearest neighbor (ANN) search regions find items most similar to the user’s interests without checking every item in the catalog (a librarian who has organized the books well doesn’t walk every shelf). Eligibility filtering regions check that each candidate is allowed to be shown: right language, right country, right content policy. Multi-task reranking regions predict the likelihood of multiple engagement actions (like, share, comment) at once, then combine them into a composite score. Some regions are hand-written by engineers; others are trained end-to-end via backpropagation. From the runtime’s perspective, all of them are nn.Module — the standard building block of PyTorch — and indistinguishable from each other.
The Redesign: Pure PyTorch Modules for Every Stage
How Each Component Worked Before
Before SilverTorch, every module in the production retrieval pipeline — ANN search, eligibility filtering, neural reranking, composite scoring — had a well-known classic implementation, mostly built as standalone services in C++.
| Module | Classic implementation | Where it runs |
|---|---|---|
| ANN search | FAISS | CPU and GPU versions |
| Eligibility filtering | Inverted index | CPU and GPU versions |
| Neural reranking | Standalone early stage ranking service | CPU and GPU versions |
| Composite scoring | Rule-based aggregation | CPU only |
These implementations are mature and battle-tested, but each is a standalone service with its own data structures, memory, and execution model. We can chain them — run ANN, then hand its output to filtering — but we cannot easily implement cross-module optimizations like “pick the most promising clusters first, filter only inside those clusters, then score only the survivors.” This level of co-design requires modules to share memory, an execution graph, and a compilation step.
The Pure PyTorch Decision
To enable that co-design, we made a decision that every module would be reimplemented in pure PyTorch. Under this paradigm:
- All data is expressed as tensors.
- All logic is tensor-in, tensor-out.
- Every module is an nn.Module that conforms to PyTorch’s standard interface.
- At execution time, the ANN and Bloom index filter modules are indistinguishable from a trained ML reranker — both are nn.Module, both take tensors in and produce tensors out.
With every module as an nn.Module, the boundary between ML engineering and infrastructure engineering dissolves — they live on the same layer, freely composed and jointly optimized in a single PyTorch training script. And because the whole system reduces to a single PyTorch model, we get to benefit from the broader AI industry’s work on making PyTorch models faster, like PyTorch’s own torch.compile that automatically rewrites a PyTorch model into more efficient GPU kernel code. Every advance in that ecosystem improves SilverTorch’s serving performance.
The pure PyTorch decision did not mean taking CPU-era retrieval components and wrapping them in nn.Module. It forced us to rethink retrieval primitives in forms native to GPU execution and to the model graph itself. Bloom index filter and fused Int8 ANN search are two examples. In both cases, the gain comes not from porting an old service into PyTorch, but from redesigning the underlying algorithm around GPU memory behavior, tensor layout, and execution inside the same forward pass. That is the fundamental playbook of SilverTorch: once retrieval components live inside one PyTorch model, co-design becomes possible, and that co-design is what unlocks the gains.
Bloom index filter is one example of how SilverTorch redesigns retrieval for GPUs. In traditional systems, filtering is usually handled by an inverted index, which is efficient on CPUs but harder to run well on GPUs. The problem is that recommendation filtering often has to check many item attributes at once, such as language, location, or eligibility rules, and posting lists can also vary dramatically in length across attributes and queries, creating intra-warp load imbalance and warp divergence on GPUs. Threads assigned short lists become inactive early, while the warp remains occupied until the lanes processing the longest lists complete.
SilverTorch replaces that with a Bloom index stored directly inside the model. Each item gets a compact signature when it is published, and at serving time the model can quickly check whether an item matches the request using simple bit operations. This turns filtering into the kind of dense, parallel work GPUs are good at, and because the filter result is already inside the model, it can flow directly into ANN search without a separate service call.
Fused Int8 ANN search follows the same idea. General-purpose ANN libraries are built to find nearby items, but recommendation systems need more than a small nearest-neighbor lookup. They often need to pull back a much larger pool of candidates so later stages can make better relevance decisions.
SilverTorch reimplements ANN search as part of the model itself. It stores item embeddings in a compact Int8 format, which cuts memory use roughly in half compared to typical 16 bits, and runs search with a fused GPU kernel. That reduces data movement and makes the retrieval stage cheap enough to return many more candidates, giving downstream models more room to find the best recommendations. Our Int8 quantized ANN search shows limited quality loss compared to brute force while significantly improving serving performance. It frees headroom for ranking more items with more sophisticated layers and improves the end-to-end retrieval accuracy, and the algorithm supports large top-k and probe counts; in practice, we observe no retrieval recall loss with 64 probes and top-2048.
Benefits — What Shows Up Outside the System
SilverTorch delivers concrete impact along three dimensions: compute cost efficiency, recommendation quality, and engineering velocity.
Compute Cost Efficiency
By moving ANN search, eligibility filtering, and composite scoring onto the GPU and combining them through SilverTorch’s co-design, we serve far more requests per second on the same machine. More requests per second means fewer machines needed for the same workload, and fewer machines means lower compute cost per request.
Below is a comparison on a production retrieval workload of 80 million items, with real production traffic replayed against each system under the same latency budget:
| Metric | FAISS-CPU | FAISS-GPU | SilverTorch |
|---|---|---|---|
| Compute cost efficiency vs. CPU baseline | baseline | 5.9× | 20.9× (13.35× with reranking) |
| Maximum top-k | unlimited (slow) | 2,048 | 100s of thousands |
| Neural reranking | not supported | not supported | supported |
| Multi-task scoring | not supported | not supported | supported |
SilverTorch’s 13.35× cost-per-request advantage compounds from several sources: The fused Int8 ANN kernel is 2.2-14.7× faster than Faiss-GPU; the Bloom index is 291-523× faster than the CPU inverted index; the probe-then-filter co-design cuts filter compute by another 30×. Int8 quantization in the model graph cuts memory in half compared to full-precision baselines, leveraging the GPU’s dp4a instructions, with no measurable recall loss.
Recommendation Quality
SilverTorch improves recommendation quality by turning retrieval into a much broader and more expressive pre-ranking stage. In traditional service-based systems, retrieval is usually constrained to a relatively narrow ANN result set, scored mostly by simple embedding similarity, with richer relevance modeling deferred to late-stage ranking.
SilverTorch unlocked headroom. By keeping ANN search, filtering, and scoring inside one model, it can widen the funnel substantially. Instead of handing only a small set of candidates downstream, it can bring one to two orders of magnitude more candidates through additional learned relevance layers before final ranking. That makes retrieval contribute meaningfully to recommendation quality, not just a fast pruning step.
Neural reranking. SilverTorch introduces a neural network based reranking layer that goes beyond dot-product similarity and applies richer user-item interaction modeling to a much larger candidate set. These layers can take the form of multi-layer perceptrons, stacked self-attention, or more structured interaction models such as mixture of logits. Because the item representations and cross-features remain in GPU memory and are executed within the same model, SilverTorch can afford to apply these more sophisticated ranking layers earlier in the pipeline, over far more candidates than conventional retrieval systems typically can.
Multi-task scoring. SilverTorch also makes retrieval natively multi-objective. A scoring layer combines predictions for different user actions into a single composite score, so retrieval is no longer optimizing around one coarse similarity signal. Instead, it can evaluate a broad candidate pool against a richer notion of user engagement before late-stage ranking begins. The result is a wider funnel with more intelligence inside it – more candidates survive early retrieval, and they are screened by more sophisticated, multi-objective scoring before being passed to the final ranking.
Engineering Velocity
Lastly, SilverTorch accelerates how quickly the team can build and ship retrieval improvements. Because the entire pipeline lives in one PyTorch codebase, an engineer working on a new retrieval idea writes PyTorch and only PyTorch. There is no longer a need to translate an algorithm from a research notebook into a C++ service, coordinate with a separate infrastructure team, and run a multi-week integration cycle. The time required to build and publish a new innovation dropped from weeks to days.
Engineering for Scale and Freshness
SilverTorch is designed with scalability and index freshness in mind to ensure that it can support a massive scale recommendation system and distribute newly created content in near real time.
Scale Up and Scale Out
Our strategy is to scale up first. We make the most of the single high-performance GPU by carefully orchestrating its memory hierarchy (on-chip SRAM, GPU-resident HBM, host DRAM, remote DRAM) so data lives close to where it’s computed. Once we’ve maximized a single GPU, we scale out within a host, taking advantage of high-bandwidth interconnects between GPU cards on the same machine.
When the neural network exceeds a single host’s capacity, we use document sharding: split the item inventory (videos, posts, photos) across hosts, like splitting a large library’s catalog across branches.
For the very large sparse networks inside the model — embedding tables that map every item and every user feature to a learned vector — we use TorchRec, PyTorch’s library for sparse-table sharding. TorchRec spreads these tables across HBM, GPU host DRAM, and even remote CPU-host DRAM, decoupling sparse data movement from computation.
Index Freshness
With index as a model module, maintaining index freshness equates to updating the model weights of a neural network in production, at scale, without taking the model offline.
SilverTorch decouples freshness from the full model publish cycle through streaming updates. As model parameters get updated based on the latest training, we periodically publish the full model as a complete snapshot. Between publishes, a continuous streaming service reads real-time signals — new items, updated engagement features, changed eligibility — and applies targeted updates in-place to the specific tensors in the in-memory model. Updates land without interrupting serving and without redeploying the model.
The result shows up in the recency of recommended content. Same-day posts now represent a significant portion of recommendations on social media platforms compared to previous systems.
The Evolution of SilverTorch and What’s Next
SilverTorch is a journey from a system of microservices with neural networks bolted in to a full model-based recommendation retrieval. Two things stand out in retrospect: Full model-based retrieval is viable and efficient at production scale — the architecture breaks down the wall between infrastructure and modeling, and they become one unified practice. It also unlocks better user experience — capabilities like multi-task scoring and neural reranking that prior systems couldn’t run inside the latency budget.
The technical work went through three stages: We first reproduced every baseline retrieval module — ANN, filtering, scoring — in PyTorch. This step alone yielded benefits from high-speed GPU memory and reducing data movements. We then rethought each module in a PyTorch-native, GPU-native way. This is where SilverTorch’s fused Int8 ANN and Bloom index filter came from, designed to compose rather than to stand alone. Finally, we enabled backward propagation for select hand-written modules so they can be trained jointly with the rest of the model.
Looking Ahead
Index-as-Model is the right paradigm for the next generation of recommendation systems, and it’s widely adopted within Meta across different apps. As recommendation systems increasingly incorporate large language models (LLMs) for understanding user intent and content semantics, SilverTorch’s architecture provides a natural integration point:
- An LLM can be plugged into SilverTorch as just another module — the system treats it identically to any other component.
- LLM-based item generation and SilverTorch’s filtering use the same GPU-parallel patterns.
- Item knowledge can be updated in real time through the same streaming infrastructure.
- The LLM and traditional scoring share the same GPU memory — no data movement between services.
In short, SilverTorch lets us integrate LLM capabilities directly inside the retrieval model, rather than orchestrating them as a separate service that sits alongside it. That tighter coupling is what raises the system ceiling for what LLM-powered recommendation can do at production scale.
Read the Paper
For more technical details, see our paper accepted as a full research paper at SIGIR 2026: “SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs.”
Acknowledgments
We would like to thank the following individuals and our partner teams across Meta for their collaboration in bringing this system to life.
Ryan Chang, Yijie Deng, Fei Ding, Eric Dong, Fan Duo, Zheng Fang, Pawel Garbacki, Hui Geng, Kevin Greer, Max Gu, Ke Huang, Chirag Jain, Anna Jung, Eric Kim, Da Kuang, Xialu Li, Sam Lin, Ziqi Liu, Yiming Ma, Lei Mao, Xiaoheng Mao, Peter Park, Lanbo She, Fangcheng Sun, Jin Sun, Shuo Tang, Harry Tran, Alex Wang, Byron Wang, Jiazhou Wang, Liang Wang, Wenting Wang, Zhen Wang, Zheng Wei, Hong Wu, Peng Xia, Judy Xiang, Bi Xue, Lan Xue, Chao Yang, Shuguang Ye, Hongzhang Yin, Min Yu, Keke Zhai, Qianqian Zhang, Rui Zhang, and Yingjiao Zhao.
Rui Li, Qifan Wang, Shengzhi Wang, Yubo Wang, Yueming Wang, Jiaqi Zhai, Erheng Zhong, and the RecSys Modeling team.
Xinyao Hu, Yanzun Huang, Rui Jian, Min Ni, Qunshu Zhang, Yuting Zhang, Yanli Zhao, and the RecSys Foundation team.
Bruce Deng, Congle Zhang, Luyi Guo, Min Li, Yang Liu, Kai Ren, Guoqiang Jerry Chen, Yimin Tan, Honghao Wei, Li Yu, Lu Zheng, and the Facebook team.
Lihan Bin, Xianjie Chen, Mingze Gao, Abhishek Kumar, Zhengyu Su, Haotian Wu, and the Instagram team
Shujian Bu, Chenglin Lu, Rui Wang, and the Threads team.
Shiyan Deng, Lu Fang, Hongyi Jia, Xudong Ma, Lujia Zhang, and the AI Infrastructure team
Rongrong Hu, Shuyi Zheng, and the Meta AI team.








