
- We’ve fundamentally transformed Facebook Groups Search to help people more reliably discover, sort through, and validate community content that’s most relevant to them.
- We’ve adopted a new hybrid retrieval architecture and implemented automated model-based evaluation to address the major friction points people experience when searching community content.
- Under this new framework, we’ve made tangible improvements in search engagement and relevance, with no increase in error rates.
People around the world rely on Facebook Groups every day to discover valuable information. The user journey is not always easy due to the amount of information available. As we help connect people across shared interests, it’s also important to engineer a path through the vast array of conversations to surface as precisely as possible the content a person is looking for. We published a paper that discusses how we address this by re-architecting Facebook Group Scoped Search. By moving beyond traditional keyword matching to a hybrid retrieval architecture and implementing automated model-based evaluation, we are fundamentally innovating how people discover, consume, and validate community content.
Addressing the Friction Points in Community Knowledge
People struggle with three friction points when searching for answers in community content – discovery, consumption, and validation.
Discovery: Lost in Translation
Historically, discovery has relied on keyword-based (lexical) systems. These systems look for exact words, creating a gap between a person’s natural language intent and the available content. For example, consider a person searching for “small individual cakes with frosting.” A traditional keyword system might return zero results if the community uses the word “cupcakes” instead. As the specific phrasing doesn’t match, that person misses out on highly relevant advice.
We needed a system where searching for an “Italian coffee drink” effectively matches a post about “cappuccino,” even if the word “coffee” is never explicitly stated.
Consumption: The Effort Tax
Even when people find the right content, they face an “effort tax.” They often have to scroll and sort through many comments before finding consensus. Imagine someone searching for “tips for taking care of snake plants.” To get a clear answer, they have to read dozens of comments to piece together a watering schedule.
Validation: Decision Making with Community Knowledge
People often need to verify a decision or validate a potential purchase using trusted community expertise. For instance, consider a shopper on Facebook Marketplace viewing a listing for a high-value item, such as a vintage Corvette. They want authentic opinions and advice about the product before purchasing, but that wisdom is typically trapped in scattered group discussions. The person needs to unlock the collective wisdom of specialized groups to evaluate the product effectively, but digging for these validation signals manually is not easy.
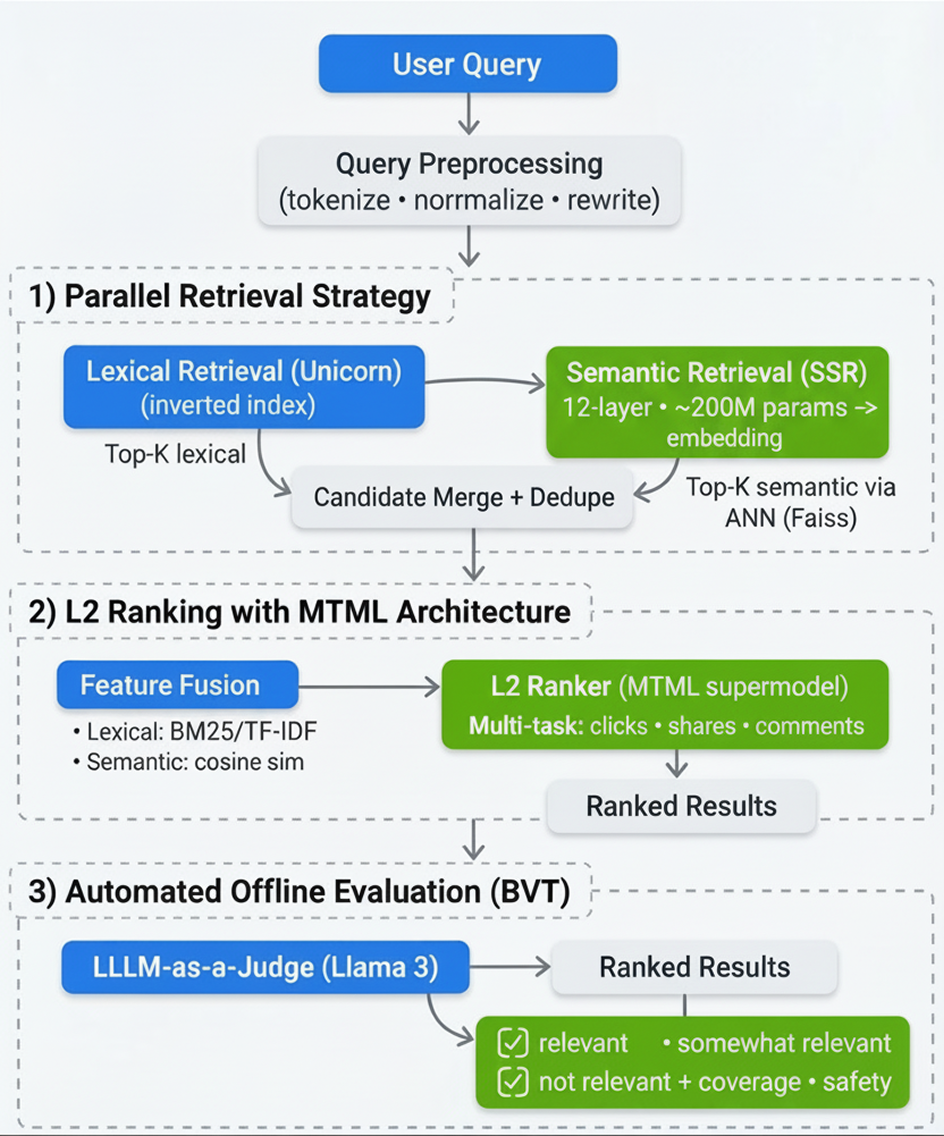
The Solution: A Modernized Hybrid Retrieval Architecture
We engineered a hybrid retrieval architecture that powers a discussions module on Facebook Search. This system runs parallel pipelines to blend the precision of inverted indices with the conceptual understanding of dense vector representations. We addressed the limitations of legacy search by restructuring three important components of our infrastructure.
The following workflow illustrates how we modernize the stack to process natural language intent:
Parallel Retrieval Strategy
We modernized the retrieval stage by decoupling the query processing into two parallel pathways, ensuring we capture both exact terms and broad concepts:
Query Preprocessing: Before retrieval, user queries undergo tokenization, normalization, and rewriting. This is important for ensuring clean inputs for both the inverted index and the embedding model.
The Lexical Path (Unicorn): We utilize Facebook’s Unicorn inverted index to fetch posts containing exact or closely matched terms. This ensures high precision for queries involving proper nouns or specific quotes.
Simultaneously, the query is passed to our search semantic retriever (SSR). This is a 12-layer, 200-million-parameter model that encodes the user’s natural language input into a dense vector representation. We then perform an approximate nearest neighbor (ANN) search over a precomputed Faiss vector index of group posts. This enables the retrieval of content based on high-dimensional conceptual similarity, regardless of keyword overlap.
L2 Ranking With Multi-Task Multi-Label (MTML) Architecture
Merging results from two fundamentally different paradigms — sparse lexical features and dense semantic features — required a sophisticated ranking strategy. The candidates retrieved from both the keyword and embedding systems are merged in the ranking stage. Here, the model ingests lexical features (like TF-IDF and BM25 scores) alongside semantic features (cosine similarity scores).
Next, we moved away from single-objective models to a MTML supermodel architecture. This allows the system to jointly optimize for multiple engagement objectives — specifically clicks, shares, and comments — while maintaining plug-and-play modularity. By weighting these signals, the model ensures that the results we surface are not just theoretically relevant, but also likely to generate meaningful community interaction.
Automated Offline Evaluation
Deploying semantic search introduces a validation challenge: Similarity scores are not always intuitive in high-dimensional vector space. To validate quality at scale without the bottleneck of human labeling, we integrated an automated evaluation framework into our build verification test (BVT) process.
We utilize Llama 3 with multimodal capabilities as an automated judge to grade search results against queries. Unlike binary “good/bad” labels, our evaluation prompts are designed to detect nuance. We explicitly programmed the system to recognize a “somewhat relevant” category, defined as cases where the query and result share a common domain or theme (e.g., different sports are still relevant in a general sports context). This allows us to measure improvements in result diversity and conceptual matching.
Impact and Future Work
The deployment of this hybrid architecture has yielded measurable improvements in our quality metrics, validating that blending lexical precision with neural understanding is superior to keyword-only methods. According to our offline evaluation results, the new L2 Model + EBR (Hybrid) system outperformed the baseline across search engagement with the daily number of users performing search on Facebook compared to baseline.
These numbers confirm that by integrating semantic retrieval, we are successfully surfacing more relevant content without sacrificing the precision users expect. While modernizing the retrieval stack is a major milestone, it is only the beginning of unlocking community knowledge. Our roadmap focuses on deepening the integration of advanced models into the search experience:
- LLMs in Ranking: We plan to apply LLMs directly within the ranking stage. By processing the content of posts during ranking, we aim to further refine relevance scoring beyond vector similarity.
- Adaptive Retrieval: We are exploring LLM-driven adaptive retrieval strategies that can dynamically adjust retrieval parameters based on the complexity of the user’s query.
Read the Paper
Modernizing Facebook Scoped Search: Keyword and Embedding Hybrid Retrieval with LLM Evaluation








