
React makes it simple to build functional, component-based user interfaces on web and mobile; at Facebook, we have more than 30,000 React components in our main web repo alone. React’s simplicity and functionality has led to its adoption by hundreds of thousands of developers outside Facebook. With today’s release of React 16, we’ve completely rewritten the internals of React while keeping the public API essentially unchanged. From an engineering standpoint, it’s a bit like swapping out the engine of a running car: since hundreds of other companies (including Facebook) use React in production every day, we wanted to do the swap without forcing people to rewrite their components built in React.
The new implementation is designed from the ground up to support asynchronous rendering, which allows processing large component trees without blocking the main execution thread. We also took the opportunity to build frequently-requested features that were previously difficult to add, like catching exceptions using error boundaries and returning multiple components from render. We’ve already spoken during the React Conf keynote in more detail about the motivation behind this rewrite, but we also wanted to bring developers behind the scenes to see how we actually built and tested this new implementation in the context of a large production app.
Developing the rewrite
For most feature development at Facebook, we don’t use long-running branches in our repositories because we’ve found it’s a lot of work to deal with merge conflicts when the branches inevitably get merged together. Instead, we use an approach based on feature flags where code is committed to the same repository but the feature can be enabled or disabled based on a runtime check. Once the code is ready, rolling out the feature simply consists of changing those boolean values.
For the rewrite, which we called React Fiber during development, we took the same approach: we wrote all of the new code alongside the old code in our GitHub repo and switched between the two with a boolean “useFiber” feature flag. This process allowed us to start building out the new implementation without affecting any of our existing users and while continuing to make bug fixes to our old codebase when necessary. We made a single entry point that checked the feature flag and imported the old or new renderer files, as appropriate.
We wanted to rebuild React with complete feature parity, so our first long-term goal was to make our existing Jest test suite pass when run against the new code. The new renderer started as a skeleton implementation that only supported a very limited subset of React’s APIs, and we added features to make more tests pass over time, as a form of test-driven development. Most of our tests already used React’s public APIs so it was easy to run them against the new implementation as it was developed. We also found some tests that relied on implementation details of the old codebase and rewrote those tests as part of this project.
A typical day working on the new implementation started with turning on the feature flag and running the React unit tests. We’d pick a test that was failing and change the renderer code to make it pass. In many cases, multiple tests would be failing due to the same issue, so a fix for one test would often fix others too.
Tracking progress
As we worked toward feature parity, we wanted to track our progress towards making all of our unit tests pass. We changed our build system to log the number of passing tests with each commit, and we built a new website, isfiberreadyyet.com, which displayed that info to help us check our progress.
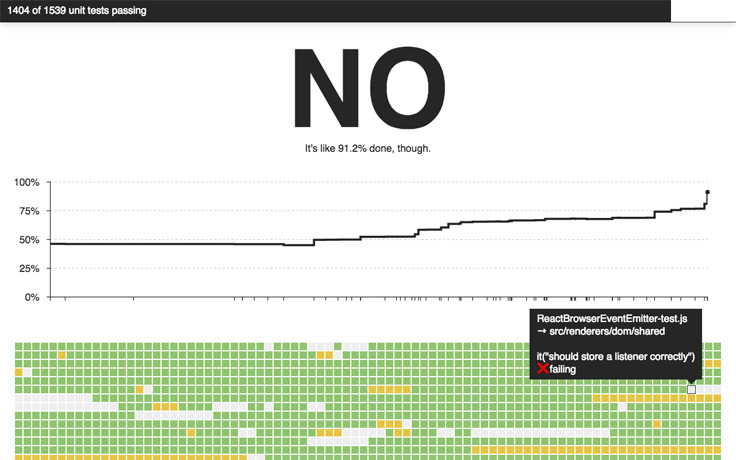
We also wanted to ensure that we would never accidentally break a test that was already passing while trying to fix a different test. We achieved this functionality by checking in a text file containing the list of tests that our rewrite was currently passing. Each pull request fixing a test would include a change that added the name of the fixed test to the list.
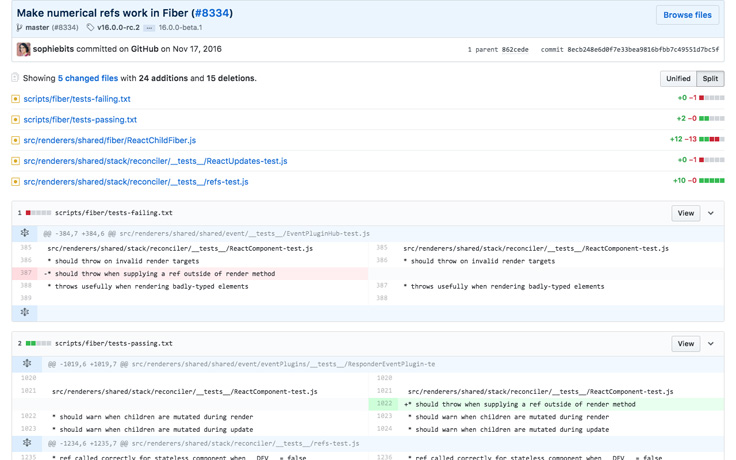
Keeping that list in our git repository ensured that any changes to it would be reviewed just like every code change; in particular, the list helped us avoid accidentally breaking tests that were previously passing. On our continuous integration servers, we verified that the list of passing tests was always kept up-to-date. It also allowed us to quickly check isfiberreadyyet.com to see which tests were still failing. On the first day it was running, three engineers on our team noticed the new system caught accidental regressions they had introduced.
When we first introduced this test-tracking system, we had about 700 out of 1500 unit tests passing. While working on the rewrite, we also continued to add to our test suite whenever we found areas that weren’t covered. By the time we reached 100 percent passing, we had added another 500 tests, for a total of about 2000 tests. Seeing the chart tick upwards as we made progress was exciting for everyone on the team, and it let us share with other people who were interested in our progress or wanted to help fix a test.
Dogfooding
One of the most reliable ways to check whether a piece of code truly works is to run it in production, so, as we do with many projects, we tested the new version of React in our web codebase at Facebook as soon as we could.
Rather than waiting for 100 percent parity in unit tests, when about half the tests were passing we tried enabling Fiber on facebook.com for a few people on our team. Even though many of our unit tests were already passing on the new implementation, we hadn’t seen the new code run on any production components, so the prospect of switching to the new code seemed daunting. The first version we tested didn’t even support most DOM properties, so many UIs we tested looked totally wrong. Once we added className support, however, most of our UIs looked close to correct.
Even though we still had a lot of bugs, seeing the new code running against our real apps was thrilling. We weren’t close to shipping to production, but seeing the rewrite work on our real components gave us confidence that completely swapping out our old implementation was a realistic goal.
Even though many parts weren’t fully baked, our team found it valuable to dogfood our new implementation across the entire production Facebook website as well as most of our internal tools. This approach matches a common strategy for roll-outs at Facebook: we enable new features for a small group of users initially and grow that group while developing more confidence in the stability of the code.
As we used the site, we kept a running list of product bugs that needed to be fixed. Some of these bugs were simply defects in our new implementation, which we fixed while adding more tests. However, many of the regressions we found in products were caused by small, undocumented implementation differences, like whether one sibling’s lifecycle methods are called before another’s. In some cases, we opted to make the new implementation conform to the old behavior; in others, we decided to fix up the brittle components and document the small breaking change in release notes.
Public rollout
After a few months we had ironed out many of the bugs. We began considering how to roll out Fiber to more people beyond our team. While we contemplated rolling it out across the entire site, we ultimately opted to start with a single product to reduce the possible set of bugs we’d encounter. We chose messenger.com as a testbed, which uses fewer components than our main site, reducing the surface area for possible bugs.
We saw employee testing as an effective way to ensure that our new codebase was ready for production. By enabling the new React implementation for Facebook employees first, we could use bug reports from them to detect issues before rolling out the code more broadly. We first enabled Fiber for the team building messenger.com, then rolled it out to more employees and eventually a small fraction of the public. When we roll out most significant changes, we use A/B testing tools to keep an eye on product metrics as well as performance numbers and error logs. With more than 2 billion Facebook users, even a 0.1 percent rollout can include hundreds of thousands of users. If we see that an infrastructure change designed to be unnoticeable causes a change in how people use our products, it usually indicates a bug in the new infrastructure.
Our initial rollout on messenger.com did show some small regressions, which we tracked down to some bugs in React. When we reset the experiment, we saw that the latest version of the code performed comparably to the old one, and we slowly expanded the rollout to cover all messenger.com users. In parallel, we brought Fiber to some internal websites and enabled it for most employees across all of our components. Once we developed confidence the release was stable, we rolled out the changes to all users on Facebook. After we completed the web rollout, we executed a similar incremental release across our mobile apps, which include hundreds of different screens built in React Native.
We’re excited to announce that with the release of React 16, we’re completely switching over to the new implementation of React. Even though React’s new core is designed to support asynchrony, we’re currently running React in a synchronous mode compatible with our older code. This allowed us to move to the new implementation smoothly. As with most of our releases, we’ve been testing the new code in production for months so we feel optimistic that people will be able to adopt it without running into issues.
We’re looking forward to exploring the new capabilities that React 16 starts to unlock, and we’re excited to continue pushing the boundaries of what’s possible in UI libraries and sharing it with you.








