
At Meta, Bento, our internal Jupyter notebooks platform, is a popular tool that allows our engineers to mix code, text, and multimedia in a single document. Use cases run the entire spectrum from what we call “lite” workloads that involve simple prototyping to heavier and more complex machine learning workflows. However, even though the lite workflows require limited compute, users still have to go through the same process of reserving and provisioning remote compute – a process that takes time – before the notebook is ready for any code execution.
To address this problem, we have invested in building infrastructure that allows for code execution directly in the browser, removing the need to provision remote compute for some lite workloads. This infrastructure leverages a library called Pyodide that sits on top of WebAssembly (Wasm).
Here’s how we married Bento with this in-browser, serverless code execution technology to power our notebooks platform for these lite workloads.
The motivation for supporting lite workloads
We define lite workloads as workloads that only consume data from upstream systems, do not have side effects to our underlying systems, and use up to the maximum Chrome tab memory limit. We frequently get internal feedback from the owners of these lite workloads that the time and complexity in getting started is not proportionate to what they want to use Bento for.
The requirements can be summarized as follows:
- An intuitive startup process that works right out of the box
- A startup process that is very quick and has the notebook immediately ready for execution
- A startup process that does not include the complex remote compute reservation process
- An execution environment that supports the majority of the lite workloads
How we put the pieces together
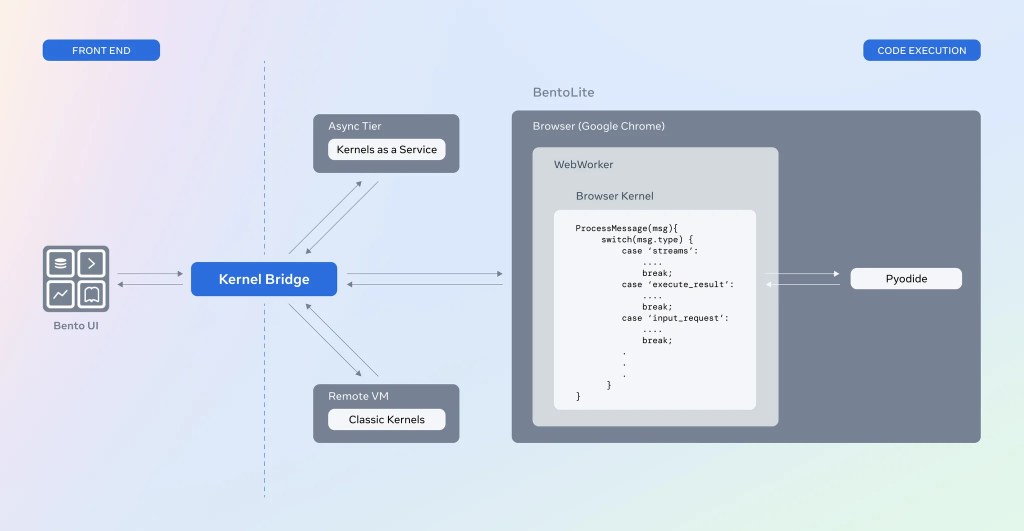
How this all works
Pyodide (a Python distribution for the browser that runs on WebAssembly) is an important ingredient for this work. We’ve built a kernel abstraction around this which, when called from Bento, will just work as any of the classic kernels we have (with some limitations) and perform message passing using the Jupyter Protocol.
Kernel bridge
This is just an abstraction that allows Bento to work with both traditional server-based kernels and this new browser-based kernel with no changes whatsoever to the rest of the system. The visible manifestation of this is just a selector in the notebook that toggles between server-based kernels and serverless.
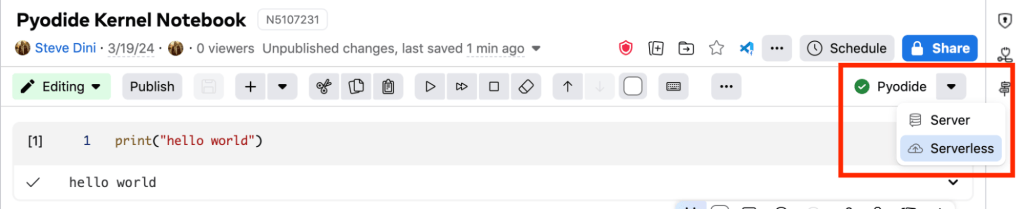
Magics
Cell magics are an important component of the Bento extension platform. In order to allow existing custom cells to work with no changes, we built middleware to capture these cell magics, process them directly in the context of javascript, and then just inject the expected results back into the Python kernel. A good example of this pattern is around %%sql, which we use to power our custom SQL cell.
We’ll showcase a few more examples in the section below on “Meta-specific” integrations.
Why we need a webworker
Since JavaScript is single-threaded, in the absence of a webworker, the entire browser would just lock up when we have “expensive” kernel operations. Having kernel operations run in a webworker with just the results being passed to the main thread helps mitigate this.
Meta-specific integrations
In order to unlock additional utility and have a coherent story around the extract, transform, and load (ETL) narrative, we built integrations with an initial set of existing extensions. These represent a relatively popular set of extensions that users leverage to perform data operations.
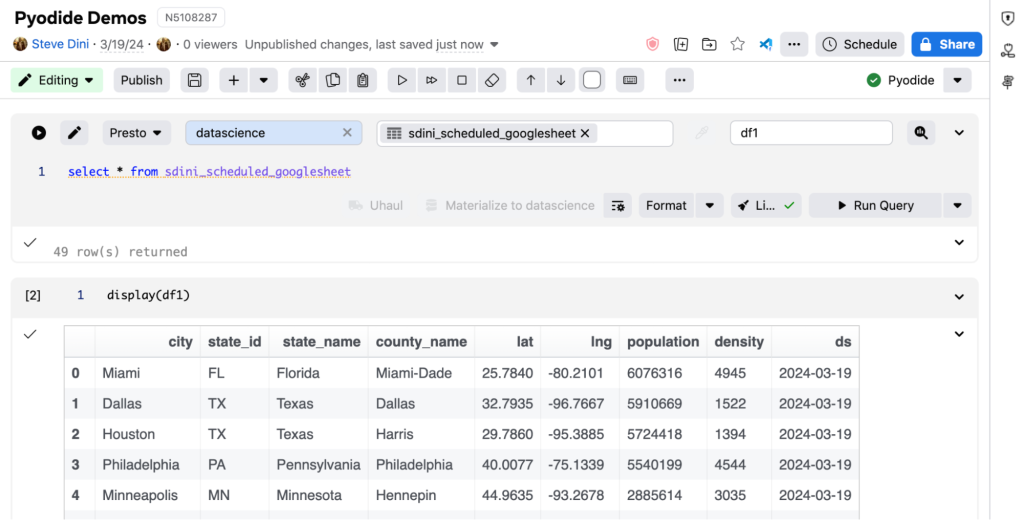
SQL Cell
This leverages the %%sql magic to fetch data from the warehouse and make it available for further processing in the Pyodide kernel.
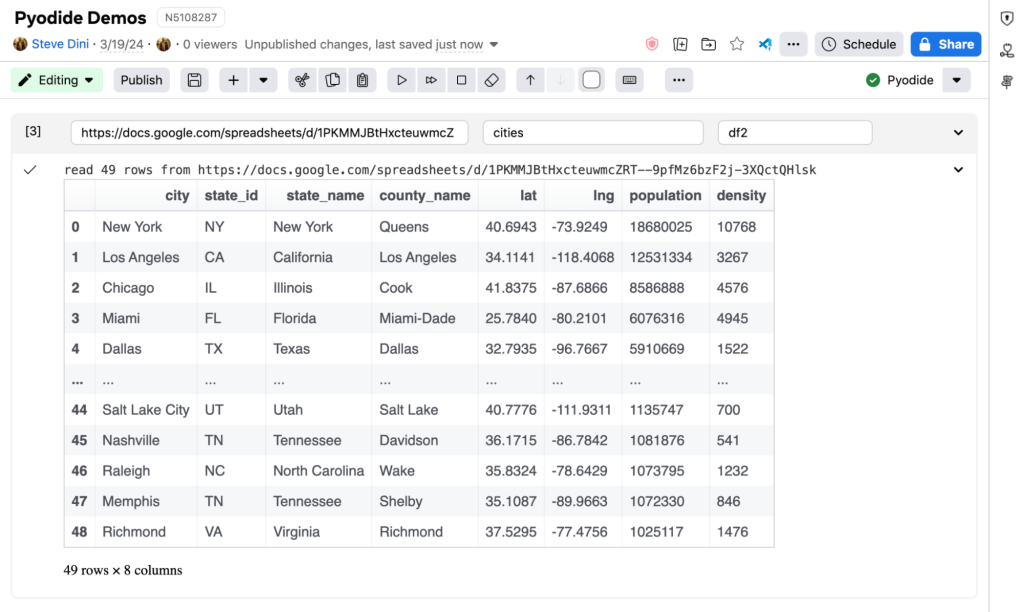
Google Sheets
Here, we leverage the %%googlesheet magic to fetch data from a Google sheet and make it available for further processing in the notebook.
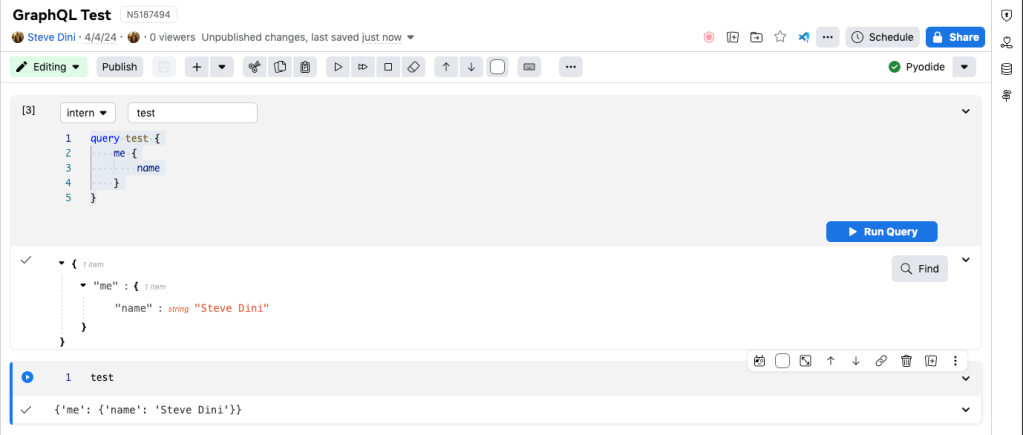
GraphQL
Here, we leverage %%graphql magic, which powers the GraphQL cell to make data fetches and then inject the result back into the kernel for further processing.
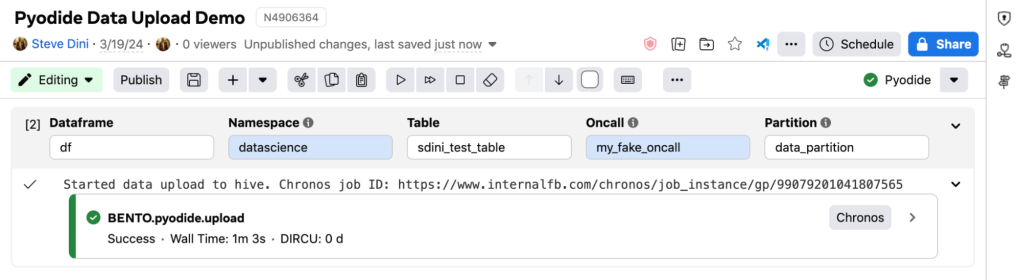
Dataframe uploads
Data uploads are a bit trickier to pull off as compared to the data reads we showcased above. We instead achieve this functionality by:
- Leveraging the %%dataframe magic that powers the upload custom cell in order to fetch the arguments in a structured way.
- We then kick off an async job using Tupperware (Meta’s async tier compute platform) and show the status of the associated tupperware job in the cell output.
What’s next for serverless notebooks
While we’ve addressed the initial set of challenges to bring this product online, there is still a lot of work to be done to improve the developer experience for users. Firstly, we’re planning on improving the lite workloads heuristic. Once we have this figured out, the next step will involve defaulting all new workloads to start as serverless. Then we can quickly autodetect (based on memory requirements, data volumes, or libraries in use) whether the workload is lite enough. If not, we can automatically switch that notebook to leverage a server-based kernel with minimal interruption to the user flow.
After this, we plan to integrate with more existing cell extensions built on top of the Bento platform and thus expand the scope of what’s possible when running “serverless.”
The biggest limitation with this approach at Meta is that homegrown libraries that have not been ported to WebAssembly will be unavailable. Given this, we’re also planning to explore whether we can farm out the execution of specific “non-lite” cells to our remote execution infrastructure while making this work seamlessly with Pyodide.
Once these have been addressed, “serverless” notebooks will become the de facto landing experience in Bento.
Acknowledgments
Some of the approaches we took were directly inspired by the work done on JupyterLite and directly leverages the Pyodide library without which this project would not have been possible. I’d also like to thank all the engineers at Meta I collaborated with to make this project a reality.








