
At Meta, Bento is our internal Jupyter notebooks platform that is leveraged by many internal users. Notebooks are also being used widely for creating reports and workflows (for example, performing data ETL) that need to be repeated at certain intervals. Users with such notebooks would have to remember to manually run their notebooks at the required cadence – a process people might forget because it does not scale with the number of notebooks used.
To address this problem, we invested in building a scheduled notebooks infrastructure that fits in seamlessly with the rest of the internal tooling available at Meta. Investing in infrastructure helps ensure that privacy is inherent in everything we build. It enables us to continue building innovative, valuable solutions in a privacy-safe way.
The ability to transparently answer questions about data flow through Meta systems for purposes of data privacy and complying with regulations differentiates our scheduled notebooks implementation from the rest of the industry.
In this post, we’ll explain how we married Bento with our batch ETL pipeline framework called Dataswarm (think Apache Airflow) in a privacy and lineage-aware manner.
The challenge around doing scheduled notebooks at Meta
At Meta, we’re committed to improving confidence in production by performing static analysis on scheduled artifacts and maintaining coherent narratives around dataflows by leveraging transparent Dataswarm Operators and data annotations. Notebooks pose a special challenge because:
- Due to dynamic code content (think table names created via f-strings, for instance), static analysis won’t work, making it harder to understand data lineage.
- Since notebooks can have any arbitrary code, their execution in production is considered “opaque” as data lineage cannot be determined, validated, or recorded.
- Scheduled notebooks are considered to be on the production side of the production-development barrier. Before anything runs in production, it needs to be reviewed, and reviewing notebook code is non-trivial.
These three considerations shaped and influenced our design decisions. In particular, we limited notebooks that can be scheduled to those primarily performing ETL and those performing data transformations and displaying visualizations. Notebooks with any other side effects are currently out of scope and are not eligible to be scheduled.
How scheduled notebooks work at Meta
There are three main components for supporting scheduled notebooks:
- The UI for setting up a schedule and creating a diff (Meta’s pull request equivalent) that needs to be reviewed before the notebook and associated dataswarm pipeline gets checked into source control.
- The debugging interface once a notebook has been scheduled.
- The integration point (a custom Operator) with Meta’s internal scheduler to actually run the notebook. We’re calling this: BentoOperator.
How BentoOperator works
In order to address the majority of the concerns highlighted above, we perform the notebook execution state in a container without access to the network. We also leverage input & output data annotations to show the flow of data.
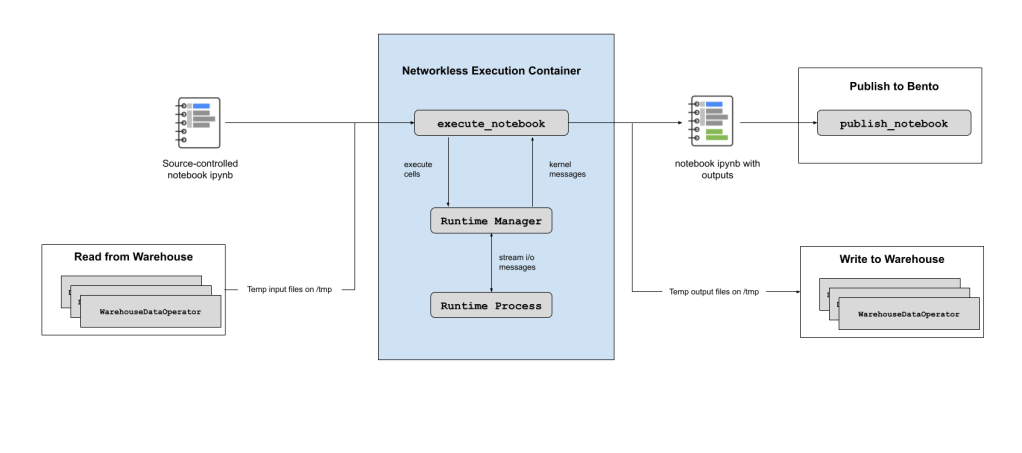
For ETL, we fetch data and write it out in a novel way:
- Supported notebooks perform data fetches in a structured manner via custom cells that we’ve built. An example of this is the SQL cell. When BentoOperator runs, the first step involves parsing metadata associated with these cells and fetching the data using transparent Dataswarm Operators and persisting this in local csv files on the ephemeral remote hosts.
- Instances of these custom cells are then replaced with a call to pandas.read_csv() to load that data in the notebook, unlocking the ability to execute the notebook without any access to the network.
- Data writes also leverage a custom cell, which we replace with a call to pandas.DataFrame.to_csv() to persist to a local csv file, which we then process after the actual notebook execution is complete and upload the data to the warehouse using transparent Dataswarm Operators.
- After this step, the temporary csv files are garbage-collected; the resulting notebook version with outputs uploaded and the ephemeral execution host deallocated.


Our approach to privacy with BentoOperator
We have integrated BentoOperator within Meta’s data purpose framework to ensure that data is used only for the purpose it was intended. This framework ensures that the data usage purpose is respected as data flows and transmutes across Meta’s stack. As part of scheduling a notebook, a “purpose policy zone” is supplied by the user and this serves as the integration point with the data purpose framework.
Overall user workflow
Let’s now explore the workflow for scheduling a notebook:
We’ve exposed the scheduling entry point directly from the notebook header, so all users have to do is hit a button to get started.

The first step in the workflow is setting up some parameters that will be used for automatically generating the pipeline for the schedule.
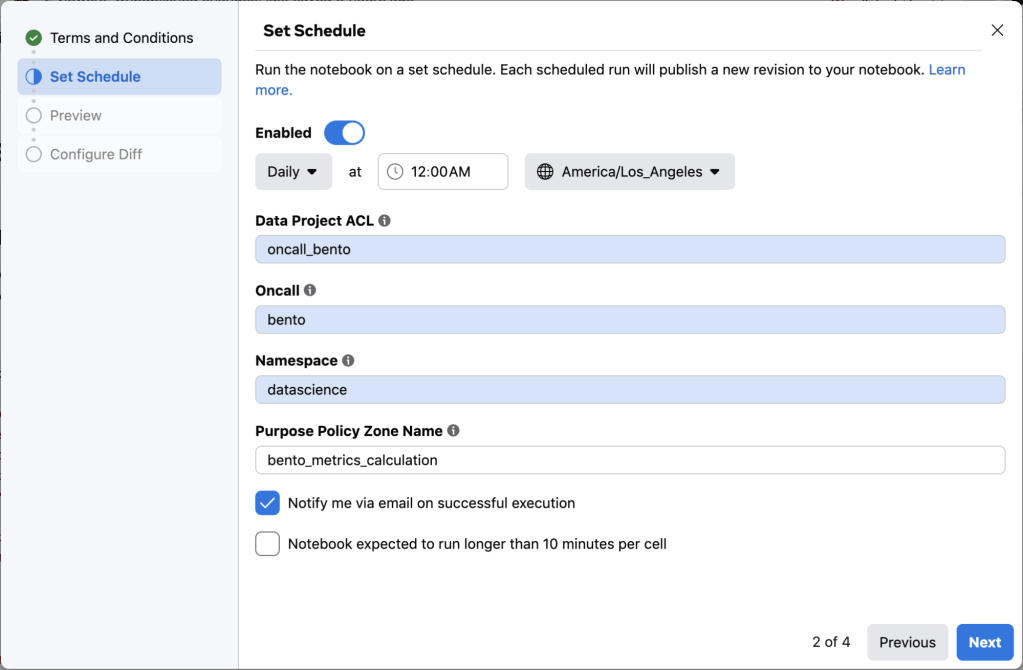
The next step involves previewing the generated pipeline before a Phabricator (Meta’s diff review tool) diff is created.
In addition to the pipeline code for running the notebook, the notebook itself is also checked into source control so it can be reviewed. The results of attempting to run the notebook in a scheduled setup are also included in the test plan.
Once the diff has been reviewed and landed, the schedule starts running the next day. In the event that the notebook execution fails for whatever reason, the schedule owner is automatically notified. We’ve also built a context pane extension directly in Bento to help with debugging notebook runs.
What’s next for scheduled notebooks
While we’ve addressed the challenge of supporting scheduled notebooks in a privacy-aware manner, the notebooks that are in scope for scheduling are limited to those performing ETL or those performing data analysis with no other side effects. This is only a fraction of the notebooks that users want to eventually schedule. In order to increase the number of use cases, we’ll be investing in supporting other transparent data sources in addition to the SQL cell.
We have also begun work on supporting parameterized notebooks in a scheduled setup. The idea is to support instances where instead of checking in many notebooks into source control that only differ by a few variables, we instead just check in one notebook and inject the differentiating parameters during runtime.
Lastly, we’ll be working on event-based scheduling (in addition to the time-based approach we have here) so that a scheduled notebook can also wait for predefined events before running. This would include, for example, the ability to wait until all data sources the notebook depends on land before notebook execution can begin.
Acknowledgments
Some of the approaches we took were directly inspired by the work done on Papermill.








