
Every day Facebook engineers make thousands of code changes and iterate frequently through the edit-compile-run development cycle. Several years ago we built and open-sourced Buck, a build tool designed from the ground up for fast iteration, allowing engineers to compile and run changes quickly.
We’ve continued to steadily improve Buck’s performance, together with a growing community of other organizations that have adopted Buck and contributed back. But these improvements have largely been incremental in nature and based on long-standing assumptions about the way software development works.
We took a step back and questioned some of these core assumptions, which led us deep into the nuances of the Java language and the internals of the Java compiler. In the end, we completely reimagined the way Buck compiles Java code, unlocking performance gains unachievable through incremental improvements. Today we’re open-sourcing a new feature in Buck that will bring these performance improvements to Android engineers everywhere.
The fastest build is the one you don’t have to do
Buck’s architecture is optimized for fast incremental builds, even with compilers that have no built-in incremental support.
Developers using Buck to build their applications define build rules for the different parts of their application. Each build rule may depend on others, resulting in a directed acyclic graph (DAG) of rules.
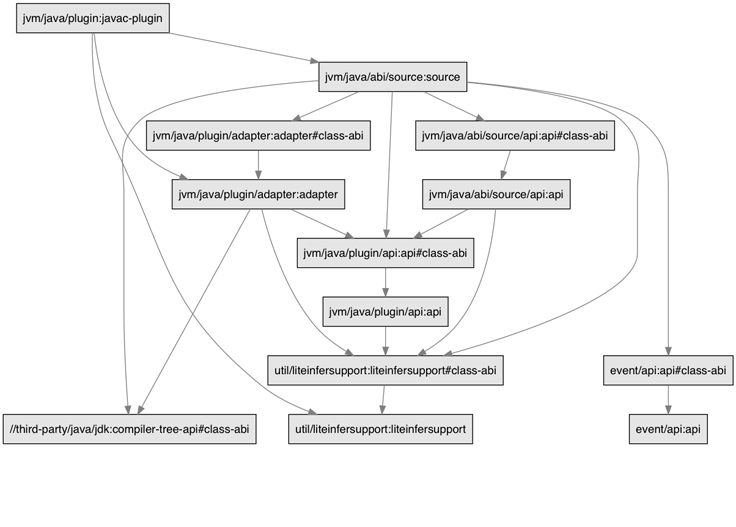
By design, build graphs like the image above help make builds fast. Buck caches the output of each rule, and when it detects a change in a rule’s output it will identify and rebuild only the dependent rules. Buck best practices recommend keeping rules small — not only does it encourage more modular application architecture, it also reduces how much code needs to be rebuilt for any given change, which makes incremental builds faster.
In some cases, Buck does more than naively detect changes in output, such as when rules compile Java code. The output of a Java rule is a JAR file (Java ARchive, essentially a .zip file by another name that contains Java bytecode). There are lots of changes you can make to Java source code that result in a different JAR file but have no impact on dependent rules, yet if Buck was doing a basic comparison of output it would rebuild them anyway. For example, private members and the contents of method bodies cannot affect dependent rules. So after building the JAR file, Buck creates a “stub JAR” by stripping all of those things out, and then compiles dependent rules based on changes in that instead of the full JAR.
Ignoring classes that aren’t used
However, not every dependent of a rule will use every class in the rule, and Buck was still rebuilding all dependents of a rule whenever any class in its stub JAR changed. About a year ago, Buck learned how to detect which classes are used by a rule by monitoring which classes are read by the Java compiler. Now Buck encodes that information in dependency files to look for changes in only those classes when deciding what to rebuild.
Turning this feature on at Facebook reduced the number of rules that Buck rebuilds by 35%. It’s now on by default in the open source version of Buck.
Shortening bottlenecks with rule pipelining
In a graph of any size, Buck is usually able to build multiple rules in parallel. However, bottlenecks do occur. If a commonly-used rule takes a while to build, its dependents have to wait. Even small rules can cause bottlenecks on systems with a high-enough number of cores.
While the standard way of creating a stub JAR is to build a full JAR first and then strip out method bodies and private members, the Java compiler actually has all the information needed to build a stub JAR roughly halfway through its run. By taking advantage of this, Buck is now able to allow dependent rules to start compiling while the compiler is still finishing up their dependencies, much like instruction pipelining in a CPU. This lets us eke out a little more parallelism and shorten the bottlenecks caused by large build rules.
At a high level, the Java compiler operates on the code in two phases: “parse+enter” and “analyze+generate.” The “parse+enter” phase parses the source code and figures out the names and signatures of all the types and members defined in it. The “analyze+generate” phase analyzes the method bodies and generates the bytecode for them — bytecode that only goes into the full JAR. We added a compiler plugin that runs after “parse+enter,” using the compiler’s model of the code to generate the stub JAR. Dependent rules then start building earlier using the stub JAR, while the compiler is still doing “analyze+generate” for the full JAR. Other tools produce stub JARs from source as a separate step using a custom parser. By doing it from inside the compiler, Buck takes advantage of work the compiler is already doing.

At Facebook, introducing rule pipelining has reduced build times by 10%. This feature is also available in open source Buck, but is not yet on by default. To opt in, add abi_generation_mode = source to the [java] section of your .buckconfig file.
Creating parallelism: Who needs dependencies anyway?
Paying attention to class usage allowed Buck to do less work, and generating stub JARs from inside the compiler allowed it to squeeze in a little more parallelism. While these changes were not trivial, they were incremental in nature. To truly break the performance curve we needed to question our core assumptions about building software and fundamentally rethink Java compilation.
Here’s one assumption: before Buck can build any rule, it needs to obtain stub JARs for all of its dependencies. And to build those it needs stub JARs of their dependencies, and so on all the way to the leaves of the build graph.
What if it didn’t?
For a given number of nodes in a graph, flatter graphs produce faster builds, both because of increased parallelism and because the paths that need to be checked for changes are shorter. If Buck didn’t need to build the dependencies first, the build graph would be drastically flattened. Further, it would stay that way. The dependency graph as developers think of it tends to get deeper as an app grows. If the dependencies aren’t actually needed to build, the dependency graph from Buck’s point of view could stay at a more or less constant depth in the face of application growth.
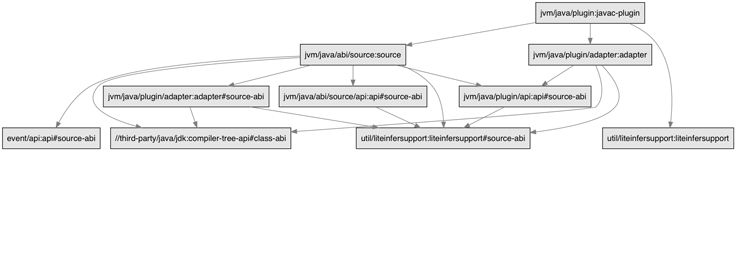
Questioning a core assumption about how Java code is built initially seemed ridiculous. Turns out, it’s not. Nearly all of the information in a stub .class file is present in its source .java file. Humans can figure out the interface of a module by just looking at the source code for the module itself. By making a few assumptions, Buck can now do so as well, through a new feature we call source-only stub generation. Here’s how we did it.
As part of our work to shorten bottlenecks described above, we’d already written a stub JAR generator that could generate stubs after the Java compiler’s “parse+enter” phase. The Java compiler will happily run “parse+enter” with missing dependencies, and its APIs will provide placeholders for missing types. We decided to extend our stub JAR generator to deal with those placeholders when they appeared.
There are two main categories of information in a rule’s stub JAR that may come from the rule’s dependencies: compile-time constants, and some basic information about types (such as their fully-qualified name, whether they are a class or an interface, and whether they even exist). Without dependencies we cannot know this information for sure, but we discovered we can make some pretty good guesses. When we get around to full compilation we can check those guesses and fail the build if they’re wrong. We then either suggest a code change to help us guess correctly, or recommend falling back to using dependencies when generating the stub JAR for the problematic rule.
What’s in a name?
Here’s a basic example:
import com.example.base.Bar;Does this type exist? We can’t know, but when generating a stub JAR we’ll assume it does. If it doesn’t, when Buck gets around to compiling the full JAR the code will not compile.
Is com.example.base a package or a class? We can’t know, but the nearly universal convention in Java is to start class names with upper-case letters and package names with lower-case, so we’ll go with that. If we find significant exceptions to the convention, we can build a way to specify them.
Of course, Java lets you be more brief when referring to classes:
package com.example;
import com.example.base.Bar;
import com.example.helper.*;
import com.example.interfaces.Baz;
public class Foo extends Bar implements Baz {
Compiler c;
}
What is the fully-qualified name of the type Compiler? There are infinite possibilities. (5 concrete guesses can be inferred from this code snippet.) We chose to assume that it is com.example.Compiler. If the engineer wants any of the other cases, they must write something unambiguous like Bar.Compiler or com.example.helper.Compiler.
Java constants also posed a challenge:
import com.example.base.Bar;
public class Foo {
public static final int SOME_CONSTANT = Bar.SOME_OTHER_CONSTANT;
}
What is the value of SOME_CONSTANT? We can’t know if we don’t have access to Bar, so we assume that it is not a compile-time constant. When compiling dependencies of this rule, the compiler will not be able to inline the constant like it normally would (a small inefficiency that can be corrected by running Redex or ProGuard). It can also cause build failures if you use SOME_CONSTANT in a location that requires a compile-time constant, such as a switch statement case label or an annotation parameter. For this case we enabled engineers to tell Buck to make sure Bar is available when generating the stub JAR for Foo.
There were some details of the .class file format that we couldn’t get exactly correct without dependencies (such as distinguishing between classes and interfaces referenced in generic type signatures, or knowing when to generate bridge methods). Fortunately, in most of those cases the details were only relevant at runtime and did not change the compiler’s behavior, so there was an arbitrary “safe” value that we could use that would usually enable the compiler to produce correct code. In the rest of the cases, we have the ability to detect the problem and suggest that the engineer opt out on a rule-by-rule basis.
But annotation processors!
Annotation processors are user-written plugins to the Java compiler that can generate new Java code in response to annotations present in the code being compiled. They’re increasingly popular as a way to reduce boilerplate, move repetitive logic from run time to compile time, or extend the compiler’s analysis capabilities. Their existence is one reason why the compiler puts placeholders for missing types (which was a key enabler of this feature), but they also presented unique challenges. If the code they generate would be visible to dependents, they must be run when generating stub JARs.
In the previous section we taught our stub generator how to guess the information that it needed based on the compiler’s placeholder types. We needed to do the same for annotation processors. Fortunately, the compiler APIs are such that annotation processors interact with the compiler almost entirely through interfaces such as javax.lang.model.util.Elements instead of concrete classes, and Buck was already responsible for instantiating the annotation processors. This allowed us to wrap the annotation processors and provide our own implementation of those interfaces. We had to make sure the annotations themselves were available during stub JAR generation, so that added a few (small) rules that needed to be built before the massive parallelism came into play.
This approach Just Worked with some annotation processors, but others needed to change their behavior when being run as part of creating a stub JAR. Some of those changes would be prohibitive, so we either found ways to avoid running those processors during stub JAR generation, or disabled the source-only generation for rules that used those processors.
Instagram’s build served as the test bed for this feature. For that build, source-only stub generation reduced graph depth by 77% and cut cache fetches by 50%, which together reduced build times by 30%. We expect further improvements going forward as we remove some of the opt-outs, and we’re working on rolling out the feature to our other Android apps.
I want it!
We’re excited to announce that source-only stub generation is available in the Buck open source repository today! Check out the Buck docs for instructions on making your code compatible (there’s an autofix script!) and enabling the feature.
We believe that everyone should benefit from faster iteration; all of these features are available to the community in the Buck open source repository. Keep moving fast, and happy hacking!








