
At today’s Systems @Scale conference, we presented Twine, our cluster management system, which orchestrates containers on millions of servers to run nearly all of our services. Since we first deployed Twine in 2011, our infrastructure has expanded from one data center to a fleet of 15 geo-distributed data center locations. Over the same time period, Twine has evolved significantly to keep pace with our growth. We are sharing several areas in which Twine advances the state of the art for cluster management, including seamless support for stateful services, a single control plane across data centers, and the ability to shift capacity among services in real time. We will also share some of the lessons we have learned as we have grown the system to its current state.
Twine serves multiple stakeholders. Application developers use Twine to deploy and manage applications. It packages an application’s code and dependencies into an image and deploys it onto servers as containers. Containers provide isolation between multiple applications running on the same server, allowing developers to focus on application logic without worrying about how to acquire servers or orchestrate upgrades of their applications. Moreover, Twine monitors server health and, upon detecting a failure, moves containers away from the affected server.
Capacity engineers use Twine to enforce server capacity allocation across teams based on budget constraints and business priorities. They also leverage it to help increase server utilization. Data center operators depend on Twine to properly spread containers throughout our data centers and to stop or move containers during maintenance events. This helps data center operators perform server, network, and facility maintenance with minimal human intervention.
Twine architecture
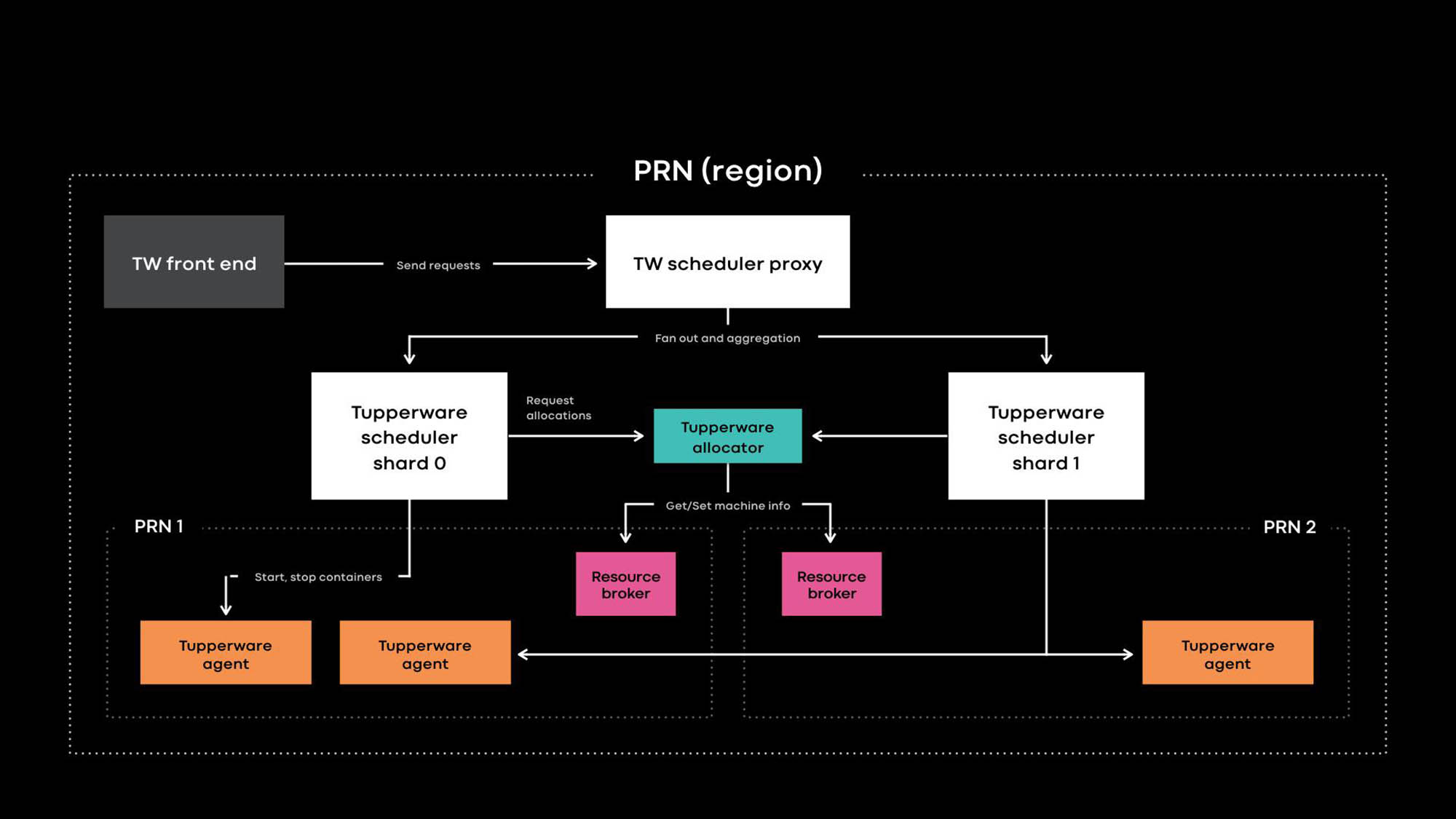
Application developers deploy services as Twine jobs, where a job consists of multiple containers, typically all running the same application binary. Twine is responsible for container allocation and container lifecycle management. It consists of the following components:
- The Twine front end provides APIs for the UI, CLI, and other automation tools to interact with Twine. It hides the internal details of Twine from job owners.
- The Twine scheduler is the control plane responsible for job and container life cycle management. It is deployed at regional and global scopes, where a regional scheduler manages servers from the same region and a global scheduler manages servers from multiple regions. The scheduler is sharded, and each shard manages a subset of jobs in its scope.
- The Twine scheduler proxy hides the internal details of scheduler sharding, and it provides the abstraction and usability of a single control plane to Twine users.
- The Twine allocator is responsible for the assignment of containers to servers. The orchestration of container start, stop, update, and failover is done by the scheduler. Currently, one allocator is scalable enough to handle an entire region without sharding. (Note some differences in terminology from other systems. For example, the Twine scheduler maps to the Kubernetes control plane, and the Twine allocator maps to the Kubernetes scheduler.)
- Resource Broker stores the source of truth for server information and maintenance events. We run one Resource Broker per data center, and it stores information about all servers in the data center. Resource Broker and a capacity management system called the resource allowance system work together to dynamically decide which scheduler deployment manages which servers. A health check service monitors servers and stores their health information in Resource Broker. If a server is unhealthy or needs maintenance, Resource Broker informs the allocator and scheduler to stop or move containers to other servers.
- The Twine agent is a daemon running on every server, and it is responsible for setting up and tearing down containers. Applications run inside containers to provide better isolation and reproducibility. We described how individual Twine containers are set up using images, btrfs, cgroupv2, and systemd at last year’s Systems @Scale event.
Distinguishing features of Twine
While Twine shares many common features with other cluster management systems, such as Kubernetes and Mesos, it distinguishes itself in the following areas:
- Seamless support for stateful services.
- A single control plane managing servers across data centers to help automate intent-based container deployment, cluster decommission, and maintenance.
- Transparent sharding of the control plane to scale out.
- An elastic compute approach to shift capacity among services in real time.
These advanced features grew out of the need to support our diverse set of stateless and stateful applications running in a large global shared fleet.
Seamless support for stateful services
Twine runs many critical stateful services that store persistent data for products spanning Facebook, Instagram, Messenger, and WhatsApp. Examples include large key-value stores (e.g., ZippyDB) and monitoring data stores (e.g., ODS Gorilla and Scuba). Supporting stateful services is challenging because the system needs to ensure that container deployments are resilient to large-scale failures, including network partitioning and power outages. While common practices, such as spreading containers across fault domains, work well for stateless services, stateful services require additional support.
For example, if a server failure renders one replica of a database unavailable, should we allow automated maintenance that will perform kernel upgrades on 50 servers out of a pool of 10,000 to proceed? It depends. If one of those 50 servers happens to host another replica of the same database, it is better to wait and not lose two replicas at the same time. Dynamic decisions, which control maintenance and system health, require visibility into the internal data replication and placement logic of each stateful service.
An interface called TaskControl allows stateful services to weigh in on decisions that may affect data availability. The scheduler leverages the interface to notify external applications of container life cycle operations, such as restart, update, migration, and maintenance events. A stateful service implements a controller that directs Twine when it is safe to perform each operation, potentially reordering or temporarily delaying operations as needed. In the example above, the database’s controller can tell Twine to upgrade 49 out of the 50 servers but temporarily leave a particular server (X) alone. Eventually, if the kernel upgrade deadline passes and the database still cannot recover the failed replica, Twine will proceed with upgrading server X anyway.
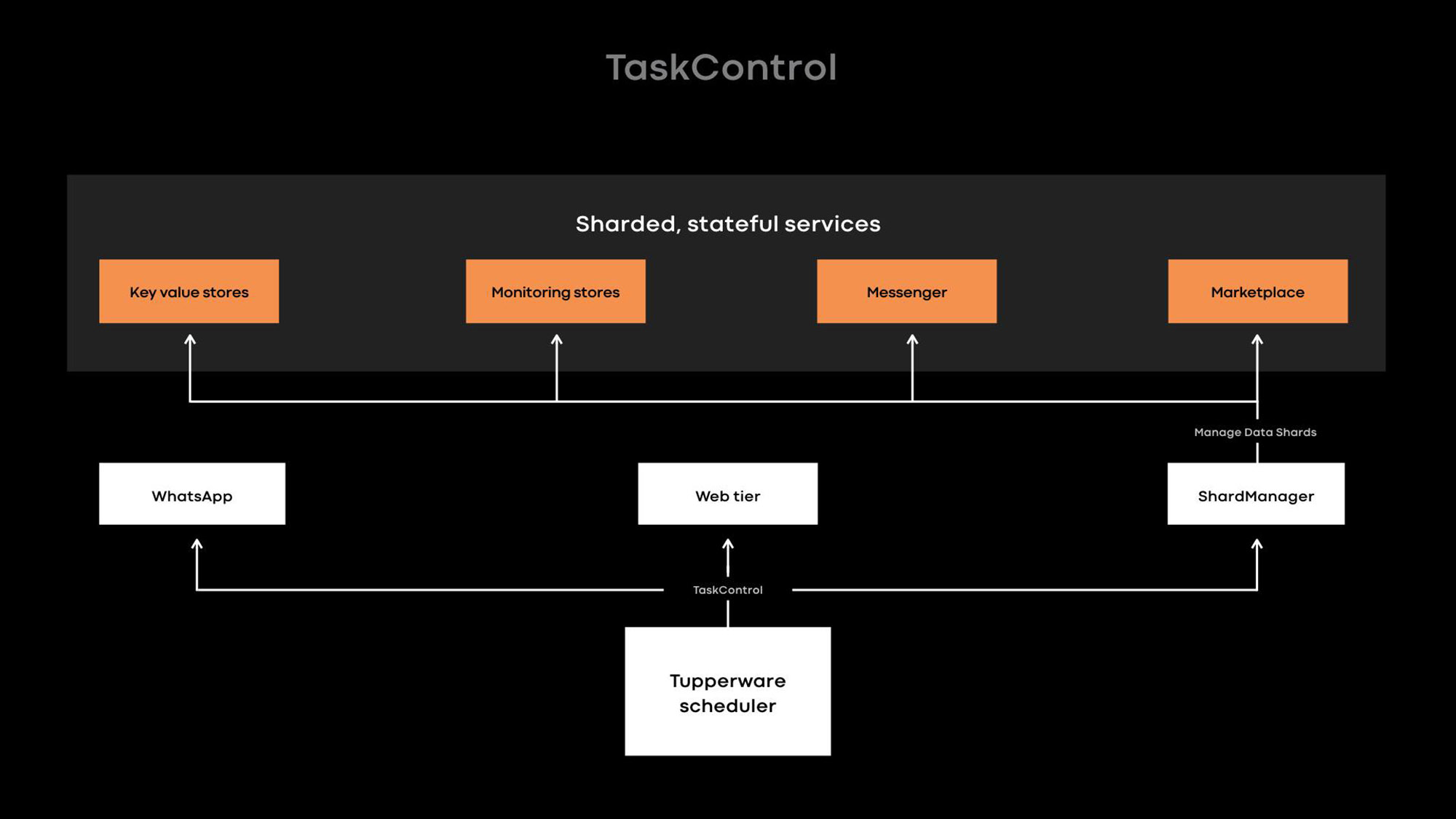
Many stateful services running on Twine use TaskControl indirectly through ShardManager, a widely used programming framework for building stateful services at Facebook. Twine allows developers to specify their intent for how containers should spread throughout our data centers; ShardManager allows developers to specify their intent for how data shards should spread across containers. ShardManager is aware of the data placement and replication of its applications, and it works with Twine through the TaskControl interface to plan container life cycle operations without applications’ direct involvement. This integration greatly simplifies stateful service management, but that is not all TaskControl supports. For example, our large web tier is stateless and uses TaskControl to dynamically adjust the speed of updates across containers. As a result, the web tier can rapidly perform multiple software releases per day without compromising availability.
Managing servers across data centers
When Twine was first created in 2011, every server cluster was managed by a separate, dedicated scheduler. At that time, a cluster at Facebook was a group of server racks connected to a common network switch, and a data center hosted multiple clusters. A scheduler could manage servers only within a single cluster, which meant a job could not span across clusters. As our infrastructure grew, cluster decommissions became increasingly frequent. Since Twine could not migrate a job from a to-be-decommissioned cluster to other clusters transparently, decommissions required large amounts of manual effort and careful coordination between application developers and data center operators. This process often resulted in significant wasted resources as servers idled for months during the decommissioning process.
We introduced Resource Broker to solve this cluster decommissioning problem and to coordinate all other types of maintenance events. Resource Broker tracks all physical information associated with a server and dynamically decides which scheduler manages each server. Dynamic binding of servers to schedulers gives flexibility for a scheduler to manage servers across data centers. Since a Twine job is no longer limited to a single cluster, Twine users can declare their intent for how containers should spread across fault domains. For instance, a developer may declare her intent (e.g., run my job across two fault domains in the PRN region) without dictating specific availability zones to use. Twine will take care of finding the appropriate servers to satisfy this intent, even in the event of cluster decommission or maintenance operations.
Scaling to support a large global shared fleet
Historically, our infrastructure was partitioned into hundreds of dedicated server pools owned by individual teams. Fragmentation and lack of standardization incurred high operational overhead and made idle servers more difficult to reuse. At last year’s Systems @Scale, we announced our Infrastructure-as-a-Service to consolidate our infrastructure into a large global shared fleet of servers. But this shared fleet introduces new challenges with competing requirements:
- Scalability: Our infrastructure has grown as we added more data centers within each region. Further, a hardware shift to using smaller and more power-efficient servers has resulted in each region hosting many more servers. As a result, a single scheduler deployment per region cannot scale to orchestrate the number of containers that can run on hundreds of thousands of servers in each region.
- Reliability: Even if a scheduler is highly scalable, the larger scope per scheduler means there is a larger risk of software bugs rendering an entire region of containers unmanageable.
- Fault tolerance: In the event of a large-scale infrastructure failure, such as a network partition or power outage in which the servers running the scheduler fail, we want to limit the negative impact to just a fraction of a region’s server fleet.
- Usability: These points might imply that we wish to run multiple independent scheduler deployments per region. However, from a usability perspective, maintaining a single entry point for the shared pool per region simplifies many capacity management and job management workflows.
We introduced scheduler sharding to address the challenges in supporting a large shared pool. Each scheduler shard manages a subset of jobs in the region, which allows us to decrease the risk associated with each deployment. As the size of the shared pool grows, we can add more scheduler shards as needed to support the growth. Twine users perceive the scheduler shards and proxy as a single control plane, without having to interact with the numerous scheduler shards that orchestrate their jobs. Note that scheduler shards are fundamentally different from our older-generation cluster schedulers because the former shards the control plane without statically sharding the shared server pool by network topology.
Increasing utilization through elastic compute
As our infrastructure footprint has grown, it has become increasingly important that we achieve high utilization of our server fleet so we can optimize infrastructure cost and reduce the operational load. There are two main approaches to increase server utilization:
- The elastic compute approach is to downscale online services at off-peak hours and provide the freed-up servers to offline workloads such as machine learning and MapReduce jobs.
- The resource overcommitment approach is to stack online services and batch workloads on the same servers and run batch workloads at a lower priority.
A limiting resource in our data centers is power. As a result, we prefer using small power-efficient servers that provide more computational capacity in aggregate. An unfortunate side effect of preferring small servers with less CPU and memory is that resource overcommitment is less effective. While we can stack multiple containers of small services with low CPU and memory needs on a single server, large services do not perform well when stacked on a power-efficient small server. Hence, we encourage developers of our large services to heavily optimize their services to utilize entire servers.
We achieve high utilization mainly via elastic compute. Many of our largest services—such as News Feed, Messaging, and our front-end web tier — exhibit a significant diurnal pattern where their utilization drops significantly during off-peak hours. We intentionally downscale these online systems to run on fewer servers at off-peak hours and provide the freed-up servers to offline workloads such as machine learning and MapReduce jobs.
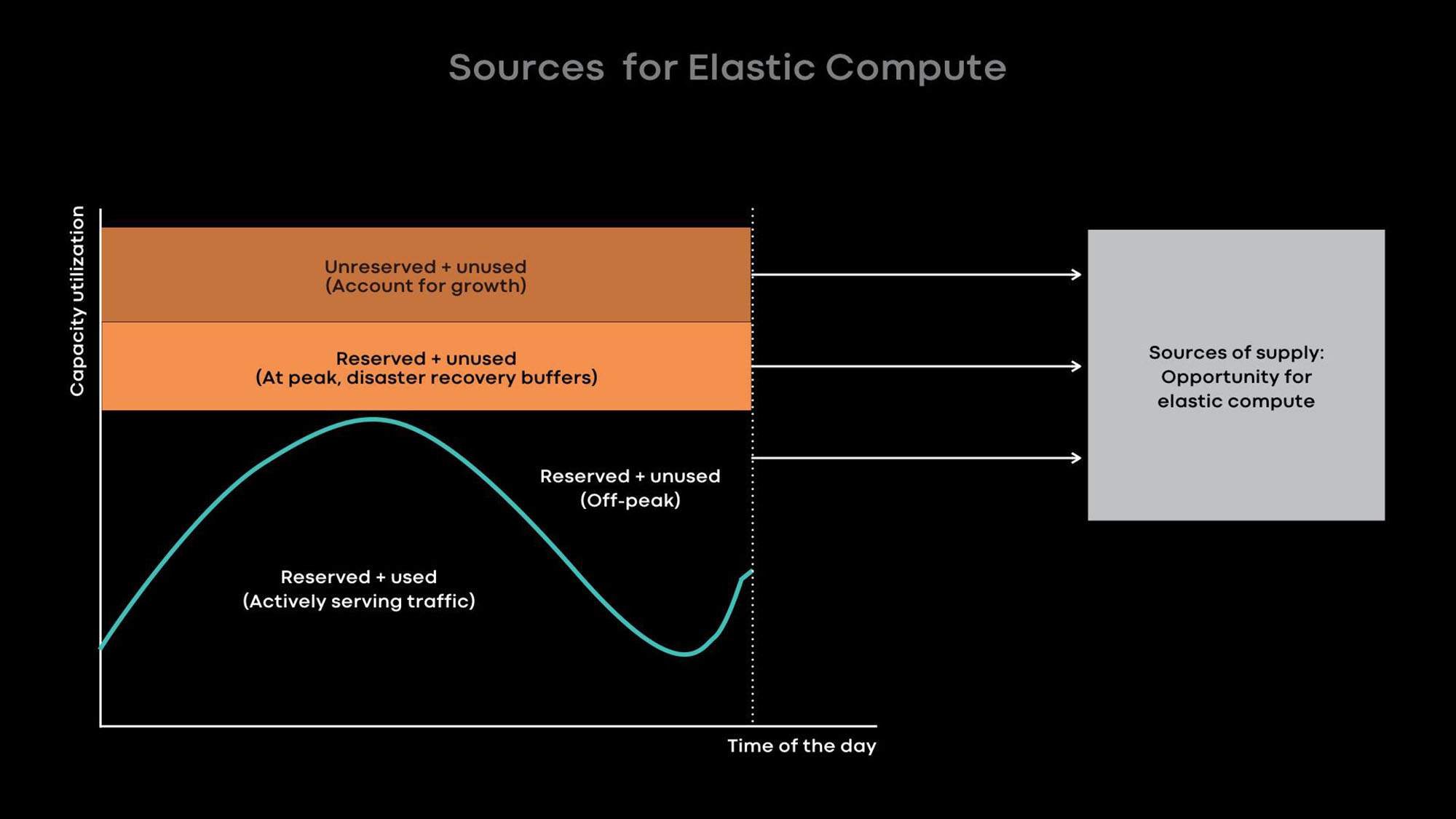
We have learned that it works best to provide whole servers as the unit of elastic capacity because large services are both the largest donors and consumers of elastic capacity and are heavily optimized to utilize entire servers. When a server is freed up from an online service at off-peak hours, Resource Broker loans the server to a scheduler to run offline workloads. If the online service experiences a load spike, Resource Broker quickly revokes the loaned server and works with the scheduler to return the server back to the online service.
Lessons learned and future work
Over the past eight years, we have evolved Twine to keep pace with Facebook’s rapid growth. We are sharing some of the lessons we have learned in the hopes that they will be helpful for others operating a rapidly growing infrastructure:
- Prefer a flexible mapping between a control plane and the servers it manages. This flexibility enables one control plane to manage servers across data centers, helps automate cluster decommission and maintenance, and allows dynamic capacity shifts via elastic compute.
- The abstraction of a single control plane per region greatly improves usability for job owners and provides easier manageability of a large shared fleet. Note that the control plane can maintain the abstraction of a single point of entry even if scale or fault-tolerance concerns lead to the control plane being sharded internally.
- By leveraging a plugin model, a control plane can notify external applications of upcoming container lifecycle operations. Further, stateful services can leverage the plugin interface to customize container management. This plugin model allows the control plane to maintain simplicity while serving many diverse stateful services effectively.
- We find that elastic compute — our process that frees up entire servers from donor services for use by batch, machine learning, and other delay-tolerant services — is an effective way to drive up server utilization while running a fleet composed of small, power-efficient servers.
We are still early in the execution of one large global shared fleet. Currently, about 20 percent of our servers are in the shared pool. To reach 100 percent, we have many challenges to address, including creating shared pool support for storage systems, automating maintenance, adding multi-tenant demand control, increasing server utilization, and enhancing support for machine learning workloads. We look forward to tackling these problems and sharing our progress.
*Facebook’s Tupperware cluster management system is now called Twine.








