
We run one of the largest microservices deployments in the world, with thousands of services that perform billions of requests per second. Keeping information secure as these services communicate globally is a complex job that requires thoughtful consideration of tradeoffs between performance, security, and operability. We are sharing new details about how we designed our encryption infrastructure within our data centers, along with lessons for others working to implement state-of-the-art security in their own systems.
We previously explained how we implement Transport Layer Security (TLS) on the public internet, including our Fizz library and our pilot project for DNS over TLS. In this post, we’ll talk about how we migrated our encryption infrastructure in data centers from the Kerberos authentication protocol to TLS. Optimizing for operability and performance, while still satisfying the right security model for each service, required navigating difficult trade-offs. By sharing our experiences, we hope to show how we think about our encryption infrastructure and help others as they think through their own implementation.
Security: More than just the encryption protocol
Because of different constraints, the threat model of the data center is different from that of the open internet, and encryption is not the only method to secure services. We control the machines that run the clients and servers in our data center, the network that connects them, and the switches that route data between the machines, which we configure to add access control at various levels. We view encryption as an elegant approach to add end-to-end defense in depth, in addition to these mechanisms.
Our services communicate with each other using Thrift as a remote procedure call library. Services generally run inside containers, and our orchestration system, called Tupperware, manages our containers. Normally, encryption threat models focus on attackers intercepting bytes in transit, but we wanted to build a solution that would be resilient even if attackers hypothetically gained access to hosts. Central to this goal is defining what identity means for services. In other words, who is able to access those services, when, and under what circumstances? We also need to define where the private keys for those identities should be stored and what happens if those identities are compromised. For example, if engineers have access to a host running services with a particular identity, they should not be able to decrypt traffic from hosts from other identities — or even other hosts from the same identity forever. We should also be able to backtrack to detect exactly where a service identity was compromised, to take appropriate action.
The encryption system needs to be incredibly robust to errors. For instance, what happens when a single connection fails to establish? What happens if an entire region fails and traffic has to fail over to another region? How do we prevent cascading failures (a common industry concern) in connection setup storms? With such a large number of hosts, we’ve had to deal with several interesting cases, including bugs in the CPU cores causing connection failures. Our design has gone through several iterations; we’ll discuss two of these and the principles we used to improve the system over time.
The three-headed dog
For our original design back in 2012, we selected Kerberos (named for the three-headed hound of Greek mythology). At the time, Kerberos was a sound choice for our needs. It was a mature protocol design that provided confidentiality, integrity, and authenticity. It supported several platforms and had mature implementations such as MIT Kerberos. TLS 1.2 was a nascent protocol at that point — most of the internet was still HTTP, and it had not yet been proven whether TLS could scale fully.
In the Kerberos system, if a client wants to talk to the server, it first has to talk to the key distribution center (KDC). The KDC then provides the client with a ticket that only the client and server can decrypt. This allows both the client and the server to verify that the other has the right identity and derive a session key to encrypt Thrift requests. We set up several systems to help Kerberos scale to suit our needs. In addition to building Kerberos support and in-memory ticket caching into Thrift, to pre-fetch tickets, we also tuned thread pools to scale to large services and clients with tens of thousands of concurrent connections and made multiple improvements to the MIT Kerberos library.
As we gained more experience and deployed Kerberos at a larger scale, we started to see issues. Several services have a large fan-out and talk to thousands of different services and thus need to fetch tickets from the KDC on a frequent basis. The KDC machines would fail from time to time, and the fallout of failure was that clients would not be able to talk to servers all of a sudden. In other cases, clients would send requests in bursts and would need to fetch multiple tickets simultaneously. The Kerberos libraries we used employ synchronous I/O, which meant we had to manage a thread pool on the clients. Thread pools are complex to tune, and we found that our thread pools were not able to keep up with bursty workloads, causing large delays. The errors and delays affected the reliability of our production systems.
The switch to TLS
Although Kerberos provided strong security guarantees, our experience showed us there is a major trade-off between the security and operability of the system. After several years of trying to manage these issues with Kerberos, we decided to redesign the system from the ground up. We based our new design on TLS mutual-authentication with X.509 certificates. By this time, we had built one of the largest deployments of TLS on the internet, and our TLS implementation and tools had matured quite a bit. Using a uniform protocol between external and internal traffic offered the advantage of being able to reuse our expertise in both domains. At the heart of the new design is how to manage the trade-off between security and operability at scale, and we set down some key ideas:
- We needed to set up X.509 certificates for TLS to be able to authenticate end points. We realized that errors fetching X.509 certificates will likely happen for some small percentage of attempts. At our scale, even a small percentage of failures can result in a lot of errors. With Kerberos, we had to fetch tickets after the container was set up, because we didn’t know a priori what other services a particular service might speak to, and a ticket is specific to a client-server pair. We realized that it would be much less disruptive if a failure occurred during container setup than after the setup was complete. Our service discovery systems perform health checks and won’t send traffic to services in containers that are down. With TLS, we can fetch certificates at container setup time, because they are not bound to the server-client pair. If the error rate is low, then this process will prevent those failures from becoming request errors. Instead, they will remain errors in starting the service, preventing disruption.
- To keep services reliable and to make debugging easier, we avoid talking to any other service while establishing secure connections and sending requests. In Kerberos, we might speak to the KDC which might fail. As a result, connections can only fail if the service itself goes down.
- To reduce CPU usage during the migration from Kerberos to TLS, it’s helpful to use symmetric key cryptography as much as possible. The TLS protocol has the ability to resume connections using a session ticket. The session ticket is an encrypted identifier of a prior connection using a Session ticket encryption key (STEK), known only to the server. The STEK allows future connections to use only symmetric key cryptography instead of asymmetric key cryptography.
- Service owners should not need to know about or decide how to provision key material. We should be able to share the same STEK transparently across several hosts in and across data centers. This helps a large number of asymmetric cryptographic handshakes survive during re-connection storms in the expected case of a data center going down. In the Kerberos world, a ticket is required for each service a client talks to, which greatly contributes to KDC overloads.
- We should rotate ticket keys robustly to have perfect forward secrecy (PFS). Kerberos did this by re-fetching tickets when they expire. But if there is a failure in fetching the tickets in Kerberos, the connection would fail to establish. In our new TLS design, if a server fails to fetch the session ticket, it falls back to a more CPU-intensive asymmetric key algorithm, but the connection does not fail. Provided this happens infrequently, even a highly loaded server can deal with full handshakes.
- We should be able to rotate TLS certificates frequently and have one centralized place to invalidate these certificates. This would allow limiting the time that a compromised certificate can be used.
Provisioning identities
Delegation of authority is important to our goal of provisioning a certificate during container setup. Services should be able to set up a connection and verify the identity they’re connecting to, without needing to talk to anyone else. Delegation has a natural trade-off between security and operation: The longer you delegate an identity, the more reliable it is (because you don’t need to talk to another service), but the harder it becomes to revoke that identity. To manage certificates, we built our own internal certificate authority (ICA) service, which can not only sign certificates but also supply ticket keys to services. To be able to fetch certificates during container setup, we integrated Tupperware with our ICA.
Bootstrapping trust is one of the most difficult problems in a security system. We created a hierarchical identity setup to bootstrap trust because several systems have to work together to provide an identity to a service. The animation shows the process of provisioning certificates. We created three types of certificates:
- A high-privilege host certificate: This is used to prove to the ICA and others that a service is running on a particular host and is accessible only to high-privilege users on the host, such as root. The trusted host provisioning system fetches this certificate from the ICA.
- An identity certificate: This certificate contains an identity of the service that is running in a container. It is represented by an attribute in a custom X.509 extension in the certificate. Authenticated identities are used in several ways, for example, to restrict API calls to only certain services. Tupperware runs an agent on the host to obtain the identity certificate of the service from the ICA right before it starts the service. Tupperware creates a signed token and a certificate signing request (CSR) and calls the ICA by creating a mutually authenticated TLS connection with the host’s high-privilege certificate. The ICA verifies that the request is from the correct host and from Tupperware, and issues the certificate.
- A low-privilege host certificate: This certificate is similar to the high-privilege host certificate but is accessible to other Linux users.
Our system provides some properties that help us mitigate the trade-offs of delegating authority:
- The private key is never transmitted over the network and is known only to the host using it.
- Each host has a unique certificate, which can be audited and revoked individually. The ICA can control the duration of validity of all the certificates. Having a unique certificate per host also enables us to use short-term certificates.
- Normally, rotating a short-term certificate would be difficult, because it is hard to prove that an attacker does not have control of a particular certificate. But because each certificate is unique, we set up an API in our ICA to be able to automatically exchange an old certificate for a new certificate only if the certificate has not been compromised. We can also use this renewal API call to decide whether the old certificate was revoked and then decide not to issue a new certificate.
Rotating ticket keys all around the world
Full TLS handshakes use different forms of asymmetric crypto to provide confidentiality and mutual authentication. TLS has a mechanism to resume a TLS session from a previous connection called TLS tickets. TLS tickets allow the use of symmetric crypto, which is an order of magnitude more efficient. Specific services inside our data center that do millions of connections per second would take a significant hit if we required every connection to perform full handshakes without a significant redesign. To demonstrate how important resumption is, the graph below shows CPU utilization when we tested a quick rotation of STEKs (which temporarily lowered the resumption rate).
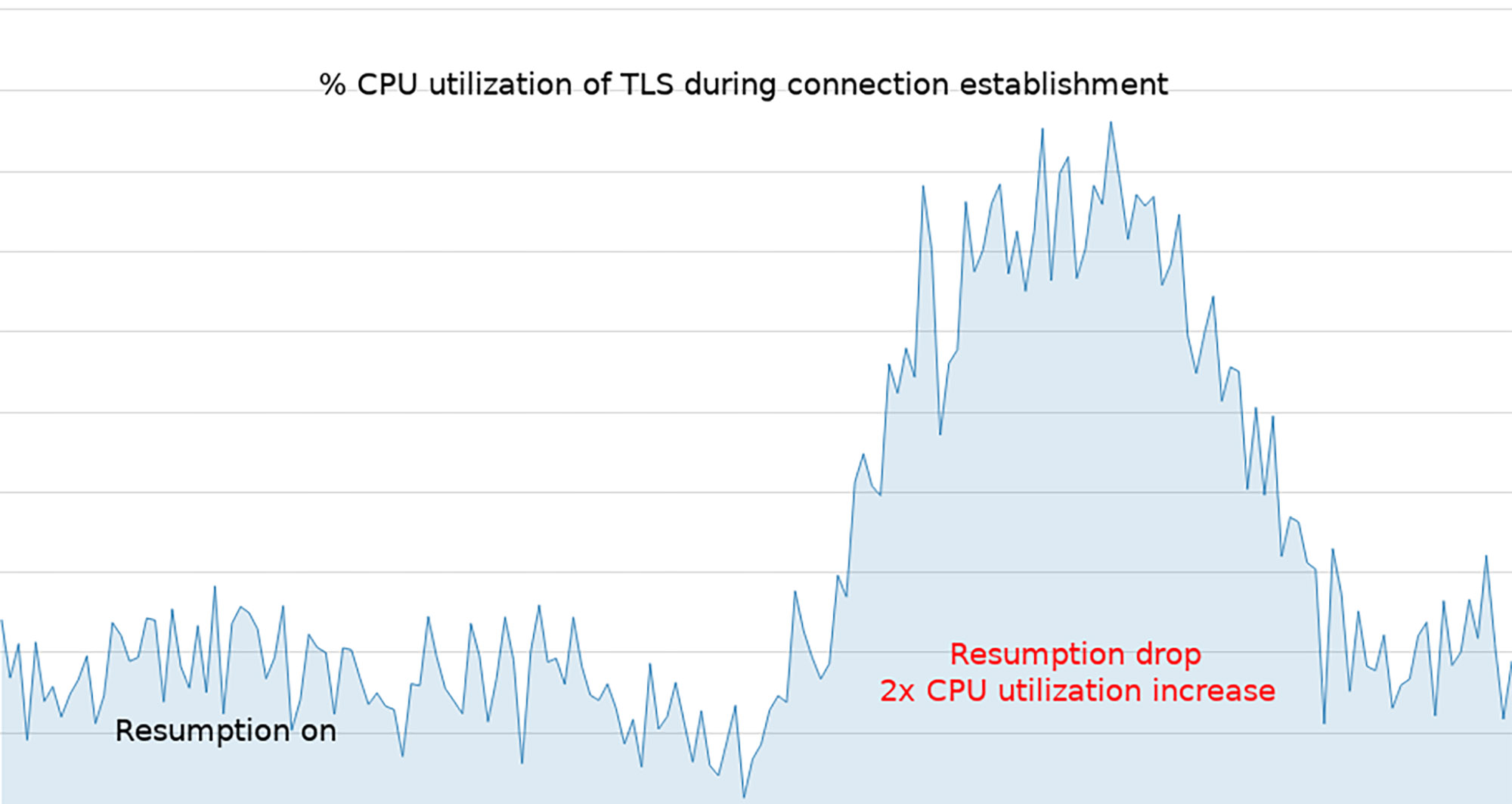
Using resumed tickets is a classic trade-off between operability of the service and security. If not used judiciously, resumption can provide weaker security properties. For example, if attackers obtain the STEK, they could decrypt all the traffic — not only for their host but for other hosts as well, using the same STEK. Resumption cannot re-validate the identity of the client, so having the STEK means that one could masquerade as any other service to a service using that STEK. Thus, we wanted to mitigate the risk of using session tickets by using different STEKs between services and rotating them frequently to reduce the compromise window. Performing global rotation of STEKs is not operationally robust. We have thousands of different services running on hundreds of thousands of hosts, which would need to synchronize STEKs. Debugging de-synchronization failures would be very difficult. We designed a system to distribute STEKs that was simple to operate and did not require service owners to perform any configuration.
After Tupperware sets up the service, a periodic task is automatically installed in each container to fetch STEKs. The job calls the ICA via a mutually authenticated TLS connection using its identity certificate as a client certificate. The ICA then verifies the identity certificate and generates three STEKs for the service using a key derivation function (KDF), like so:
Generate_STEK(ica_secret, identity) =
KDF(ica_secret, identity, ...)The identity comes directly from the client identity in the mutually authenticated TLS connection. The ICA rotates and maintains three master STEKs and rotates them between all the ICA machines. It returns three STEKs to the host:
{
"previous": [Generate_STEK(previous_ica_secret)],
"current" : [Generate_STEK(current_ica_secret)],
"next" : [Generate_STEK(next_ica_secret)],
}Having three keys allows graceful rotation of the tickets. Services issue tickets with the “current” keys and accept tickets with the previous and next keys. The STEKs are stored inside the container, and the service reloads the STEKs whenever they change.
This system has some very nice properties. The algorithm for the generation of STEKs is all in the ICA. Therefore, individual hosts in different data centers do not need to communicate with one other to rotate secrets, and they can get the same ticket keys. We can also set security policies for ticket sharing in a single place. For example, if we want to share tickets between specific data centers, we can just push a change to the ICA. Service owners do not need to do anything to provision tickets, reducing the risk of human error. Tickets are generated directly from the identity certificate, so their lifetime is naturally tied to the lifetime of the identity certificate and bound to the same authorization policies. New services immediately get tickets, without any lag. We have been running this service in our production environment and found that it is reliable at our scale.
Why is deploying encryption difficult?
Deploying encryption at our scale is challenging. We’ll discuss a few of the challenges that we designed for and ran into. We came up with some effective solutions to these issues that would be relevant outside of Facebook.
Once we had all the systems and code in place, we couldn’t simply flip the switch to turn TLS on everywhere at once. Each service updates on its own schedule, so we had to make sure that clients that didn’t support TLS could continue talking to servers while they gradually updated. We also wanted to make sure we had a way to turn off TLS quickly if something went wrong. To do this, each server would need to accept both TLS and plaintext connections. The usual way to accomplish this is to allocate a different port for TLS. In our case, this wasn’t ideal because ports are auto-assigned and each port also has a nontrivial overhead — for example, it needs to be independently health-checked. To reuse the same port for both plaintext and TLS, we built a mechanism that peeks at the first few bytes to determine whether the client is speaking TLS and dispatches it to the correct handler on the server. The client then determines whether to speak TLS to the servers. We built an out-of-band mechanism to detect and flip client settings when we know servers support TLS.
Another challenge was in tuning the CPU performance for encryption. Thrift services use asynchronous I/O and use an event loop in which they process I/O events. It is very important that each operation in this loop be on the order of 10 microseconds to protect service responsiveness. TLS connection establishment involves asymmetric key operations, which can slow down the event loop. One example of an issue we faced was that we found several services that would send a burst of requests when they started up. A naïve connection pool algorithm checks the connection pool for the destination for each request, and if it doesn’t find a pooled connection, it creates a new connection. Because TLS took slightly longer to establish connections on the event loop than plaintext requests, when we turned on TLS, we saw that each request would create a new connection and the host would run out of file descriptors to allocate to all the connections. To solve this problem, we implemented late-socket binding for our connection pool. This means that if there were several connections pending for the same host, instead of establishing a connection immediately for each request if there was not a pooled connection, we would queue up all the requests for a host. As soon as the connection to the host was established, we would then multiplex all the requests on that connection. We also performed connection establishment on a separate thread pool, which relieved the main event loop from asymmetric key operations.
At our scale, even the smallest probability of errors in TLS Thrift end up having relatively large impact. One example of such an issue we encountered was when we started seeing several TLS errors as a result of the finished message not computing correctly between the client and server. Normally, a finished message is used in TLS to detect an attack on the handshake, and they should mismatch only if there is tampering of data. We knew that these machines were in our private network and there would be no one tampering with the connection at the time of the errors. We suspected everything, including faulty network hardware and a code bug. After several days, we finally narrowed down the issue to a bad Advanced Vector Extensions (AVX) instruction on a single CPU in our fleet. To mitigate these kinds of errors, we rolled out additional checks to make sure we would flag these issues earlier in the provisioning process.
The new design of our encryption infrastructure has had a big impact on the reliability and performance of services. We saw an improvement of reliability for non-application errors, from 99.99 percent to almost 100 percent. As a result, our overhead for debugging issues during our on-call reduced significantly, and we could focus more on improving performance.
To further improve performance, we implemented our own library for TLS 1.3, called Fizz. As of this writing, ours is the largest deployment of TLS 1.3 on the internet, and we’ve deployed it to our internal services. Fizz provides zero-copy features, which have decreased request latency and reduced CPU usage for several of the high-request rate services by 10 percent to 15 percent over TLS 1.2.
Future work
We’ve come a long way since Kerberos, and we’ve built a robust system based on TLS. To make encryption practical at scale involves ongoing evaluation of trade-offs between security and operability. Our work on encryption is a continuous process, and we are trying to push the boundaries of existing technologies to further improve the performance and security of Fizz and Thrift. For the future, our team is interested in technology that will transparently encrypt traffic. We hope these lessons will be useful for others to enable encryption within their infrastructure in a maintainable and performant way.
Many people have made significant contributions to this work, including Alex Dibert, Puneet Mehra, Angelo Marletta, Andrei Bajenov, Callen Rain, Yedidya Feldblum, Scott Renfro, Berk Demir, Steve Weis, Anita Zhang, Mingtao Yang, and Leonardo Piacentini.








