
When we first shared details of our data center fabric, we were supporting 1.35 billion people on one app. Since then, we have openly shared our journey of building our own switches, writing FBOSS (our own network operating system) and continuing to scale out various aspects of the network. Most recently, we announced last year our distributed network system, Fabric Aggregator. Fast-forward to today. Our data center fabrics now support more than 2.6 billion people on a family of video-enabled, real-time apps and a rapidly expanding, extremely demanding set of internal services. We have grown from a handful of regions to 15 locations around the world. Even as the demands increase, we are bound by hard physical constraints of power and optics supply availability.
Because of these dual pressures of increasing demand and physical constraints, we decided to rethink and transform our data center network from top to bottom, from topologies to the fundamental building blocks used within them. In this post, we’ll share the story of this transformation over the last two years:
- In the network, we developed F16, a next-generation data center fabric design that has 4x the capacity of our previous design. F16 is also more scalable and simpler to operate and evolve, so we are better equipped for the next few years. We developed F16 using mature, readily available 100G CWDM4-OCP, which in essence gives us the same desired 4x capacity increase as 400G link speeds, but with 100G optics.
- We designed a brand-new building block switch, Minipack, that consumes 50 percent less power and space than its predecessor. More important, it is built to be modular and flexible so it can serve multiple roles in these new topologies and support the ongoing evolution of our network over the next several years. In addition to Minipack, we also jointly developed Arista Networks’ 7368X4 switch. We are contributing both Minipack and the Arista 7368X4 to OCP, and both run FBOSS.
- We developed HGRID as the evolution of Fabric Aggregator to handle the doubling of buildings per region.
- FBOSS is still the software that binds together our data centers. There were significant changes to ensure that a single code image and the same overall systems can support multiple generations of data center topologies and an increasing number of hardware platforms, especially the new modular Minipack platform.
New data center topologies: F16 and HGRID
In rethinking our data center topologies over the past few years, we considered demand-related factors, including:
- Higher per-rack speeds: We were projecting the need for much more inter-rack bandwidth. The workloads as well as the NIC technology were easily capable of driving 1.6T and more per rack.
- More regions, bigger regions: Our data center regions were originally designed for three buildings at most, so the interconnection network was created for that scale. But our compute demands were growing so quickly that, in addition to building new regions, we looked back at our existing regions to see where we could double their footprint to six buildings.
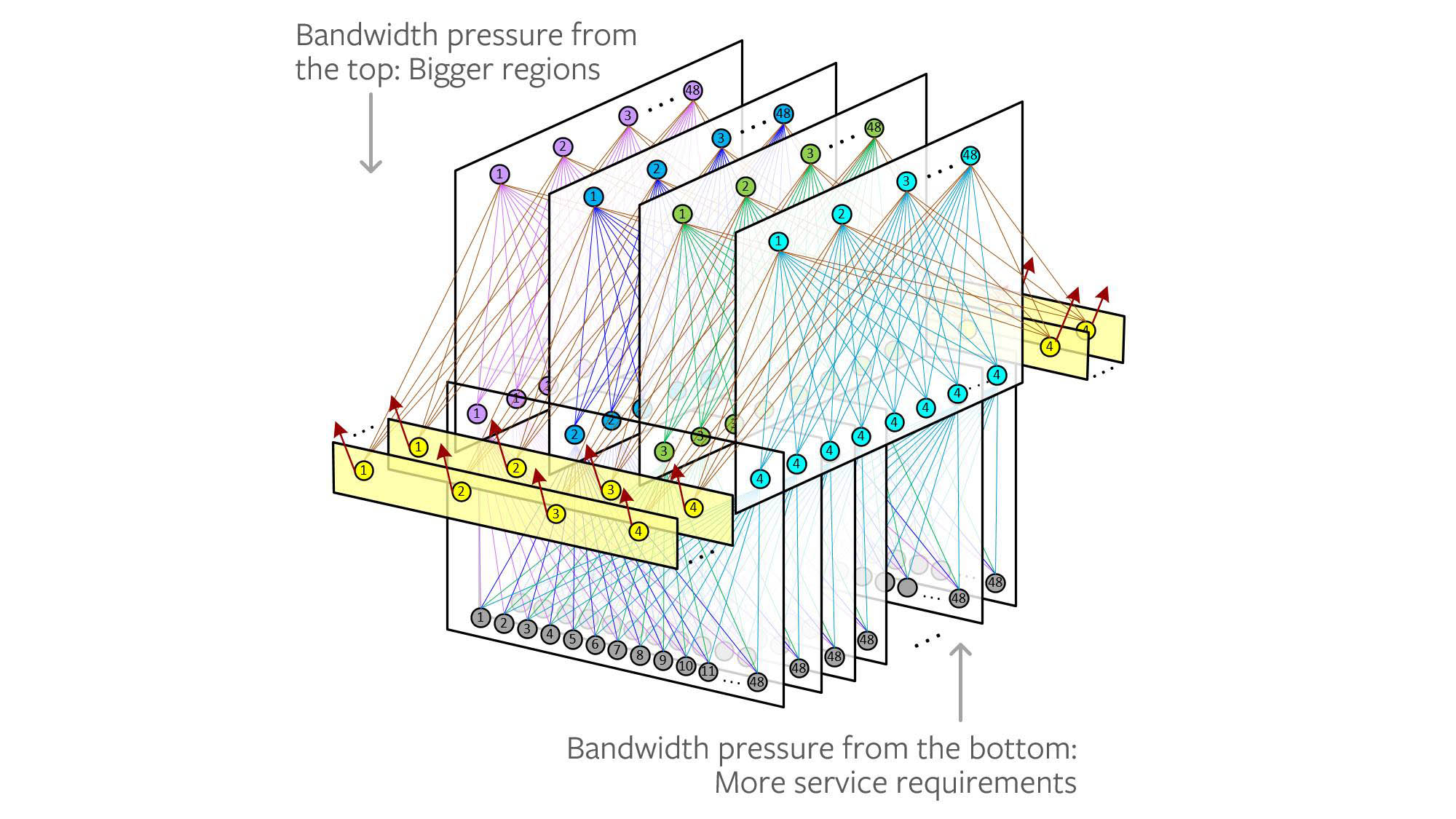
In terms of hard, physical constraints, we considered factors such as:
- Power: The power in a region is a fixed resource. Many of our regions already have dedicated power facilities with more than 100 MW of capacity. Just because we have the real estate to double the number of buildings, however, doesn’t mean we can double the available power for everything in those new buildings. On top of that, the higher bandwidth ASICs and optics (e.g., 400G) require more power. Therefore, the network would have used a disproportionate amount of the overall DC power budget.
- Optics availability: The need for new data center buildings meant that whatever optics technology we selected had to be rolled out at a massive scale — and in time for our deployment goals. We had concerns about the availability of 400G optics at scale and the risk of adopting such leading-edge technology in these early stages.
In addition, we’ve learned that operating a data center fleet at Facebook’s scale means constantly evolving our networks. While we continue to roll out “green field” data centers, every iteration marks the “new” data centers as the ones we need to upgrade. This upgrade process is something we wanted to pay much more attention to in these future designs.
Some alternatives
We considered a number of options to reach these higher bandwidths. For example:
- We could take the previous fabric design and simply add more fabric planes with our existing multichip hardware. But this would have required too much power from the existing fabric switch. Backpack’s current design requires twelve 3.2Tb/s ASICs to provide 128x100G ports, for a total of 48 ASICs in a single pod. We looked into alternative, non-Clos topologies within Backpack, but that still did not provide enough power savings.
- We could increase link speeds in Backpack, moving to 400G. Chasing the latest optics, though, would require 800G or 1,600G optics in another two to three years. This clearly isn’t viable given that, even now, 400G optics are not available at the scales we need.
Announcing F16, our next-generation fabric topology
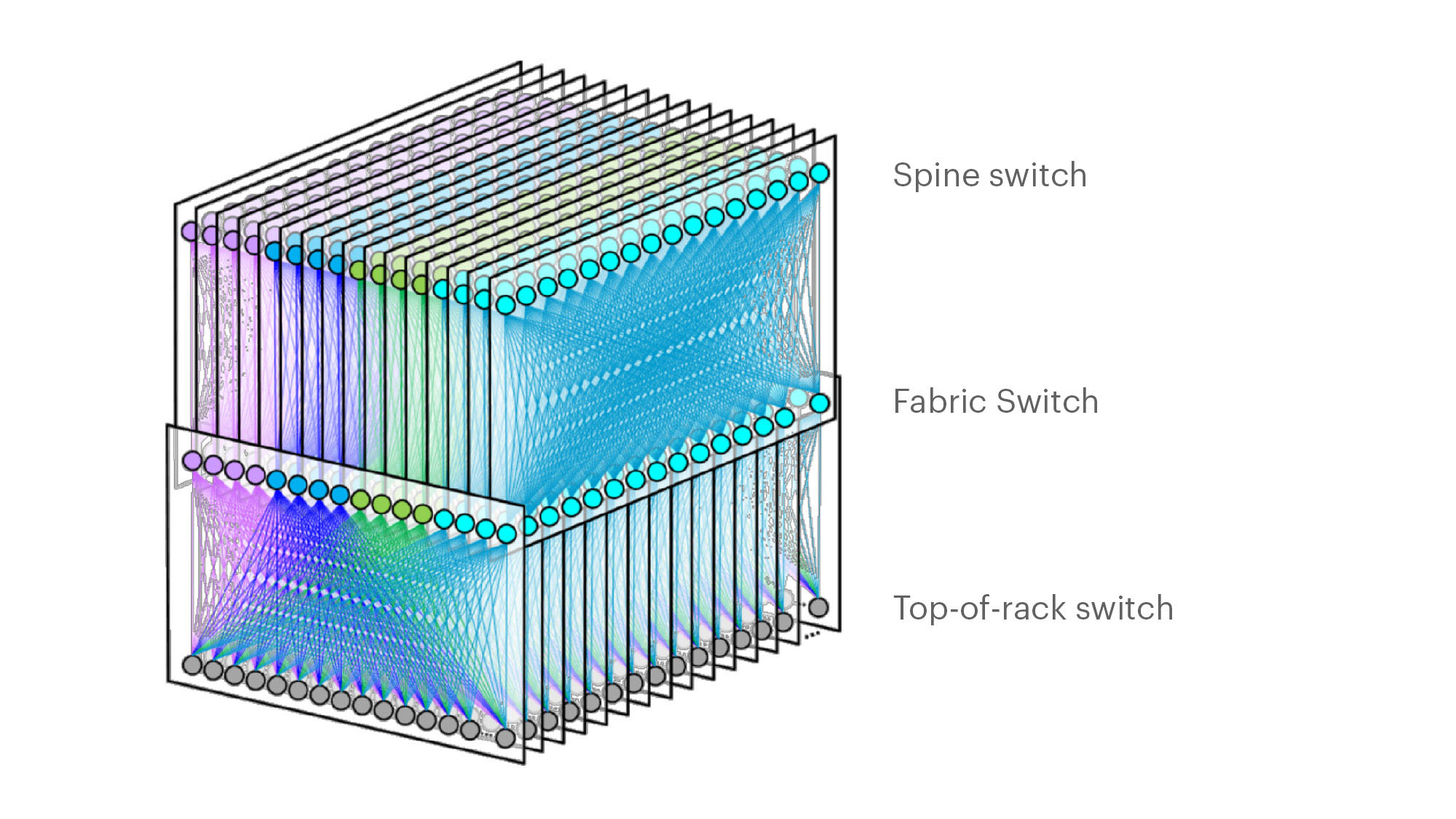
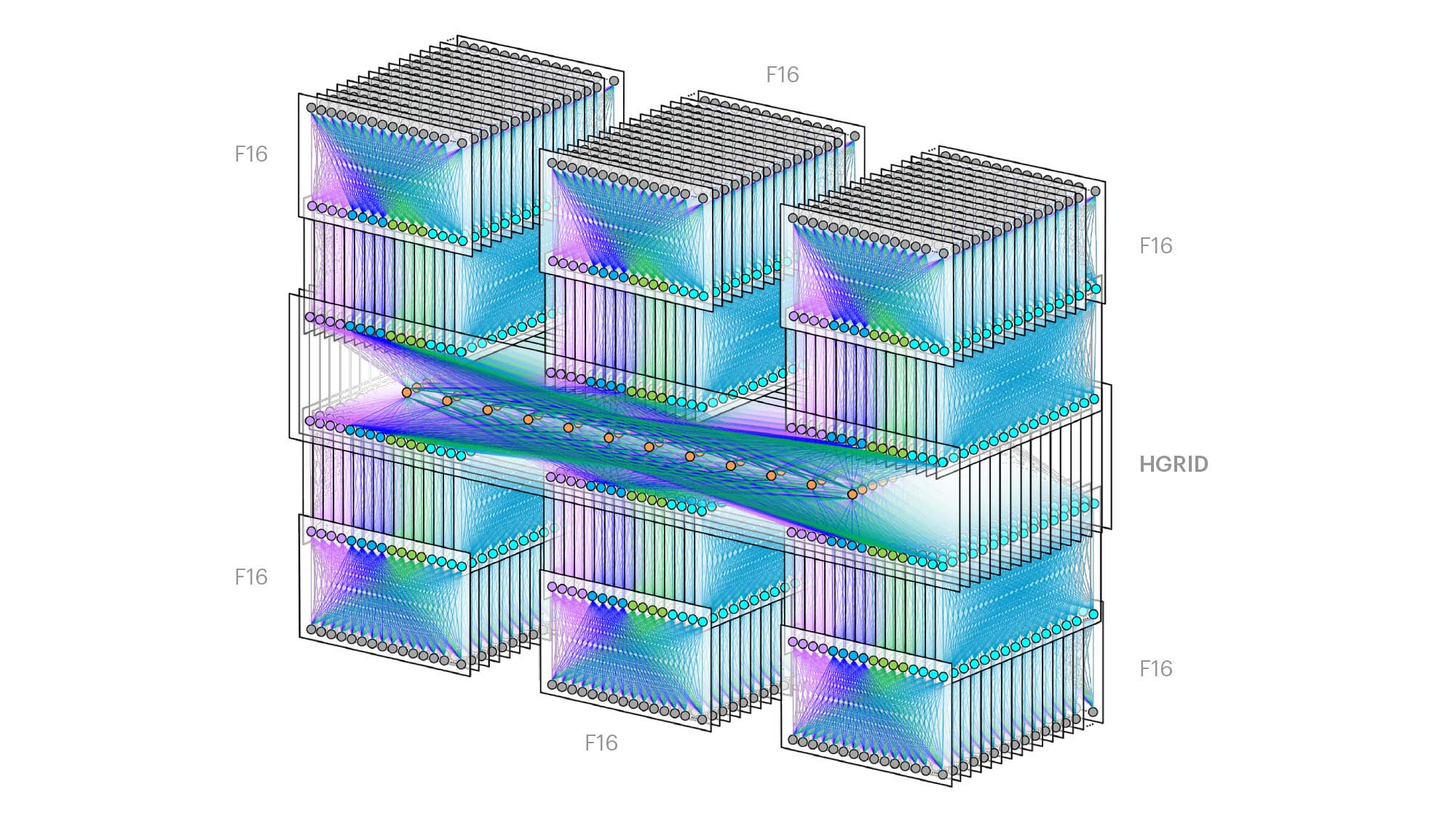
After evaluating multiple options, we converged on a topology within each data center building, which we call “F16.” It is based on the same Broadcom ASIC that was the candidate for a 4x-faster 400G fabric design, Tomahawk 3 (TH3). But we use it differently: Instead of four multichip-based planes with 400G link speeds (radix-32 building blocks), we use the ASIC to create 16 single-chip-based planes with 100G link speeds (our optimal radix-128 blocks). Below are some of the primary features of F16:
- Each rack is connected to 16 separate planes. With Wedge 100S as the top-of-rack (TOR) switch, we have 1.6T uplink bandwidth capacity and 1.6T down to the servers.
- The planes above the rack comprise sixteen 128-port 100G fabric switches (as opposed to four 128-port 400G fabric switches).
- As a new uniform building block for all infrastructure tiers of fabric, we created a 128-port 100G fabric switch, called Minipack. Minipack is a flexible, single ASIC design that uses half the power and half the space of Backpack. Furthermore, a single-chip system allows for easier management and operations.
Both typical ways of using the Broadcom TH3 chip — 32 ports at 400G or 128 ports at 100G — can provide us the target 4x capacity increase, up to 1.6T per rack. By choosing 100G for F16, we were able to achieve it with 3x fewer fabric chips, going from 48 infra switches per pod to only 16 per pod:
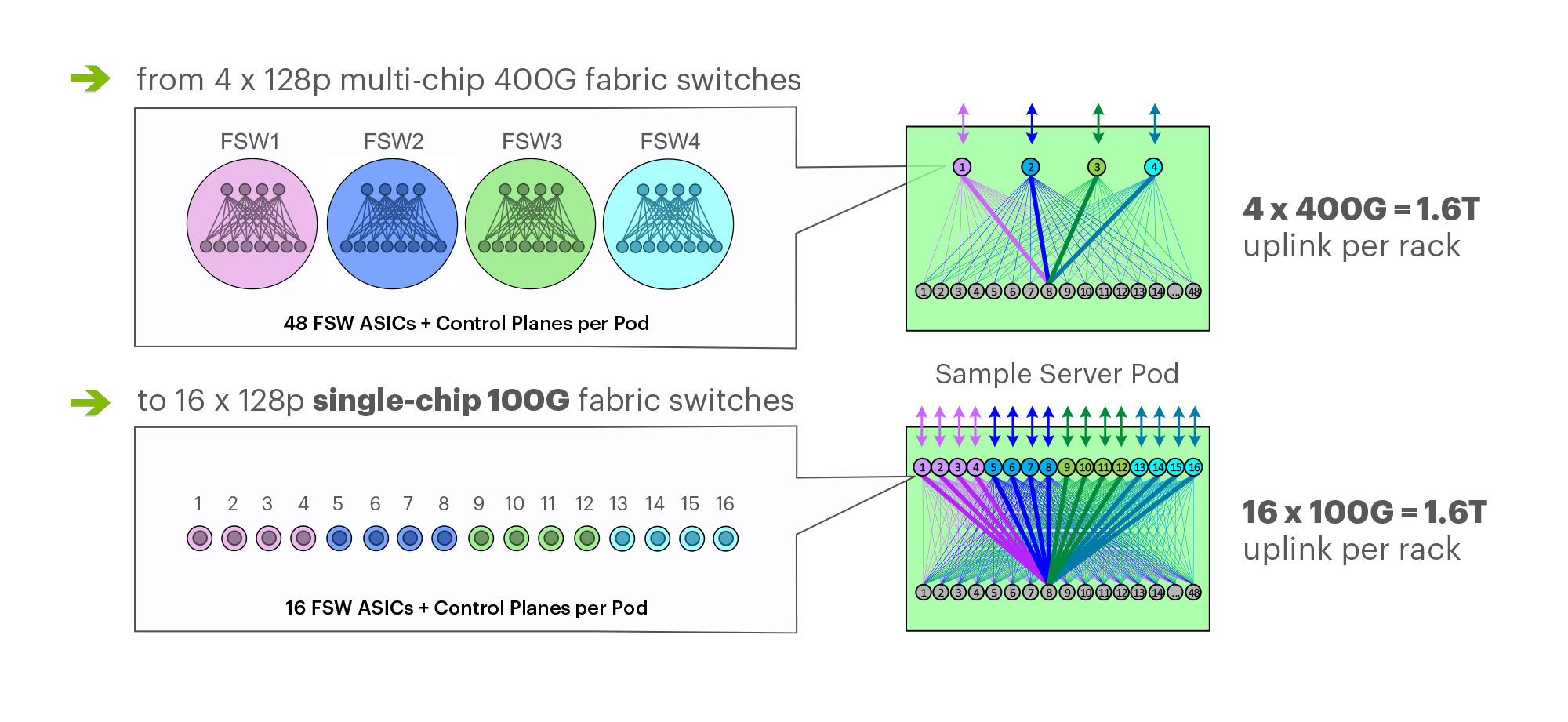
In addition to reducing the number of individually managed sub-switches and the immediate power savings, we also achieve this capacity increase with mature, proven, and readily available CWDM4-OCP 100G optics and our existing Wedge 100S TORs. This setup also gives us a simpler upgrade flow for existing four-plane fabrics and sets us on a more realistic path toward the next improvements with 200G and 400G optics in the future. This setup has a better power-usage profile and is much more feasible than expecting 800G and 1.6T links at mass-production scale soon enough to help us achieve the next 2x to 4x increase.
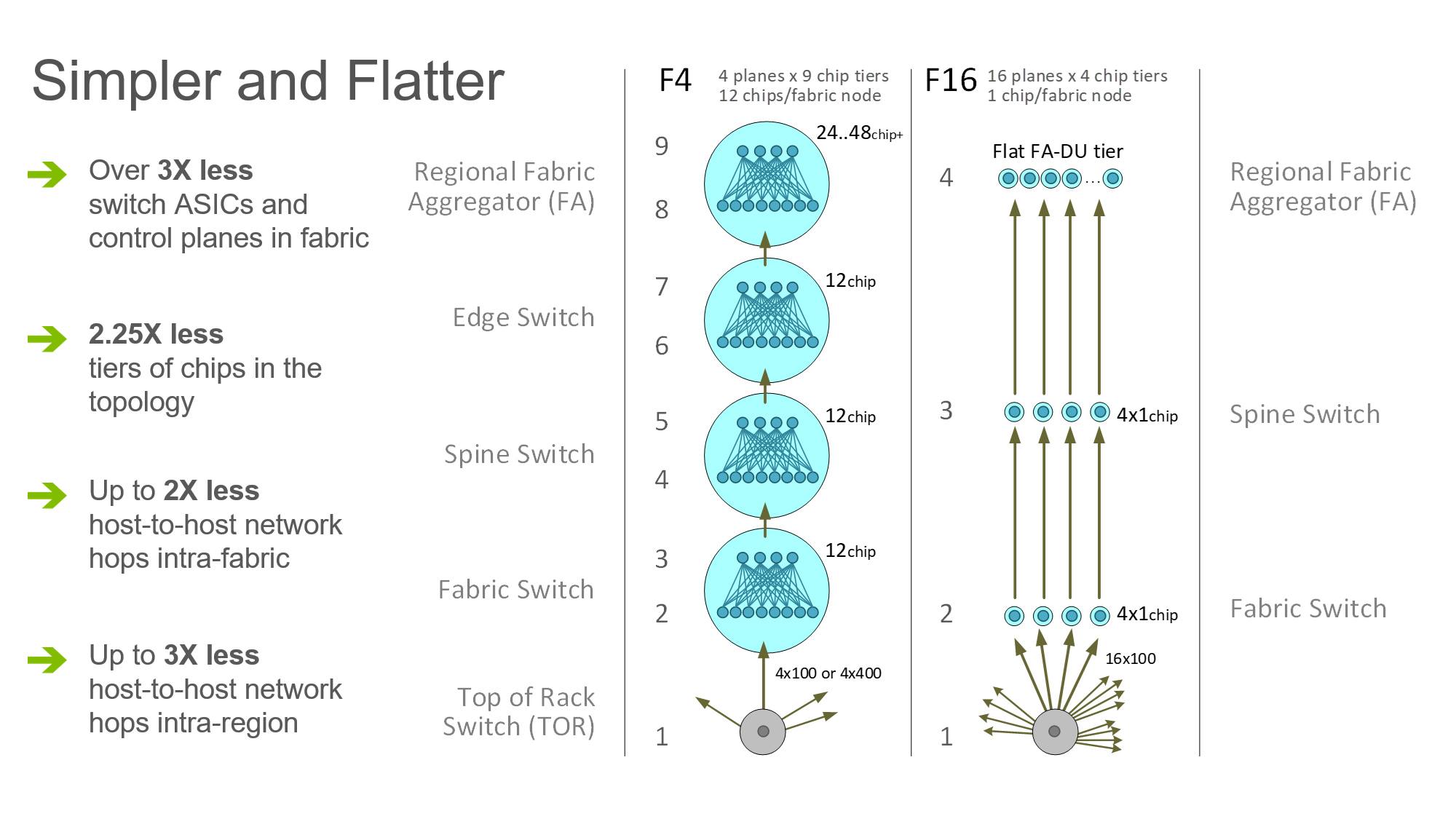
Despite looking large and complex on the schematic diagrams, F16 is actually 2.25 times flatter and simpler than our previous fabric. Counting all intra-node topologies, our original fabric consisted of nine distinct ASIC tiers, from the bottom tier (TOR) to the top of the interbuilding network in the region (Fabric Aggregator). The number of network hops from one rack to another inside a fabric ranged from six hops in the best case to 12 hops in the worst. But with small-radix ASICs, the majority of paths are of the worst-case length, as the probability of hitting the target that shares the same front-panel chip is low in a large, distributed system. Similarly, a path from a rack in one building to a rack in another building over Fabric Aggregator was as many as 24 hops long before. With F16, same-fabric network paths are always the best case of six hops, and building-to-building flows always take eight hops. This results in half the number of intrafabric network hops and one-third the number of interfabric network hops between servers.
Announcing HGRID, our next-generation fabric aggregation
Last year, we announced the Fabric Aggregator, a disaggregated design for connecting the buildings within a region. One of the primary reasons for designing the Fabric Aggregator was that we were already hitting the limits of single large devices that could mesh the fabrics of three buildings in a region. We would certainly be beyond those device limits once we doubled the number of buildings in a region.
Fabric Aggregator gave us experience building a completely disaggregated design that could scale across multiple racks, and the building block at that time was the Wedge 100S. Looking back, the rollout of Fabric Aggregator was a stepping-stone to what we call HGRID. HGRID is a new, even larger aggregation layer between buildings that is able to scale to six buildings in the region, each equipped with a full F16 fabric.
HGRID uses all the same design principles as Fabric Aggregator, but now the building block is Minipack, the new platform that powers our F16 fabrics. As part of the F16 design, we replaced fabric edge pods with direct connectivity between fabric spine switches and HGRID. This change allowed us to further flatten the regional network for East-West traffic and scale the regional uplink bandwidth to petabit levels per fabric. Edge pods served us well during the initial growth phase of fabrics and provided a simple radix normalization and routing handoff to the past full-mesh aggregators. The new disaggregated FA tier, however, removed the need for these interim hops and allowed us to scale the regions in both bandwidth and size.
A new, modular 128x100G building block
Next, we designed the building block switch that is at the core of all these new topologies. When designing both the topologies and the new switches, power reduction was a consideration, as well as flexibility and modularity. We wanted a single switch that would fulfill multiple roles in the data center (fabric, spine, aggregator) and also allow us to easily upgrade the network to faster optics as they become available.

With the advent of 12.8T switch ASICs, we designed Minipack, a 128x100GE switch, with a single 12.8T ASIC, instead of the 12-chip folded Clos fabric that Backpack was built upon. Using a single ASIC already brings significant power savings compared with Backpack. We worked with Edgecore to build Minipack based on our designs.
Modularity
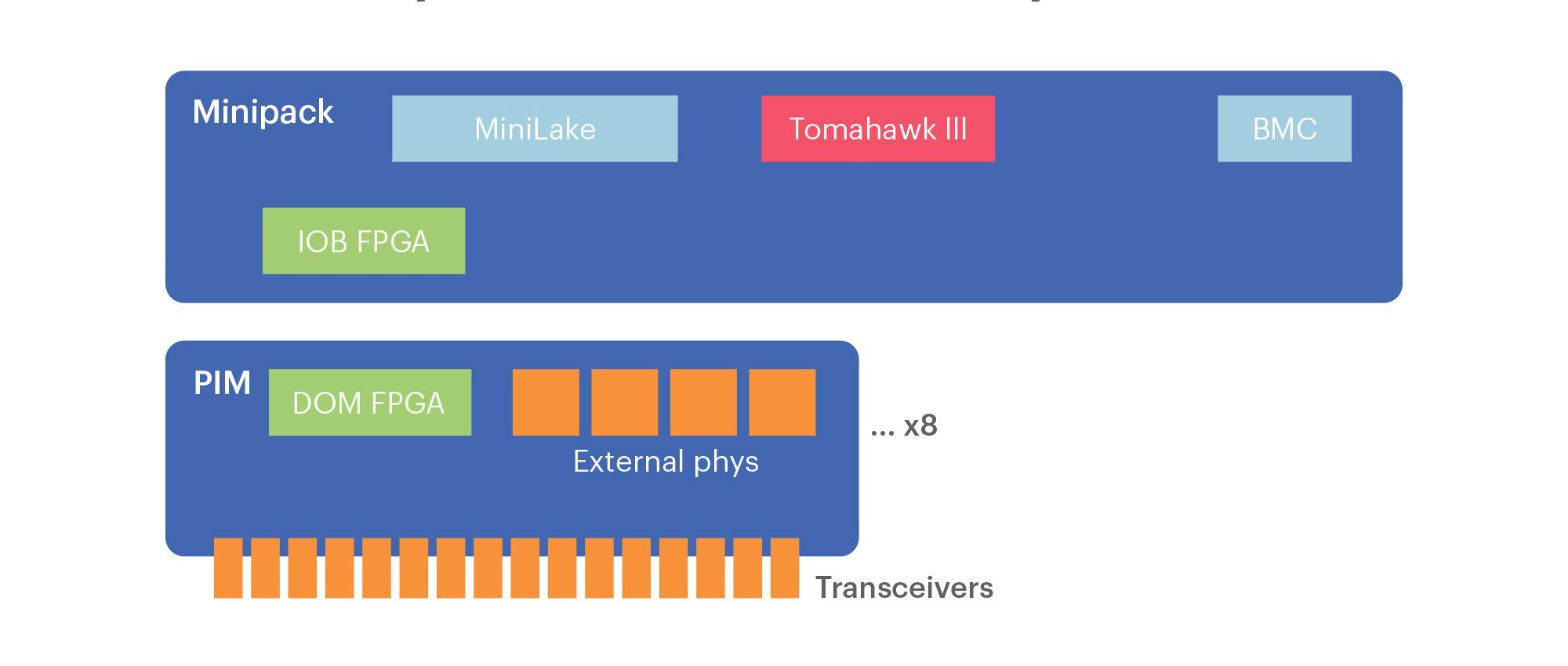
Even though we wanted a single ASIC switch, we still needed the modularity and flexibility that a chassis switch such as Backpack provides. Thus, Minipack has interface modules for the 128 ports instead of a fixed “pizza box” design. This design allows us to have both the simplicity and power savings of a single-ASIC design and the flexibility/modularity of a chassis switch.
We explored different system design options to achieve this modularity. We chose the eight port interface module (PIM) orthogonal-direct architecture because it offers the right granularity to make Minipack deployment more efficient at multiple roles in the F16 network. Each PIM card is vertically oriented in the chassis, and we overcame mechanical challenges to fit 16x100G QSFP28 ports on its front panel. We also came up with a solution to manage and route the fiber with the vertical PIMs. There are 4x reverse gearbox chips on the PIM, called PIM-16Q. When we configure the reverse gearboxes to 200G retimer mode, PIM-16Q can support 8x200G QSFP56 ports. The remaining eight ports will be nonfunctional in the 200G mode. In addition, PIM-16Q is backward compatible to 40G and supports 16x 40G QSFP+ ports. We also designed a 400G PIM called PIM-4DD, and it supports 4x400G QSFP-DD ports. Each PIM-4DD has 4x400G retimer chips. We can mix and match PIM-16Q and PIM-4DD in the same Minipack chassis to have 40G, 100G, 200G, and 400G ports.
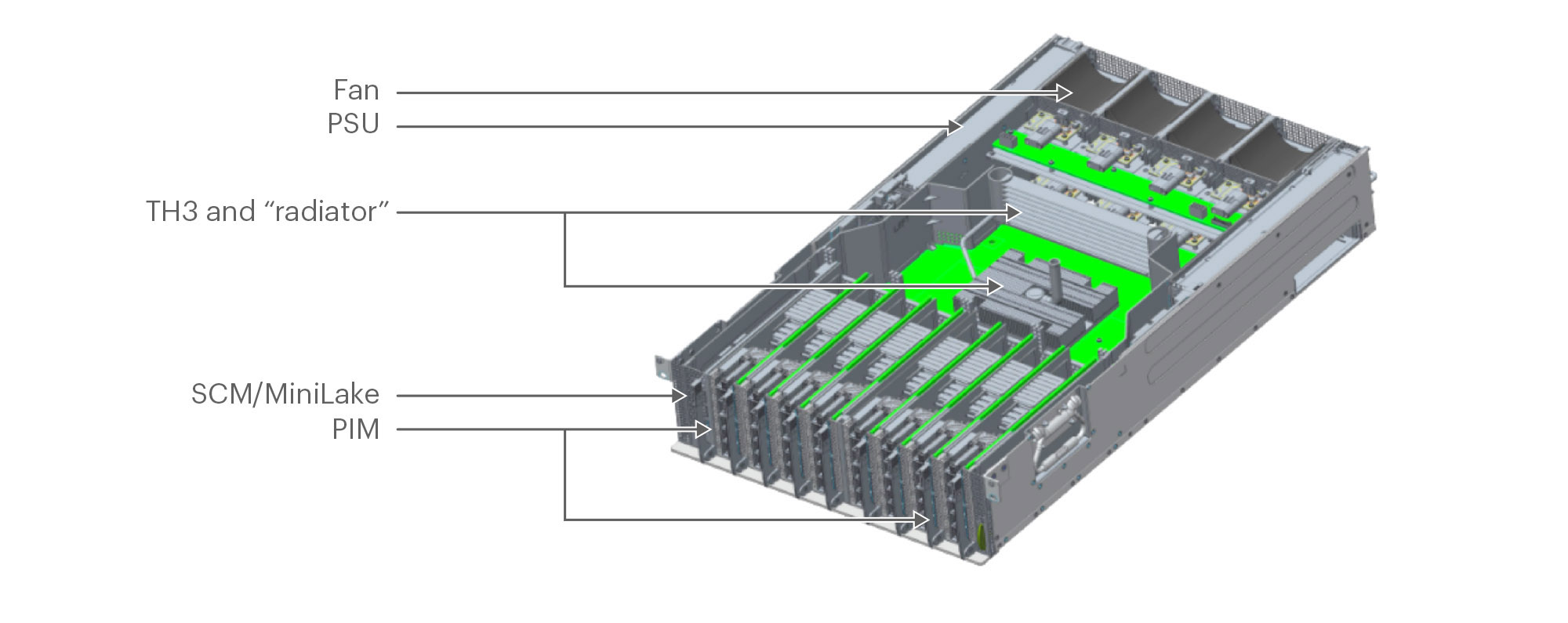
This PIM-port flexibility allows Minipack to support multiple generations of link speeds and data center topologies, and enables the network to upgrade from one speed generation to the next smoothly.
Optics
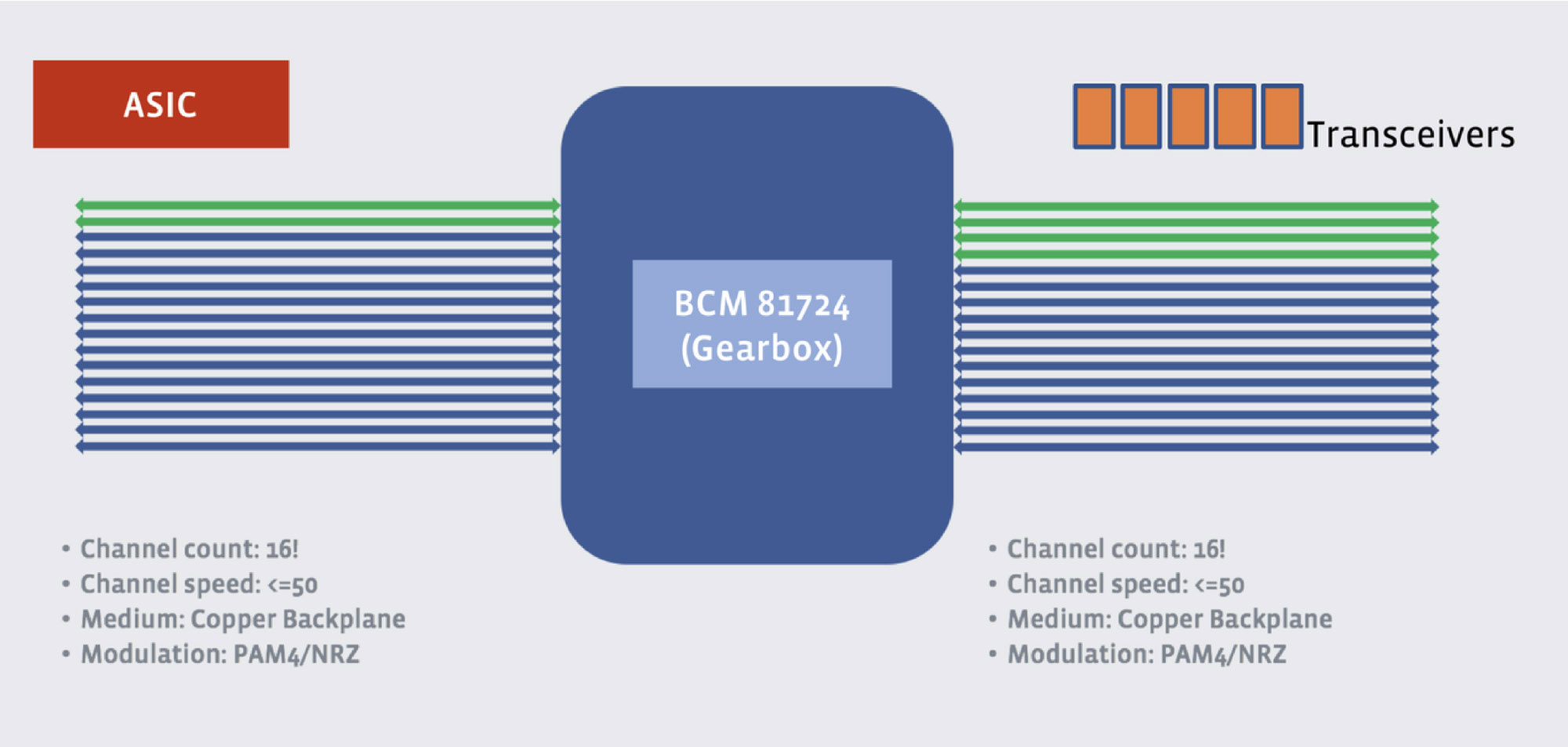
In order to leverage the mature 100G CWDM4-OCP optics, Minipack uses reverse gearboxes. The Broadcom TH3 switch ASIC has 256 lanes of 50G PAM4 SerDes to achieve 12.8T switching bandwidth, whereas the existing 100G CWDM4 optics come with four lanes of 25G NRZ SerDes. We use reverse gearbox chips in between to bridge the gap. There are a total of 32 reverse gearbox chips in Minipack (128x100G configuration), and each processes 4x100G ports.
System design
TH3 sits on the horizontal switch main board (SMB), with a radiatorlike highly efficient heatsink, and the reverse gearboxes are on the vertical PIMs. This architecture opens up the air channel and reduces system impedance for better thermal efficiency. We can use 55-degree Celsius rated 100G CWDM4-Lite optics in Minipack while running the cooling fans at low speeds. The direct connection between SMB and PIM reduces printed circuit board trace lengths and lowers channel insertion loss. FRU-able PIM enables us to explore different interface options such as PIM-16Q and PIM-4DD, and FRU-able SCM (switch control module) improves serviceability when a dual in-line memory module or solid state disk replacement is required.
Unlike previous generations of Facebook switches, Minipack includes digital optics monitoring (DOM) acceleration function. There is one input/output block (IOB) FPGA on SMB and it is connected to the CPU by a peripheral component interconnect express (PCIe) link. The IOB FPGA talks to a DOM FPGA on each PIM through a local bus. DOM FPGA periodically polls the optics modules for DOM information through the low-speed I2C buses, and the CPU only needs to read such information from the FPGAs through the high-speed PCIe link (and avoids doing direct I2C bus accesses).
MiniLake: Control for Minipack
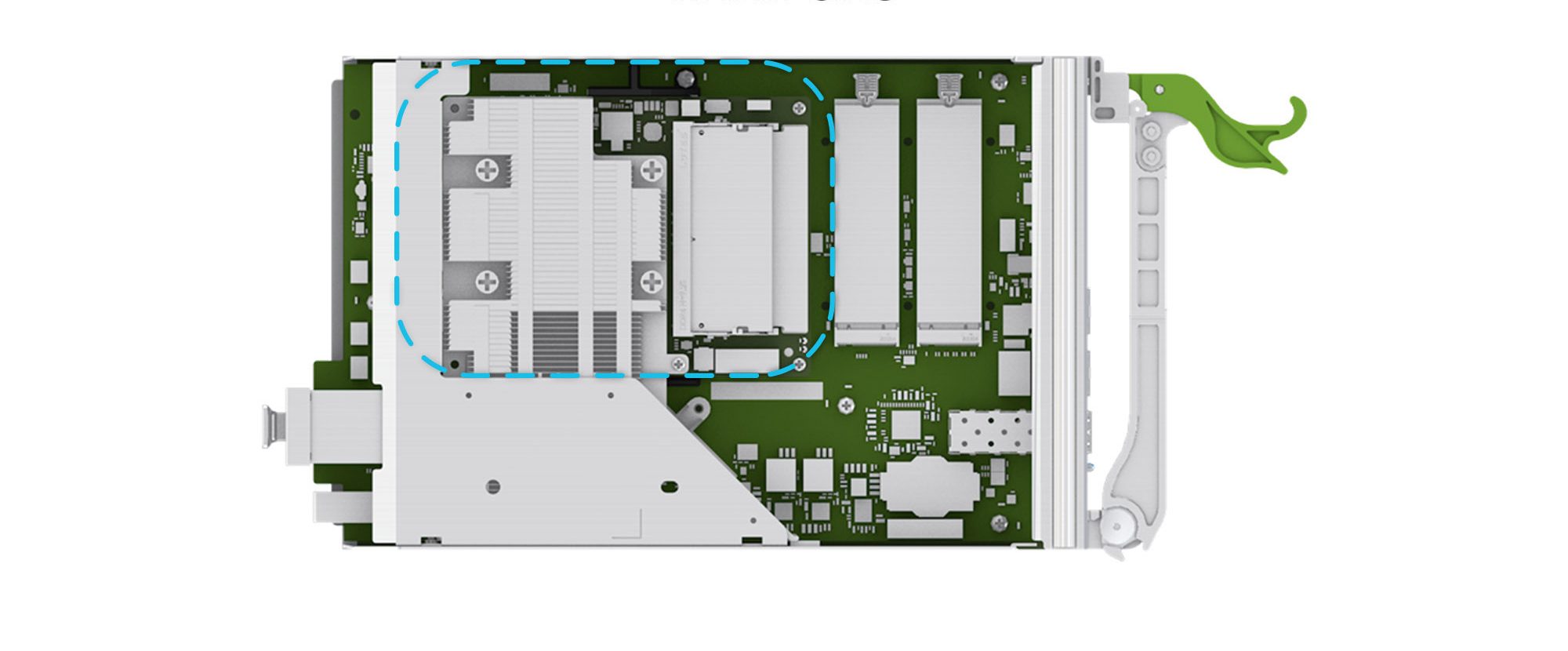
For the control plane of Minipack, we custom-designed a microserver called MiniLake. It is based on the COM Express basic form factor and Type-7 pinout, which fit the switch application well. One of our guiding principles is to manage the switches like servers, and MiniLake gives us the same management interface as Mono Lake, a one-socket workhorse in our server fleet.
We have contributed the full design package of Minipack + MiniLake to OCP, including the system hardware specification, all the electrical design files, all the mechanical design files, and programming images. They are now fully open to the OCP community. Softwarewise, we use FBOSS on Minipack, but for the external community, different software stacks have been ported to Minipack, including commercial software from Cumulus Networks and the SAI/SONIC open source stack from the OCP Networking Project.
The 7368X4: Joint development with Arista Networks
As we designed the F16 and HGRID topologies and envisioned a single-ASIC, 128x100G switch as its building block, we decided to have two sources for this switch. For our second source, we turned to longtime partner Arista Networks, to perform joint development of a switch that met our high-level requirements as covered earlier (power envelope, modularity, manageability, etc.). This was a new partnership for both companies. We at Facebook have historically worked with original design manufacturers such as Edgecore and Celestica for our earlier switches where the design is entirely from Facebook, and Arista has historically designed the switches entirely on its own.

Together, Facebook and Arista jointly designed the Arista 7368X4, and it has all the same benefits of Minipack. We can use the Arista 7368X4 in all the same roles as Minipack in our topologies. For deployment simplicity, we have conventions for which switch is used in which role in a particular data center. We can run our FBOSS software on the Arista 7368X4, but the switch also runs EOS.
The joint development model brought us several benefits:
- We had a second source for a second design with some amount of separation on the underlying components to provide redundancy in the supply chain.
- We were able to leverage Arista’s team for more of the engineering development in parallel, especially with respect to the primary ASIC (where we were both working on it in parallel), as well as the modular PIM design and the external PHY programming (even though we used different gearboxes).
- It was useful to have another NOS like EOS running on the switch, as it helped us decide early on whether a particular issue was specific to FBOSS or specific to a particular platform. We believe the ability to run EOS or open source software on this switch will be valuable to network operators. It gives them the option to have open switch but still want to run familiar commercial software such as EOS if desired.
Finally, Arista is contributing the specification for its Arista 7368X4 switch to the OCP networking project. Arista has been participating within OCP Networking already, through working with the SAI/SONIC project with some of its other switches and through its recent acquisition of Mojo Networks. The contribution of the 7368X4 specification represents a significant and logical next step for established original equipment manufacturers such as Arista to embrace the open and disaggregated networking espoused by the OCP Networking Project.
FBOSS: The unifying software
Meeting the software challenges
We’ve covered the brand-new topologies, F16 and HGRID, and the new modular building block switches, Facebook Minipack and the Arista 7368X4, all of which were conceived and developed in record time to meet Facebook’s needs. On the software side, the FBOSS software needed to handle the new networks and platforms along with our large fleet of production switches. Our efforts spanned the entire stack of on-switch software — OpenBMC support for two new hardware platforms, support for modularity within a single control plane via our swappable PIM design, complex port programming at different speeds, two new microservers, brand-new I2C, MDIO, and FPGA work, and the first platforms to support external PHY chips.
Some challenges were specific to our joint development of the Arista 7368X4. In addition to being another platform, it was the first time we were running FBOSS on non-Facebook-designed hardware. This meant working closely with Arista to design the hardware to satisfy FBOSS architecture, such as adding BMC SoC to Arista 7368X4. We also revisited some assumptions FBOSS always had, including UEFI BIOS support (not available on Arista) and the conversion between Arista EOS and FBOSS on the switches.
While the normal tendency might be to go slower on the software side given the larger and more challenging scope, we instead went back to the principles that have led us to develop FBOSS and to iterate quickly for the past five years:
- Stay focused on the precise requirements of the new topologies and the new hardware.
- Maintain our single-image, continuous-deployment philosophy by greatly expanding our simulation, emulation, and general testing capabilities.
- Stay involved in DC network deployment and operations, including the constant rollout of the new topologies and hardware, migrations, and troubleshooting.
Applying the same principles we used when we operated a single platform and tier to this massive scale was not easy. This work involved several initiatives:
- Building proper software abstractions to hide hardware differences at many levels.
- Validating the vast number of hardware-software tier combinations through more powerful automated tests and frequent deployment.
- Scaling our higher layer control software for routing to handle all DC tiers — fabric, spine, and Fabric Aggregator.
We’ll focus on #1 and #2 below.
Developing more hardware abstractions
Our software stack consists of several layers:
- OpenBMC for the board-system level management software.
- CentOS as the underlying Linux OS; it has the same kernel and OS that we run throughout the Facebook server fleet.
- FBOSS as the set of applications that program the control plane and data plane.
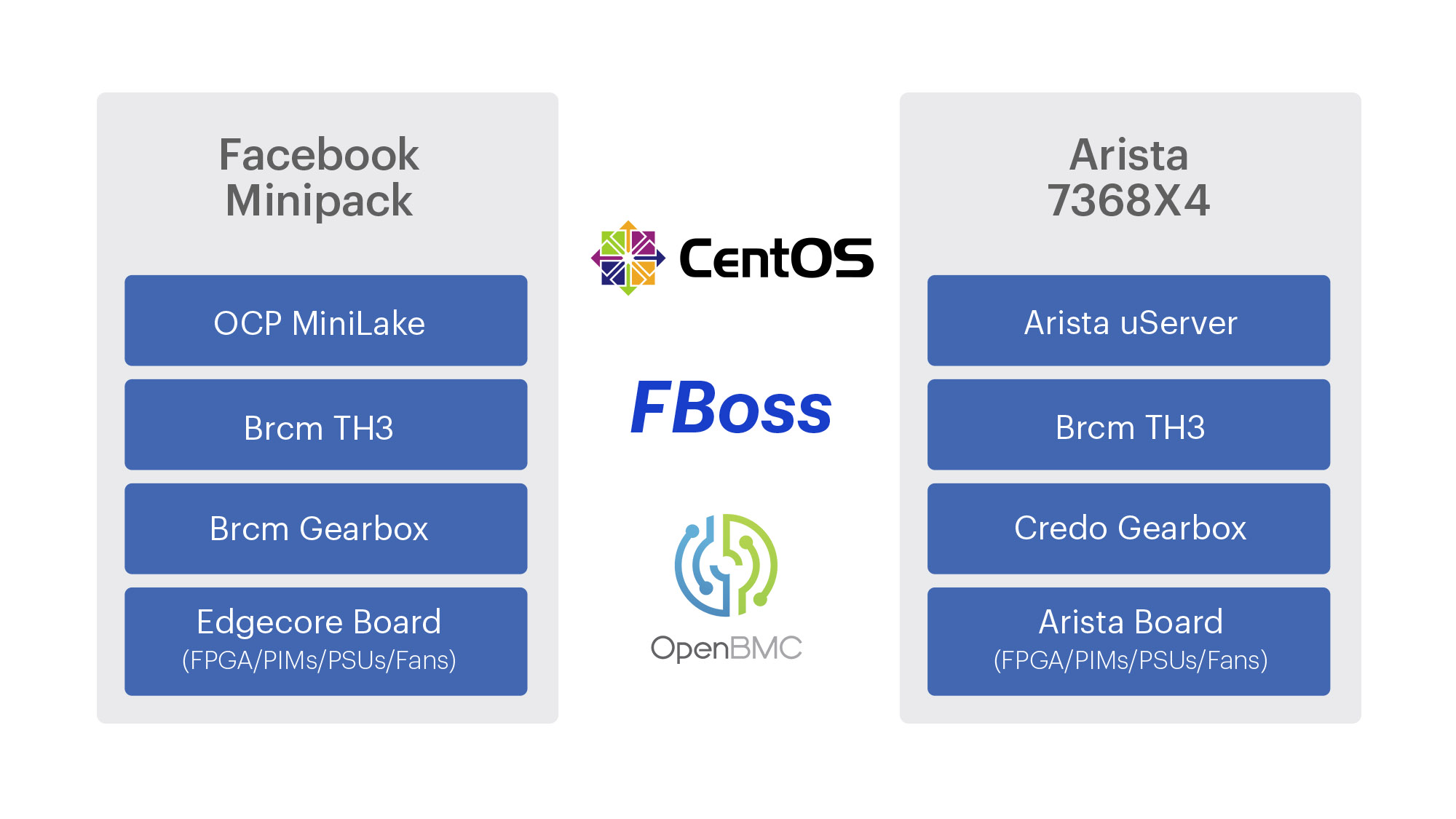
We wanted to run these same three components on both of our new platforms, as well as our large fleet of already deployed Wedge 40, Wedge 100, and Backpack switches. There were already several abstraction layers in FBOSS, but they had to be reworked or extended to handle the new Minipack and Arista 7368X4 platforms. We’ll go through examples of a few of these modifications.
Handling the new hardware and bootloader
FBOSS handles hardware platform differences through the BMC SoC and OpenBMC. The Arista team added the BMC SoC to the 7368X4, with support of two operational modes. In Arista EOS mode, the microserver controls the fans, power, and other on-board components. But when we run with FBOSS, we expect the BMC to perform those environmental and board management functions, consistent with how we manage our server fleet. With design to support both operation modes, we are able to reuse and extend our existing OpenBMC stack to support the new hardware platform.
Facebook Minipack had the new MiniLake control module, which wasn’t too large of a departure from a software perspective from our existing microserver design. MiniLake provides a UEFI BIOS with v6 PXE function. With that interface, getting an image onto Minipack was fairly straightforward. We were thankful for the 32G of RAM on MiniLake, as it makes it easier for us to leverage the general Facebook software development infrastructure and software services.
The Arista 7368X4 had a different microserver, but more important, Arista has historically used a custom coreboot implementation rather than an off-the-shelf UEFI BIOS, unlike typical Facebook servers. To meet this challenge, we decided to align with the OCP Open System Firmware program. We had been wanting to try this initiative, so we engaged with Arista and now have a solution based on coreboot, u-root, and LinuxBoot to handle the microserver imaging.
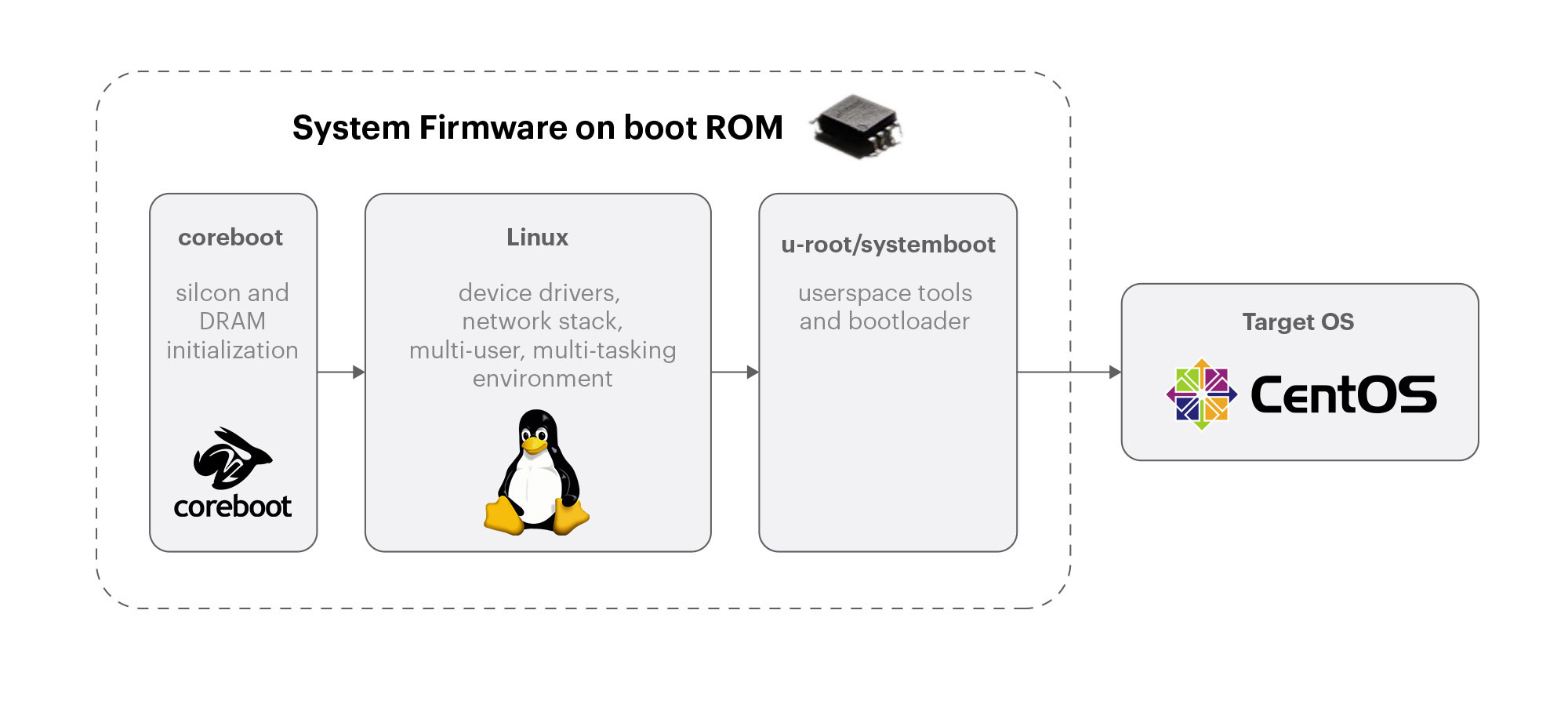
With the flexibility of this hardware, we also had to make sure to automate the conversion process between Arista EOS and FBOSS on the 7368X4 platform. The 7368X4 ships with EOS by default. If a 7368X4 needs to be converted to run FBOSS in a particular deployment, a conversion process is triggered automatically. We regularly test the conversion back and forth to ensure there are no regressions.
Bringing up a port
We are used to simple interfaces for port management, where we can easily enable or change the speed of any port on the platform. Minipack’s modular design, with separate PIMs and external PHYs made this much more involved and infrastructure had to be put in place under the hood to perform the high-level task of “bringing up a port”:
- Communicating with the transceivers. Our transceiver management software runs on the microserver, and past platforms had a single I2C bus connecting the microserver to the transceivers. In the Minipack design, that would mean one I2C bus to 128 devices, which was not going to scale.
To address that problem, we created a custom FPGA implementation to accelerate I2C. It included some relatively standard I2C controller blocks, but it also had a more complicated procedure to background-fetch and cache the data pages of interest on the transceivers, ensuring maximal freshness of the data to track light levels, temperature, and other fields of interest. Thanks to the Minipack’s space-efficient design, we were able to squeeze 128 transceivers into only 4 RU. So we designed sophisticated fan control algorithms to cool the chassis. Specifically, we wanted to factor transceiver temperature into the fan control algorithm run on the BMC. This cache implementation provided a way to efficiently have both the BMC and microserver access transceiver DOM data, like the temperature and power usage, without contending for I2C resources. - Communicating with the external PHYs. These speak MDIO instead of I2C, so we utilized MDIO controllers in the FPGAs to speak to the chips. We needed to write an MDIO interface that can fit into our C++ codebase and into the chip SDKs, as well as an implementation to utilize the FPGA. We had to do all of this for both the Minipack and the Arista 7368X4 separately, as they had different FPGAs and gearboxes.
- Programming the external PHYs. Now that we can communicate with PHYs, we could program them to provide the flexibility we wanted. For example, the primary configuration we wanted to support was to take two channels on the ASIC side of the gearbox, run them at 50G PAM4, and then translate the signal in the gearbox to four 25G NRZ channels, thereby creating a 100G port to the transceivers. We also had to support 40G, wherein we would go from 2x20G to 4x10G. Looking ahead, 200G is supportable by mapping four channels on the ASIC side directly to four channels on the line side, but then we cannot use the neighboring port.
Expanding continuous test capabilities
We expanded our test infrastructure to support all the new platforms and topology deployment combinations. Our overall test strategy has three components: (1) Realistic or full life-cycle lab environments, (2) test automation, and (3) early deployment.
We greatly expanded the lab environment to handle the tremendous size of the F16 fabric network. Although we couldn’t create a full F16 in the lab, we kept the policy as similar as possible, leveraging parallel links to test more involved features such as traffic hashing (an area that had bitten us before). We also added all three different role-platform-software combinations we were planning to deploy. We used tools to simulate additional peers and generate large scales. Finally, we ensured our lab environments are able to securely work production management systems so we can test the full life cycle of software.
In terms of test automation, we introduced two additions to the test infrastructure during the course of F16-Minipack development. Both of these will allow us to onboard new platforms in the future significantly faster:
- ASIC-level testing. As one of the lowest layers of the software stack, this was traditionally not as automated as we would have hoped. Before, we had limited the deployment of a new ASIC into only one tier to reduce exposure and the testing burden. But given the new ASIC had to work at three different tiers from day 1, we prioritized automating ASIC-level testing.
- On-diff testing. We have always pushed for continual test and deployment, effectively running complete test suites on every software change (a “diff”) that a developer introduces. We started adopting this on-diff philosophy in FBOSS and leveraging Facebook’s as it was becoming harder for individual developers to predict the ripple effect of their changes throughout all the deployment combinations.
Finally, we continued to embrace our philosophy of early deployment and iteration (covered more extensively in our SIGCOMM 2018 paper on FBOSS). In fact, we had Minipacks serving production traffic before we had even exited DVT of the project, and most weeks we were performing a new Minipack or 7368X4 deployment somewhere in our data center networks. Facebook software as a whole sets the philosophy of getting into production as quickly as possible, staying in production, and then continuously iterating. In our networks, this philosophy allows us to discover issues in both the on-switch software and the network-level tooling and monitoring needed to deploy at scale. In the end, we are developing a complete, ready-to-deploy switching system — not just a hardware/software platform.
Conclusion
F16 and HGRID are the topologies, and Minipack and the Arista 7368X4 are the platforms that are the core of our new data center network. They all bring significant improvements in power and space efficiency and reduce complexity in the overall network design, while building upon readily available, mature 100G optics. This new network will help us keep up with increasing application and service demands. We believe in working with the OCP community and networking ecosystem as a whole, so we have shared an overview of our network design in this blog and the complete design package for Minipack via OCP. Arista has also shared the specification from our joint development work with OCP.
Looking ahead, we believe the flexibility of the F16 topology and modular switch design will help us leverage faster ASICs and optics as they become available over the next few years. We will continue to leverage this modular switch design as a pattern in designing future networking platforms.
Thanks to the teams and industry partners that helped make these new topologies and platforms possible.








