
Over the past several years, model capabilities and training dataset sizes have experienced exponential growth. During the past year or so, the time between new-frontier-model releases has gone down from months to weeks. Reliable and fast access to storage is important to both the speed and computational cost of this AI innovation. If AI is the brain, storage is the memory: Capability and speed are highly dependent on the size of memory and speed of retrieval.
Yet while AI compute performance has roughly tripled every two years, storage and interconnect performance growth have been more modest. As a result, storage bottlenecks continue to be one of the primary contributors to GPU stalls for AI workloads, directly impacting expenditures and time to market. Aside from GPU utilization, storage architecture also directly impacts the speed of iteration in AI research; with GPUs increasingly becoming geo-distributed and dataset sizes increasingly becoming massive, researchers spend a significant amount of time ingesting and moving data across regions, thus impacting research velocity. In this blog post, we discuss how Meta’s BLOB-storage architecture evolved to address two primary challenges: maximizing GPU utilization and maximizing research velocity.
Storage Architecture Overview
Meta operates hundreds of exabyte-scale storage clusters that serve all of Meta’s external and internal products, including Facebook, Instagram, Reality Labs, Meta AI, Ads, Data Warehouse, and internal Databases. Our storage service exposes object storage, file systems, and block-device APIs, and these API abstractions are built on top of a horizontally scalable foundational block layer called Tectonic. The Tectonic layer is a regional, multi-tenant storage fabric that provides high durability and availability leveraging erasure-coding techniques, supports tiering across media types (e.g., HDD and flash), and manages smart placement of hot, cold, and warm data for efficient utilization of I/O across tenants. The BLOB-storage layers that operate on top of Tectonic expose a global, infinitely scalable storage fabric, and expose policies that let users make tradeoffs between durability and availability.
In a previous @Scale talk titled, “Training Llama: A Storage Perspective,” we discussed how Meta trained Llama directly over the Tectonic block layer by exposing an NFS-like FileSystem interface on top of it. While this architecture continues to be used widely within Meta, our modern training stack has been migrating slowly on top of the BLOB-storage interface, as is the case across the industry. This transition is motivated by the need for unified storage access to massive data lakes in the BLOB-storage layer as well as the need for high performance.
Maximizing GPU Utilization
Modern AI workloads are “data hungry” and have very different workload characteristics than traditional web applications: bursty and sustained high throughput, predictable and bounded pMax latencies, and variable I/O patterns. The focus for BLOB storage, in recent years, has largely shifted to maximizing GPU utilization.
Why Latency Matters
To see why bounded and low-pMax latencies are important, let’s consider model training. During that training, hundreds of thousands of GPUs iterate over vast amounts of data in storage multiple times (i.e., over multiple epochs), and the GPUs train datasets in batches. Periodically, after every certain number of steps or batches, the GPUs synchronize their state among themselves. If one GPU is slow, this step will slow down all GPUs as well as the entire training.
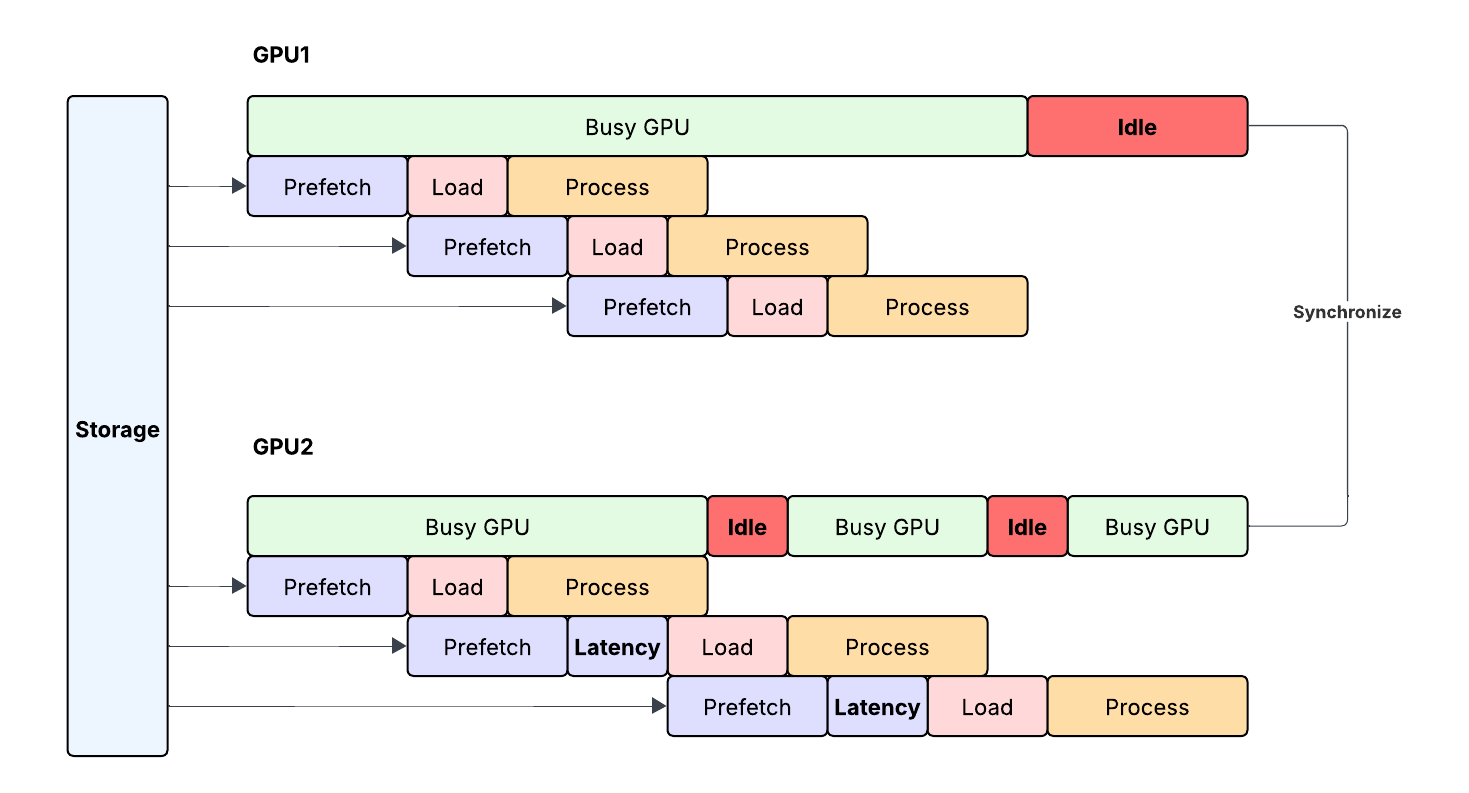
Figure 1 shows a data-loading pipeline across two GPUs. The dataloader in every GPU host prefetches the next dataset batch, while the GPU is processing the current batch for maximum compute or I/O overlap. In the case of GPU1, the storage-fetch latency is well within bounds, so the GPU is never stalled waiting on I/O. In the case of GPU2, there are two instances where storage fetch exhibits high latency, stalling GPU. As a result of these stalls, the overall step-completion time is delayed.
Legacy BLOB-Storage Architecture Wasn’t AI-Ready
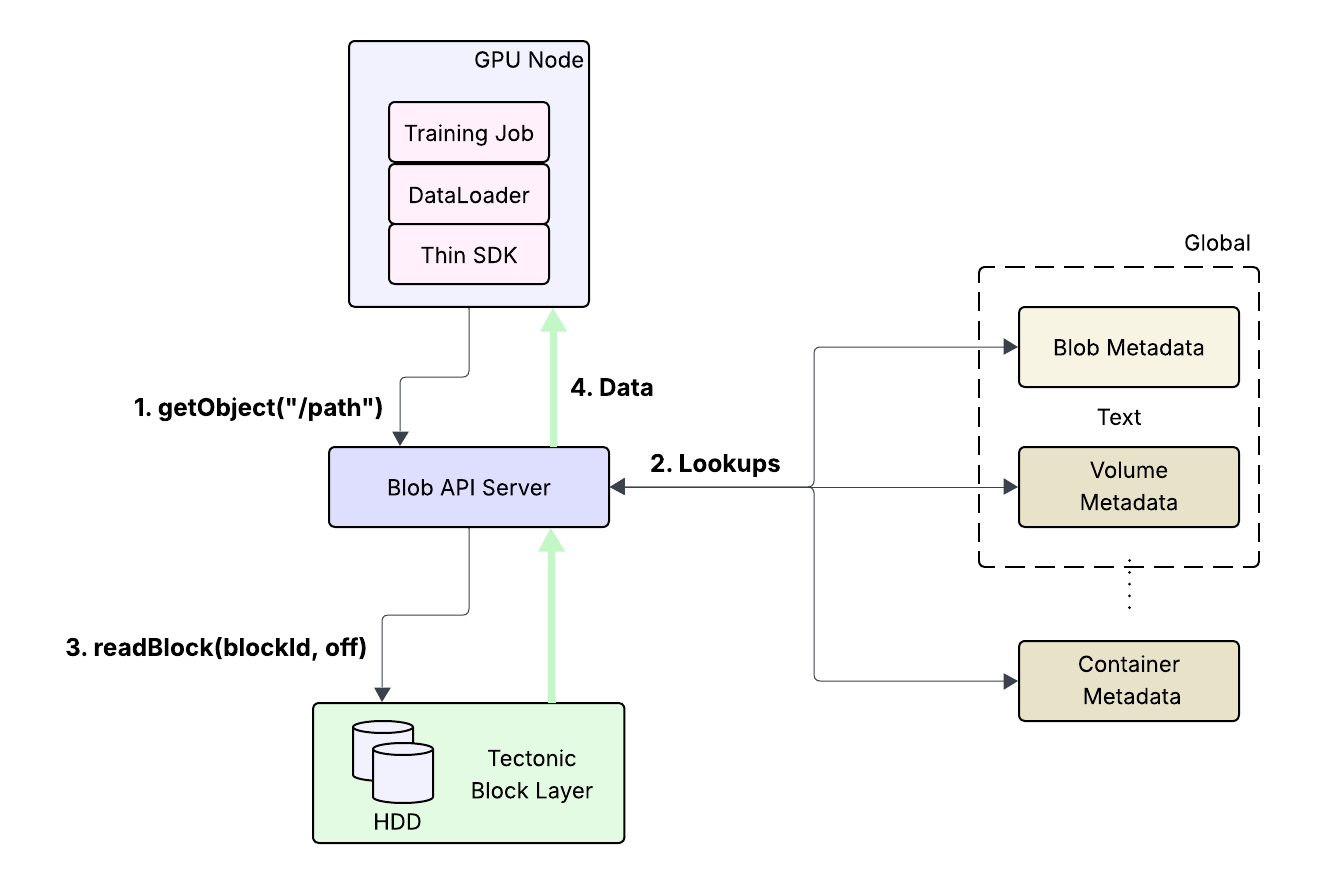
Over the years, BLOB storage evolved organically, adding layers on top of layers in a true service-oriented fashion. Many of these layers were stateful and maintained their own metadata stores. While these metadata-access latencies typically weren’t the bottleneck for the traditional use cases served by global HDDs, they were showstoppers for AI workloads with millisecond access to data in flash. Figure 2 shows the request flow for a typical getObject(“/bucket/path”) API. After the request arrives at the API server, the server does many metadata lookups across the namelayer, volumeslayer, and containerlayer before resolving the path to a set of (blockId, offset, size) tuples. Some of these lookups can cross regions, and it’s not uncommon for latencies to add up to hundreds of milliseconds; one slow response from any of the lookups was sufficient. After the lookups, the API server proxies the data from the Tectonic layer to the client.
While this architecture served conventional workloads well, the foundational assumptions that dictated design tradeoffs have since shifted. Some of these are:
- Performance and latency: As discussed, while latency needs for conventional workloads were modest, AI workloads demand predictable and bounded latencies all the way up to pMax.
- Reliability and durability: The legacy architecture was designed to be highly durable and available, even in the face of region outages; data and metadata were globally replicated by default. While AI workloads demand very high availability, the global-by-default design choice no longer holds.
- Cost efficiency: Legacy stack was built on top of HDDs and highly optimized for cost per byte. The IOPS demands for AI workloads necessitate flash, and in addition, the computational cost of storage becomes negligible relative to the computational cost of GPUs.
- Power efficiency: With GPUs, datacenters are increasingly power constrained rather than space constrained. Every kilowatt of power spent on storage is power not spent on GPUs. This is a new constraint with AI workloads.
In short, the tradeoff space has shifted enough for us to rethink the entire architecture.
Rebuilding the Foundation
As we set out to build the new foundation, we made the following major design choices:
- Unified metadata schema: We rewrote the metadata subsystem and collapsed the metadata spread across different layers into one unified and flat schema backed by ZippyDB. This paves the way for O(1) lookup to resolve paths to storage addresses, which is a step-function improvement.
- No dataplane proxy: We eliminated the dataplane proxy and built a fat client SDK that is capable of streaming bytes directly from storage servers to the clients. This helps with power-efficiency goals and also helps achieve higher throughput/lower latency.
- Regional deployment: The BLOB-storage stack is now lean with flexibility to be deployed as a regional or global service. We now deploy a regional BLOB-storage stack colocated with GPUs in every AI region.
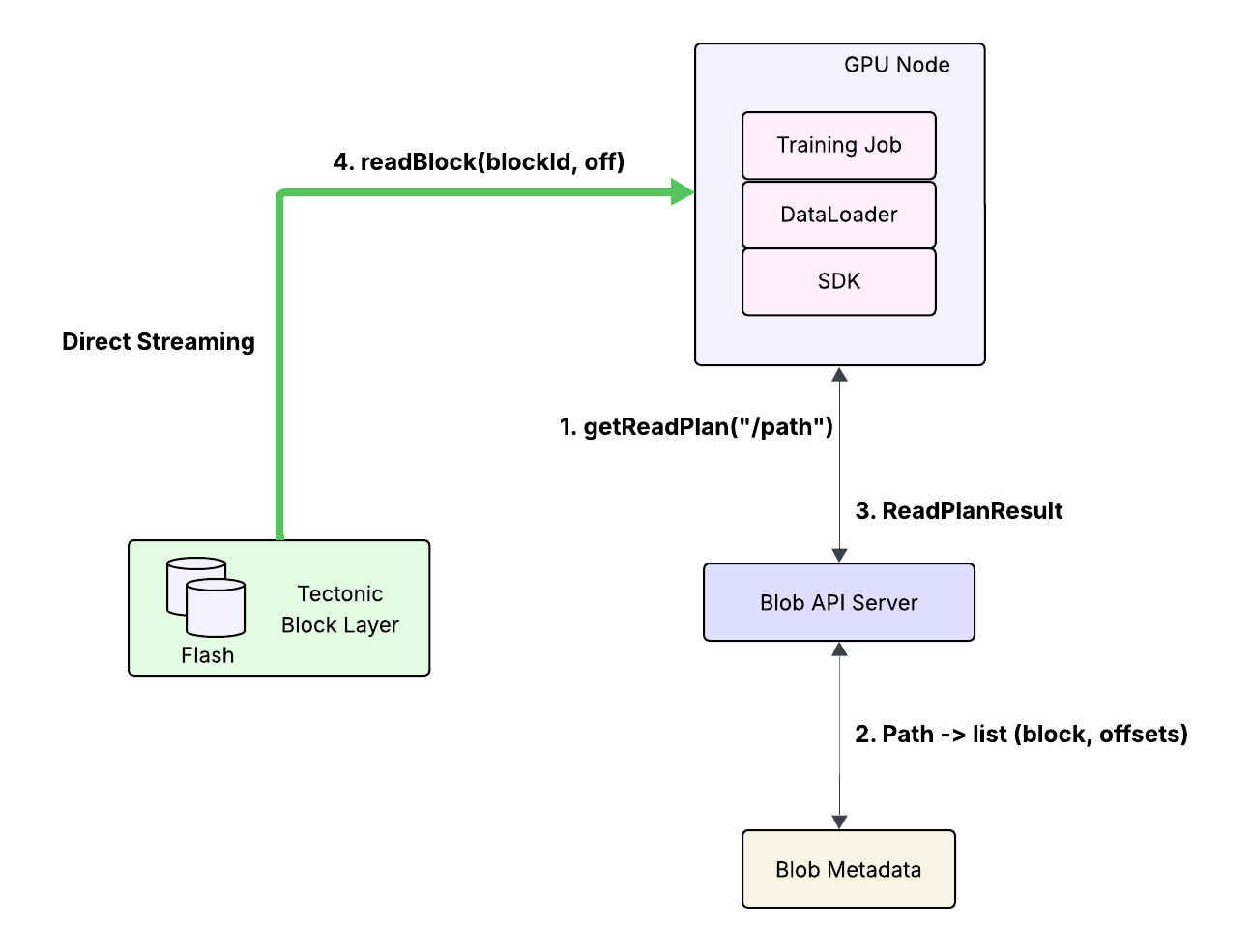
Figure 3 shows the new request flow for getObject(“/bucket/path”). When the SDK on the client receives this API call, it now issues a getReadPlan(“/bucket/path”) request to the API server. The API server does O(1) lookup per chunk to the new metadata store to map the path to (blockId, offset, size) tuples. It then returns the ReadPlanResult to the SDK. The SDK has Tectonic BlockClient embedded within it, and so is now able to stream data from these blocks directly from Tectonic. With these changes, we have rebuilt the foundations and met the goal of adding zero overhead on top of Tectonic. By eliminating the data proxy, we also stay within budget for the power footprint.
Dealing With Spikes and Hot Spots
During data and checkpoint loading, AI workloads are known to access data concurrently across hundreds of GPUs. Subsets of data such as model weights are often “hot,” and events such as GPU restarts trigger sharp traffic spikes. With the foundations now fixed, our next problem was dealing with those spikes and hot spots. Luckily, the BLOB-storage layer has had experience dealing with hot spots over the years, so we adapted existing solutions to AI workloads here. Specifically, we employed two approaches:
- Distributed data cache: We leveraged the spare memory on the GPU hosts as a distributed data cache for frequently and concurrently accessed data. To achieve this, we reused components from Meta’s Owl subsystem: We integrated the peers in the Owl subsystem directly into the BLOB-storage client SDK so that all data access goes through this data cache.
- Readplan metadata cache: Readplan refers to the mapping from path to storage address. We now cache the read-plan for frequently accessed BLOBs in a distributed-memory store similar to memcache.
In practice we observe an average cache hit rate of 80% on the distributed data cache, and the read-plan cache provides 1-2 ms access to metadata. In essence, these simple mechanisms do three things:
- Absorb the spikes and reduce the I/O requirements from storage.
- Solve the problem of metadata hot shards.
- Improve p50 and p99 latencies by serving from memory.
Protocol Optimizations
What we’ve discussed so far got us 80% of the way. We achieved the remaining 20% by identifying and fixing bottlenecks across the stack. Below are some noteworthy problems, though not an exhaustive list by any means:
- Laggards: One slow storage node contributing to tail latencies. This is a well-understood problem, and we resorted to hedged reads on the client side to mitigate this.
- Egress spikes: During checkpoint events, it is common for the client to create sharp egress spikes. This in turn can cause congestion, timeouts, and retries, eventually stalling GPUs. We resolved this by building dynamic concurrency control on the client SDK to automatically tune parallelism based on application-level congestion signals.
With all of the above, the new BLOB-storage stack is now capable of serving AI workloads without causing GPU stalls, adding negligible overhead on top of the Tectonic layer. Our next focus shifted to research.
Maximizing Research Velocity
GPUs are scarce and increasingly becoming geo-distributed; at the same time, training workloads need data colocated with GPUs for performance reasons. This creates an interesting challenge for researchers: They are now on the hook for ingesting and moving datasets across regions.
At Meta, a typical training-job submission involves the following:
- A researcher curates data from various sources, enriches them and persists them in BLOB storage.
- The researcher picks a region where they want to run the job.
- The researcher submits a data-ingestion job, which creates a snapshot of the training datasets onto the target region in a file format optimized for data loading from within the GPU host.
- The researcher then waits for ingestion to finish; depending on the dataset size, that can take hours.
- The researcher submits their training job and monitors their run.
- The researcher analyzes outputs, tweaks datasets, and iterates again, starting with Step 3.
Steps 2 through 4 can take hours and directly impact the speed of iteration for researchers. Ideally, we like our researchers’ time to be spent on tuning models, not waiting for storage. Currently, researchers copy snapshots before starting their jobs to colocate data with GPUs, which results in the most optimal performance. While this optimization for performance makes sense for large-scale training jobs that span weeks or months, the vast majority of jobs are much smaller; the researchers owning these jobs are more than willing to trade off occasional performance degradation for iteration speed.
And so, we needed a system where researchers are able to ingest data once and access data anywhere without thinking about regional boundaries. We needed a workflow that allows researchers to iterate in minutes and not hours. As we went back to the drawing board, the write-once, read-many characteristic of these datasets rang a bell. What if we think of storage as a disk in a planet-scale computer and borrow ideas from the operating-system world? When a Linux process running on a CPU core attempts to read a file from disk, the operating system transparently hydrates data on demand across the various layers of the cache—page cache in memory and L2 and L1 CPU caches. This intuition led to the architectural evolution in Figure 4:
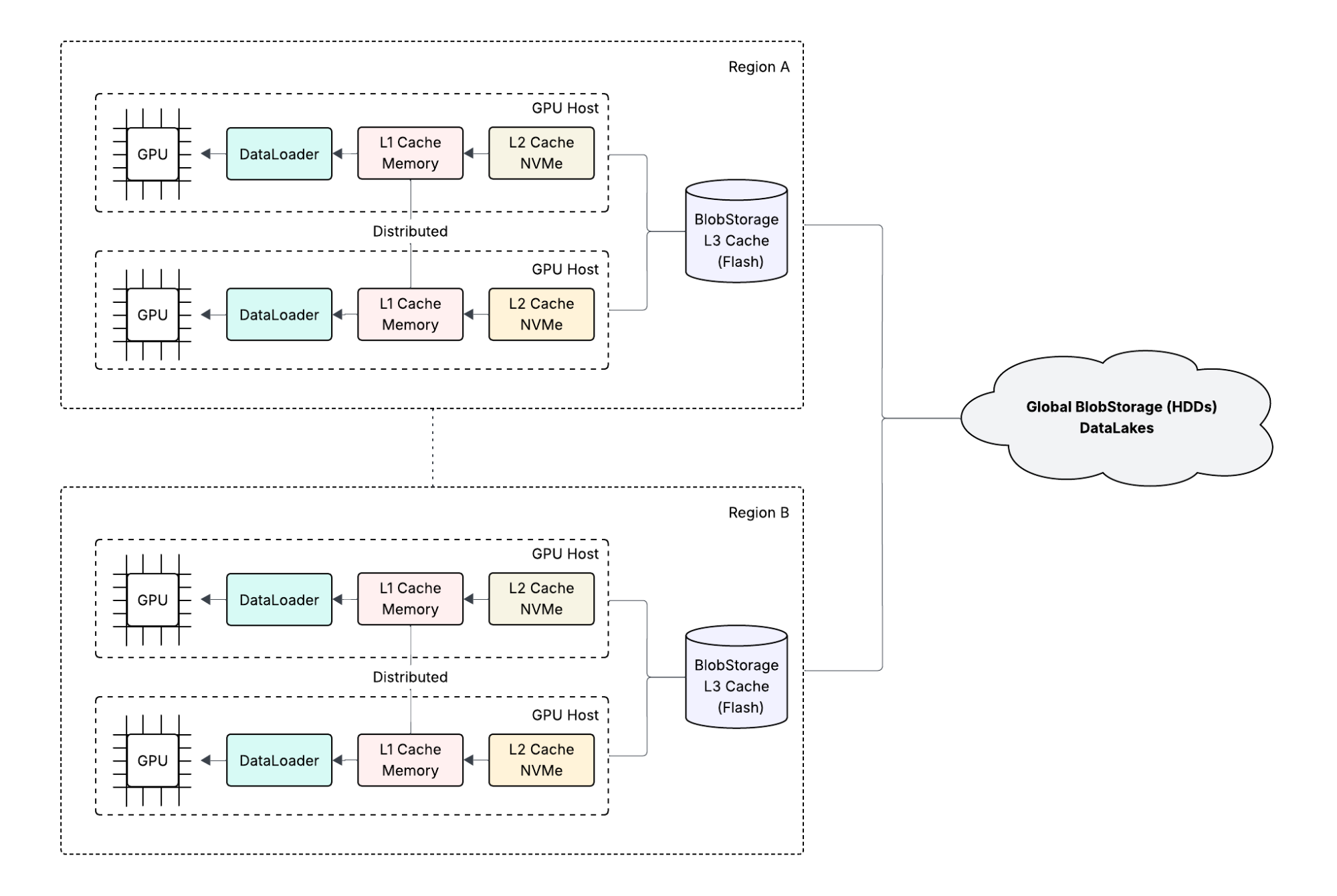
The core idea is to leverage the various on-host and off-host storage resources as a tiered cache with global BLOB-storage fabric backed by HDDs as the ultimate source of truth. Specifically, we leverage the memory and flash on the GPU host as L1 and L2 caches. And we leverage the regional BLOB-storage fabric backed by flash as the L3 cache dataloader continues to access storage through the familiar BLOB-storage SDK. To effectively hide latencies and to simplify the data life cycle, we rely on the following:
- Dataloader prefetch: Dataloaders prefetch the next batch of datasets into memory while processing the current batch. This prefetch will surface as a read operation at the BLOB-storage SDK level.
- Deep prefetch: We expose an explicit prefetch() API as part of the BLOB-storage SDK. The dataloader will trigger explicit prefetch of the data needed during the next few minutes by invoking the prefetch() API in the background. This API triggers hydration of data from remote storage onto the local region L3 cache and also prewarms the metadata cache.
- Automatic data life cycle: Data in the L3 regional disaggregated flash tier is typically held for a configured period of time to allow reuse across epochs in a training cycle. We support custom eviction policies, including TTL and LRU policies. The eviction policies are also capacity/quota aware.
We saw rapid adoption of this new data-loading paradigm as soon as production rollout started, and we continue to support both of the data-loading paradigms in production today. To illustrate the impact in numbers, Figure 5 shows roughly the ingestion times before and after the rollout across all workloads:

In a world where new frontier models get released in weeks, this shift in the data-loading paradigm is a much-needed change to move even faster.
Key Takeaways
Modern AI workloads are data hungry, and storage plays an important role in both the computational cost and speed of innovation. Storage bottlenecks directly impact GPU utilization and computational cost, and in a world with geo-distributed GPUs, time spent on cross-region data ingestion directly impacts the speed of iteration in research. The BLOB-storage architecture at Meta was built to serve Meta’s family of apps, and we needed a step-function improvement in performance to serve AI workloads. This led to rethinking the entire architecture. By rebuilding the metadata subsystem and by adopting a tiered caching architecture with prefetching/on-demand hydration, we are able to meet the needs of today’s workloads effectively.
Future Work
We are continuously evolving storage at Meta to keep up with hardware evolution and workload demands. Some future work in this area will include:
- Scaling storage to network limits.
- Supporting checkpointing without stalling GPUs at even higher scale.
- New challenges for inference workloads, which we are starting to tackle.








