This is the second post in the Ranking Engineer Agent blog series exploring the autonomous AI capabilities accelerating Meta’s Ads Ranking innovation. The previous post introduced Ranking Engineer Agent’s ML exploration capability, which autonomously designs, executes, and analyzes ranking model experiments. This post covers how to optimize the low-level infrastructure that makes those models run efficiently at scale. We introduce KernelEvolve, an agentic kernel authoring system used by Ranking Engineer Agent and generally applicable to a range of AI models beyond Ads Ranking.
Summary
- Meta operates a large fleet of heterogeneous hardware — NVIDIA GPUs, AMD GPUs, Meta’s custom MTIA silicon chips, and CPUs. Using this hardware effectively and efficiently requires developing software that translates high-level model operations into efficient, chip-specific instructions called optimized kernels. Authoring and optimizing kernels must be done for each new chip generation and ML model architecture. Beyond standard kernel operators like general matrix multiplications (GEMMs) and convolutions covered by vendor libraries, production workloads require many custom operators across ranking models. With the number of models and number of hardware types and generations, hand-tuning by kernel experts doesn’t scale.
- To address the volume of performance optimization work required by the increasing number of models X number of hardware types & generations, we built KernelEvolve, an agent to optimize performance used by Meta’s Ranking Engineer Agent. It enables:
- Faster development: Compresses weeks of expert engineering time optimizing kernels, including profiling, optimizing, and cross-hardware debugging, into hours of automated search and evaluation, freeing engineers for other work.
- Better performance: Over 60% inference throughput improvement for the Andromeda Ads model on NVIDIA GPUs and over 25% training throughput improvement for an ads model on Meta’s custom MTIA silicon chips.
- Broad applicability: Optimizes across public and proprietary hardware including NVIDIA GPUs, AMD GPUs, MTIA chips and CPUs, generating kernels in high-level DSLs like Triton, Cute DSL, and FlyDSL, as well as low-level languages including CUDA, HIP, and MTIA C++.
- KernelEvolve treats kernel optimization as a search problem: a purpose-built job-harness evaluates each candidate kernel, feeds diagnostics back to the LLM, and drives a continuous search over hundreds of alternatives, exceeding the performance of human expert generated kernels.
- More details are available in the paper, “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta,” which will appear at the 53rd International Symposium on Computer Architecture (ISCA) 2026.
Every day, Meta serves billions of AI-powered experiences, from personalized recommendation to generative AI assistants, on a global infrastructure including diverse hardware from NVIDIA, AMD, and Meta’s custom MTIA silicon chips. Behind every training or inference request lies a layer of highly optimized low-level hardware kernels: small programs that translate high-level model operations into instructions a specific chip can execute efficiently. As AI models grow more complex and the hardware landscape diversifies, the number of kernels scales across hardware platforms, model architectures and operator types, resulting in thousands of configurations that can no longer realistically be tuned by human experts, creating a critical bottleneck that delays hardware enablement and performance tuning and slowing model iteration cycles that drive critical advances in ML technology and its applications.
Today, we are sharing KernelEvolve, an agentic AI system that improved ads model inference throughput by 60% in hours of experimentation, a task that would take human experts weeks. KernelEvolve autonomously generates and optimizes production-grade kernels for heterogeneous hardware used in training and inference, including NVIDIA GPUs, AMD GPUs, Meta’s custom MTIA silicon, and CPUs. Unlike typical large language model (LLM)-based agents that perform one-shot code generation, KernelEvolve treats kernel optimization as a search problem. It explores hundreds of alternative kernel implementations to identify a solution that often matches or exceeds human expert performance, and does so in hours instead of weeks. In Meta’s production environment, KernelEvolve is optimizing code that serves trillions of daily inference requests.
KernelEvolve represents a fundamental shift in how we think about the relationship between AI software and hardware. Where kernel development was once a manual, expert-driven process that struggled to keep pace with hardware and model evolution, KernelEvolve makes it continuous and automated — adapting as each changes. As Meta continues to diversify its AI hardware portfolio, the ability to rapidly generate optimized kernels for new chips substantially reduces the engineering effort required to integrate heterogeneous hardware for training and inference.
The Challenge: The Bottleneck of Explosive Kernel Growth
We’re seeing explosive kernel growth because the total number of kernels scales with the product of three factors: {hardware types and generations X model architectures X number of operators}. This product results in thousands of unique kernel configurations that must be written, tested, and maintained. Hand-tuning each kernel doesn’t scale, and kernel experts alone can’t keep up with the pace.
Hardware Heterogeneity
Meta’s accelerator fleet now spans NVIDIA GPUs, AMD GPUs, and Meta’s custom MTIA silicon, each with fundamentally different memory architectures and hierarchies, instruction sets, and execution models. A kernel that runs optimally on one platform may perform poorly or fail entirely on another. And the complexity doesn’t stop at vendor boundaries. Even within a single hardware family, successive generations introduce architectural changes that require different optimization strategies. Meta’s MTIA roadmap spans four chip generations in two years (MTIA 300 through 500), each introducing new compute capabilities, memory bandwidth characteristics, and numeric data types optimized for evolving workloads. A kernel optimized for one generation will underperform when run on the next generation of the same hardware architecture.
Model Architecture Variation
Meta’s recommendation models have evolved through three major phases: from early embedding-based deep learning recommendation models, to sequence learning models that process engagement histories with attention mechanisms, to Meta’s Generative Ads Recommendation Model (GEM), and most recently Meta’s foundation inference model that brings LLM-scale to ads (Meta Adaptive Ranking Model). Each generation introduces operator types the previous generation never needed. Beyond these generational shifts, Meta’s production stack simultaneously serves fundamentally different model families, each with its own unique operators, and a single ads request may traverse multiple families in one serving call. With a vast and growing number of distinct models in production, every new architecture extends the matrix of operators that must be optimized across hardware.
Kernel Diversity Beyond Standard Libraries
Vendor libraries like cuBLAS and cuDNN cover a set of common operations — GEMMs, convolutions, standard activations — but even these standard operators resist one-size-fits-all solutions. A single operator like matrix multiplication behaves differently across contexts: The optimal kernel for a training batch differs from an inference serving request, and tensor shapes vary widely across ranking stages and ranking models, creating a combinatorial space of configurations that neither human experts nor today’s compiler-based autotuning and fusion can fully cover at scale. Beyond standard operators, production workloads are dominated by a long tail of operators that fall outside library coverage. These include data preprocessing transforms like feature hashing, bucketing, and sequence truncation that prepare raw input for model inference, as well as custom model operators like fused feature interaction layers and specialized attention variants that are unique to Meta’s architectures.
None of these custom operators appear in vendor libraries, and many are too workload-specific to warrant a library implementation. Without native accelerator implementations, these operators either fall back to CPU — forcing disaggregated serving architectures with significant latency overhead — or run via unoptimized code paths that underutilize hardware.
The problem compounds with hardware diversity. A hand-tuned NVIDIA kernel cannot simply be recompiled for AMD GPUs or MTIA. Each new model architecture extends the tail further, and each new chip multiplies the work required to cover it.
How KernelEvolve Addresses These Challenges
Each challenge maps to a specific architectural decision:
| Challenge | How KernelEvolve Addresses It |
| Hardware Heterogeneity | A retrieval-augmented knowledge base injects platform-specific documentation including architecture manuals, instruction sets, and/or optimization patterns into the generation context. The LLM reasons over this documentation at inference time—no prior training on the target hardware required. A single universal prompting interface eliminates per-platform prompt templates. |
| Model Architecture Variation | Tree search explores implementation alternatives for any operator, including novel ones. Successful optimizations are distilled into reusable patterns that transfer across model families—an optimization discovered for one architecture accelerates similar operators in future ones. |
| Kernel Diversity / Long Tail | Automated evaluation validates hundreds of candidates in parallel. Search-based optimization replaces the need for hand-tuning, making operators feasible that wouldn’t otherwise justify weeks of manual tuning. |
KernelEvolve: Searching for Optimal Kernels
KernelEvolve approaches this challenge differently from standard AI coding assistants. Rather than prompting an LLM to generate a single kernel and testing it, the system formalizes kernel optimization as a structured search problem across the space of possible implementations. Under the hood, a purpose-built long-running job harness drives each iteration – compiling candidates, evaluating correctness and performance, profiling hardware utilization, and generating analysis reports – all while handling the multi-minute build cycles and infrastructure failures that make native approaches impractical.
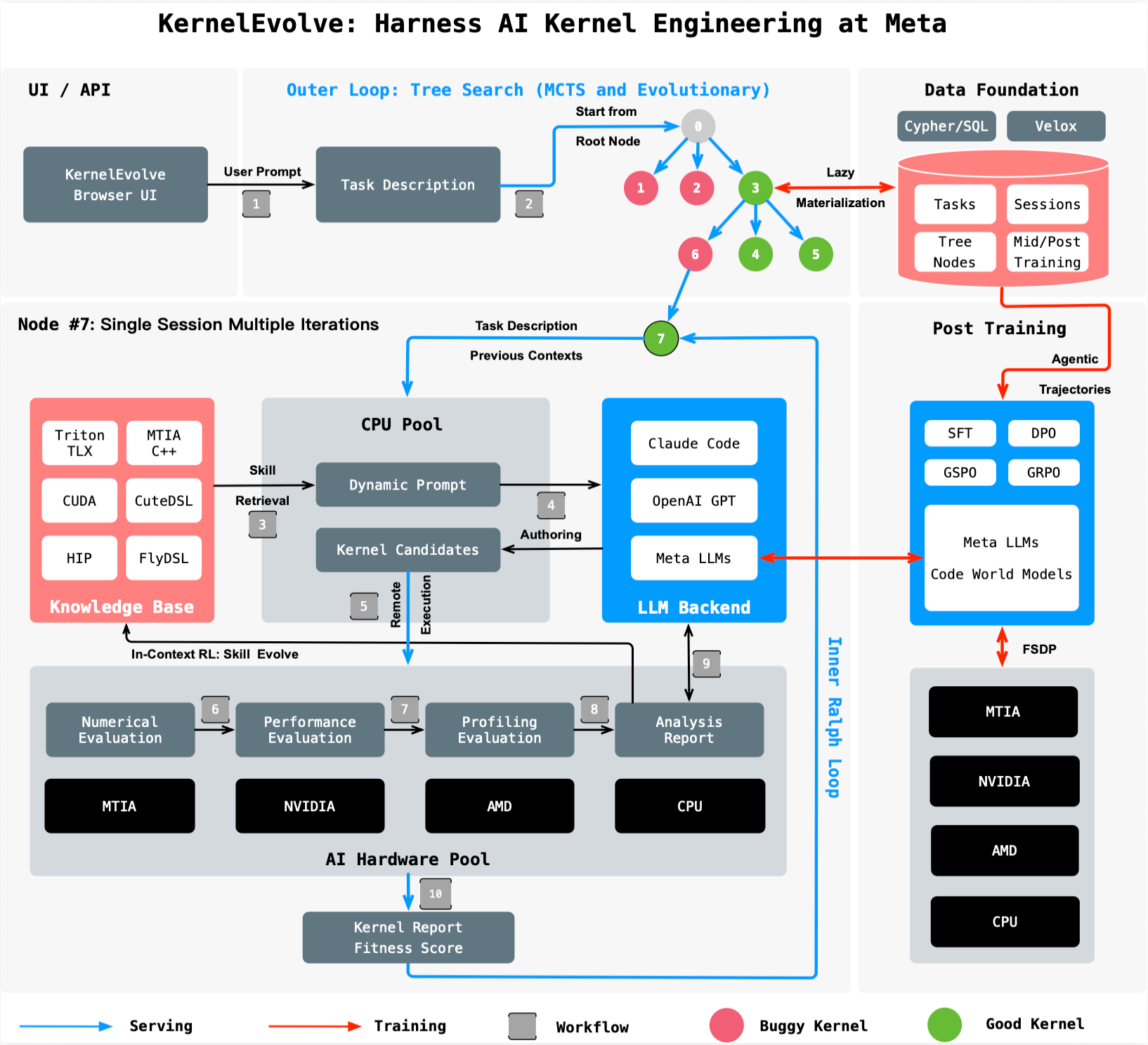
LLM Synthesizer
An LLM generates candidate kernels across multiple programming languages and hardware targets — from high-level DSLs like Triton, TLX, CuTe DSL, and FlyDSL, to low-level backends including CUDA, HIP, and MTIA C++.
Rather than using static prompts, the synthesizer constructs dynamic, context-aware prompts that are continuously enriched with runtime diagnostics, hardware constraints, and the historical signals from prior candidate optimization evaluation. This replaces the traditional approach of maintaining separate prompt templates for debugging, performance tuning, and correctness verification with a single adaptive interface that unifies these workflows into a single adaptive interface that drives a continuous, feedback-driven optimization loop.
Tree Search Engine
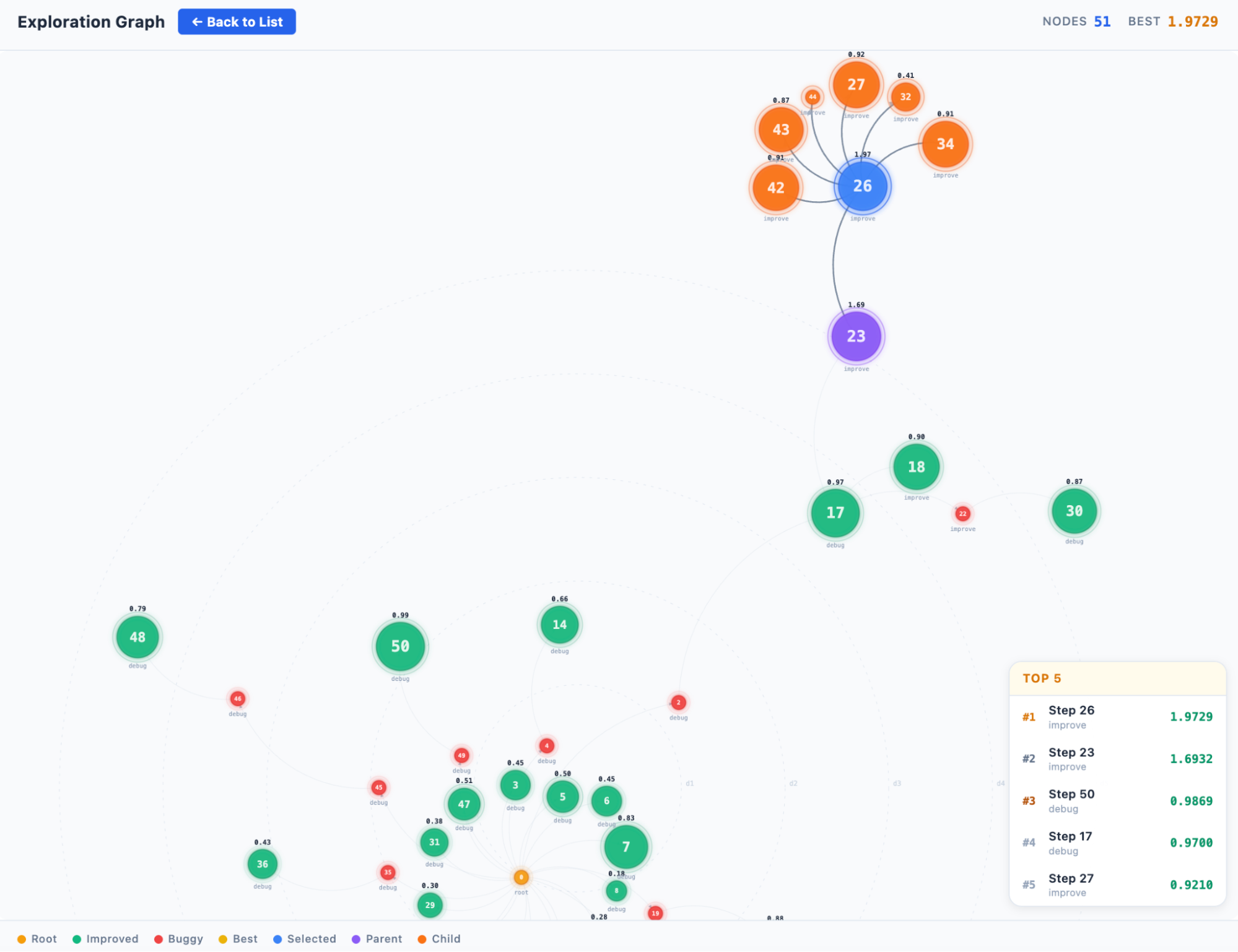
The system explores the optimization space using graph-based search algorithms, including Monte Carlo tree search and evolutionary strategies. Each kernel candidate becomes a node in a search tree. The engine selects promising candidates, applies transformations, evaluates results, and decides whether to explore further or backtrack — balancing exploitation of known-good strategies against exploration of novel approaches.
Crucially, nodes do not evolve in isolation. Each node carries a configurable memory operator that determines how it draws context from the search tree when generating the next round of candidates. A node may inherit its parent’s optimization trajectory to refine a promising direction, compare against siblings to learn what differentiates high-performing variants, combine insights from both parent and sibling histories, or start with a clean slate to escape local optima. This selective memory mechanism allows the tree search to move beyond simple independent sampling – sibling nodes collaborate by surfacing complementary strategies, parent-child chains preserve and deepen successful optimization paths, and memory-free restarts inject diversity when the search stagnates.
Retrieval-Augmented Knowledge Base
To generate optimized code for hardware the underlying LLM was never trained on, KernelEvolve maintains a hierarchical knowledge base organized into three categories: correctness constraints that enforce valid kernel implementations, platform-agnostic optimization guidance covering debugging and tuning strategies, and hardware-specific documentation containing architectural details for each accelerator platform. The system retrieves relevant knowledge dynamically based on runtime signals. For example, a memory bandwidth bottleneck triggers retrieval of memory hierarchy documentation; a compilation error activates debugging guidance.
This knowledge base is not static. As the system solves new optimization problems it distills successful strategies into reusable skills — compact optimization patterns and debugging heuristics — that are continuously written back into the knowledge base. This self-evolving skill library acts as a form of in-context reinforcement learning: Each successful exploration enriches the context available to future sessions, enabling the system to solve similar problems faster and with fewer search steps, without requiring model retraining.
Automated Evaluation Framework
Every generated kernel passes through a rigorous validation pipeline that checks both correctness — bitwise accuracy against reference implementations — and performance. And evaluation goes far beyond a single runtime number.
KernelEvolve leverages a stack of profiling tools, each targeting a different level of analysis. TritonBench validates numerical correctness against PyTorch baselines and measures end-to-end speedup across production input shapes. PyTorch Profiler captures system-level execution timelines, including kernel launch overhead and host-device synchronization. For GPU targets, tools like NCU provide kernel-level hardware metrics — occupancy, memory throughput, instruction mix — while Proton delivers intra-kernel instruction-level latency and pipeline behavior. For MTIA targets, MTIA Insight provides comprehensive accelerator-specific instrumentation: PE utilization, fixed-function engine metrics (DPE, SFU, MLU utilization and stall cycles), cache behavior, and per-PE memory bandwidth counters.
Rather than treating these tools as standalone steps, KernelEvolve unifies them through a compiler-centric abstraction. The framework composes analysis through job graphs: compiler transforms insert MLIR-level instrumentation, profiling passes collect metrics, and trace synthesis produces structured output. This means the search engine doesn’t just see “kernel A is 1.2x faster than kernel B” — it sees why: whether the bottleneck is memory-bound, compute-bound, or limited by occupancy — and feeds that diagnostic signal back into the LLM synthesizer to guide the next round of candidates.
Shared Data Foundation
Every optimization session contributes to a shared data foundation. When one engineer’s exploration discovers an effective tiling strategy for a class of operators, that insight becomes available to every future session targeting similar workloads — creating a compounding effect where the system grows more capable with each use. Early adopters perform the hardest exploration; subsequent users inherit much closer to optimal starting points and refine from there.
Agentic Reinforcement Learning
Every optimization session generates structured training data as a natural byproduct: agentic trajectories capturing the reasoning, code transformations, and evaluation feedback behind high-performing kernels. This domain-specific data is rare and valuable. It encodes optimization intuition that no public dataset contains.
We use this data to post-train smaller, specialized models through agentic reinforcement learning, where the reward signal comes directly from measured kernel performance. The result is a virtuous cycle where better models produce better kernels in fewer reasoning tokens and fewer search steps, which in turn generate higher-quality training data. Over successive iterations, this compounding flywheel enables us to self-host increasingly efficient models that are compact enough to run cost-effectively at scale while retaining the optimization capability of much larger frontier models.
Enabling Proprietary AI Chips
One of the most consequential capabilities of this architecture is its ability to generate optimized code for hardware that does not exist in any public training dataset.
Meta’s custom MTIA chips present a unique programming challenge. Because these chips are proprietary, no public LLM has been trained on MTIA code. A standard coding assistant lacks the context to write optimized MTIA kernels because it has never seen MTIA documentation, instruction set details, or programming idioms.
KernelEvolve solves this through systematic knowledge injection. We encode MTIA-specific documentation (architecture manuals, instruction set references, memory hierarchy specifications, and optimization patterns) directly into the retrieval-augmented knowledge base. When the system targets MTIA, it retrieves and incorporates this proprietary knowledge into its reasoning, effectively “learning” the hardware in real time.
This approach extends to any new accelerator. When a new chip arrives, the engineering cost shifts from writing thousands of kernels by hand to curating a set of hardware documents and injecting them into the knowledge base. The system then autonomously generates optimized kernels for the new platform, ensuring the software stack is ready at the speed of hardware deployment rather than the speed of manual engineering.
KernelEvolve’s Impact Across Benchmark and Production
KernelEvolve has delivered strong results across both standardized benchmarks and production workloads.
Benchmark performance: On KernelBench, a benchmark suite of 250 kernel optimization problems from Stanford spanning three difficulty levels, KernelEvolve achieves a 100% pass rate — all generated kernels are both functionally correct and faster than their PyTorch reference implementations. The system also validates 160 PyTorch ATen operators with 100% correctness across three hardware platforms (480 total configurations).
Production speedups: On Meta’s MTIA chips, KernelEvolve’s generated kernels, which spanned compute-bound, memory-bound, and custom operations, achieved speed ups of over 25% training throughput improvement on an ads model. On NVIDIA GPUs, it delivered more than 60% inference throughput improvement over a model with highly optimized kernels including torch.compile and vendor libraries — performance gains that directly translate to serving capacity and infrastructure efficiency.
Hardware coverage: The system generates optimized kernels for NVIDIA GPUs, AMD GPUs, Meta’s custom MTIA silicon, and CPUs — from a single unified framework. Rather than maintaining separate prompt templates per platform, the system dynamically retrieves hardware-specific constraints and optimization patterns, adapting to each target through retrieval augmentation rather than manual prompt engineering.
Development Velocity
Kernel development that previously required weeks of expert effort — profiling, iterating on tiling strategies, debugging edge cases across hardware — now completes in hours through automated search and evaluation. This shifts engineer time from writing low-level code to higher-value work such as designing model architectures, improving training techniques, and defining optimization objectives.
How It All Fits Together
An engineer specifies a target operator, hardware platform, and performance goals. The system then autonomously:
- Retrieves relevant hardware documentation and optimization knowledge from the knowledge base.
- Generates an initial set of kernel candidates using the LLM synthesizer with context-aware prompting.
- Evaluates each candidate for correctness and performance using distributed benchmarking infrastructure.
- Feeds results back into the search engine, which selects the most promising candidates and applies further optimizations.
- Iterates steps 1-4, exploring the search tree until the termination criteria are met — either a performance target is achieved, the search budget is exhausted, or progress stalls.
- Outputs the best-performing, fully validated kernel, ready for production deployment.
The process runs on Meta’s distributed infrastructure, evaluating thousands of candidates in parallel. Persistent storage of search trees and implementations lets the system build on prior results when targeting new model variants or hardware generations.
Looking Ahead
The same agentic techniques powering KernelEvolve — structured reasoning, retrieval-augmented knowledge, closed-loop evaluation — can be applied to hybrid model search, compiler optimization, memory management, and system configuration. KernelEvolve represents an early step toward the vision of a Ranking Engineer Agent that can continuously optimize its own performance-critical infrastructure.
Within REA, ML Exploration discovers better models. KernelEvolve makes them production-ready. Together, they accelerate how quickly ranking improvements reach advertisers.
In the next post in the REA series, where we’ll explore other agentic ML optimizations.
Read the Paper
For more technical details, read our paper, “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta” from ISCA 2026.
Acknowledgements
We would like to thank Ying Wang, Hongsen Qin, Tao Yang, Jia Jiunn Ang, Yujia He, Alicia Golden, Michael Kuchnik, Wei Guo, Yihan He, Jiangyuan Li, Dianshi Li, Chao Xie, Adele Sun, Richard Li, Alec Hammond, Ajit Mathews, Roman Levenstein, Hongtao Yu, Yuanwei (Kevin) Fang, Kunming Ho, Haishan Zhu, Site Cao, Abdullah Ozturk, Jort Gemmeke, Daniel Wang, Juan Angeles Acuna, Yoram Bachrach, Ming Chen, Terry Chen, Jake Cheng, Wayne Chiang, Wenyuan Chi, Rick Chang, Wyatt Cook, Tri Dao, Barry Dong, Liubov Dmitrieva, Derek Dunfield, Zhou Fang, Rob Fergus, Maxwell Harrison Fisch, Zacharias Fisches, Zach Freeman, Chunli Fu, Vishal Gandhi, Kaustubh Gondkar, Wentian Guo, Han Guo, William Hanwei Liang, Samuel Hsia, Barney Huang, Nicholas Hungria, Martin Josifoski, Jacob Kahn, Shobhit Kanaujia, Drew Lackman, Marek Latuskiewicz, Kristin Lauter, Matan Levi, Evan Li, Yiting Li, Jiang Liu, Alexey Loginov, Yining Lu, Anuj Madan, John Martabano, Anna Mcburney, Keyur Muzumdar, Kelvin Niu, Sandeep Pandey, Uladzimir Pashkevich, Dmitrii Pedchenko, Pedro Pedreira, Varna Puvvada, Preyas Janak Shah, Bidit Sharma, Feng Shi, Stanley Shi, Ketan Singh, Vibha Sinha, Matt Steiner, Gabriel Synnaeve, Oleksandr Stashuk, Jim Tao, Ritwik Tewari, Chris Wiltz, Yao Xuan, Tak Yan, Bill Yoshimi, Xiayu Yu, Abdul Zainul-Abedin, Qing Zhang, and Mingjie Zhu








