
We are open-sourcing the initial version of RCCLX – an enhanced version of RCCL that we developed and tested on Meta’s internal workloads. RCCLX is fully integrated with Torchcomms and aims to empower researchers and developers to accelerate innovation, regardless of their chosen backend.
Communication patterns for AI models are constantly evolving, as are hardware capabilities. We want to iterate on collectives, transports, and novel features quickly on AMD platforms. Earlier, we developed and open-sourced CTran, a custom transport library on the NVIDIA platform. With RCCLX, we have integrated CTran to AMD platforms, enabling the AllToAllvDynamic – a GPU-resident collective. While not all the CTran features are currently integrated into the open source RCCLX library, we’re aiming to have them available in the coming months.
In this post, we highlight two new features – Direct Data Access (DDA) and Low Precision Collectives. These features provide significant performance improvements on AMD platforms and we are excited to share this with the community.
Direct Data Access (DDA) – Lightweight Intra-node Collectives
Large language model inference operates through two distinct computational stages, each with fundamentally different performance characteristics:
- The prefill stage processes the input prompt, which can span thousands of tokens, to generate a key-value (KV) cache for each transformer layer of the model. This stage is compute-bound because the attention mechanism scales quadratically with sequence length, making it highly demanding on GPU computational resources.
- The decoding stage then utilizes and incrementally updates the KV cache to generate tokens one by one. Unlike prefill, decoding is memory-bound, as the I/O time of reading memory dominates attention time, with model weights and the KV cache occupying the majority of memory.
Tensor parallelism enables models to be distributed across multiple GPUs by sharding individual layers into smaller, independent blocks that execute on different devices. However, one important challenge is the AllReduce communication operation can contribute up to 30% of end-to-end (E2E) latency. To address this bottleneck, Meta developed two DDA algorithms.
- The DDA flat algorithm improves small message-size allreduce latency by allowing each rank to directly load memory from other ranks and perform local reduce operations, reducing latency from O(N) to O(1) by increasing the data exchange from O(n) to O(n²).
- The DDA tree algorithm breaks the allreduce into two phases (reduce-scatter and all-gather) and uses direct data access in each step, moving the same amount of data as the ring algorithm but reducing latency to a constant factor for slightly larger message sizes.
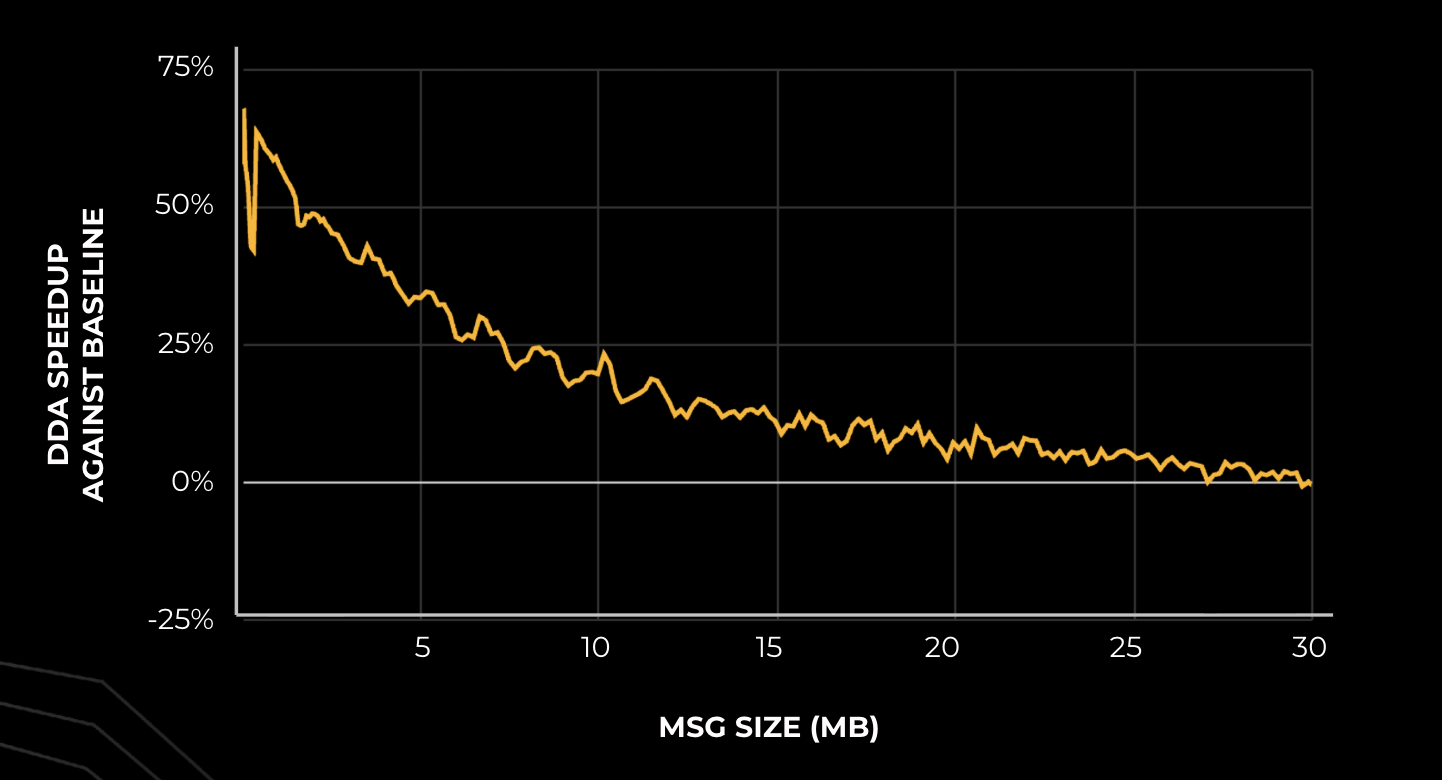
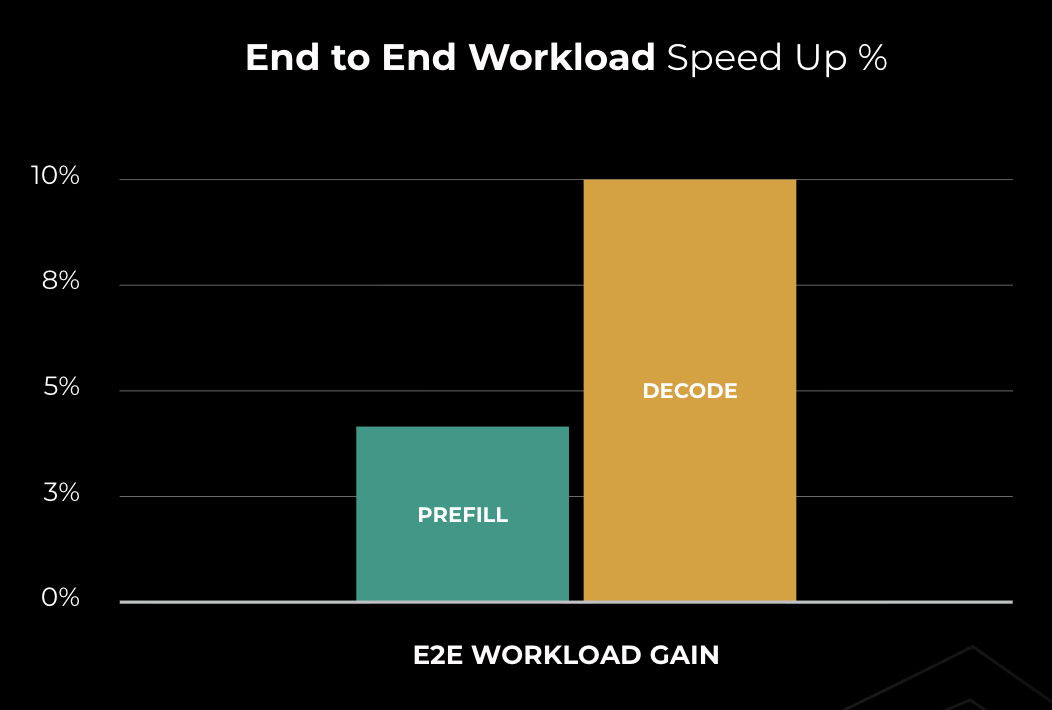
The performance improvements of DDA over baseline communication libraries are substantial, particularly on AMD hardware. With AMD MI300X GPUs, DDA outperforms the RCCL baseline by 10-50% for decode (small message sizes) and yields 10-30% speedup for prefill. These improvements resulted in approximately 10% reduction in time-to-incremental-token (TTIT), directly enhancing the user experience during the critical decoding phase.
Low-precision Collectives
Low-precision (LP) collectives are a set of distributed communication algorithms — AllReduce, AllGather, AlltoAll, and ReduceScatter — optimized for AMD Instinct MI300/MI350 GPUs to accelerate AI training and inference workloads. These collectives support both FP32 and BF16 data types, leveraging FP8 quantization for up to 4:1 compression, which significantly reduces communication overhead and improves scalability and resource utilization for large message sizes (≥16MB).
The algorithms use parallel peer-to-peer (P2P) mesh communication, fully exploiting AMD’s Infinity Fabric for high bandwidth and low latency, while compute steps are performed in high precision (FP32) to maintain numerical stability. Precision loss is primarily dictated by the number of quantization operations — typically one or two per data type in each collective — and whether the data can be adequately represented within the FP8 range.
By dynamically enabling LP collectives, users can selectively activate these optimizations in E2E scenarios that benefit most from performance gains. Based on internal experiments, we have observed significant speed up for FP32 and notable improvements for BF16; it’s important to note that these collectives have been tuned for single-node deployments at this time.
Reducing the precision of types can potentially have an impact on numeric accuracy so we tested for this and we found that it provided acceptable numerical accuracy for our workloads. This flexible approach allows teams to maximize throughput while maintaining acceptable numerical accuracy, and is now fully integrated and available in RCCLX for AMD platforms — simply set the environment variable RCCL_LOW_PRECISION_ENABLE=1 to get started.
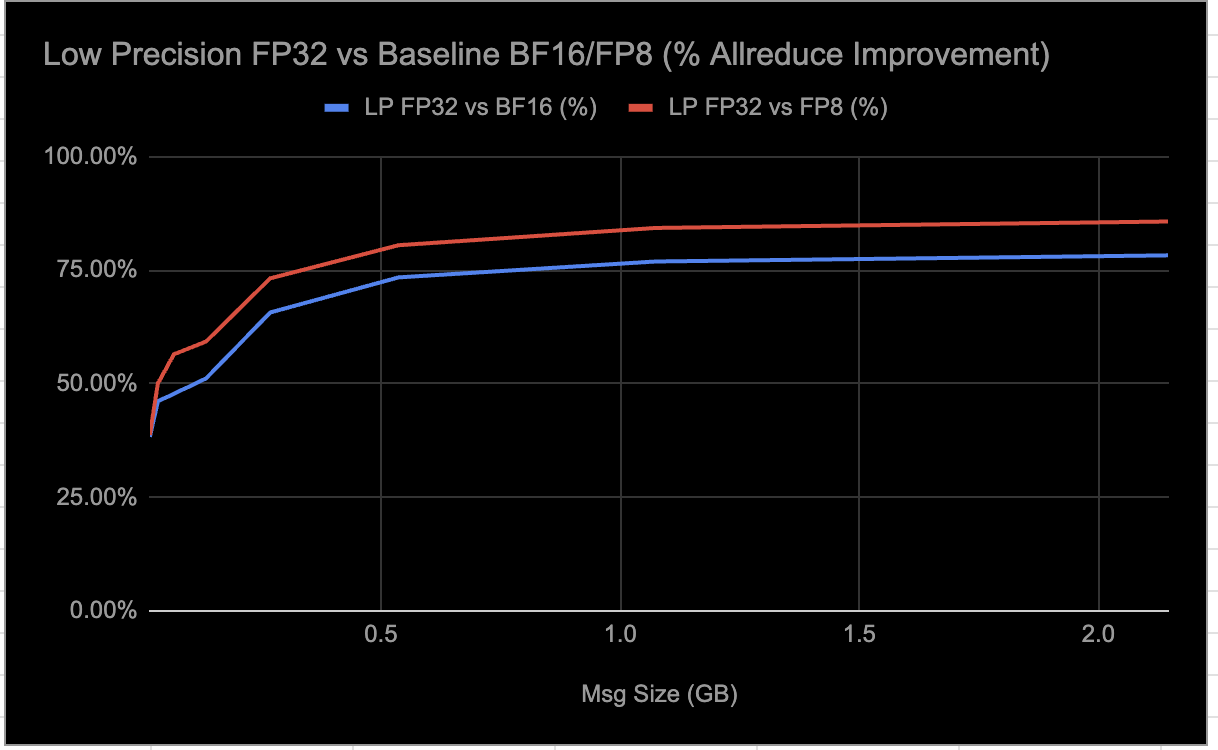
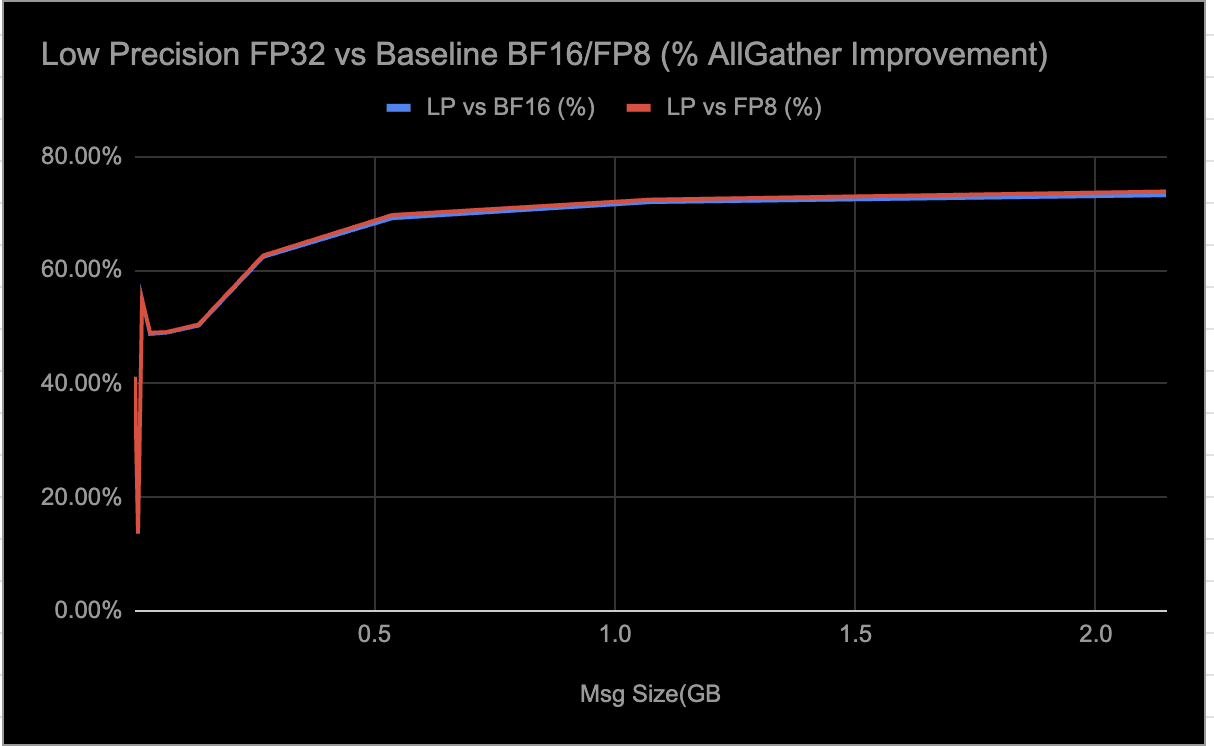
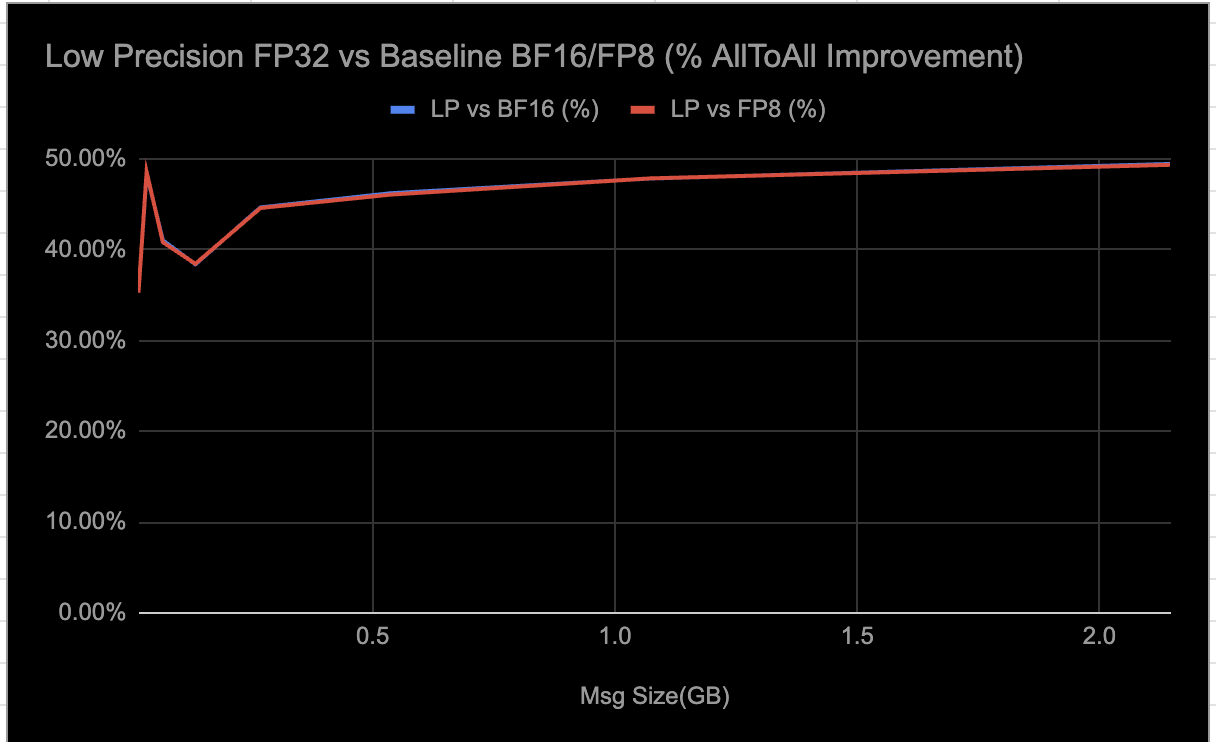
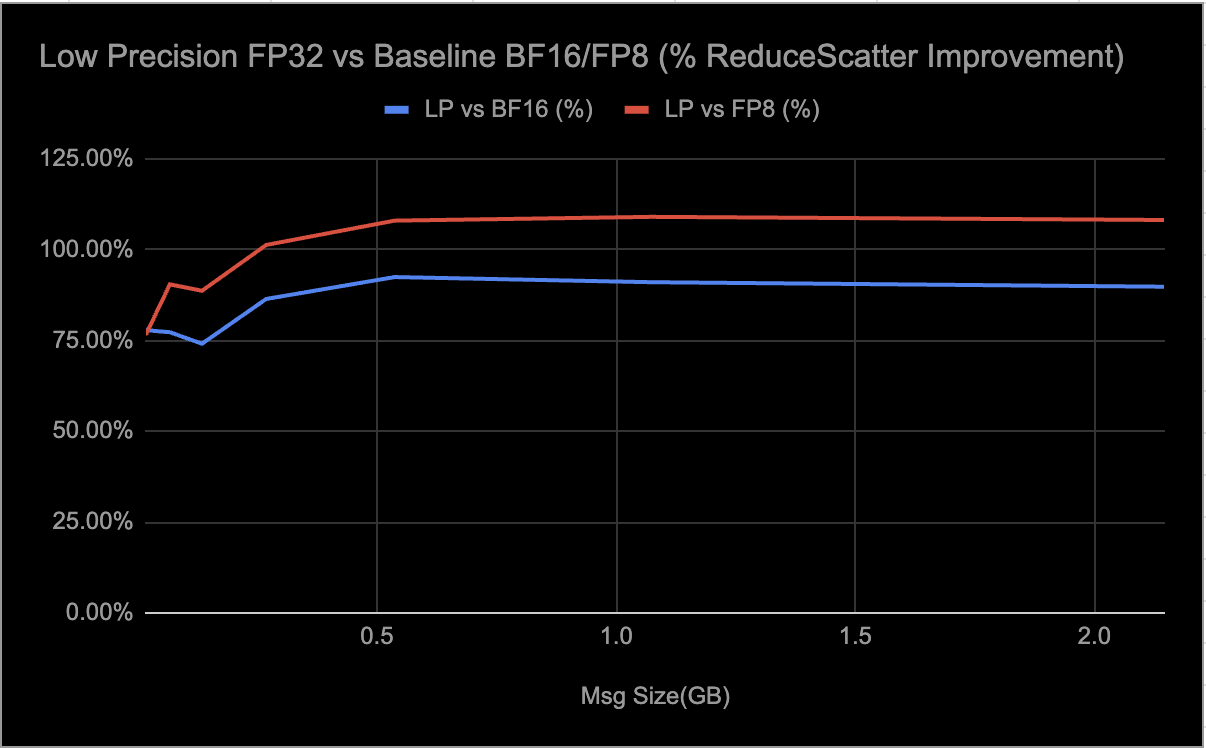
We are observing the following results from E2E inference workload evaluations when selectively enabling LP collectives:
- Approximately ~0.3% delta on GSM8K evaluation runs.
- ~9–10% decrease in latency.
- ~7% increase in throughput.
The throughput measurements shown in the graphs were obtained using param-bench rccl-tests. For the MI300, the tests were run on RCCLX built with ROCm 6.4, and for the MI350, on RCCLX built with ROCm 7.0. Each test included 10 warmup iterations followed by 100 measurement iterations. The reported results represent the average throughput across the measurement iterations.
Easy adaptation of AI models
RCCLX is integrated with the Torchcomms API as a custom backend. We aim for this backend to have feature parity with our NCCLX backend (for NVIDIA platforms). Torchcomms allows users to have a single API for communication for different platforms. A user would not need to change the APIs they’re familiar with to port their applications across AMD, or other platforms even when using the novel features provided by CTran.


RCCLX Quick Start Guide
Install Torchcomms with RCCLX backend by following the installation instructions in the Torchcomms repo.
import torchcomms
# Eagerly initialize a communicator using MASTER_PORT/MASTER_ADDR/RANK/WORLD_SIZE environment variables
provided by torchrun.
# This communicator is bound to a single device.
comm = torchcomms.new_comm("rcclx", torch.device("hip"), name="my_comm")
print(f"I am rank {comm.get_rank()} of {comm.get_size()}!")
t = torch.full((10, 20), value=comm.rank, dtype=torch.float)
# run an all_reduce on the current stream
comm.allreduce(t, torchcomms.ReduceOp.SUM, async_op=False)
Acknowledgements
We extend our gratitude to the AMD RCCL team for their ongoing collaboration. We also want to recognize the many current and former Meta employees whose contributions were vital in developing torchcomms and torchcomms-backends for production-scale training and inference. In particular, we would like to give special thanks to Dingming Wu, Qiye Tan, Pavan Balaji Yan Cui, Zhe Qu, Ahmed Khan, Ajit Mathews, CQ Tang, Srinivas Vaidyanathan, Harish Kumar Chandrappa, Peng Chen, Shashi Gandham, and Omar Baldonado








