
- Meta presents Chakra execution traces, an open graph-based representation of AI/ML workload execution, laying the foundation for benchmarking and network performance optimization.
- Chakra execution traces represent key operations, such as compute, memory, and communication, data and control dependencies, timing, and resource constraints.
- In collaboration with MLCommons, we are seeking industry-wide adoption for benchmarking.
- Meta open sourced a set of tools to enable the collection, analysis, generation, and adoption of Chakra execution traces by a broad range of simulators, emulators, and replay tools.
At Meta, our endeavors are not only geared towards pushing the boundaries of AI/ML but also towards optimizing the vast networks that enable these computations. Our agile, reproducible, and standardized benchmarking system plays an important role in this. Through our collaboration with MLCommons, and our deep insights into traditional benchmarking constraints, we have initiated the Chakra execution traces—a graph-based representation of AI/ML workloads. This approach aims to unify diverse execution trace schemas, seeking industry-wide adoption for enhanced AI efficiency analysis tools and holistic performance benchmarking.
The limitations of traditional AI benchmarking methodology
Traditionally, benchmarking AI systems has largely relied on running full ML workloads. Established benchmarking approaches, such as MLPerf, have provided invaluable insights into the behavior and performance of AI workloads and systems. However, traditional full workload benchmarking presents several challenges:
- Difficulty in forecasting future system performance: When designing an AI system, engineers frequently face the challenge of predicting the performance of future systems. Such predictions become even more complex when the compute engines aren’t ready or when changes in network topology and bandwidth become necessary. Relying on full workloads to evaluate the performance of these not-yet-realized systems is not feasible.
- High compute cost: Executing full workload benchmarks comes at a substantial compute cost. Given that training contemporary ML models often requires thousands of graphics processing units (GPUs), these benchmarks should ideally be executed on a similarly vast number of GPUs. Additionally, gauging the performance of a system using this method can be time-consuming.
- Inability to adapt to evolving workloads: The landscape of ML workloads and their requirements is rapidly evolving. Traditional full workload benchmarks fall short when it comes to addressing these changing needs, primarily because they necessitate significant efforts to standardize workloads as benchmarks.
An overview of Chakra
Building upon our insights into the constraints of traditional benchmarking, we present the Chakra execution traces. This new approach provides an open, interoperable graph-based depiction of AI/ML workload execution. The Chakra execution trace captures core operations—including compute, memory, and communication—along with their dependencies, timing, and metadata.
Though execution traces are a valuable representation of an ML task, the structure and metadata of the resulting traces can differ based on the ML framework utilized. Recognizing this, Chakra introduces a standardized schema for performance modeling, termed the Chakra execution trace. The below figure outlines the Chakra ecosystem, with execution traces as its central component. As depicted in the figure, Chakra also offers a range of tools to convert, visualize, generate, and simulate these execution traces.
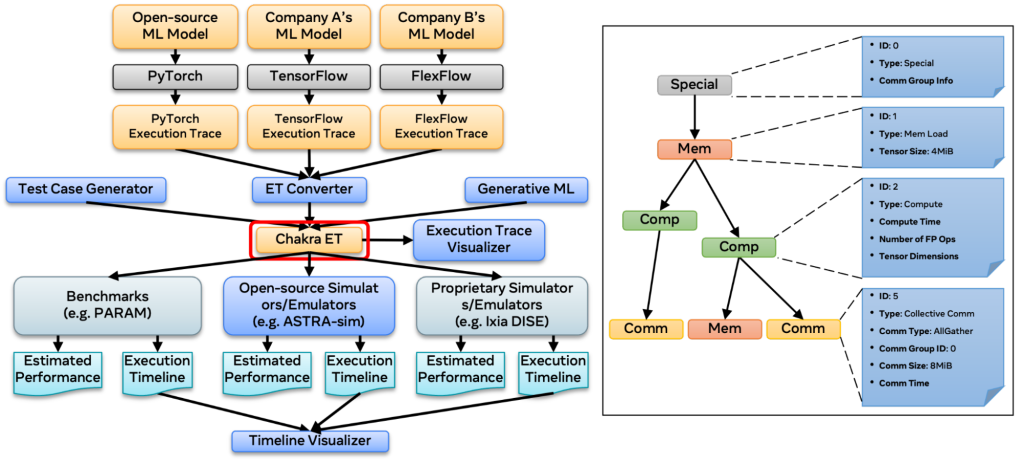
How Meta leverages Chakra execution traces
At Meta, we collect execution traces from our production servers every day. These execution traces serve multiple purposes: Benchmarking, visualization, and performance optimization.
Benchmarking
Benchmarking is essential for improving current AI systems and planning future networks. We specifically utilize Chakra execution traces for this task. We have developed several benchmarking tools, including Mystique and PARAM. Mystique allows us to replicate the performance of an ML workload by replaying both compute and communication operators found in execution traces. It leverages the Chakra execution trace to record runtime details of a model at the operator level and then replays them to reproduce the original performance. In line with our vision, the MLCommons Chakra working group is curating the ‘Chakra trace benchmark suite’ by gathering execution traces from various industry players.

Visualization and performance optimization
One example of visualization and performance optimization is the analysis of collective message sizes. We analyze production execution traces using an automated system. The visual data generated aids us in identifying any balance or imbalance in collective message sizes across different ranks. Our visualization tool can precisely highlight these imbalances, as shown by the below figure.
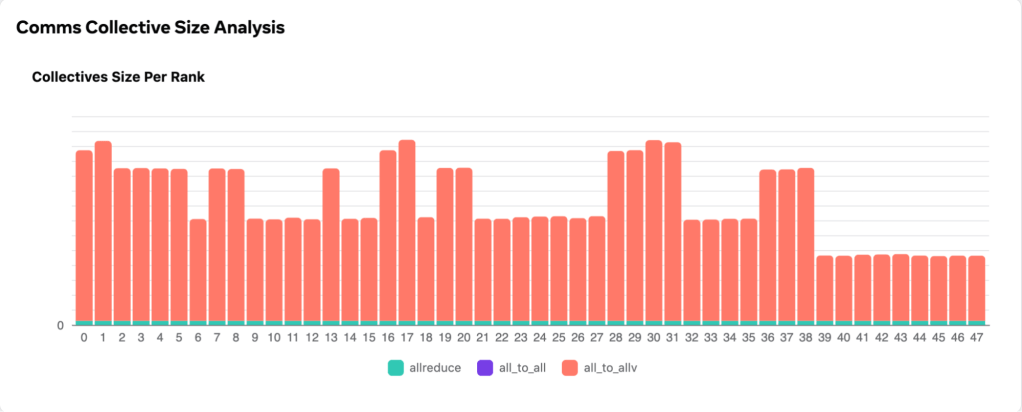
With this information at hand, Meta engineers are equipped to craft appropriate solutions, ensuring a balanced message size, as demonstrated in the below figure.
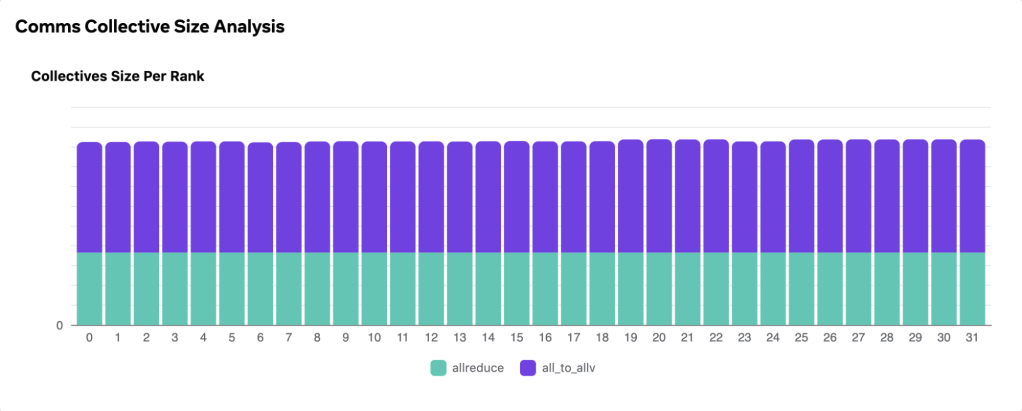
Future plans
Enhancing the benchmarking capability of Chakra execution traces
While the execution trace replayer enables replay of execution traces, it brings forth challenges. A primary challenge is the intrinsic linkage of collected execution traces to specific systems. Because traces are gathered from actual machine runs, the kernels executed are optimized for the specific system at play. As a result, traces sourced from one system might not accurately simulate on another with a different GPU, network topology, and bandwidth.
We’re addressing this constraint in collaboration with the MLCommons Chakra working group. We aspire to gather execution traces prior to the operator optimization phase for any target system, as shown in the figure. These are termed pre-execution traces. In parallel, to enable benchmarking next-gen AI systems, we’re streamlining the process from trace collection to simulation on a simulator.

Using AI to generate representative execution traces
Chakra execution traces are capable of identifying network bottlenecks in ML workload execution. However, optimizing SW/HW stacks with production execution traces presents a practical challenge. The main challenge arises when trying to globally optimize our production systems. Given the sheer volume of production traces, exhaustively running them for system optimization is neither feasible nor efficient. Doing so would be both time-consuming and computationally expensive. Thus, selecting a representative subset of production execution traces becomes imperative.
However, there’s a risk: The chosen traces might not holistically represent the global characteristics, potentially skewing optimization efforts towards only specific ML workloads. We envision a generative AI model that can identify and generate execution traces that are representative of the primary characteristics observed. We also plan to incorporate an obfuscation mechanism within the AI model. This will facilitate trace sharing without jeopardizing intellectual property, fostering SW/HW co-design between different companies.
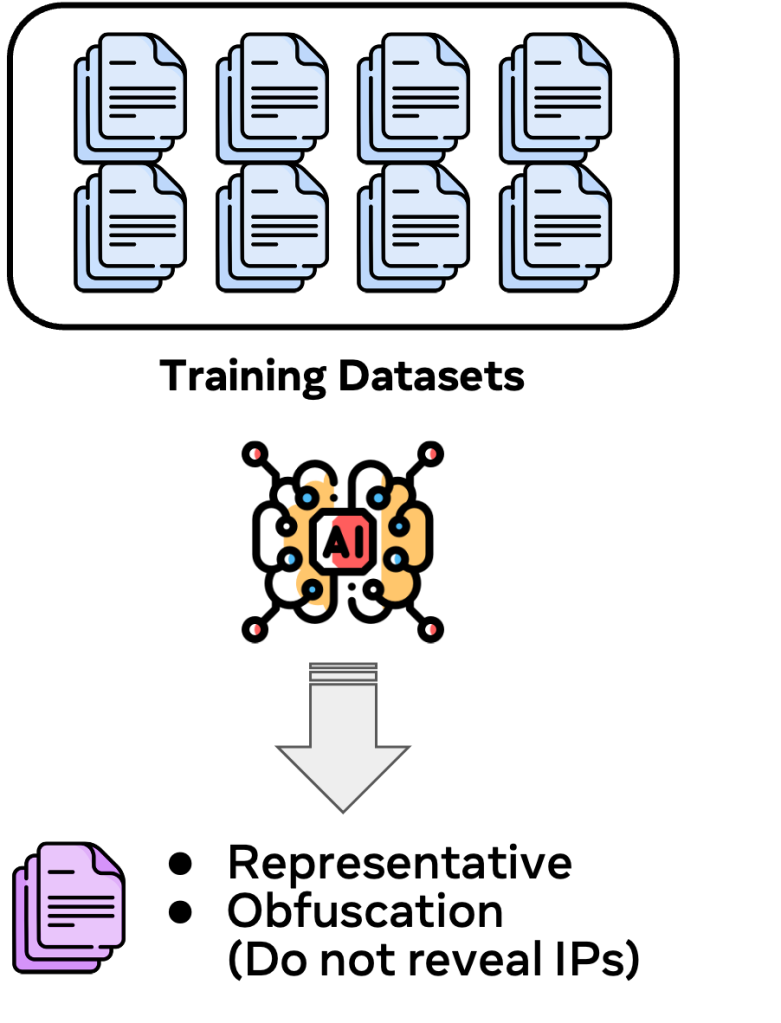
Taking the leap with industry collaboration
For such an ecosystem to flourish, industry consensus is paramount. Our collaboration with the MLCommons consortium, an open engineering assembly of over 50 leading companies, is a testament to our commitment. This collaboration aims to establish Chakra within its fold, providing a framework for broad adoption.
Chakra’s working group under MLCommons will spearhead efforts to create and develop:
- A standardized schema that can capture and convert execution traces from diverse frameworks.
- ML models for creating representative Chakra execution traces – protecting proprietary information while also projecting future AI workloads.
- An open ecosystem of tools for benchmarks, simulations, and emulations.
- Comprehensive benchmarks with Chakra execution traces based on MLCommons/MLPerf guidelines.
Join us on this journey
Our vision is to forge an agile, reproducible benchmarking and co-design system for AI. Collaboration with peers, academic institutions, and consortiums will be pivotal. We invite interested individuals and companies to become a part of the Chakra working group, to help contribute to the paradigm shift in benchmarking and network performance optimization.
Read the research paper
Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
Acknowledgements
We would like to thank all contributors to the Chakra project within Meta: Taekyung Heo, Srinivas Sridharan, Brian Coutinho, Hiwot Kassa, Matt Bergeron, Parth Malani, Shashi Gandham, Omar Baldonado, our external partners in Georgia Tech and MLCommons, as well as external collaborators in AMD, CMU, Cornell, Enfabrica, Google, Harvard, HP Labs, Intel, Keysight Technologies, Microsoft, NVIDIA, OCP, and Stanford.








