
Over the past 21 years, Meta has grown exponentially from a small social network connecting a few thousand people in a handful of universities in the U.S. into several apps and novel hardware products that serve over 3.4 billion people throughout the world.
Our infrastructure has evolved significantly over the years, growing from a handful of software systems on a small fleet of servers in a few co-location facilities to a massive, globally networked operation. We faced numerous challenges along the way and developed innovative solutions to overcome them.
The advent of AI has changed all of our assumptions on how to scale our infrastructure. Building infrastructure for AI requires innovation at every layer of the stack, from hardware and software, to our networks, to our data centers themselves.
Facebook was built on the open source Linux, Apache, MySQL, and PhP (LAMP) stack. True to our roots, much of our work has been openly shared with the engineering community in the form of research papers or open source hardware and software systems. We remain committed to this open source vision and describe how we are committed to an open standards approach to silicon and hardware systems as we push the frontiers of computer science.
Scaling Our Infrastructure Stack (2004 – 2010)
In our earliest years, we focused our engineering work on scaling our software stack. As Facebook expanded from Harvard to other universities, each university got its own database. Students logging on to Facebook would connect to a set of common web servers that would in turn connect each student to their university’s database. We quickly realized that students wished to connect with their friends who attended other universities — this was the birth of our social graph that interconnected everyone on the social network.
As Facebook expanded beyond universities to high schools and then the general public, there was a dramatic increase in the number of people on our platform. We managed database load by scaling our Memcache deployments and then building entirely new software systems such as the TAO social graph, and a whole host of new caching and data management systems. We also developed a new ranking service for News Feed and a photo service for sharing photos and videos.
Soon, we were expanding beyond the US to Europe. Scaling our software systems was critical, but no longer sufficient. We needed to find other ways to scale. So we moved one layer below software and started scaling our physical infrastructure. We expanded beyond small co-location facilities in the Bay Area to a co-lo in Ashburn, Va. In parallel, we built out our first data centers in Prineville, Ore. and Forest City, N.C.
As our physical infrastructure scaled to multiple data centers, we ran into two new problems. First, we needed to connect our user base distributed across the US and Europe to our data centers. We tackled this problem by aggressively building out our edge infrastructure where we obtained some compute capacity beside every local internet service provider (ISP) and bought into the peering network that connected the ISP to our data centers. Second, we needed to replicate our entire software stack to each data center so that people would have the same experience irrespective of which actual physical location they connected to. This required us to build a high bandwidth, multipath backbone network that interconnected our data centers. Initially, this entailed building out our terrestrial fiber network to connect the various co-location facilities in California and Virginia to our new data centers in Oregon and North Carolina.
As our user base grew globally, we scaled beyond single data center buildings and into data center regions consisting of multiple buildings. We also aggressively built out our edge presence, where we now operate hundreds of points-of-presence (POPs) across the world.
The Challenges of Scaling (2010 – 2020)
Building out a global infrastructure also brought along all of the complex corner cases of computer science.
Cache Consistency
First, we needed to solve for cache consistency. We saw issues where people would receive notifications about being tagged in a photo, but couldn’t see the photo. Or people in a chat thread would receive messages out-of-order. These problems manifested because we were serving a fraction of our user base out of each data center region. People served out of the same region would receive notifications and see the right data, while people in a different region would experience a lag as the data update was replicated across our distributed fleet. This lag directly led to an inconsistent user experience. We solved these problems by building novel software systems that delivered cache invalidations, eventually building a consistency API for distributed systems.
Fleet management
As we added new data center regions and grew our machine fleet, we also had to develop new abstractions to manage them. This included systems and associated components like:
- Twine: a cluster management system that scales to manage millions of machines in a data center region.
- Tectonic: a data center scale distributed file system.
- ZippyDB: a strongly consistent distributed key value store.
- Shard Manager: a global system to manage tens of millions of shards of data, hosted on hundreds of thousands of servers for hundreds of applications.
- Delos: a new control plane for our global infrastructure.
- Service Router: to manage our global service mesh.
We developed the above systems, and many others, so we could operate a global fleet of millions of machines, while also providing excellent performance.
Masking hardware failure
More machines also implies a higher likelihood of failure. To address this, we worked to ensure that we could mask failures from users and provide a highly available and accessible service. We accomplished this by building new systems like:
- Kraken: which leverages live traffic load tests to identify and resolve resource utilization bottlenecks.
- Taiji: to manage user traffic load balancing.
- Maelstrom: which handled data center-scale disasters safely and efficiently while minimizing user impact.
We continue to invest heavily in reliability and fault tolerance as stability is critical for all the people who use our services to connect with their friends, family, and the businesses that serve them.
Enter AI Workloads (2020)
While we were navigating the challenges of scaling, we were also seeing glimpses of how AI workloads would impact our infrastructure.
The Emergence of GPUs
Our first encounter with AI-induced infrastructure challenges actually started in the late 2010s when short-form videos were becoming very popular. The people who consumed this type of content wanted personalized recommendations – this differed dramatically from our format of ranking content to date.
Meta’s apps were built on the premise that people are part of communities with shared interests. Thus, Facebook surfaced content based on what the community liked rather than having a direct understanding of the individual and their interests. In contrast, if you want to give people an entertaining stream of short form videos, you have to be able to understand all videos uploaded to the platform and pick videos that are interesting to every single person.
This is a significantly different problem. In the first case, all we’re ranking is content that someone’s friends (typically just a few hundred people) have interacted with. In this new model, we have to rank all content that has been uploaded, which is orders of magnitude larger than the number of friends each person has. And we need to produce this ranking not just once, but a custom ranking for each person for each piece of content.
This is where GPUs and other AI accelerators enter the picture. In contrast to a CPU which is primarily a load-store machine, a GPU is a vector and matrix processing machine which can perform orders of magnitude more computation than a CPU.
When given an extremely large corpus of data, for example, a video library, we can build an embedding, which is a mathematical representation of each video as a vector of numbers. This vector captures the context of the video in a lower-dimensional space so that semantically similar content is positioned close to each other. We can now build a model that tracks the sequence of clicks a user makes as they navigate through a library of videos and predict future videos that they might be interested in. Thus, AI combines the mathematical notion of similarity in content, with the computational power of a GPU to provide personalized recommendations.
Internet services scaled throughout the 2000s and 2010s by buying CPUs/memory/hard drives that were extremely cost efficient but unreliable, and then built software systems to mask failures. In contrast, an AI cluster is a high performance computational system consisting of hundreds or even thousands of extremely powerful GPUs with ample memory interconnected with a high bandwidth, a low latency network, and a custom software stack optimized to squeeze the maximum performance out of the system.
Our initial AI clusters interconnected 4k GPUs that were used to train our ranking and recommendation models.
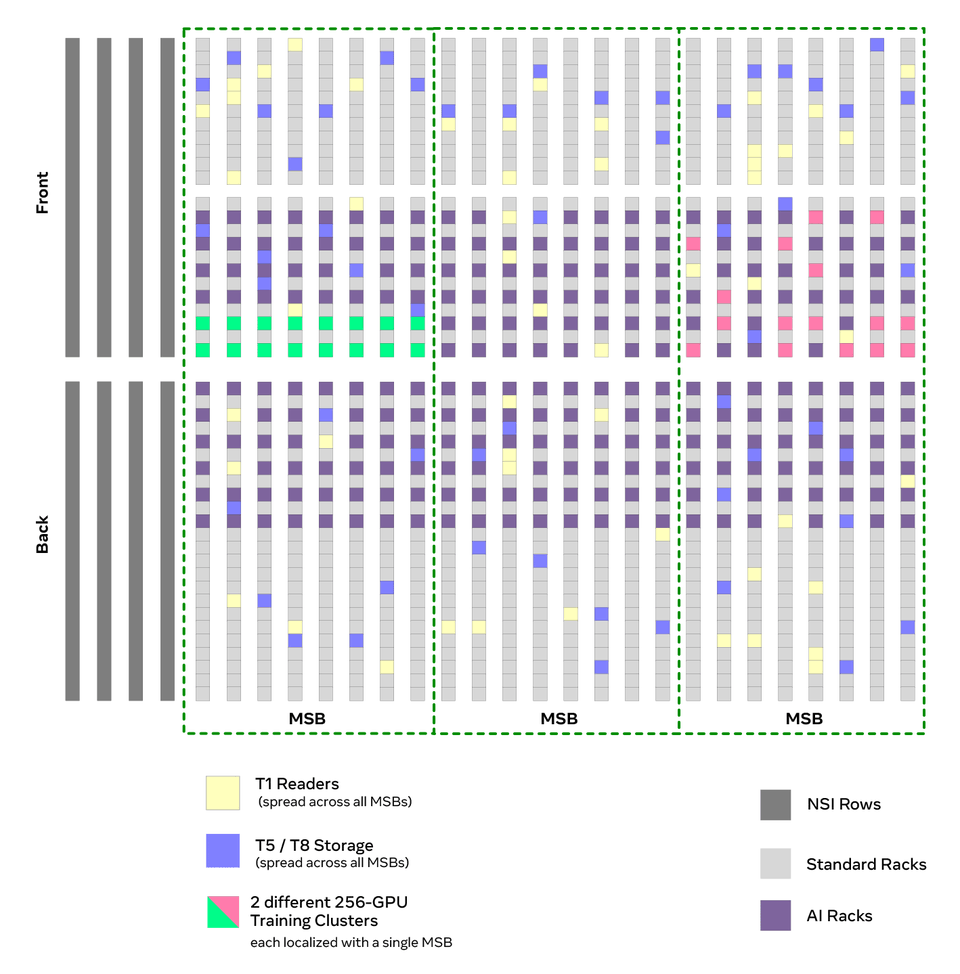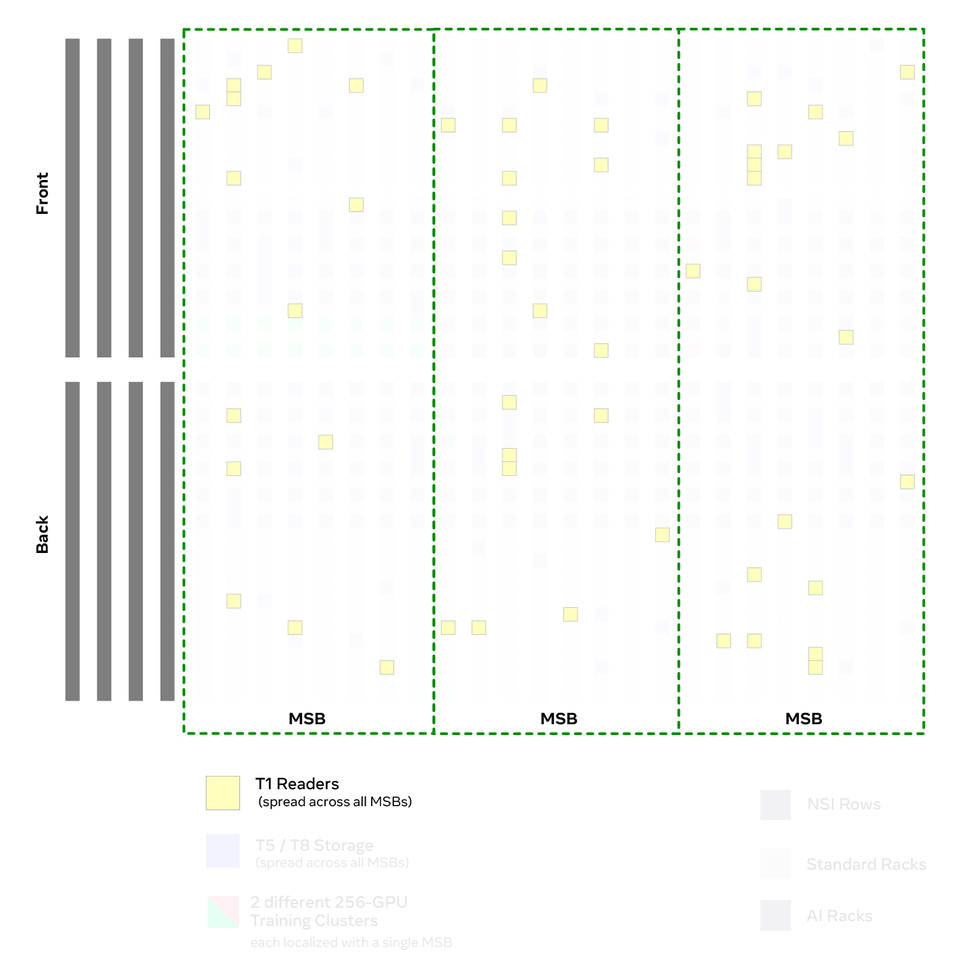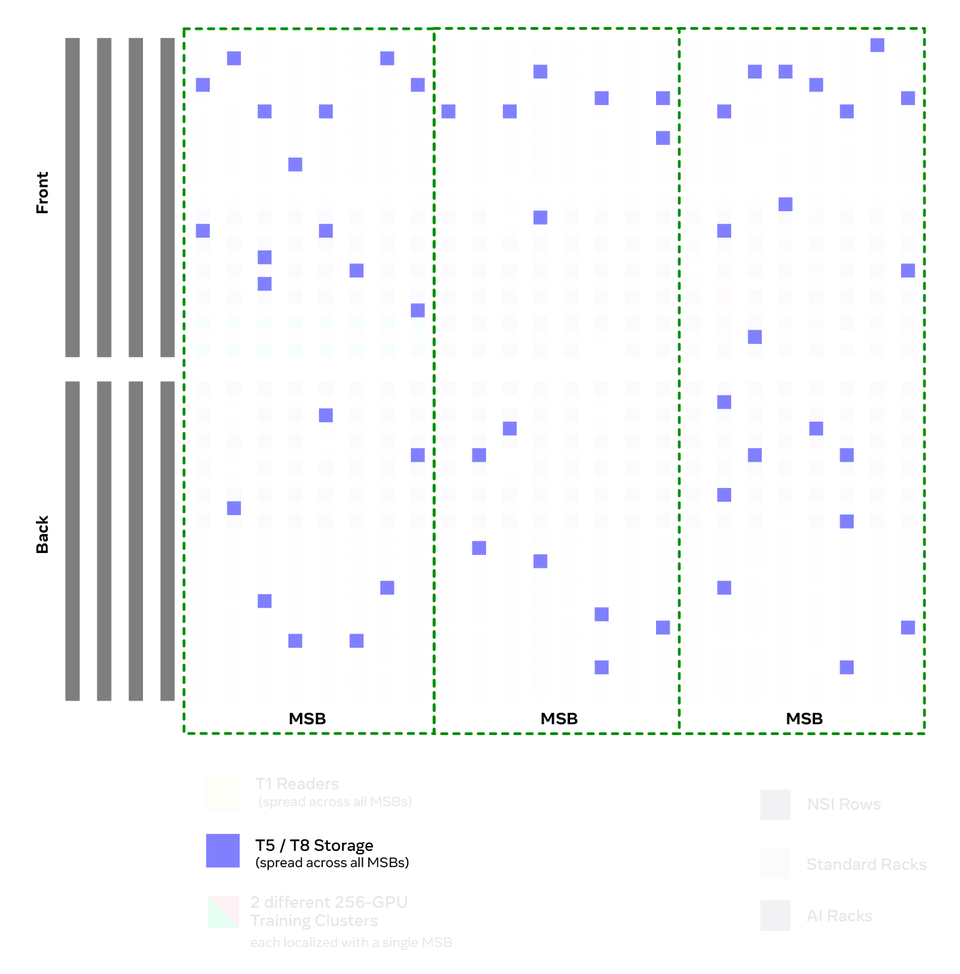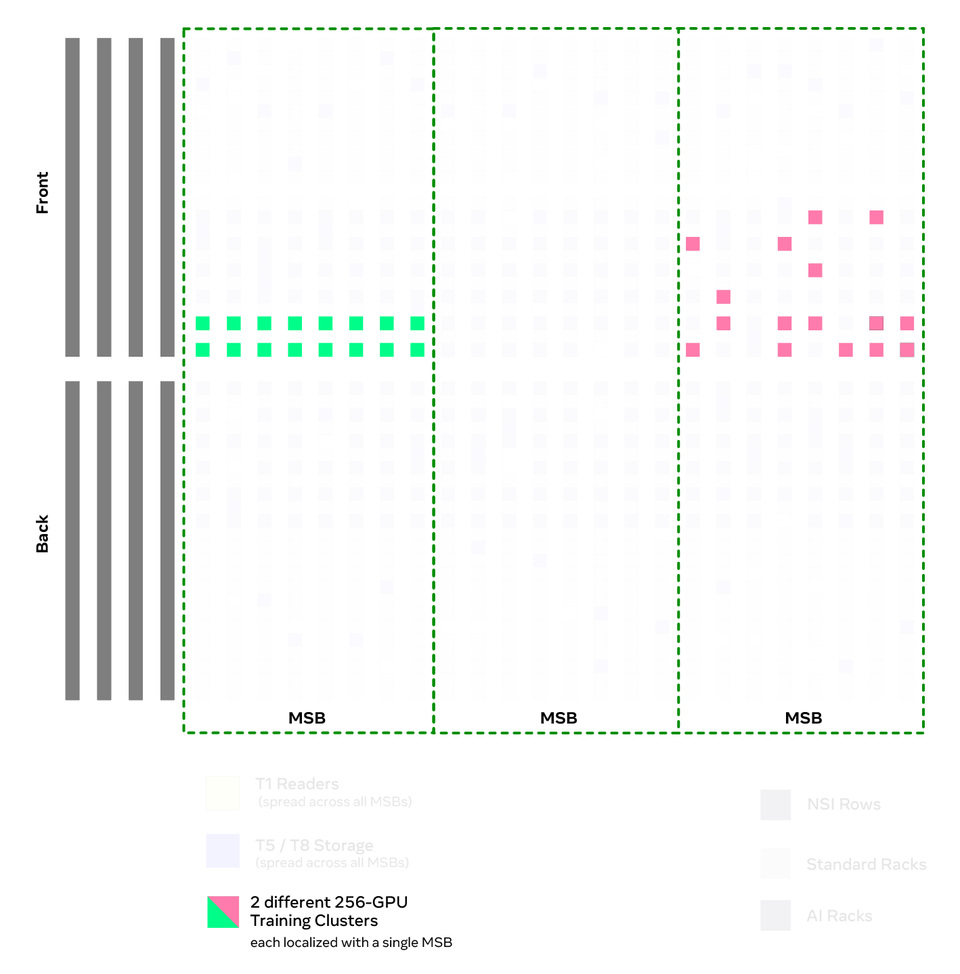
The Rise of Large Language Models (2022)
This remained the case until large language models (LLMs) started to take off in 2022. At the time, while our AI clusters were 4k in size, each of our training jobs tended to run on 128 GPUs.
When we started to train LLMs, this quickly changed.
LLMs required dramatically more compute capacity, and the more compute you were able to throw at the pretraining job, the better the model you were able to produce. In a few weeks, we had to scale our training job sizes from 128 GPUs to 2k and then 4k GPUs.
For the first time, we were regularly dealing with training jobs where we needed thousands of GPUs to run synchronously. Any single straggling GPU would hold up the performance of the entire cluster.
We quickly learned that scaling training jobs came with all kinds of challenges. GPUs can fail, memory can have errors, the network can experience jitter… And, as with traditional web workloads, the more machines you have, the more likely you are to experience failure. Except this time, it was not so easy to avoid the failures because, unlike the case of serving web requests — where you can simply retry your request on a different machine — in the case of AI training workloads, your entire training cluster is running one job, and any single failure can bring that job to a halt. If jobs fail too frequently, we stop making progress because of how long it takes to checkpoint and restart jobs. Through collaboration with the industry and our partners, we were able to drive the interruption rate down by ~50x (based on normalized interruption/reliability metrics).As we built larger clusters, we also invested in fundamental research and development across our AI Infrastructure. LLMs influenced how we developed our ranking and recommendation models. For instance, Hierarchical Sequential Transduction Units (HSTU) accelerated training and inference by 10-1000x for Generative Recommenders.
Accelerating Our GPU Scale and AI Infrastructure (2023)
As we were working to get our 4k jobs to run well, we also realized we needed to figure out how to build even larger clusters. Taking advantage of what was available to us, we designed a cluster to use all the power available in a data center building, which is typically low 10s of megawatts. This led to us to build two clusters of 24k H100s each in late 2023, one using Infiniband and the other using RoCE. This allowed us to explore different network technologies while providing our AI teams with the capacity they needed to train increasingly larger LLM models such as Llama 3.
While our two 24k clusters were amongst the largest in the world in 2023, our AI researchers were finding that the more computational power we dedicated to pre-training, the higher quality and more performant the LLM models became. Thus, our infrastructure engineers were tasked with scaling our AI cluster up by another order of magnitude.
To accomplish this, we did something we had never done in Meta’s history: As we mentioned, Meta’s data centers are usually deployed as regions of five or more identical buildings in a single location. By emptying out five production data centers we were able to build a single AI cluster with 129k H100 GPUs – all in a matter of months!

The final challenge that we are tackling is one of efficiency: What hardware and software solutions can most efficiently support the workloads we care about and maximize utilization of our data center capacity?
Unfortunately, our AI workloads are not homogenous. The ranking and recommendation models that deliver personalized user experiences on our apps have different needs than LLMs. And LLMs themselves are rapidly evolving. We are quickly moving beyond the pre-training era to one where reinforcement learning, supervised fine tuning, test time inference, and reasoning are all increasing in importance and require custom hardware and software support.
Given the size of Meta’s AI ambitions, we need to work with different vendors to encourage market diversity. We believe that having multiple options leads to a healthier ecosystem and better solutions in the long run.
To build out our AI infrastructure, we’ve leveraged solutions from partners like AMD and NVIDIA as well as our own custom silicon. The image below shows a pod consisting of six racks. The middle two racks house 72 NVIDIA Blackwell GPUs that consume ~140kW of power! We do not have facility liquid cooling in our traditional data centers, so we had to deploy four air assisted liquid cooling (AALC) racks so the heat wouldn’t melt the machines!


This pod, together, produces 360 PFLOPS of FP16 compute capacity. To put things in perspective, this pod consumes more than 800x the power a typical CPU consumes, and produces hundreds of thousand times the compute capacity! We are also starting to work with the next system, GB300, which is an improvement in many ways over GB200.
We have invested in other AI accelerators such as AMD’s MI300, which serves a variety of workloads at Meta. We have also invested heavily in the software layer to abstract away hardware differences from our developers as much as possible. Here is where open source software stacks such as PyTorch and Triton have really paid off for us.
Meta Training & Inference Accelerator (MTIA)
We have also invested heavily in developing our own silicon. The Meta Training and Inference Accelerator (MTIA) is optimized for our ranking and recommendation inference workloads. This chip is now deployed at scale in our data centers, primarily serving our ads workloads, and has given us massive benefits in efficiency over vendor silicon.
This is only the beginning of our silicon program. Our training chip for ranking and recommendations is also starting to ramp up production. And we have multiple chips in various stages of development that we expect to deploy in the next couple of years.

As we’ve been diving further into designing our own silicon we’ve encountered some scaling challenges.
The Need for Advanced Packaging Techniques
Transistors aren’t scaling at the same pace as the need for performance. Right now, reticle size is limited to 830 mm², which means that if anyone needs more performance than a single die can enable, their only option is to invest in more dies.
Working with LLMs we’ve found that the need to scale is so innate that it forces us into this exact scenario to keep up with the performance needs of each new model generation. The challenge is only compounded by the fact that these dies can only be placed adjacently through advanced 2.5D and 3D packaging, which limits the size of the arrays we can build and creates concerns around energy efficiency and cooling as well.
We suspect that, along with advanced cooling solutions, advanced packaging techniques can help overcome these challenges by integrating multiple chiplets, or diverse capabilities (compute, memory, I/O).
Investing in Solutions for Memory Disaggregation
The rise of reasoning models, test-time inference, and reinforcement learning are all adding additional pressure to memory subsystems. We are starting to stack high-bandwidth memory (HBM) adjacent to the compute chiplets to maximize I/O bandwidth. But we only have so much silicon beachfront, so we have to make hard tradeoffs between the computational capability of the chip, versus memory size, versus network bandwidth. Not to mention that adding several HBMs creates more cooling concerns.
Investing in higher performance networks instead and locating high bandwidth memory off-chip, or even off machines, might mitigate these issues.
The Case for Silicon Photonics
As we have been planning our silicon roadmap, we’ve found that the minimum power budget for each rack has grown dramatically. We’re building larger and larger interconnected chips, and that comes with increasing power demands.
Silicon photonics, which offer a range of benefits, such as allowing for faster signaling over larger distances, could significantly reduce the rack’s overall power consumption.
Advanced optical solutions like these are also the only viable path to increasing shoreline beyond 3.2T and moving beyond the constraints of backplanes required to connect more endpoints.
These solutions would come with challenges of their own, such as higher power consumption and less reliability compared to electrical signaling. Ultimately, future solutions will have to be interoperable between different technologies and vendors, more reliable than electrical signaling, and capable of being manufactured at a high volume.
We are actively engaging in research to tackle these difficult hardware challenges and collaborating with the industry ecosystem to evolve the field and develop higher performance hardware.
The Role of Open Standards in Scaling AI
While the proliferation of hardware provides options and allows us to handle workload heterogeneity by matching customized solutions that optimize for each need, they also create management challenges for hyperscalers, cloud operators, and hardware and software developers.

From an operator point of view, it is difficult for Meta to deal with 5-6 different SKUs of hardware deployed every year. Heterogeneity of the fleet makes it difficult to move workloads around, leading to underutilized hardware. It is difficult for software engineers to think about building and optimizing workloads for different types of hardware. If new hardware necessitates the rewriting of libraries, kernels, and applications, then there will be strong resistance to adoption of new hardware. In fact, the current state of affairs is making it hard for hardware companies to design products because it is difficult to know what data center, rack, or power specifications to build for.
What is needed here are open standards, open weight models, and open source software.
Open source software like PyTorch and Triton can help by providing a consistent programming interface for machine learning developers and researchers. Open weight models give application developers cost efficient access to high quality LLMs, and at the same time, give infrastructure and hardware engineers a standard workload to optimize for.
From the very beginning, we’ve been strong supporters of open hardware for data center infrastructure. We were a founding member of the Open Compute Project and continue to be a leading contributor of technical content and IP into it. Since its inception, Meta has made 187 contributions (approximately 25% of all tech contributions) to OCP. Working with the OCP community has benefited us operationally by improving consistency in our fleet, financially through economies of scale, and technologically by enabling companies to come together and debate solutions. While we’ve seen this produce great results in our general purpose compute fleet, the benefits will only be amplified in the era of AI.
Last year at the annual OCP Global Summit, for example, we unveiled Catalina, our open-design, high-powered rack for AI workloads, and a new version of Grand Teton, our AI hardware platform that features a single monolithic system design with fully integrated power, control, compute, and fabric interfaces.
But we have a long way to go in continuing to push open standards. We need standardization of systems, racks and power as rack power density continues to increase. These common abstractions help us continue to innovate quickly and deploy at scale as we build out the next generation of data centers and power grids. An example of this standardization is the recent push to adapt the Open Compute rack standards to accommodate AI needs.
We need standardization of the scale up and scale out network that these AI clusters use so that customers can mix/match different GPUs and accelerators to always use the latest and more cost effective hardware. We need software innovation and standards to allow us to run jobs across heterogeneous hardware types that may be spread in different geographic locations. These open standards need to exist all the way through the stack, and there are massive opportunities to eliminate friction that is slowing down the build out of AI infrastructure.
The Next Stage (2026 and Beyond)
No one can say for certain how the AI field will continue to evolve. Yet, what we do know is that computational capability is key to building higher quality models.
At Meta, our goal is to build models that will deliver the best, most engaging experiences, and act as personal assistants to each one of the billions of people that use our products every day.
Building the infrastructure for models this sophisticated means actively addressing challenges throughout our data centers – everything from advanced packaging, thermal management, power delivery, to memory disaggregation, while enabling scalable networks through optics.
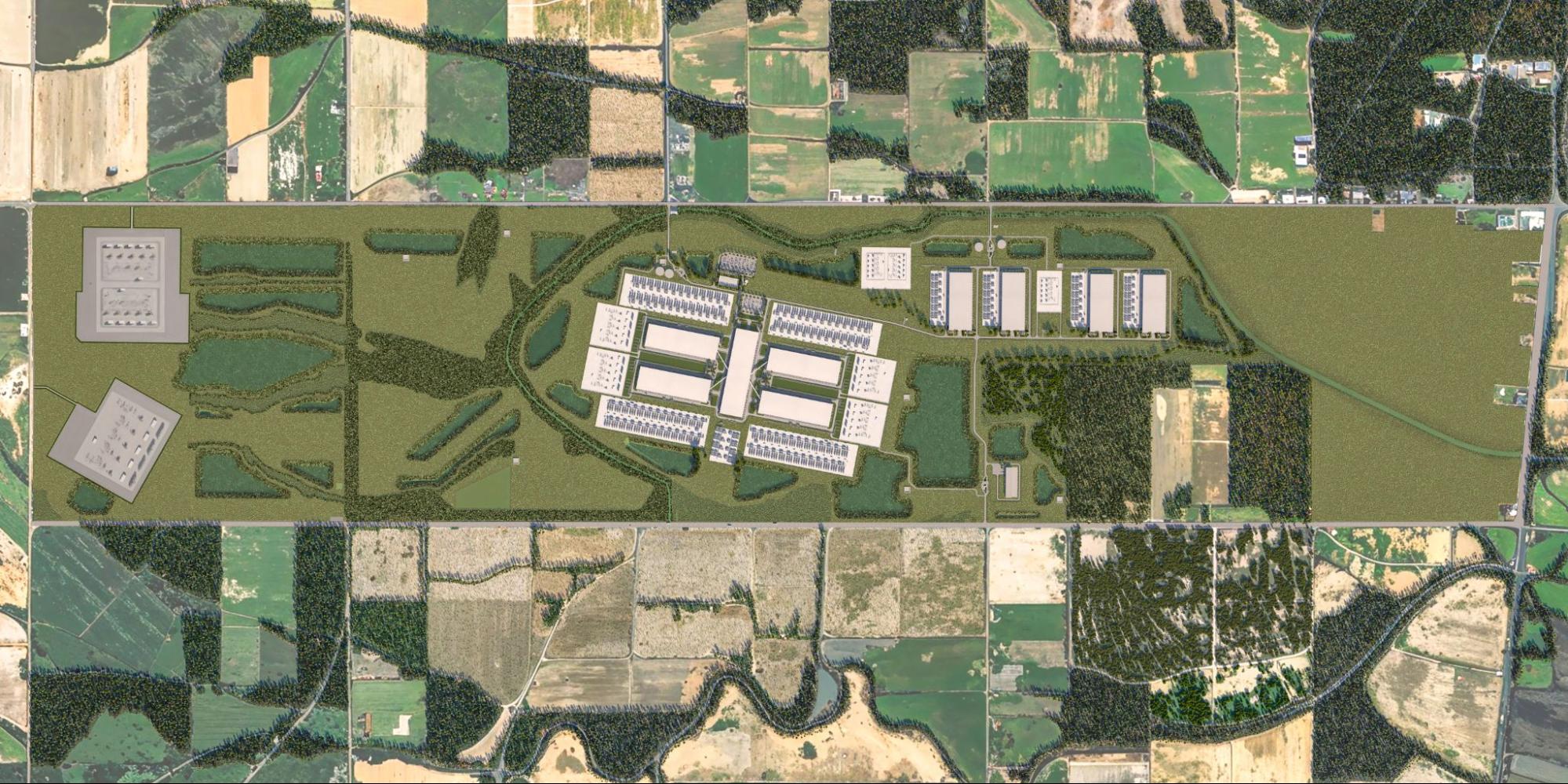
Our next AI cluster, Prometheus, will be a 1-gigawatt cluster spanning across multiple data center buildings. Constructing Prometheus has been a monumental engineering feat, with infrastructure spanning five or more data center buildings in a single data center region. While a region is large, it is a small fraction of a gigawatt facility. Thus, we needed to find innovative ways to scale: We accomplished this by building this cluster across several of our traditional data center buildings as well as several weatherproof tents, and adjacent colocation facilities. We are also evolving our software stack, including Twine and MAST, to support long-distance training across a geographically distributed set of data centers.

We also have an even larger cluster, Hyperion, expected to come online beginning in 2028. Once finished, the Hyperion cluster will have the ability to scale up to a capacity of 5 gigawatts.
We are still early in the evolution and adoption of AI workloads. The last few years have been busy, but the next few years are going to move at an even faster pace. The demands AI will push on hardware show no signs of slowing down.








