
- Hardware faults can have a significant impact on AI training and inference.
- Silent data corruptions (SDCs), undetected data errors caused by hardware, can be particularly harmful for AI systems that rely on accurate data for training as well as providing useful outputs.
- We are sharing methodologies we deploy at various scales for detecting SDC across our AI and non-AI infrastructure to help ensure the reliability of AI training and inference workloads across Meta.
Meta’s global AI infrastructure consists of a large number of hardware components and servers , connected via network fabric across globally distributed data centers. This setup integrates storage, compute, and network architectures with unique file systems and PyTorch applications tailored for training or inference workloads. This infrastructure supports training large-scale models as well as advanced AI applications such as text-to-image generation and object segmentation.
Since 2018, Meta’s hardware reliability journey has led to novel findings, identifying unique failure types in disks, CPUs, memories, switches, GPUs, ASICs, and networks, often leading the industry in discovering failure modes. We have developed mitigation policies to ensure smooth infrastructure operation and availability for billions of users and thousands of internal use cases. As we continue to build large AI clusters, understanding hardware failures and mitigation strategies is crucial for the reliable training of large-scale AI models.
Training large-scale models involves thousands of accelerators in a synchronous environment, where any component failure can interrupt or halt the process. We focus on reducing hardware failures during training through detection and diagnostics, and quickly restarting training with healthy servers and accelerators. This involves optimizing fault categorization, device triage, node selection, cluster validation, and checkpoint restore.
From our experience running the Llama 3 herd of models, we find that hardware failures in components such as SRAMs, HBMs, processing grids, and network switch hardware significantly impact AI cluster reliability, with over 66% of training interruptions due to such failures. Some of the challenges for AI clusters include accelerators that might be less reliable than CPUs due to complexity and limited telemetry, network complexity that could result in misattributed failures, and errors within the GPU software stack that may require extensive configuration to correct. Hence, reducing hardware and configuration failures greatly enhances cluster efficiency.

Types of hardware faults encountered at Meta
The hardware faults or errors that we observe in our infrastructure can be classified broadly into three categories:
Static errors
Hardware failures often appear as binary states: A device either powers on or powers off. These static errors are straightforward to identify in large-scale fleets. If devices fail to power on or enumerate, simple health checks can verify their presence and configurations. As configurations and device scales grow in large training clusters, these faults occur more frequently but are easier to triage, root-cause, and repair, making them manageable at scale.
Transient errors
Transient errors, categorized by their reproducibility, include load-dependent or partially observable faults, such as device issues from thermal runaway or random crashes from uncorrectable errors. Mitigation involves understanding manifestation conditions; and our larger scale aids in triaging and pattern matching, setting traps for these conditions. When triggered, devices are marked for mitigation or repair. Advances in RAS telemetry in hyperscale infrastructure have greatly improved this process. Factors including workload sensitivity, temperature range, frequency, and manufacturing parameters contribute to these errors.
Mitigation can also involve inducing conditions with artificial workloads in non-production stages to make faults more repeatable. Additionally, capturing transient states as “sticky” status values provides telemetry indications for hardware failures. Though less frequent than static faults and harder to detect, Meta’s scale and our significant engineering efforts have made these scenarios detectable.
Silent errors
Silent errors or silent data corruptions (SDCs) occur when hardware miscomputes without leaving detectable traces, leading applications to consume incorrect results. These errors, often due to silicon defects, can remain unnoticed for long periods unless significant deviations are observed. Detecting them requires extensive engineering and costly telemetry to trace data corruption back to specific devices. These faults significantly impact large-scale services due to the lack of telemetry and continued consumption.
Case studies, including one where a single computation error led to missing rows in a Spark application, highlight the prevalence of silent errors in hyperscale infrastructures. Historically, soft-error-related bitflips were reduced to one fault per million devices, but with increased silicon density in accelerators, silent data corruptions now occur at about one fault per thousand devices, much higher than cosmic-ray-induced soft errors.
Key challenges presented by SDCs
SDCs present significant challenges in hyperscale infrastructure due to their data dependency, creating an impractical exponential test space for all possible data values. These faults also depend on device voltage, frequency, operating temperature, and life cycle. For instance, a device may fail computational checks only after months of use, indicating a state of “wear out.” Therefore, consistent, periodic, and frequent testing within a random state space is necessary throughout the device’s life cycle to identify these inaccuracies.

Novel SDC detection mechanisms
To protect applications from silent data corruption, Meta employs several detection mechanisms, as detailed in the papers, “Detecting Silent Errors in the Wild” and “Hardware Sentinel.”
- Fleetscanner: Fleetscanner captures performance outliers at scale with targeted micro-benchmarks for identifying hardware defects. These benchmarks’ signatures are integrated into telemetry for non-benchmark-based detection. This approach involves running directed tests during maintenance operations such as firmware upgrades and hardware repairs. Tests are scheduled periodically, covering the entire fleet every 45 to 60 days. While it provides dedicated testing on hosts, it may be too slow for some SDCs.
- Ripple: Ripple co-locates with workloads, executing tests in milliseconds to seconds, allowing fleet-wide coverage in days. It overlaps test instructions across cores and threads, providing faster detection than Fleetscanner.
- Hardware Sentinel: This novel, test-and-architecture-agnostic approach evaluates application exceptions in kernel space. It identifies core-based anomalies as silent data corruption without requiring test allocations, operating solely in the analytical plane. Hardware Sentinel outperforms testing-based methods by 41% across architectures, applications, and data centers.
Combined together, these three mechanisms provide one of the best in-fleet coverage at scale, for detecting and protecting our infrastructure against SDCs.
Silent errors in AI hardware
The methodologies described above execute across the fleet and are fully productionized at scale, detecting SDCs across AI and non-AI infrastructure. However, AI applications such as training and inference have unique and more challenging implications for SDCs.
SDCs in training workloads
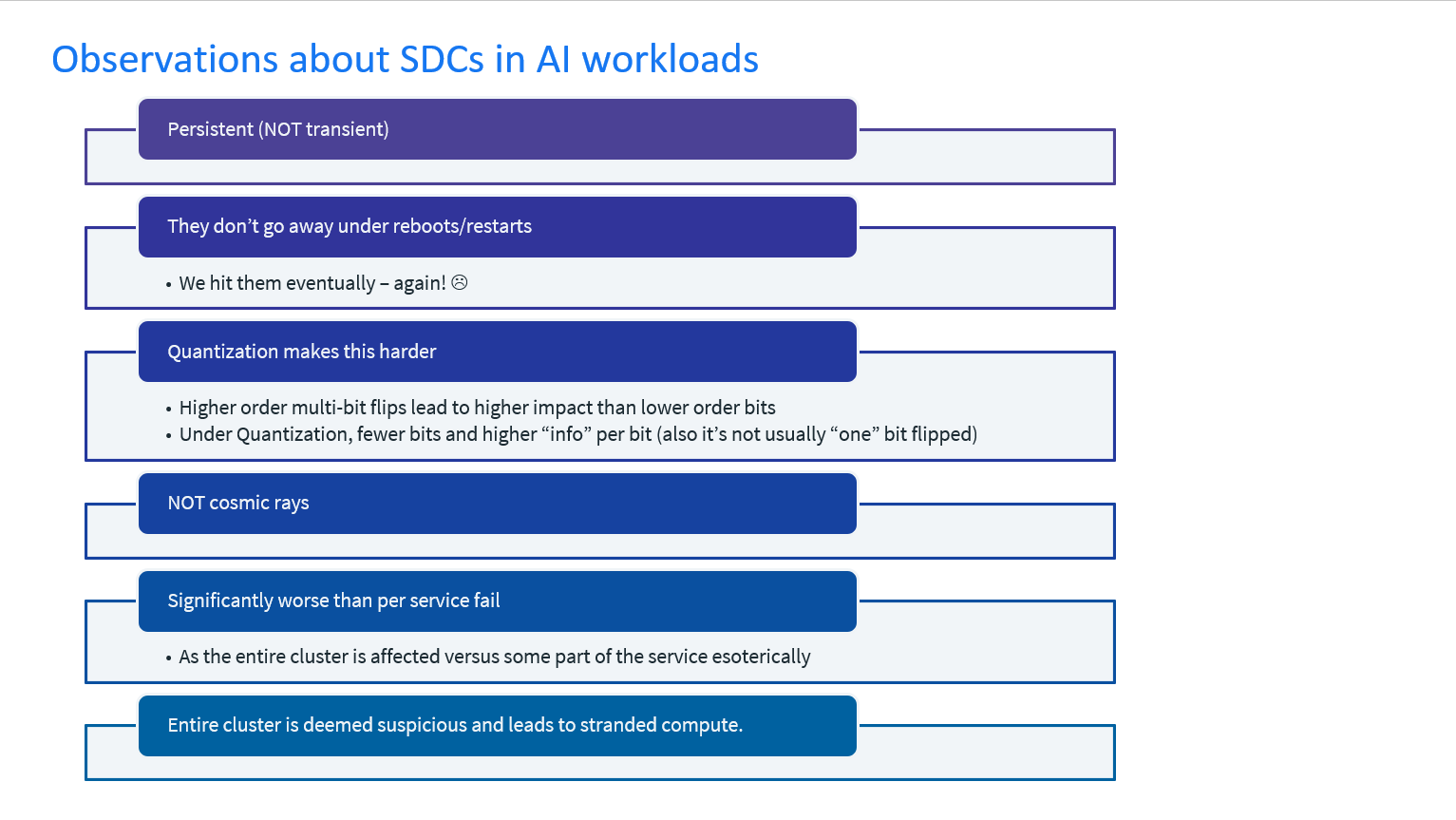
SDCs in training workloads lead to incorrect computations, affecting both forward and backward passes. This results in a divergence from the intended training path, impacting training efficacy. While AI training workloads are sometimes considered self-resilient to SDCs, this is true only for a limited subset of SDC manifestations. In most realistic scenarios, self-resilience is inadequate. SDCs persist across iterations, and the quantization of data values in AI training, which increases information per bit, exacerbates the impact of SDCs, continuously increasing divergence rates in training workloads.
Below we present the two most common cases of training divergence due to SDCs.
Not-a-Number (NaN) propagation
Not-a-Number (NaN) propagation occurs when an SDC pushes a representable value into an incorrect representation, generating a NaN during training computations. Once a NaN is created, it propagates through subsequent computations, affecting the training iteration, accelerator domain, host domain, and eventually the entire cluster. This widespread NaN contagion can lead to a cluster halt, as the source—often a few specific computations on a single accelerator—may be difficult to trace amidst the cluster’s scale. Identifying and quarantining the offending accelerator and nodes are necessary to resolve the issue.
Corrupted gradient variance
Corrupted gradient variance occurs when an SDC affects gradient calculations, leading to gradient explosion, implosion, or local minima. This corruption, while within numeric bounds, is mistakenly treated as correct, affecting the entire cluster in synchronous training. The corrupted values are exchanged as true values, causing the training to appear to progress without actual improvement. Over time, SDCs aggregate, causing major divergences in gradients, potentially trapping the algorithm in local minima or causing gradient explosions or implosions.
Detecting these SDCs is challenging due to their subtlety and the time required to observe their effects, which can take weeks or months. Unlike NaN propagation, these corruptions are harder to trace and rectify, as they don’t trigger NaN traps. Consequently, SDCs can lead to significant unproductive use of computational resources and training iterations. Without detection, the root cause remains elusive, making subsequent training risky until the offending device is identified and isolated.
SDCs in inference workloads
In inference applications, SDCs lead to incorrect results, which, due to the scale of operations, affect thousands of inference consumers. Persistent SDCs can directly impact decisions made by systems such as recommendation engines or LLM outputs. These corruptions can bypass policies related to privacy or integrity, as they are not constrained by boundaries. Consequently, inference corruptions significantly reduce the efficacy of models trained with substantial computational resources, making seemingly benign inference use cases problematic at scale.
Impact of SDCs
SDCs in training and inference clusters create complex debugging scenarios across thousands of components.
In training, visible faults halt the cluster, but SDCs create an illusion of progress, obscuring the fault source. NaN propagation requires identifying the offending node; otherwise, restarts from checkpoints will eventually fail. Corrupted gradient variance prolongs this illusion until variances aggregate, making restarts ineffective. SDCs thus cause significant computational inefficiency, with a larger temporal impact than visible faults.
In inference, triage involves costly telemetry at each substage. Until the offending node is identified, inference clusters can’t be used, risking repeat corruption. Large deviations are easier to detect with anomaly detectors, but smaller ones require extensive debugging. This process involves hundreds of engineers, halting production use cases, and impacting reliable capacity for serving production.
Detection of SDCs in AI hardware
Mitigation strategies that we run in our infrastructure for dealing with SDCs in AI training workloads are classified into infrastructure strategies and stack strategies:
Infrastructure strategies
These are applied during operational triage at the cluster level. They focus on managing and mitigating SDCs through the physical and network infrastructure, ensuring that the hardware and system-level components are robust and capable of handling errors effectively.
Reductive triage
This strategy involves conducting a binary search with mini-training iterations on progressively smaller cluster sizes to isolate NaN propagation. The goal is to identify a small cluster that replicates the NaN issue, allowing the offending node to be quarantined for further investigation. A reconstituted cluster with new nodes can then resume training from a saved checkpoint. However, this method relies on the ability to reproduce SDCs, which is not always guaranteed due to their dependence on data, electrical, and temperature variations. For corrupted gradient variance, a similar divide-and-triage approach can be used, but the effectiveness varies with training data and cluster size, despite consistent hyperparameter settings.
Deterministic training
This approach involves running a known effective model for a few training iterations to ensure there are no NaNs or gradient divergences. It helps verify computational failures that are not data-dependent, as it guarantees correctness for a specific set of values and training inputs.
Hyper-checkpointing
This method involves creating checkpoints at increasingly high frequencies to facilitate faster identification and isolation of the corrupting node. It helps maintain training throughput while containing NaN propagation to a specific accelerator or host, thereby speeding up the triage and quarantine process.
Stack strategies
These require coordination with the workload and involve adjustments and enhancements at the software-stack level. This includes implementing error detection and correction mechanisms within the application and software layers to handle SDCs more effectively during training processes.
Gradient clipping
This strategy involves enforcing gradient clipping within the training workload to limit values within a specified range, thereby mitigating NaN propagation. Computations exceeding this range are clipped, and NaNs can be detected during this step by setting them to a max or min value based on the operand sign. While effective for some NaNs depending on representation format, it may introduce partial errors in certain cases.
Algorithmic fault tolerance
This robust approach integrates fault tolerance into training algorithms to handle a range of data corruptions, reducing the need for detection and triage. It enhances computational efficiency with minimal overhead, as demonstrated in CPU training. This method requires understanding common defect modes and investing in engineering across the stack, with modified guarantees to training workloads, albeit with some overhead to the overall training footprint.
Tri-variate computational training architecture
This approach uses shadow nodes in synchronous training to mitigate SDCs. Training steps are repeated across different nodes at random iterations, ensuring correct progress after verification. If shadow and live nodes differ, training halts, and only those nodes are investigated. The rest continue with new nodes. This method involves multiple shadow-node pools, a random training-node pool, and specified steps from the same checkpoint. It offers robust training but demands significant algorithmic changes and increased data movement and infrastructure overhead.
Parameter vulnerability factors
This approach identifies vulnerable and resilient layers in machine-learning architectures, allowing mapping of vulnerable layers to resilient hardware and resilient layers to unprotected hardware. This dynamic evaluation must scale with architecture evolution. Resilience often incurs costs in area, power, or performance, so PVF enables targeted resilient design, especially for inference.
Divergence detection
This mechanism maintains a distribution map for each neuron to detect divergence from typical output distributions, identifying inference corruptions. Though costly, it can be applied at selected sampling rates for large-scale inference. By preserving each neuron’s behavior for specific workloads, divergence helps detect corruptions during execution.
While we have optimized these different methodologies to run effectively in our infrastructure, it should be noted that they offer varying levels of resilience with distinct operating points and engineering/infrastructure overheads. Depending on the scale and intensity of training and inference workloads, orchestrating these strategies effectively can mitigate SDCs’ adverse effects in AI applications.
Performance faults and unknown unknowns!
While SDCs are a major challenge at hyperscale, Meta has been developing solutions to detect performance regressions. ServiceLab, for example, is a large-scale performance testing platform that helps identify tiny performance regressions at scale. In addition, Fleetscanner has identified hundreds of performance outliers, seen as an emergent fault mode alongside SDCs.
While current mechanisms detect and address static, transient, and silent faults, the full range of hardware fault variants remains partially uncovered. The unknown unknowns require agile solutions across the entire infrastructure and silicon lifecycle, as well as across the hardware-to-software and application stack, to achieve first-class reliability operations.
A journey towards industry leadership and standardization
Meta’s journey toward industry leadership in SDC began with identifying frequent fleet issues in 2016, scaling SDC detection in 2018, and implementing detection frameworks by 2019. By 2020, detection mechanisms were integrated into accelerators, and Meta published the paper, “Silent Data Corruptions at Scale.” In 2022, Meta introduced “FleetScanner and Ripple” and conducted an RFP for academic awards, funding five winners.
In 2023, Meta collaborated with industry leaders (Google, Microsoft, ARM, AMD, NVIDIA, and Intel) to enhance server resilience, defining test architectures and metrics. A joint RFP with partners from the Open Compute Project selected six winners for cross-domain SDC research. By 2024, Meta’s fleet had advanced AI SDC detection methodologies in production, contributing to research through publications, tutorials, and talks at major conferences and forums, addressing at-scale reliability challenges.

The Meta Training and Inference Accelerator
Meta is on an ambitious journey toward enabling training and inference accelerators under the Meta Training and Inference Accelerator (MTIA) family. On this journey, our goal is to utilize all the lessons learned from the fleet and move toward industry-leading, fleet-reliability practices in MTIA architecture and design practices. Using the factory-to-fleet approach, and consistently revisiting our reliability solutions across the stack, our goal is to deliver a best-in-class, reliable-and-performant solution to add to our infrastructure portfolio of AI hardware and to power AI applications at scale.
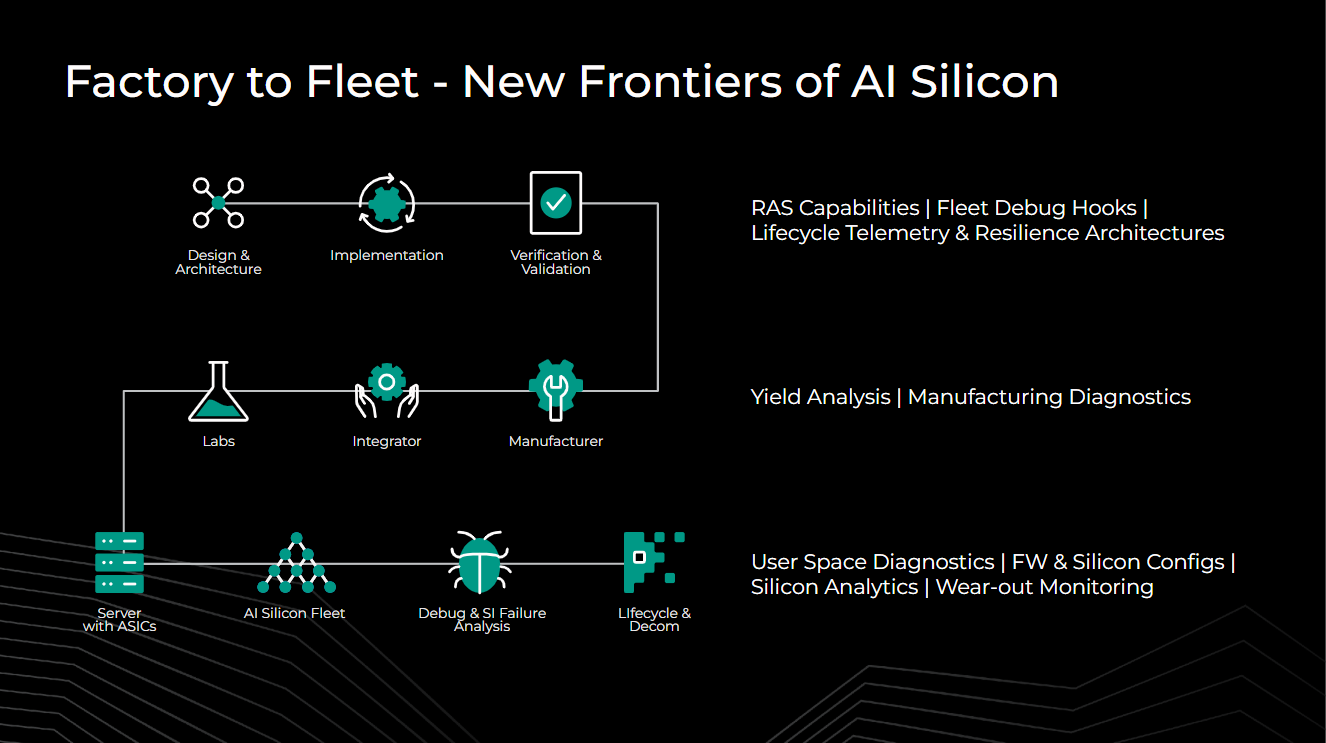
Factory to fleet
To uncover unknowns early, a comprehensive factory-to-fleet view of the silicon life cycle is key. Innovation is needed in all phases, from design to deployment. In design and architecture, revisiting RAS solutions for scale, life-cycle debug hooks, and telemetry architectures can support tools such as Hardware Sentinel, Fleetscanner, and Ripple. During validation and integration, novel yield analysis, manufacturing diagnostics, and fleet-signature-feedback-based detection can prevent faults before shipping. In AI silicon fleets, user-space diagnostics with periodic testing, coverage maps, and control parameters are beneficial. Large-scale analytics like Hardware Sentinel can detect early wear out and data corruption. Robust firmware hooks and debug architecture provide fast feedback to design and architecture amidst fleet-scale issues.
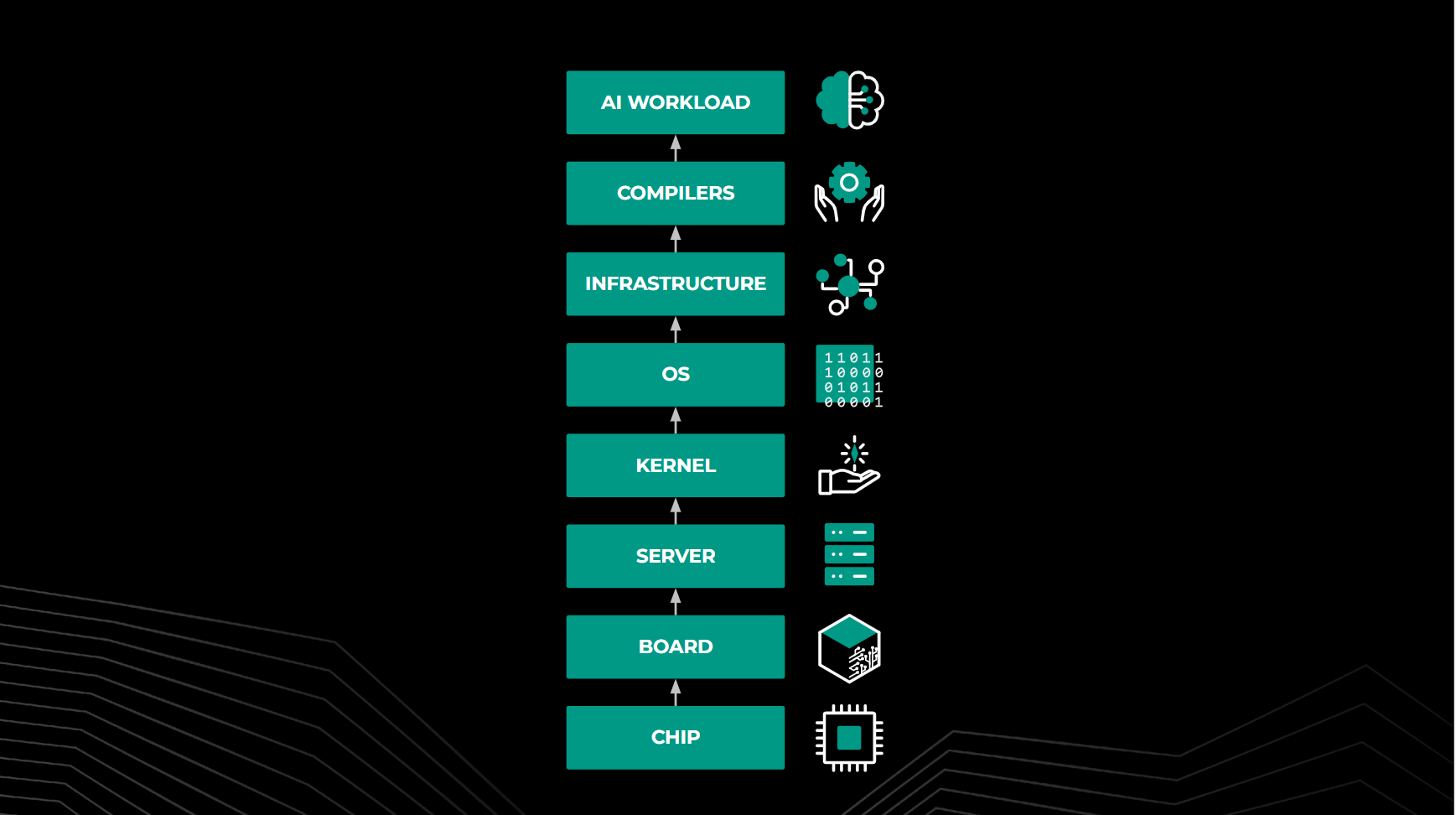
Stack-level resilience
Factory-to-fleet solutions offer life-cycle resilience for silicon, but resilience must extend beyond silicon to firmware, compilers, kernels, and operating systems. Investments in resilience architectures are needed for correctness-invariant-instruction heterogeneity and enhanced telemetry for exception tracing. Granular firmware-control mechanisms improve telemetry upon fault detection. At the software and application level, techniques like gradient clipping and algorithmic fault tolerance that we called out in this blog, are crucial for security amidst corruptions. Experience with SDCs shows that in-line software resilience and test-agnostic analytical approaches effectively scale for many SDCs with minimal investment, while testing-based approaches are limited to specific instructions.
Hardware faults significantly impact AI training and inference production. As cluster sizes and semiconductor complexity grow, fault complexity will exponentially increase. Solutions must involve factory-to-fleet coordination and stack-level resiliency. For AI applications, treating reliability as a primary design consideration is essential.
Acknowledgments
The authors would like to thank all the cross-functional engineers and teams instrumental in landing these solutions over the years. This blog accompanies the @Scale conference talk, please check out the talk for more details.








