
- We’re introducing Arcadia, Meta’s unified system that simulates the compute, memory, and network performance of AI training clusters.
- Extracting maximum performance from an AI cluster and increasing overall efficiency warrants a multi-input system that accounts for various hardware and software parameters across compute, storage, and network collectively.
- Arcadia gives Meta’s researchers and engineers valuable insights into the performance of AI models and workloads in an AI cluster – enabling data-driven decision making in the design of AI clusters.
AI plays an important role in the work we do at Meta. We leverage AI to deliver more personalized experiences and recommendations for people across our family of apps. We’re also committed to advancing the state-of-the-art in generative AI, computer vision, new augmented reality (AR) tools, natural language processing (NLP), and other core areas of AI for a wide range of applications.
Delivering on these commitments means maximizing the performance of every GPU within our AI clusters across three performance pillars: Compute, memory, and network.
Within these pillars, AI cluster performance can be influenced by multiple factors, including model parameters, workload distribution, job scheduler logic, topology, and hardware specs. But focusing on these pillars in isolation leads to local performance optimization efforts that are unable to tap into the full extent of cluster performance. From an organizational perspective, this further leads to decreased efficiencies because multiple efforts with the same goal of increasing cluster performance aren’t being holistically prioritized. These challenges will only grow as large language models (LLMs) become more prevalent.
We need a systemized source of truth that can simulate various performance factors across compute, storage, and network collectively. That’s where Arcadia, Meta’s end-to-end AI system performance simulator, comes in. Arcadia is designed to create a unified simulation framework that accurately models the performance of compute, memory, and network components within large-scale AI training clusters. Using insights from Arcadia, our engineers and developers can make data-driven design decisions for AI clusters and infrastructure that supports it while they are being developed.
Challenges of optimizing AI clusters
When we think about optimizing our AI clusters, there are several factors to take into consideration:
- Our large-scale distributed system: Advancement in any area of AI, whether it is computer vision, speech, or NLP requires training large and complex models. At Meta, this is facilitated by multiple high performing computing infrastructure clusters. For instance, the AI Research SuperCluster for AI research.
- Our multi-layered system: At Meta, we control the stack from physical network to applications. This translates into multiple tunable parameters across network, compute, memory, application, and scheduling to achieve the desired model performance. Finding the right set of parameters and inputs for achieving good model performance is an iterative task that can increase training time significantly.
- Our operational workflows: The availability of the underlying infrastructure is a major factor that can influence model training time. For instance, a component failure can trigger a job to be rolled-back to a previous checkpoint and progress made would be lost. At our scale, operating such clusters without operational awareness data can lead to performance losses.
- AI workload characteristics: Our training clusters cater to workloads across multiple use cases that may exhibit different sets of characteristics ranging from memory and compute-intensive, to latency-sensitive, and parallelizable. Keeping track of these characteristics across multiple workloads is already challenging. But the problem’s complexity increases by an order of magnitude due to uncertainty around future workloads and predicting various workloads for optimum performance.
- The need for a common source of truth: Interdisciplinary research efforts, such as AI cluster-performance optimization, span multiple teams across network, compute, and storage. These teams may be working on outdated assumptions about other pillars as they drive their own local optimization efforts. Lack of a holistic approach in such cases often leads to organizational inefficiencies such as decision-making challenges and duplicative efforts.
The Arcadia system
Our primary objective with Arcadia is to develop a multi-disciplinary performance analysis system that enables design and joint optimization across various system levels, including application, network, and hardware.
Arcadia empowers stakeholders to examine and enhance different aspects such as machine learning (ML) model architectures, collective algorithms, job scheduling, hardware, and network architecture design. By providing insights into the impact of these factors on system performance, Arcadia facilitates data-driven decision-making processes and fosters the evolution of models and hardware.
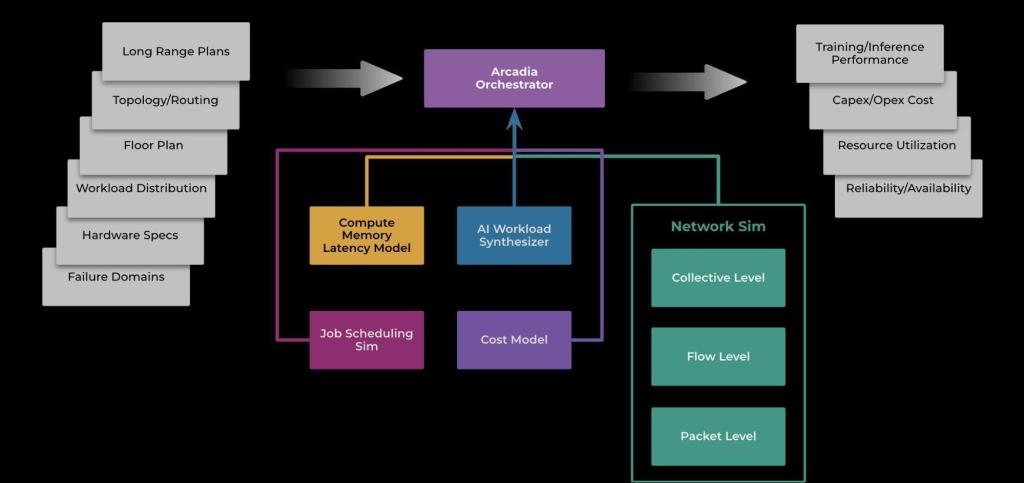
Inputs
As shown in the architecture design above, the input to the Arcadia system encompasses a range of essential parameters, including the long-range plans of AI systems and models, network topology and routing protocols, data center floor plans, AI workload distributions, and hardware specifications. Additionally, Arcadia considers failure domains to provide a holistic view of the system’s performance and reliability.
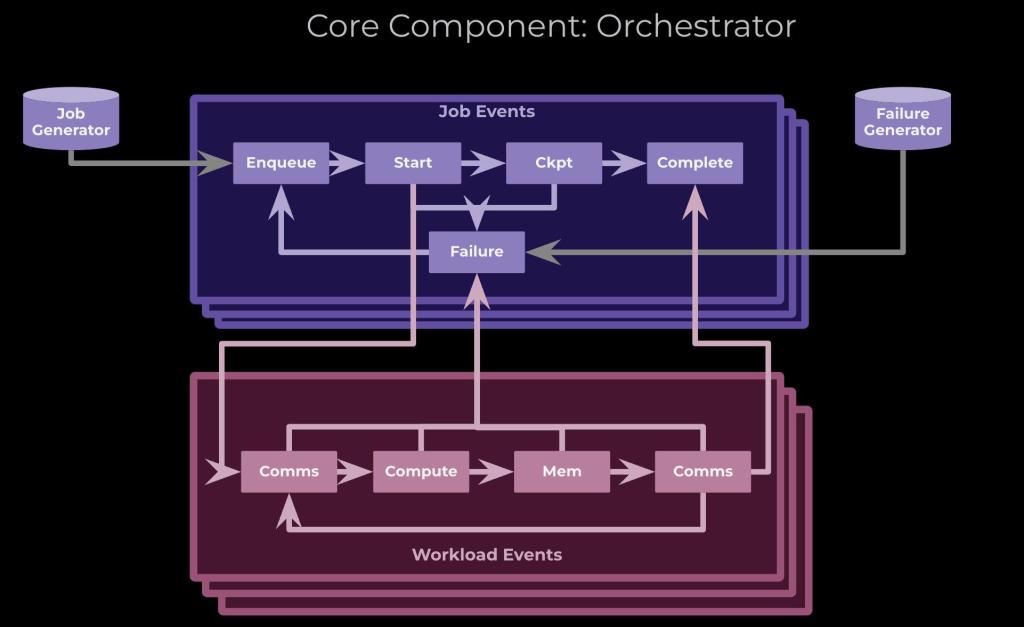
Core
At the core of Arcadia is an orchestrator that coordinates the simulation of various components, including job scheduling, compute and memory, and network behavior at different levels. The system employs an AI workload synthesizer that learns from production distributions and generates representative workloads as inputs, ensuring the simulation reflects real-world conditions.
Outputs
Arcadia offers a wide range of outputs, including AI training and inference performance metrics, resource utilizations, and reliability and availability metrics. This comprehensive set of metrics empowers stakeholders to analyze the impact of different factors and make informed decisions to optimize system performance.
Feedback Loop
Unlike analytical roofline estimates, Arcadia takes into account the network and compute feedback loop, providing accurate estimations of performance that align with real-world production measurements. This capability allows for more precise predictions and a better understanding of the expected performance of AI models and workloads on a given infrastructure.
Arcadia’s benefits
Arcadia provides operational insights and a level of flexibility in simulation that allows us to address several challenges around optimizing our clusters.
Operational workflows benefit significantly from Arcadia’s simulation capabilities, providing enhanced visibility and a deeper understanding of risk and mitigation plans. Simulation-based audits for AI/HPC network maintenance can be conducted to identify potential issues and devise appropriate solutions. Maintenance scheduling can be optimized by leveraging Arcadia’s insights, ensuring minimal disruption to AI/HPC jobs. Furthermore, Arcadia aids in debugging and root-causing production events, enabling efficient troubleshooting and preventing recurrence of issues.
Arcadia offers flexibility in terms of simulation detail levels, catering to different user requirements and purposes. Users who focus solely on the application level can disregard lower-level details, enabling faster simulation runs. On the other hand, for example, users requiring in-depth analysis of low-level network hardware behaviors can leverage Arcadia’s packet-level network simulation to extract detailed insights.
Furthermore, Arcadia serves as a single source of truth that is agreed upon by all stakeholders. This unified approach helps ensure consistent and reliable performance analysis across teams and disciplines, establishing a common framework for hardware, network, job-scheduling, and AI systems co-design.
Use cases for Arcadia
There are several use cases for Arcadia system in pursuit of large-scale, efficient high-performance clusters:
- Cluster utilization and fragmentation insights
- Measuring the impact of network and hardware on AI/HPC job performance
- AI/HPC job profile analysis in the training clusters
- Assessing the reliability, availability, and efficiency of training clusters
- Optimization of training cluster maintenances
- Optimization of AI/HPC job scheduling and configurations
Next steps for Arcadia
As we build out more use cases for Arcadia we’re also developing additional frameworks to expand on its capabilities. This will include a framework to support operational cases in production networks, such as optimizing training cluster maintenance and AI/HPC job scheduling and configurations.
We’re also investigating a framework to provide design insights for different topology/routing designs given a set of known models. This would be used to surface key bottlenecks in compute, memory, or network and provide insights on how different model parameters can be optimized for a given cluster.
Finally, we’re aiming for Arcadia to support inputs from Chakra, an open, graph-based representation of AI/ML workloads being developed in a working group in MLCommons.
Acknowledgments
Many people contributed to this project but we’d particularly like to thank Naader Hasani, Petr Lapukhov, Mikel Jimenez Fernandez, Thomas Fuller, Xin Liu, Greg Steinbrecher, Yuhui Zhang, Max Noormohammadpour, Mustafa Ozdal, Kapil Bisht, Phil Buonadonna, Josh Gilliland, Abishek Gopalan, Biao Lu, Gaya Nagarajan, Steve Politis, Kevin Quirk, Jimmy Williams, Yi Zhang, and Ying Zhang.








