
- We’ve made architecture changes to Meta’s event driven asynchronous computing platform that have enabled easy integration with multiple event-sources.
- We’re sharing our learnings from handling various workloads and how to tackle trade offs made with certain design choices in building the platform.
Asynchronous computing is a paradigm where the user does not expect a workload to be executed immediately; instead, it gets scheduled for execution sometime in the near future without blocking the latency-critical path of the application. At Meta, we have built a platform for serverless asynchronous computing that is provided as a service for other engineering teams. They register asynchronous functions on the platform and then submit workloads for execution via our SDK. The platform executes these workloads in the background on a large fleet of workers and provides additional capabilities such as load balancing, rate limiting, quota management, downstream protection and many others. We refer to this infrastructure internally as “Async tier.”
Currently we support myriad different customer use cases which result in multi-trillion workloads being executed each day.
There is already a great article from 2020 that dives into the details of the architecture of Async tier, the features it provided, and how these features could be applied at scale. In the following material we will focus more on design and implementation aspects and explain how we re-architected the platform to enable five-fold growth over the past two years.
General high-level architecture
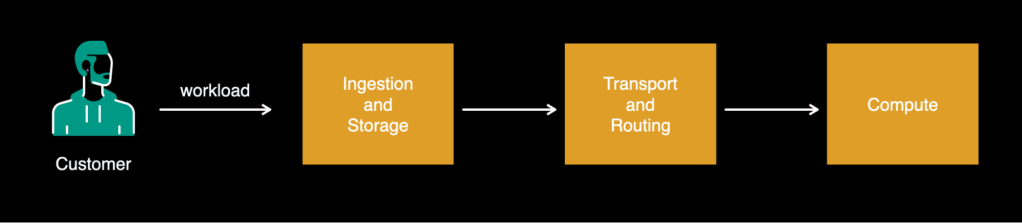
Any asynchronous computing platform is composed of the following building blocks:
- Ingestion and storage
- Transport and routing
- Computation
Ingestion and storage
Our platform is responsible for accepting the workloads and storing them for execution. Here, both latency and reliability are critical: This layer must accept the workload and respond back ASAP, and it must store the workload reliably all the way to successful execution.
Transport and routing
This deals with transferring the adequate number of workloads from storage into the computation layer, where they will be executed. Sending inadequate numbers will underutilize the computation layer and cause an unnecessary processing delay, whereas sending too many will overwhelm the machines responsible for the computation and can cause failures. Thus, we define sending the correct number as “flow-control.”
This layer is also responsible for maintaining the optimal utilization of resources in the computation layer as well as additional features such as cross-regional load balancing, quota management, rate limiting, downstream protection, backoff and retry capabilities, and many others.
Computation
This usually refers to specific worker runtime where the actual function execution takes place.
Back in 2020
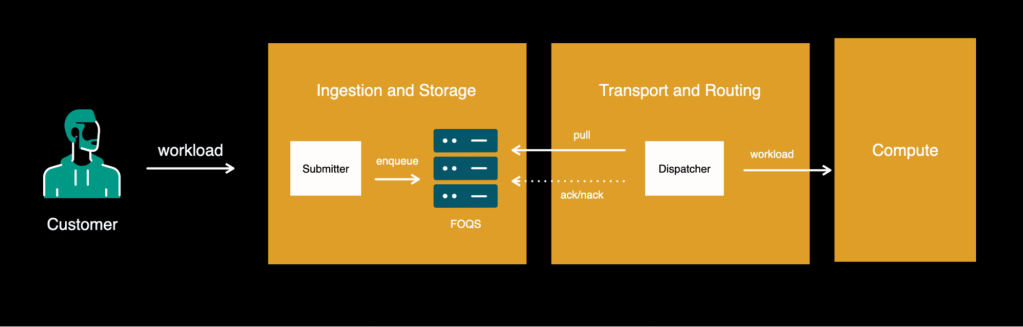
In the past, Meta built its own distributed priority queue, equivalent to some of the queuing solutions provided by public cloud providers. It is called the Facebook Ordered Queuing Service (since it was built when the company was called Facebook), and has a famous acronym: FOQS. FOQS is critical to our story, because it comprised the core of the ingestion and storage components.
Facebook Ordered Queuing Service (FOQS)
FOQS, our in-house distributed priority queuing service, was developed on top of MySQL and provides the ability to put items in the queue with a timestamp, after which they should be available for consumption as an enqueue operation. The available items can be consumed later with a dequeue operation. While dequeuing, the consumer holds a lease on an item, and once the item is processed successfully, they “ACK” (acknowledge) it back to FOQS. Otherwise, they “NACK” (NACK means negative acknowledgement) the item and it becomes available immediately for someone else to dequeue. The lease can also expire before either of these actions takes place, and the item gets auto-NACKed owing to a lease timeout. Also, this is non-blocking, meaning that customers can take a lease on subsequently enqueued, available items even though the oldest item was neither ACKed nor NACKed. There’s already a great article on the subject if you are interested in diving deeply into how we scaled FOQS.
Async tier leveraged FOQS by introducing a lightweight service, called “Submitter,” that customers could use to submit their workloads to the queue. Submitter would do basic validation / overload protection and enqueue these items into FOQS. The transport layer consisted of a component called “Dispatcher.” This pulled items from FOQS and sent them to the computation layer for execution.
Challenges
Increasing complexity of the system
Over time we started to see that the dispatcher was taking more and more responsibility, growing in size, and becoming almost a single place for all the new features and logic that the team is working on. It was:
- Consuming items from FOQS, managing their lifecycle.
- Protecting FOQS from overload by adaptively adjusting dequeue rates.
- Providing all regular features such as rate limiting, quota management, workload prioritization, downstream protection.
- Sending workloads to multiple worker runtimes for execution and managing job lifecycle.
- Providing both local and cross-regional load balancing and flow control.
Consolidating a significant amount of logic in a single component eventually made it hard for us to work on new capabilities in parallel and scale the team operationally.
External data sources
At the same time we started to see more and more requests from customers who want to execute their workloads based on data that is already stored in other systems, such as stream, data warehouse, blob storage, pub sub queues, or many others. Although it was possible to do in the existing system, it was coming along with certain downsides.
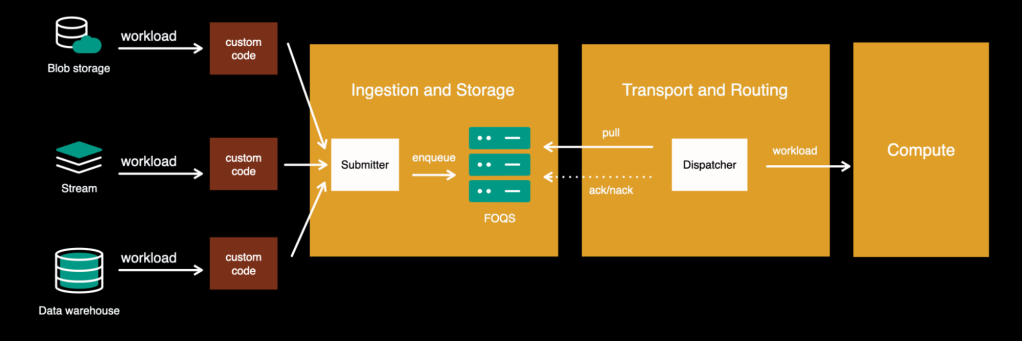
The limitations in the above architecture are:
- Customers had to write their own solutions to read data from the original storage and submit it to our platform via Submitter API. It was causing recurrent duplicate work across multiple different use cases.
- Data always had to be copied to FOQS, causing major inefficiency when happening at scale. In addition, some storages were more suitable for particular types of data and load patterns than others. For example, the cost of storing data from high-traffic streams or large data warehouse tables in the queue can be significantly higher than keeping it in the original storage.
Re-architecture
To solve the above problems, we had to break down the system into more granular components with clear responsibilities and add first-class support for external data sources.
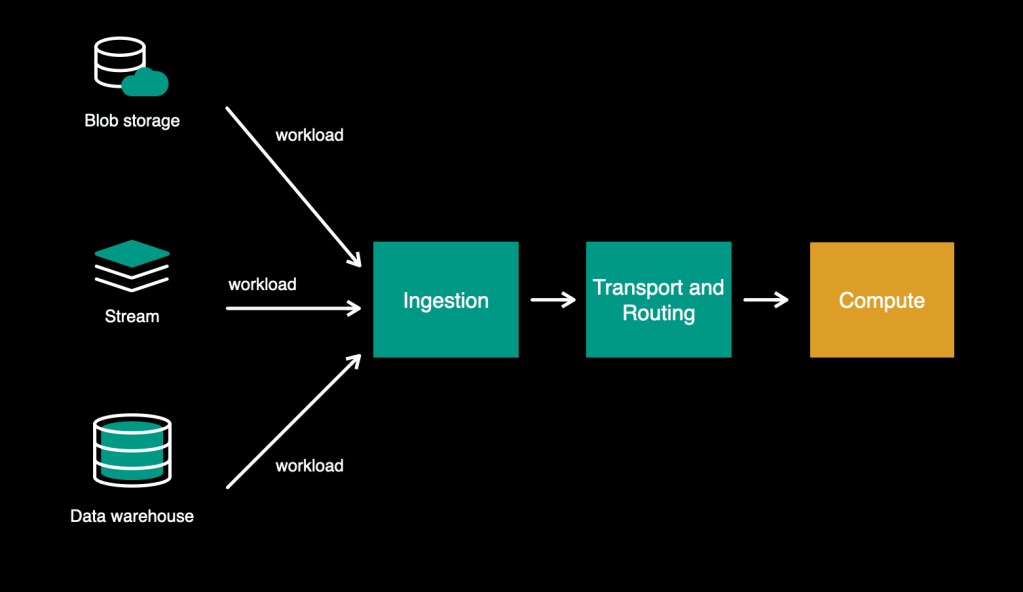
Our re-imagined version of Async tier would look like this:
Generic transport layer
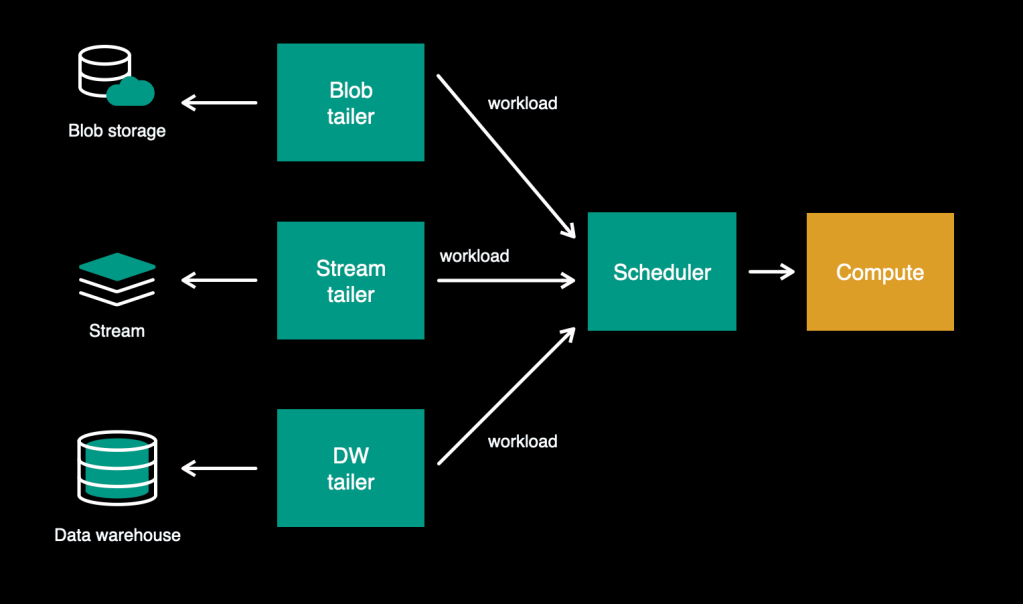
In the old system, our transport layer consisted of the dispatcher, which pulled workloads from FOQS. As the first step on the path of multi-source support, we decoupled the storage reading logic from the transport layer and moved it upstream. This left the transport layer as a data-source-agnostic component responsible for managing the execution and providing a compute-related set of capabilities such as rate limiting, quota management, load balancing, etc. We call this “scheduler”—an independent service with a generic API.
Reading workloads
Every data source can be different—for example, immutable vs. mutable, or fast-moving vs large-batch—and eventually requires some specific code and settings to read from it. We created adapters to house these “read logic”–the various mechanisms for reading different data sources. These adapters act like the UNIX tail command, tailing the data source for new workloads—so we call these “tailers.” During the onboarding, for each data source that the customer utilizes, the platform launches corresponding tailer instances for reading that data.
With these changes in place, our architecture looks like this:
Push versus pull and consequences
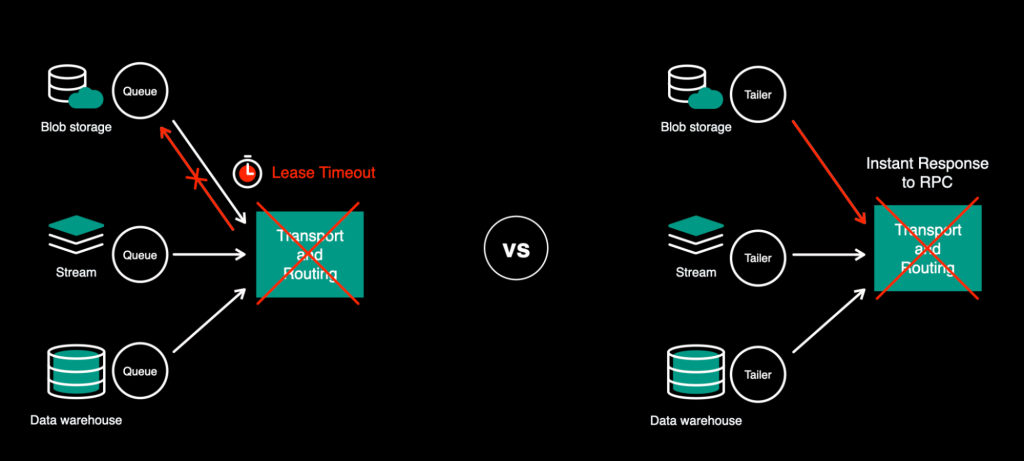
To facilitate these changes, the tailers were now “push”-ing data to the transport layer (the scheduler) instead of the transport “pull”-ing it.
The benefit of this change was the ability to provide a generic scheduler API and make it data-source agnostic. In push-mode, tailers would send the workloads as RPC to the scheduler and did not have to wait for ACK/NACK or lease timeout to know if they were successful or failed.
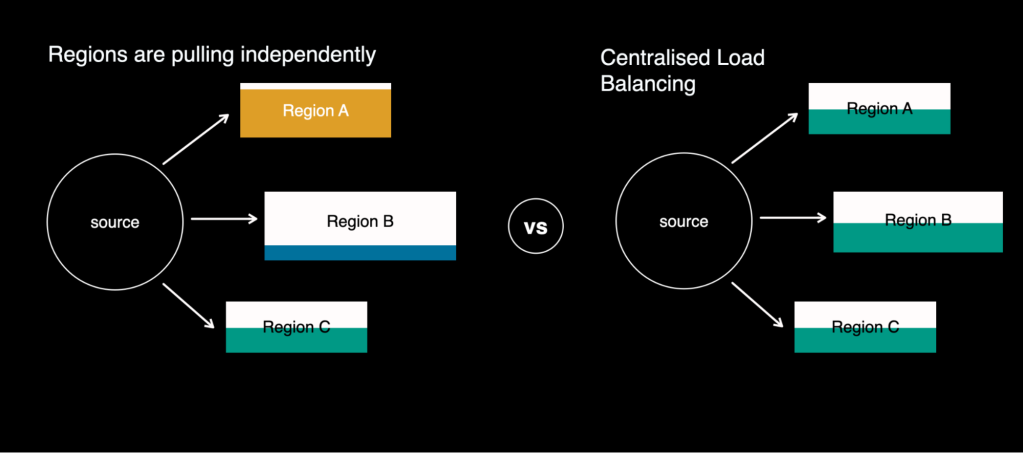
Cross-regional load balancing also became more accurate with this change, since they would be controlled centrally from the tailer instead of each region pulling independently.
These changes collectively improved the cross-region load distribution and the end-to-end latency of our platform, together with getting rid of data duplication (owing to buffering in FOQS) and treating all data sources as first-class citizens on our platform.
However, there were a couple of drawbacks to these changes as well. As push mode is essentially an RPC, it’s not a great fit for long-running workloads. It requires both client and server to allocate resources for the connection and hold them during the entire function running time, which can become a significant problem at scale. Also, synchronous workloads that run for a while have an increased chance of failure due to transient errors that will make them start over again completely. Based on the usage statistics of our platform, the majority of the workloads were finishing within seconds, so it was not a blocker, but it’s important to consider this limitation if a significant part of your functions are taking multiple minutes or even tens of minutes to finish.
Re-architecture: Results
Let’s quickly look at the main benefits we achieved from re-architecture:
- Workloads are no longer getting copied in FOQS for the sole purpose of buffering.
- Customers don’t need to invest extra effort in building their own solutions.
- We managed to break down the system into granular components with a clean contract, which makes it easier to scale our operations and work on new features in parallel.
- Moving to push mode improved our e2e latency and cross-regional load distribution.
By enabling first-class support for various data sources, we have created a space for further efficiency wins due to the ability to choose the most efficient storage for each individual use case. Over time we noticed two popular options that customers choose: queue (FOQS) and stream (Scribe). Since we have enough operational experience with both of them, we are currently in a position to compare the two instances and understand the tradeoffs of using each for powering asynchronous computations.
Queues versus streams
With queue as the choice of storage, customers have full flexibility when it comes to retry policies, granular per-item access, and variadic function running time, mainly due to the concept of lease and arbitrary ordering support. If computation was unsuccessful for some workloads, they could be granularly retried by NACKing the item back to the queue with arbitrary delay. However, the concept of lease comes at the cost of an internal item lifecycle management system. In the same way, priority-based ordering comes at the cost of the secondary index on items. These made queues a great universal choice with a lot of flexibility, at a moderate cost.
Streams are less flexible, since they provide immutable data in batches and cannot support granular retries or random access per item. However, they are more efficient if the customer needs only fast sequential access to a large volume of incoming traffic. So, compared to queues, streams provide lower cost at scale by trading off flexibility.
The problem of retries in streams
Clogged stream
While we explained above that granular message-level retries were not possible in stream, we could not compromise on the At-Least-Once delivery guarantee that we had been providing to our customers. This meant we had to build the capability of providing source-agnostic retries for failed workloads.
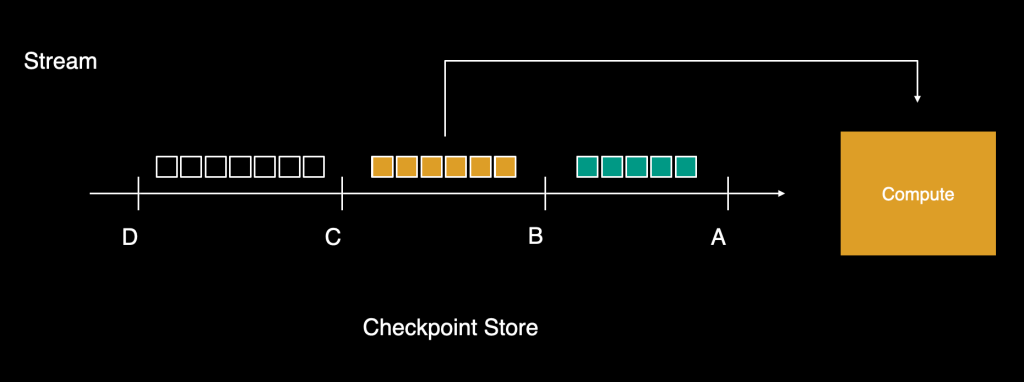
For streams, the tailers would read workloads in batches and advance a checkpoint for demarcating how far down the stream the read had progressed. These batches would be sent for computation, and the tailer would read the next batch and advance the checkpoint further once all items were processed. As this continued, if even one of the items in the last batch failed, the system wouldn’t be able to make forward progress until, after a few retries, it’s processed successfully. For a high-traffic stream, this would build up significant lag ahead of the checkpoint, and the platform would eventually struggle to catch up. The other option was to drop the failed workload and not block the stream, which would violate the At-Least-Once (ALO) guarantee.
Delay service
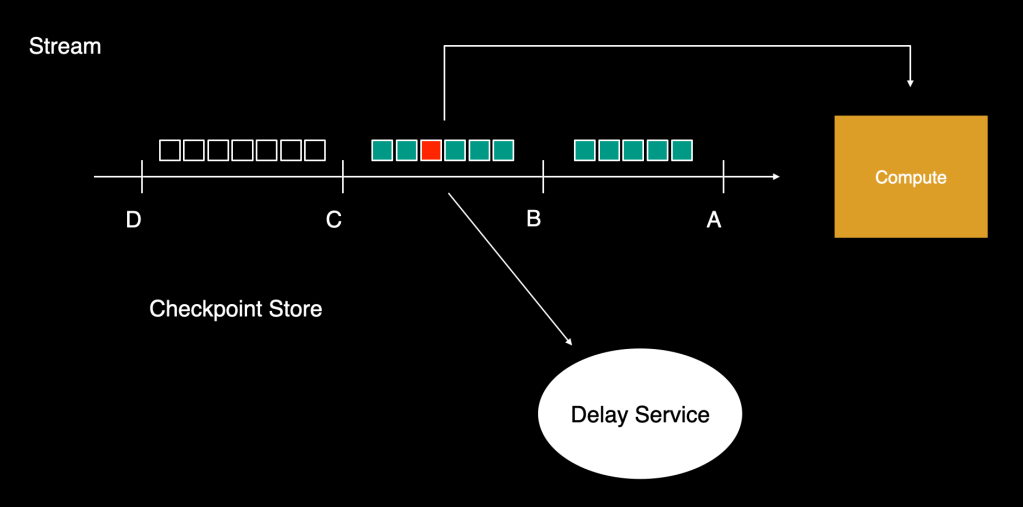
To solve this problem, we have created another service that can store items and retry them after arbitrary delay without blocking the entire stream. This service will accept the workloads along with their intended delay intervals (exponential backoff retry intervals can be used here), and upon completion of this delay interval, it will send the items to computation. We call this the controlled-delay service.
We have explored two possible ways to offer this capability:
- Use priority queue as intermediate storage and rely on the assumption that most of the traffic will go through the main stream and we will only need to deal with a small fraction of outliers. In that case, it’s important to make sure that during a massive increase in errors (for example, when 100% of jobs are failing), we will clog the stream completely instead of copying it into Delay service.
- Create multiple predefined delay-streams that are blocked by a fixed amount of time (for example, 30s, 1 minute, 5 minutes, 30 minutes) such that every item entering them gets delayed by this amount of time before being read. Then we can combine the available delay-streams to achieve the amount of delay time required by a specific workload before sending it back. As it’s using only sequential access streams under the hood, this approach can potentially allow Delay service to run at a bigger scale with lower cost.
Observations and learnings
The main takeaway from our observations is that there is no one-size-fits-all solution when it comes to running async computation at scale. You will have to constantly evaluate tradeoffs and choose an approach based on the specifics of your particular use cases. We noted that streams with RPC are best suited to support high-traffic, short-running workloads, whereas long execution time or granular retries will be supported well by queues at the cost of maintaining the ordering and lease management system. Also, if strict delivery guarantee is crucial for a stream-based architecture with a high ingestion rate, investing in a separate service to handle the retriable workloads can be beneficial.








