
- UPM is our internal standalone library to perform static analysis of SQL code and enhance SQL authoring.
- UPM takes SQL code as input and represents it as a data structure called a semantic tree.
- Infrastructure teams at Meta leverage UPM to build SQL linters, catch user mistakes in SQL code, and perform data lineage analysis at scale.
Executing SQL queries against our data warehouse is important to the workflows of many engineers and data scientists at Meta for analytics and monitoring use cases, either as part of recurring data pipelines or for ad-hoc data exploration.
While SQL is extremely powerful and very popular among our engineers, we’ve also faced some challenges over the years, namely:
- A need for static analysis capabilities: In a growing number of use cases at Meta, we must understand programmatically what happens in SQL queries before they are executed against our query engines — a task called static analysis. These use cases range from performance linters (suggesting query optimizations that query engines cannot perform automatically) and analyzing data lineage (tracing how data flows from one table to another). This was hard for us to do for two reasons: First, while query engines internally have some capabilities to analyze a SQL query in order to execute it, this query analysis component is typically deeply embedded inside the query engine’s code. It is not easy to extend upon, and it is not intended for consumption by other infrastructure teams. In addition to this, each query engine has its own analysis logic, specific to its own SQL dialect; as a result, a team who wants to build a piece of analysis for SQL queries would have to reimplement it from scratch inside of each SQL query engine.
- A limiting type system: Initially, we used only the fixed set of built-in Hive data types (string, integer, boolean, etc.) to describe table columns in our data warehouse. As our warehouse grew more complex, this set of types became insufficient, as it left us unable to catch common categories of user errors, such as unit errors (imagine making a UNION between two tables, both of which contain a column called timestamp, but one is encoded in milliseconds and the other one in nanoseconds), or ID comparison errors (imagine a JOIN between two tables, each with a column called user_id — but, in fact, those IDs are issued by different systems and therefore cannot be compared).
How UPM works
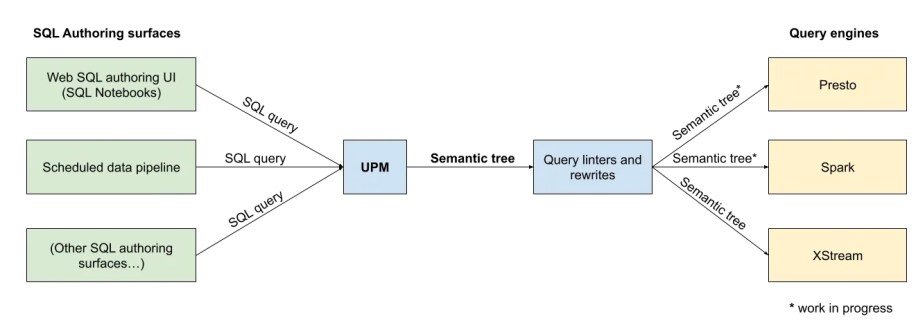
To address these challenges, we have built UPM (Unified Programming Model). UPM takes in an SQL query as input and represents it as a hierarchical data structure called a semantic tree.
For example, if you pass in this query to UPM:
SELECT
COUNT(DISTINCT user_id) AS n_users
FROM login_eventsUPM will return this semantic tree:
SelectQuery(
items=[
SelectItem(
name="n_users",
type=upm.Integer,
value=CallExpression(
function=upm.builtin.COUNT_DISTINCT,
arguments=[ColumnRef(name="user_id", parent=Table("login_events"))],
),
)
],
parent=Table("login_events"),
)
Other tools can then use this semantic tree for different use cases, such as:
- Static analysis: A tool can inspect the semantic tree and then output diagnostics or warnings about the query (such as a SQL linter).
- Query rewriting: A tool can modify the semantic tree to rewrite the query.
- Query execution: UPM can act as a pluggable SQL front end, meaning that a database engine or query engine can use a UPM semantic tree directly to generate and execute a query plan. (The word front end in this context is borrowed from the world of compilers; the front end is the part of a compiler that converts higher-level code into an intermediate representation that will ultimately be used to generate an executable program). Alternatively, UPM can render the semantic tree back into a target SQL dialect (as a string) and pass that to the query engine.
A unified SQL language front end
UPM allows us to provide a single language front end to our SQL users so that they only need to work with a single language (a superset of the Presto SQL dialect) — whether their target engine is Presto, Spark, or XStream, our in-house stream processing service.
This unification is also beneficial to our data infrastructure teams: Thanks to this unification, teams that own SQL static analysis or rewriting tools can use UPM semantic trees as a standard interop format, without worrying about parsing, analysis, or integration with different SQL query engines and SQL dialects. Similarly, much like Velox can act as a pluggable execution engine for data management systems, UPM can act as a pluggable language front end for data management systems, saving teams the effort of maintaining their own SQL front end.
Enhanced type-checking
UPM also allows us to provide enhanced type-checking of SQL queries.
In our warehouse, each table column is assigned a “physical” type from a fixed list, such as integer or string. Additionally, each column can have an optional user-defined type; while it does not affect how the data is encoded on disk, this type can supply semantic information (e.g., Email, TimestampMilliseconds, or UserID). UPM can take advantage of these user-defined types to improve static type-checking of SQL queries.
For example, an SQL query author might want to UNION data from two tables that contain information about different login events:

In the query on the right, the author is trying to combine timestamps in milliseconds from the table user_login_events_mobile with timestamps in nanoseconds from the table user_login_events_desktop — an understandable mistake, as the two columns have the same name. But because the tables’ schema have been annotated with user-defined types, UPM’s typechecker catches the error before the query reaches the query engine; it then notifies the author in their code editor. Without this check, the query would have completed successfully, and the author might not have noticed the mistake until much later.
Column-level data lineage
Data lineage — understanding how data flows within our warehouse and through to consumption surfaces — is a foundational piece of our data infrastructure. It enables us to answer data quality questions (e.g.,“This data looks incorrect; where is it coming from?” and “Data in this table were corrupted; which downstream data assets were impacted?”). It also helps with data refactoring (“Is this table safe to delete? Is anyone still depending on it?”).
To help us answer those critical questions, our data lineage team has built a query analysis tool that takes UPM semantic trees as input. The tool examines all recurring SQL queries to build a column-level data lineage graph across our entire warehouse. For example, given this query:
INSERT INTO user_logins_daily_agg
SELECT
DATE(login_timestamp) AS day,
COUNT(DISTINCT user_id) AS n_users
FROM user_login_events
GROUP BY 1
Our UPM-powered column lineage analysis would deduce these edges:
[{
from: “user_login_events.login_timestamp”,
to: “user_login_daily_agg.day”,
transform: “DATE”
},
{
from: “user_login_events.user_id”,
to: “user_logins_daily_agg.n_user”,
transform: “COUNT_DISTINCT”
}]
By putting this information together for every query executed against our data warehouse each day, the tool shows us a global view of the full column-level data lineage graph.
What’s next for UPM
We look forward to more exciting work as we continue to unlock UPM’s full potential at Meta. Eventually, we hope all Meta warehouse tables will be annotated with user-defined types and other metadata, and that enhanced type-checking will be strictly enforced in every authoring surface. Most tables in our Hive warehouse already leverage user-defined types, but we are rolling out stricter type-checking rules gradually, to facilitate the migration of existing SQL pipelines.
We have already integrated UPM into the main surfaces where Meta’s developers write SQL, and our long-term goal is for UPM to become Meta’s unified SQL front end: deeply integrated into all our query engines, exposing a single SQL dialect to our developers. We also intend to iterate on the ergonomics of this unified SQL dialect (for example, by allowing trailing commas in SELECT clauses and by supporting syntax constructs like SELECT * EXCEPT <some_columns>, which already exist in some SQL dialects) and to ultimately raise the level of abstraction at which people write their queries.








