
Every workday, Facebook engineers commit thousands of diffs (which is a change consisting of one or more files) into production. This code velocity allows us to rapidly ship new features, deliver bug fixes and optimizations, and run experiments. However, a natural downside to moving quickly in any industry is the risk of inadvertently causing regressions in performance, reliability, or functional correctness.
To enable us to scale our developer infrastructure to this volume — while also mitigating and minimizing regressions — we build tools and mechanisms to help engineers understand whether a diff has introduced (or will introduce) a regression. We consider the feedback we get from these tools as signals. Signals can be generated by automated tests, static analysis frameworks, performance logs, crash dumps, bug reports, production monitoring alarms, and dozens of other sources. These signals can be surfaced at any stage of the development life cycle. A given diff can generate hundreds of signals — including errors, successes, and warnings — that can help an engineer assess whether that diff is ready to be landed into a stable branch and begin making its way into production. After a diff has landed, signals are usually delivered to engineers via our task management system. An individual engineer can easily have hundreds of tasks in their backlog.
With so many signals being generated, it can quickly become overwhelming for engineers to know where to focus their time. A very important signal could get overlooked because it was drowned out by noisy, lower-priority signals — making it harder for engineers to quickly or easily assess the relative priority for each signal. They might spend hours debugging an issue that turned out to be noise, or lack the necessary information to help them diagnose and fix it.
Over time, as we built more tools and monitoring systems, the signal volume increased until it became a persistent distraction. Eventually, we realized we needed a more effective way to help engineers easily see what to work on first, and spend less time debugging and fixing issues.
Making fixes more efficient
We’ve seen that defects become exponentially more time consuming to fix as they progress further along the development process. This is true for most manufacturing industries, whether you are producing automobiles, building skyscrapers, or shipping software. We clearly see this in our own data:
- A defect detected in the integrated development environment (IDE) while an engineer is coding, can be fixed in minutes.
- A defect detected while a diff is being reviewed can be fixed in hours.
- If that same defect is allowed to land and make its way into production, it can take days to deliver a fix.
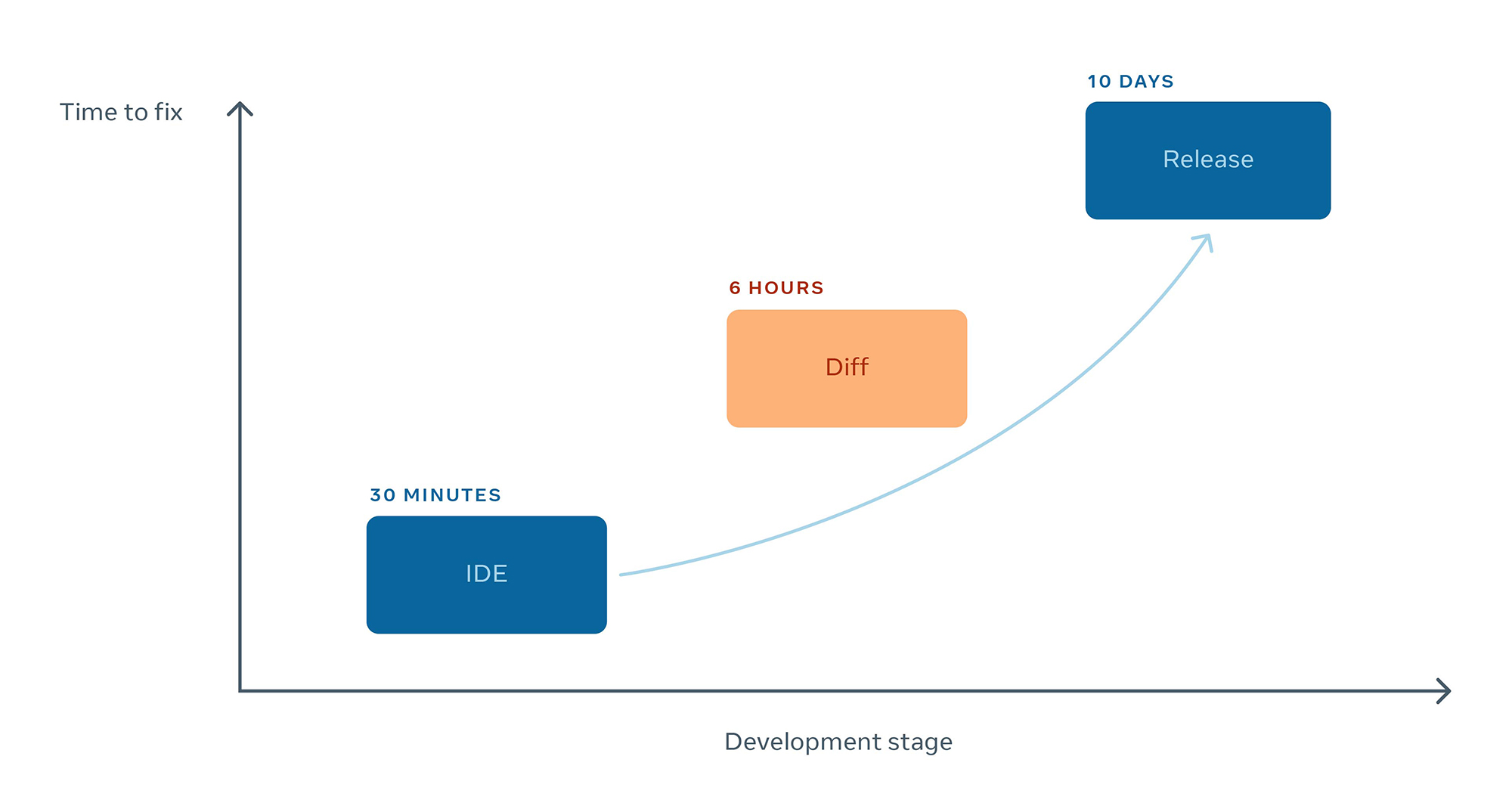
Any solution designed to decrease fix times would need to ensure that regressions were being detected and fixed as early as possible in the process.
Introducing Fix Fast
To address these challenges, we launched our cross-functional effort, dubbed Fix Fast, in 2019. Fix Fast brings together the engineering teams responsible for generating the lion’s share of signals representing regressions in performance, reliability, and functional correctness. The mission of this effort was to reduce the effort required to fix regressions at scale by improving the engineering experience and by moving actionable detection further upstream.
While the high-level strategy was clear, we still had some big questions to answer: Which problems should we start with? How should we measure progress? We knew we’d need a data-driven approach to execute against this goal at Facebook scale, so we started by finding a way to measure the level of effort and set benchmarks.
A metric for faster fixes
In pursuit of a metric, we considered many options. Ultimately, we landed on a metric that would incentivize engineers to “shift left,” a common industry practice of detecting (and fixing) regressions as early in the development life cycle as possible. As mentioned above, helping engineers detect and fix an issue in the IDE while they are still focused on that block of code is significantly less time-consuming doing so once the code is live in production.
We developed a uniform top-level metric, called cost per developer (CPD), such that earlier stages of a fix were given a lower weighted cost than later stages. (Note that the term cost is used to represent the amount of time an engineer spends fixing an issue, as opposed to a direct dollar amount.) Weights for each stage were established by analyzing internal data and applying rigorous backtesting to determine the relative amount of time engineers were already spending fixing regressions in each stage. This approach encouraged detection and prevention of issues in the earlier stages of the life cycle. It also incentivized engineers to focus on noise reduction, signal actionability, and other intra-stage improvements. This helps ensure not only that signals are detected, but also that the relevant engineers are able to quickly fix the issues before the code moves to the next stage of the development life cycle.
By evaluating progress against CPD, the team was able to take a quantitative approach to tracking projects within each stage to help reduce the engineering time spent fixing regressions.
Project playbook
Once CPD was in place, the Fix Fast team developed a playbook of approaches that had made proven improvements in shifting left, noise reduction, actionability, and more.
Shift left
Earlier detection is by far the number one way to reduce fix times. Automated tests are important to ensure that regressions are not promoted into production. However, running tests in continuous integration and production require a significant amount of data center capacity and time. Given the sheer number of diffs that need to be tested each day, and the number of tests to choose from, we’ve employed complex heuristics and machine learning algorithms to help choose the best tests to run at each stage, taking into account the amount of time and capacity available. On a typical day, Facebook runs millions of tests on diffs alone.
We are also developing automated tests within the IDE to allow engineers to run a subset of tests while they are coding, before they even submit their code for review. IDE test results are returned in minutes. By taking this approach, engineers can now get test signals 90 percent sooner, and we have decreased the number of post-commit failures by more than 10 percent.
Signal quality
Reducing noisy, duplicated, or unactionable signals is important for ensuring that engineers know which signals are important and can quickly fix any underlying regressions.
To address this, we first had to understand which signals were resulting in useful outcomes. After manually analyzing hundreds of such signals, we developed a heuristic, called meaningful action, to represent tasks that were useful and resulted in some action by an engineer. The meaningful action heuristic considers human comments, diffs attached to a task, or other nontrivial actions. By systematically removing the unhealthy bots (those more likely to produce noisy or otherwise inactionable signals), we were able to dedupe signals and map them to the right regression metrics with a reasonable threshold for triggering. Accurate and actionable information was added to the tasks to give users clear direction on issue fixing.
One example of this is Health Compass, where we successfully improved the meaningful action ratio by 20 percent last year by reducing noise and tuning the regression detection logic.
Faster attribution
Getting the signal in front of the right person the first time can shave days off of fix time. But this is often easier said than done. When a task is assigned to the wrong owner, it can ping-pong around the company before finally landing with someone who can fix it. In internal testing, we found that for tasks that had three or more owners before being resolved, close to 50 percent of the task’s cycle time was spent on ping-pong reassignments before reaching the correct owner.
One win was achieved by simply adding an “I’m not the right owner” button to the task. Previously, engineers had to track down the next best owner themselves, which could create a significant delay and prevent them from moving on to a new task. Now, when an engineer indicates that they are not the right person to fix an issue, the ownership selection algorithm engages the next best prediction on whom to assign the task. This data is also being used to help improve our ownership selection algorithm over time.
Better regression triage and root cause analysis are important to solving this. One of the biggest success stories in this area is our multisect service. Multisect analyzes a branch to trace the root cause back to the specific diff where a regression was introduced. This year, we worked on speeding up this process. As a result, we can now find the right diff three times faster than before.
Get clean, stay clean
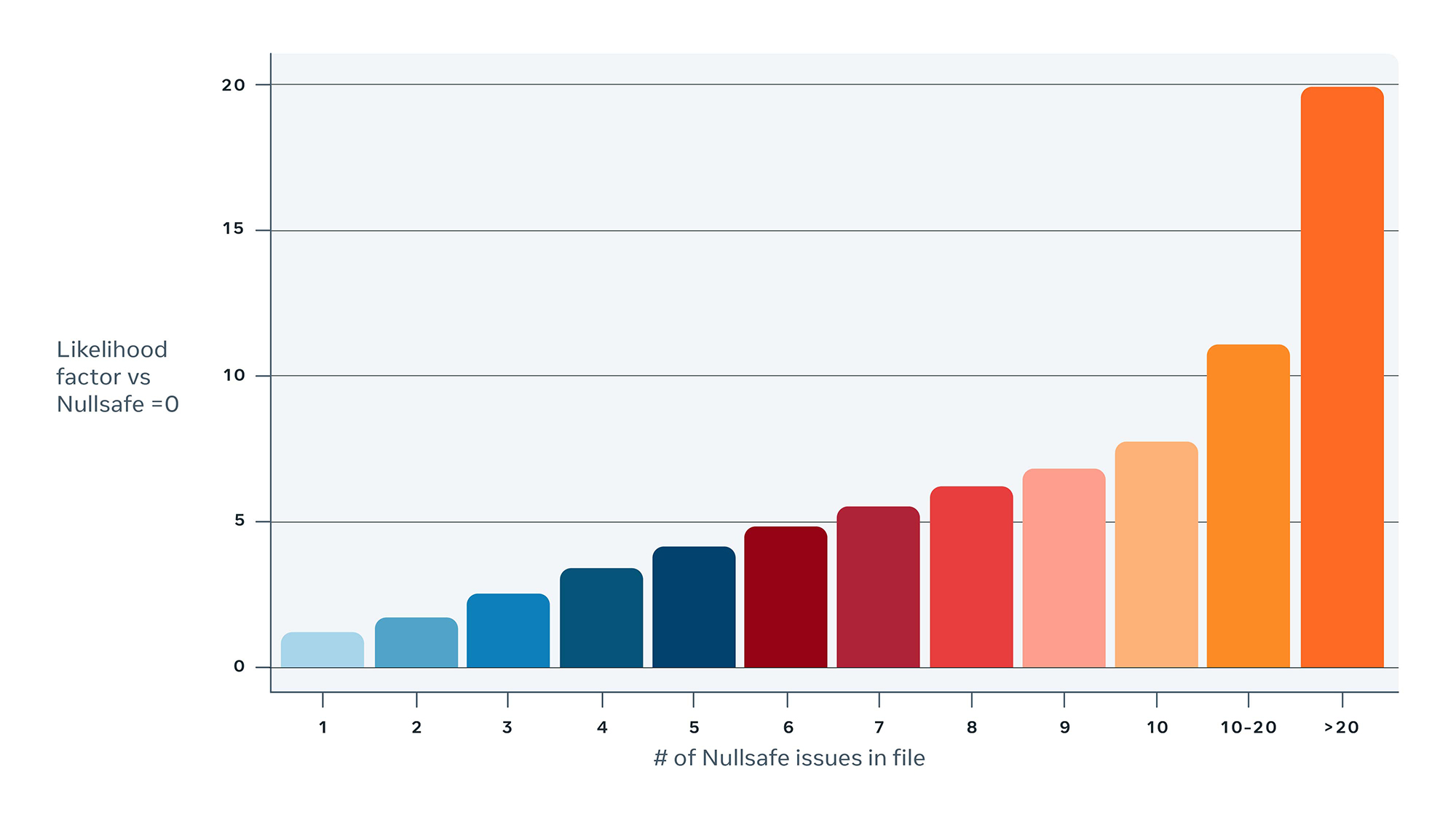
Implement a land-blocking signal to help prevent regressions from being promoted. Null pointer exceptions (NPE) are a common crash type that affect hundreds of millions of Android users of Facebook’s family of apps. Making Java classes NullSafe is an important step toward reducing and eliminating these crashes.
Our data has shown that non-NullSafe Java files are three times more likely to result in NPE crashes than Java files that are NullSafe. The more NullSafe issues a file has, the more likely it is to be associated with NPE crashes. In 2020, we applied static analysis to help us detect code that’s not yet NullSafe and to provide engineers with tools to rapidly fix these issues. But perhaps more important, once a class has no more NullSafe issues, it is marked with an @NullSafe annotation. This blocks the code from being promoted again if any new NullSafe issues are introduced.
What’s next?
By implementing all of these procedures, we are able to detect a greater percentage of regressions earlier in the engineering life cycle, thereby reducing the overall effort required to fix these regressions. Additional work in machine learning and other techniques is ongoing, to monitor and refine the best mixture of early detection techniques at scale.
We have also established a robust set of metrics, which help ensure that the quality of regression signals being delivered to engineers is sufficient for them to quickly triage, diagnose, and repair underlying regressions without overwhelming them with potentially noisy or duplicative signals. In the near future, we will be investing in systems that can automatically tune the sensitivity of regression detectors without requiring an engineer to proactively monitor these metrics. For example, a detector that is producing potentially noisy or inactionable signals can be temporarily disabled until an engineer can diagnose the problem, thus preventing unnecessary noise from being generated.
Ultimately, these techniques have proved beneficial not only for engineers, who reduce the amount of time they spend fixing regressions, but also for customers, who benefit from fewer regressions and faster fixes.








