
To develop new product features and updates efficiently, we use a trunk-based development model for changes to our codebase. Once an engineer’s code change has been accepted into the main branch (the trunk), we strive to make it visible quickly to every other engineer working on that product or service. This trunk-based development model is more effective than the use of feature branches and feature merges because it enables everyone to work on the latest version of the codebase. But it is important that each proposed change be thoroughly tested for regressions before being accepted into the trunk. Every code change undergoes exhaustive testing before it is deployed from the trunk to production, but allowing regressions into the trunk would make it much more difficult to evaluate a new proposed code change, and it would impact engineer productivity.
We have developed a better way to perform this regression testing, using a new system that leverages machine learning to create a probabilistic model for selecting regression tests for a particular code change. This method needs to run only a small subset of tests in order to reliably detect faulty changes. Unlike typical regression test selection (RTS) tools, the system automatically develops a test selection strategy by learning from a large data set of historical code changes and test outcomes.
This predictive test selection system has been deployed at Facebook for more than a year, enabling us to catch more than 99.9 percent of all regressions before they are visible to other engineers in the trunk code, while running just a third of all tests that transitively depend on modified code. This has allowed us to double the efficiency of our testing infrastructure.
The system also requires little to no manual tuning to adapt as the codebase evolves. And it has also proved capable of accounting for flaky tests that produce inconsistent and nondeterministic results.
Why using build dependencies is inefficient
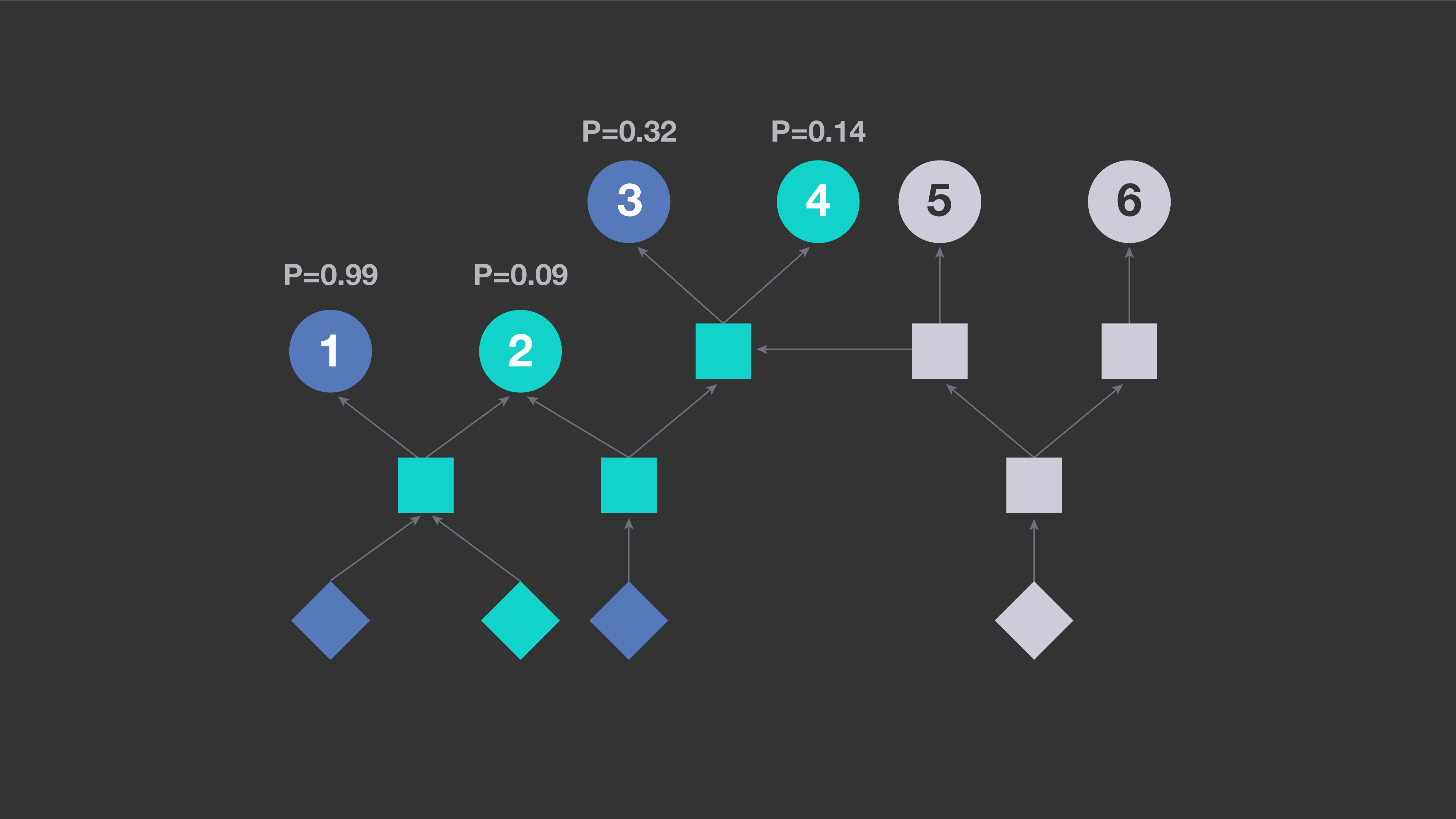
A common approach to regression testing is to use information extracted from build metadata to determine which tests to run on a particular code change. By analyzing build dependencies between units of code, one can determine all tests that transitively depend on sources modified in that code change. For example, in the diagram below, circles represent tests; squares represent intermediate units of code, such as libraries; and diamonds represent individual source files in the repository. An arrow connects entities A → B if and only if B directly depends on A, which we interpret as A impacting B. The blue diamonds represent two files modified in a sample code change. All entities transitively dependent upon them are also shown in blue. In this scenario, a test selection strategy based on build dependencies would exercise tests 1, 2, 3, and 4. But tests 5 and 6 would not be exercised, as they do not depend on modified files.
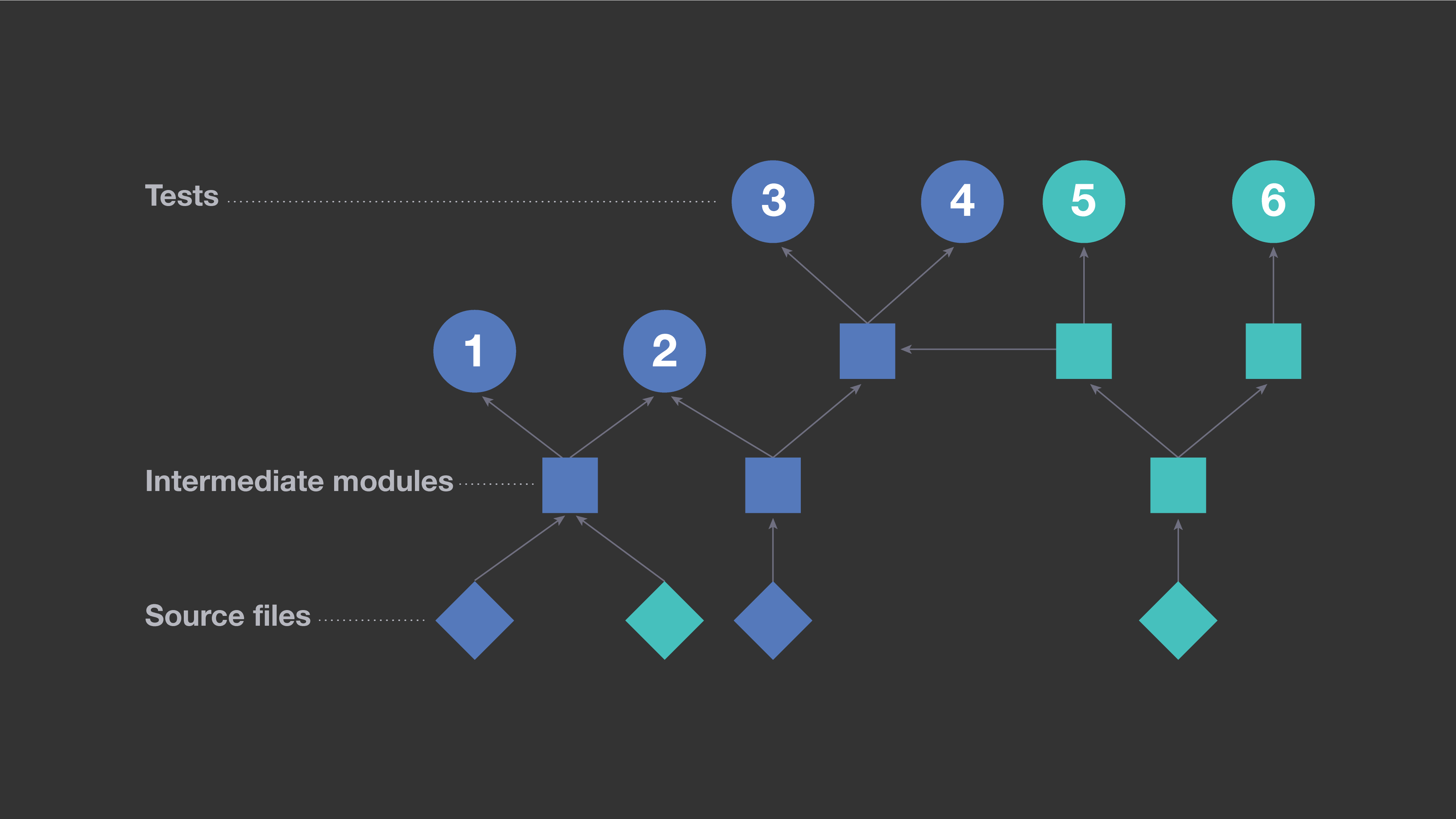
This approach has a significant shortcoming: It ends up saying “yes, this test is impacted” more often than is actually necessary. On average, it would cause as many as a quarter of all available tests to be exercised for each change made to our mobile codebase. If all tests that transitively depend upon modified files were actually impacted, we would have no alternative but to exercise each of them. However, in our monolithic codebase, end products depend on many reusable components, which use a small set of low-level libraries. In practice, many transitive dependencies are not, in fact, relevant for regression testing. For example, when there is a change to one of our low-level libraries, it would be inefficient to rerun all tests on every project that uses that library.
The research community has developed other approaches to regression test selection, such as those based on static change-impact analysis. These techniques, however, are impractical in our use case because of the size of our codebase and the number of different programming languages in use.
A new approach: Predictive test selection
Selecting tests based on build dependencies involves asking which tests could potentially be impacted by a change. To develop a better method, we consider a different question: What is the likelihood that a given test finds a regression with a particular code change? If we estimate this, we can make an informed decision to rule out tests that are extremely unlikely to uncover an issue. This is a significant departure from conventional test selection and opens up a new, more efficient way of selecting tests.
As the first step, we created a predictive model that estimates the probability of each test failing for a newly proposed code change. Instead of defining the model manually, we built it by using a large data set containing results of tests on historical code changes and then applying standard machine learning techniques.
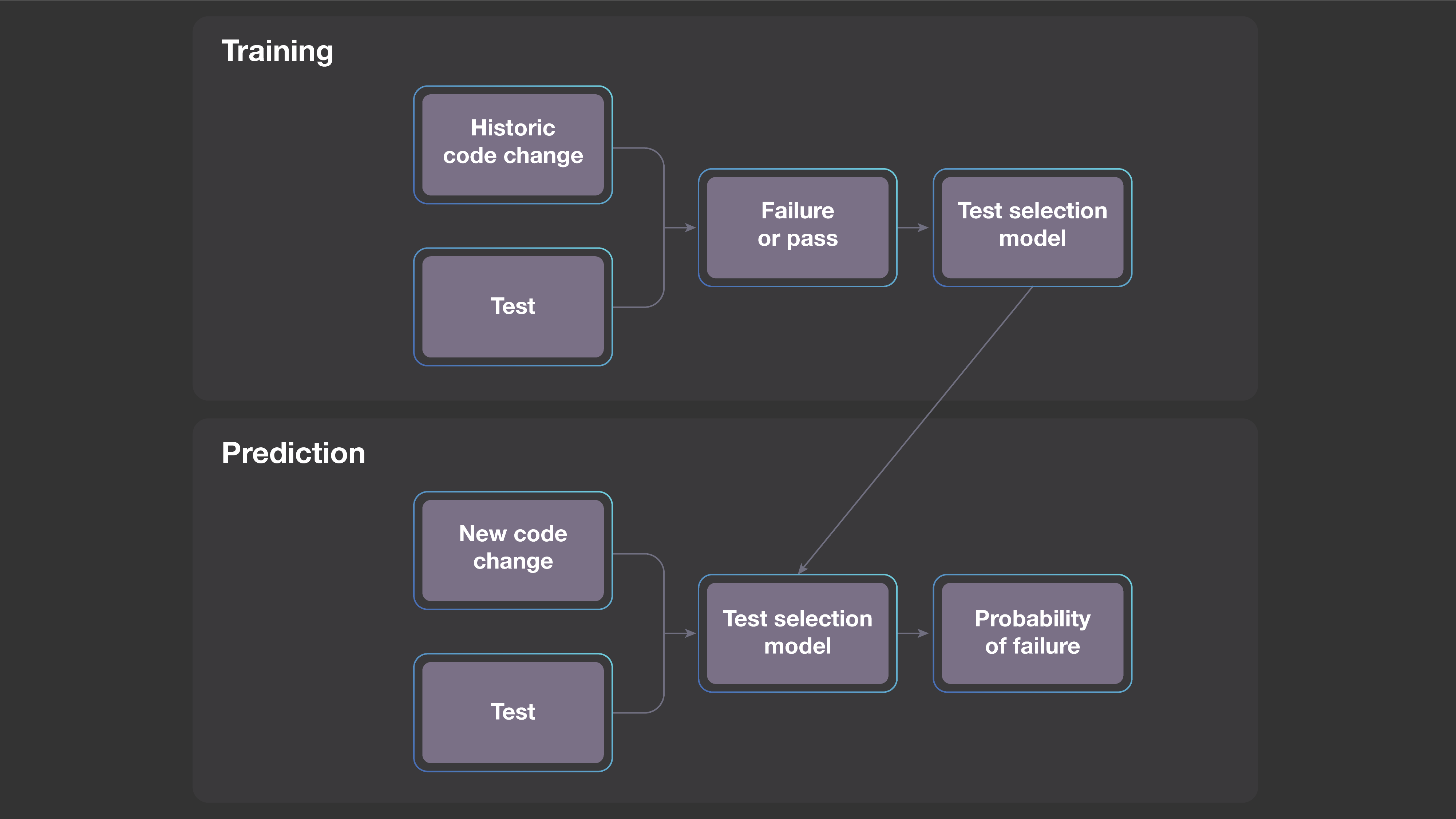
Each new code change will always be at least slightly different from previous cases, so the model cannot simply compare a new change with a historical one to determine which tests are worth running. However, an abstraction of the new change can be similar to the corresponding abstraction of one or more of the previous code changes.
During training, our system learns a model based on features derived from previous code changes and tests. Then, when the system is analyzing new code changes, we apply the learned model to a feature-based abstraction of the code change. For any particular test, the model is then able to predict the likelihood of detecting a regression.
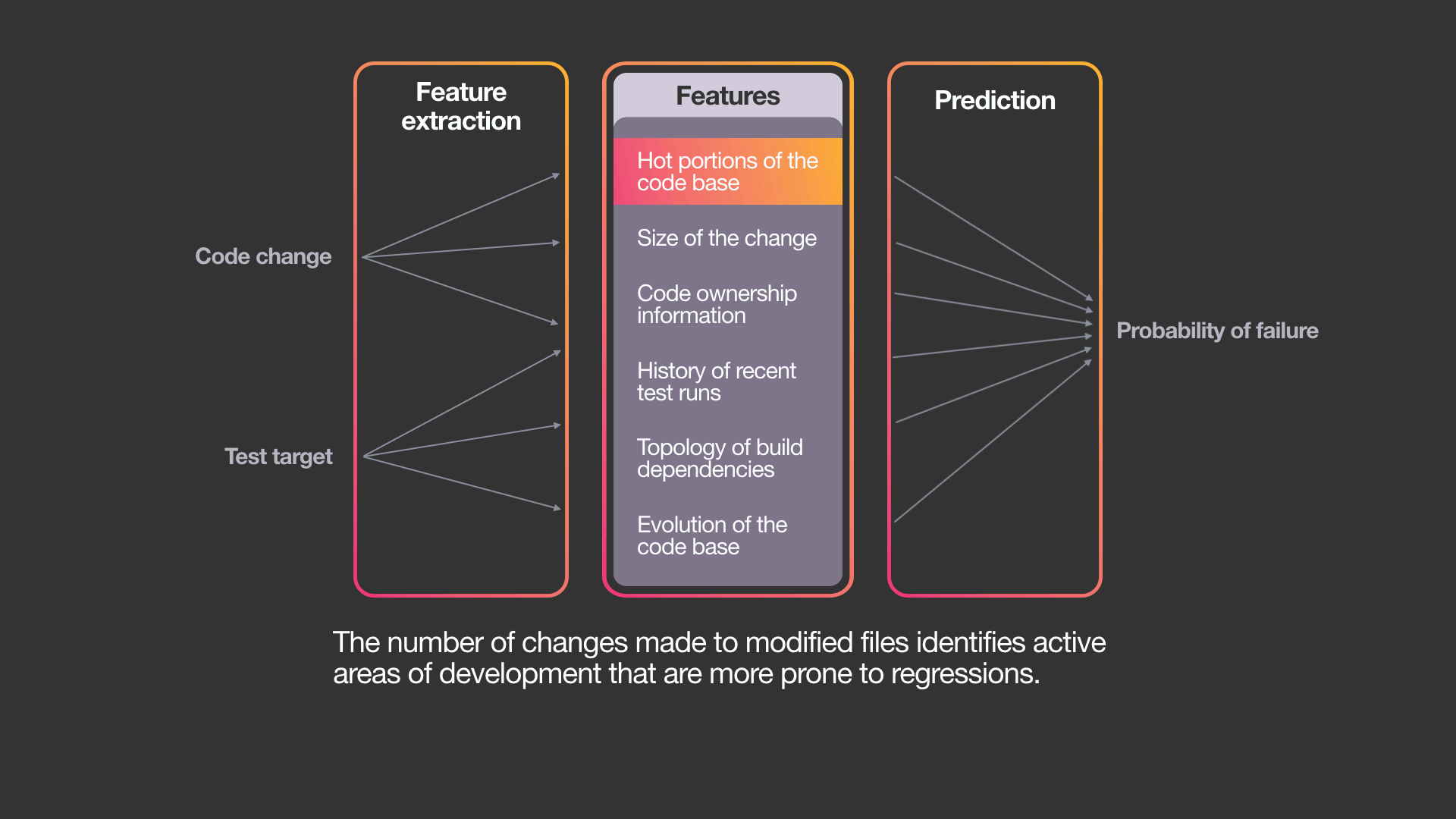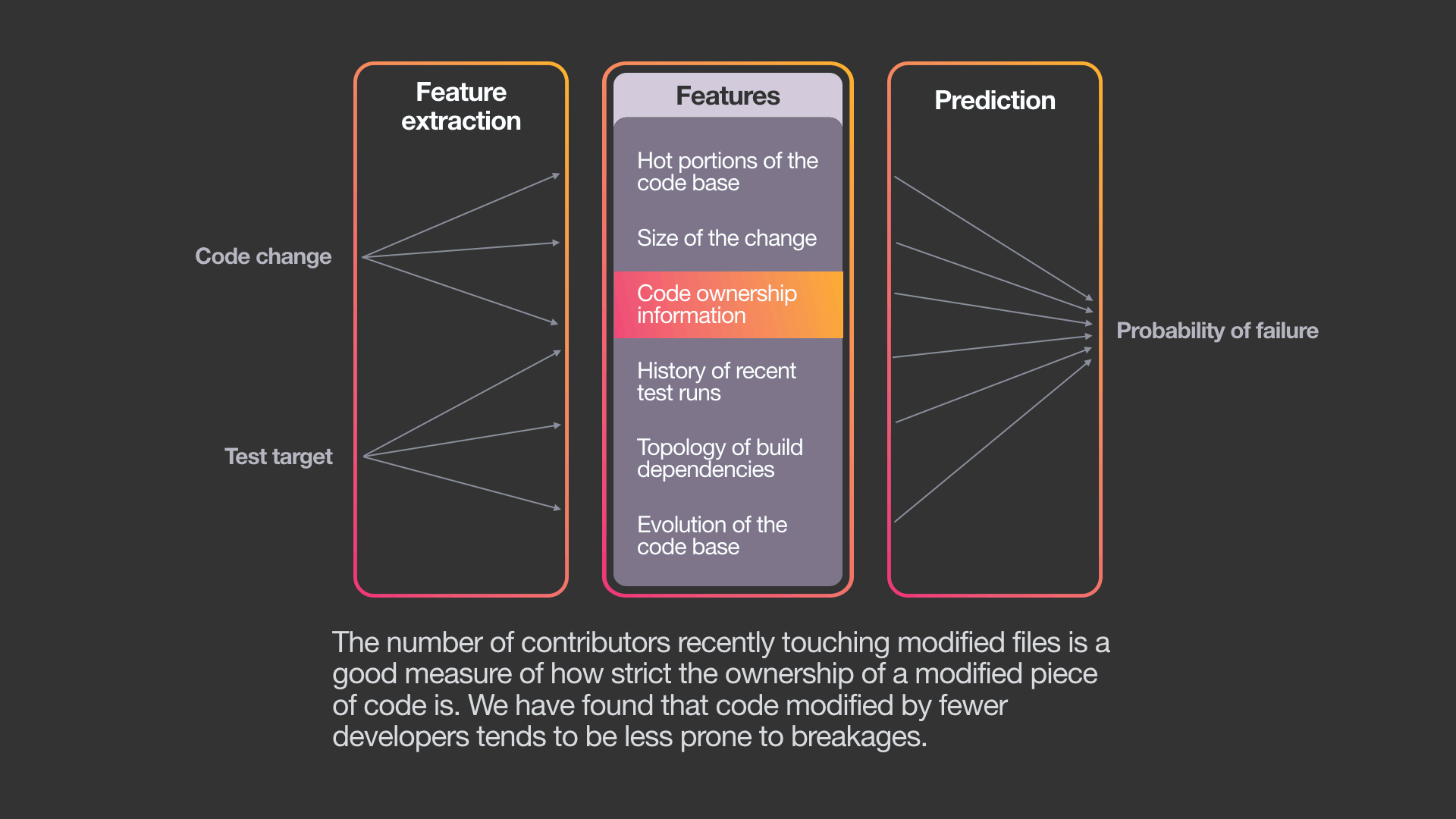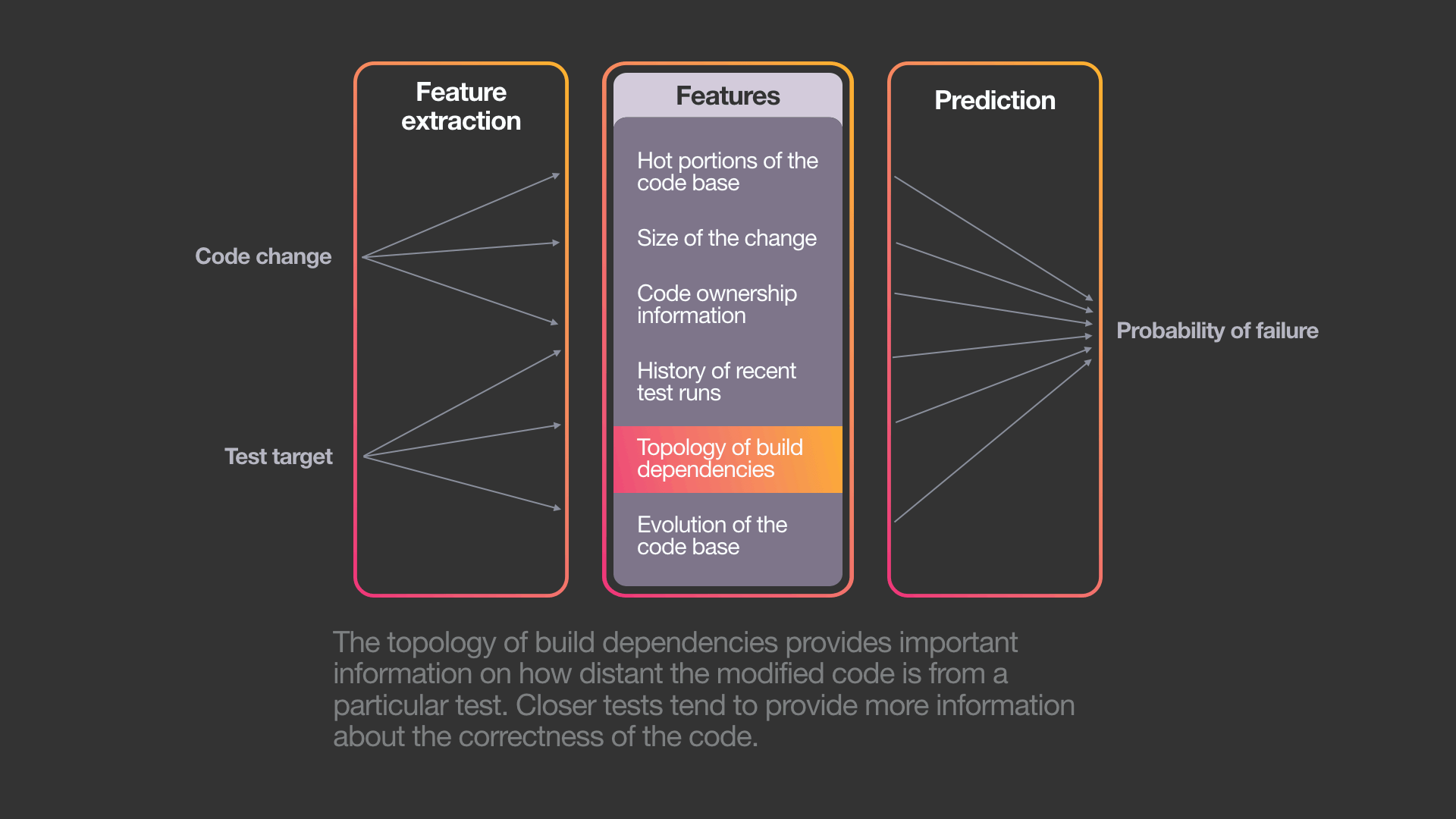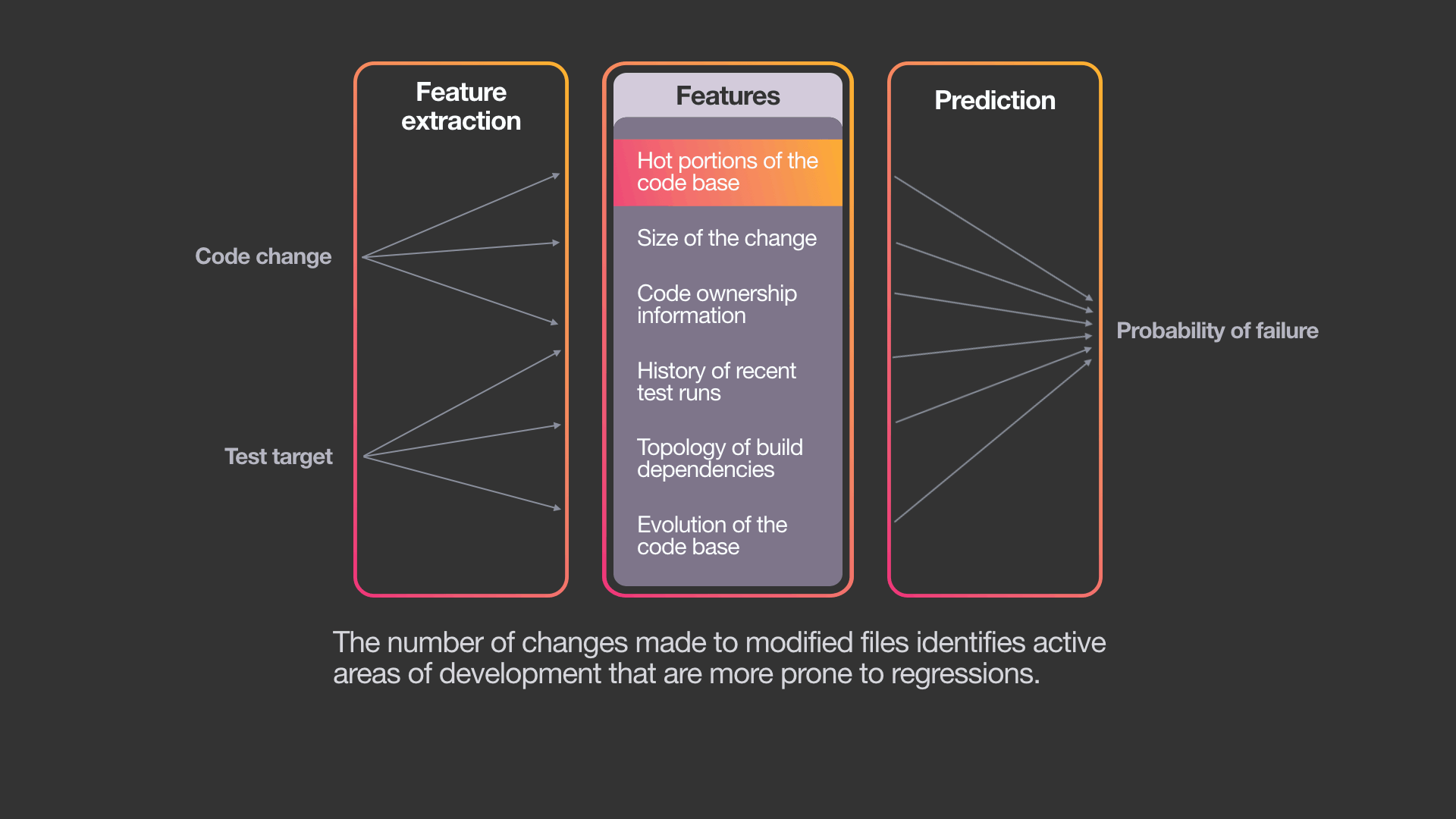
To do this, the system uses a variant of a standard machine learning algorithm — a gradient-boosted decision-tree model. While it is possible to use other ML algorithms, we have chosen this approach for several reasons: Decision trees are explainable, easy to train, and already part of Facebook’s ML infrastructure.
With this model, we can analyze a particular code change to find all potentially impacted tests that transitively depend on modified files, and then estimate the probability of that test detecting a regression introduced by the change. Based on those estimates, the system selects the tests that are most likely to fail for a particular change. The diagram below shows which tests (shown in blue) would be chosen for a change affecting the two files from the previous example, where the likelihood of each considered is represented by a number between zero and one.
Evaluating and calibrating the model
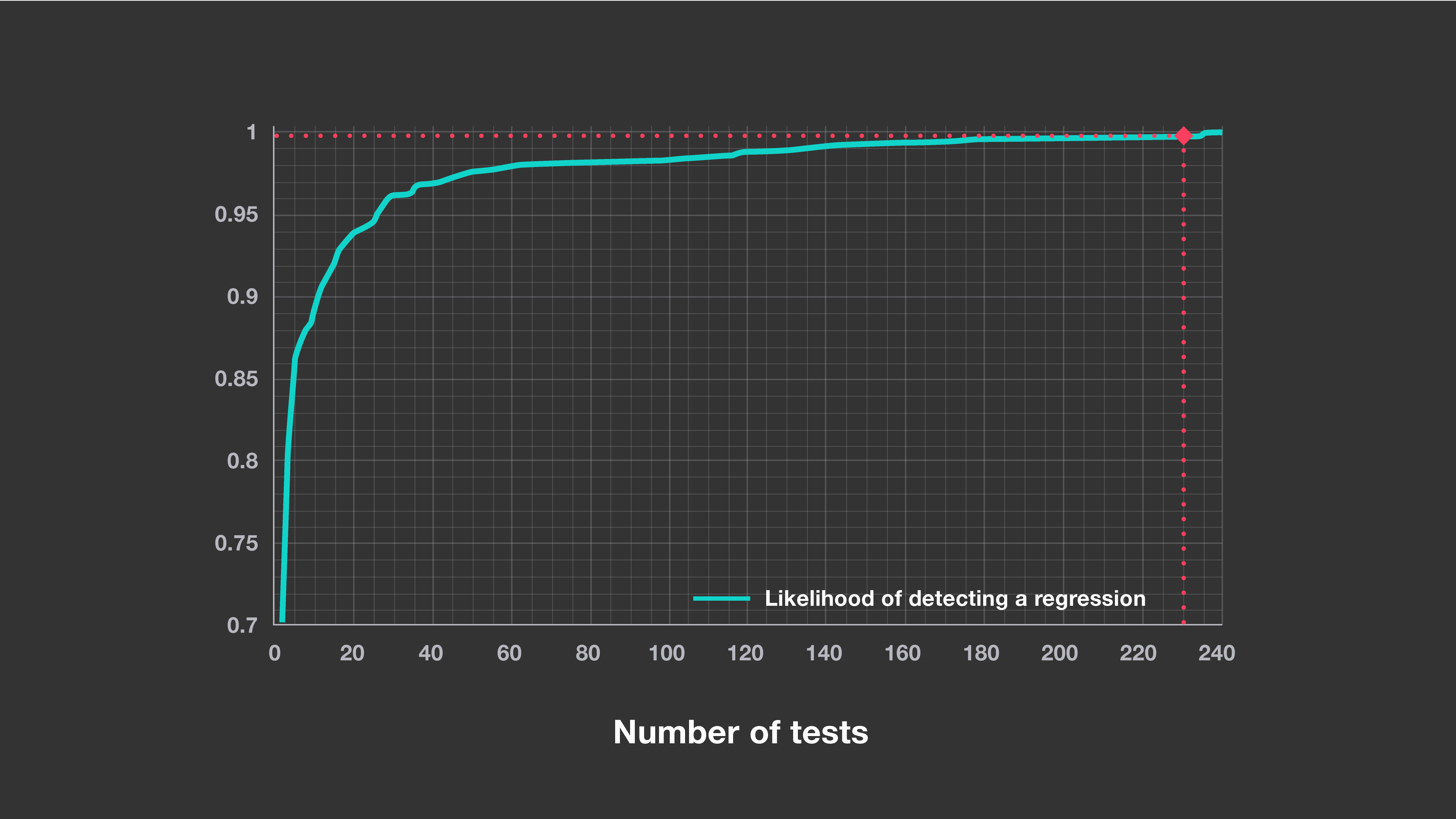
For each code change, the number of tests selected by the system affects how reliable it is at detecting a regression. Using a selection of recent code changes as a validation set, we can evaluate its accuracy on new changes. The chart below shows the relationship between the maximum number of tests to select per change and the accuracy of that selection. In production, we require our model to predict more than 95 percent of test outcomes correctly and to catch at least one failing test for more than 99.9 percent of problematic changes. We have found that this high standard for accuracy causes negligible loss of test signal and eliminates a large number of unnecessary test executions.
Because of the constantly evolving structure of the codebase, our test selection strategy must adapt to continue to satisfy these strict correctness requirements. This becomes straightforward with our system, however, because we can regularly retrain the model using test results from recently submitted code changes.
Addressing test flakiness
To ensure that our test selection works well for real-world tests, the system needs to address the problem of test flakiness, where test outcomes change from pass to fail when the code under test hasn’t actually changed. As explained in more detail in our paper, if we train a model without identifying flaky test failures, the model may not learn to predict test outcomes consistently. In the example below, two test selection strategies capture an equal portion of all failed test executions. If the system isn’t able to distinguish which test failures are flaky and which are not, it will not learn which strategy is best. Strategy A has significantly better accuracy, as it has captured all the tests that uncover actual regressions. Strategy B, however, selected many tests that failed due to flakiness rather than to an actual problem with the code.
To mitigate the impact of flakiness on the learned test selection model, we aggressively retry failed tests when collecting training data. This approach allows us to distinguish tests that failed consistently (indicating a true regression) from those that exhibited flaky, nonreproducible failures.
Detecting and fixing regressions: The 30,000-foot view
This system is part of our broader effort to build intelligent tools to make the code development process more reliable and efficient. Sapienz, our search-based automated software testing system, and Getafix, our automated bug-fixing tool, also help us detect and fix regressions automatically — that is, with little to no attention required from engineers.
Predictive test selection (the system described in this blog post) efficiently detects regressions by choosing the right subset of engineer-defined tests. Sapienz generates new test sequences that reveal conditions under which a mobile application would crash, and Getafix suggests patches for issues found by our testing and verification tools, which are then reviewed and accepted or rejected by the engineer who authored the change. Together, these systems enable engineers to create and deploy new features more quickly and effectively for the billions of people who use Facebook’s products.
Future plans
Predictive test selection is one of several projects at Facebook that seeks to apply statistical methods and machine learning to improve the effectiveness of regression testing. As we work on improving this system’s efficiency and accuracy even further, we are also applying related methodologies to identify potential gaps in test coverage.
Machine learning is revolutionizing many aspects of life. It is our belief that software engineering is no different in this respect.
We’d like to thank the following engineers and acknowledge their contributions to the project: Billy Cromb, Jakub Grzmiel, Glenn Hope, Hamed Neshat, Andrew Pierce, Yuguang Tong, Eric Williamson, and Austin Young.








