
As the PyTorch ecosystem and community continue to grow with interesting new projects and educational resources for developers, today at the NeurIPS conference we’re releasing PyTorch 1.0 stable. The latest version, which was first shared in a preview release during the PyTorch Developer Conference in October, includes capabilities such as production-oriented features and support from major cloud platforms.
Researchers and engineers can now readily take full advantage of the open source deep learning framework’s new features, including a hybrid front end for transitioning seamlessly between eager and graph execution modes, revamped distributed training, a pure C++ front end for high-performance research, and deep integration with cloud platforms.
PyTorch 1.0 accelerates the workflow involved in taking AI from research prototyping to production deployment, and makes it easier and more accessible to get started. In just the past few months, we’ve seen beginners quickly ramp up on PyTorch through new, widely available education programs, and experts build innovative projects that extend the framework to areas from natural language processing to probabilistic programming.
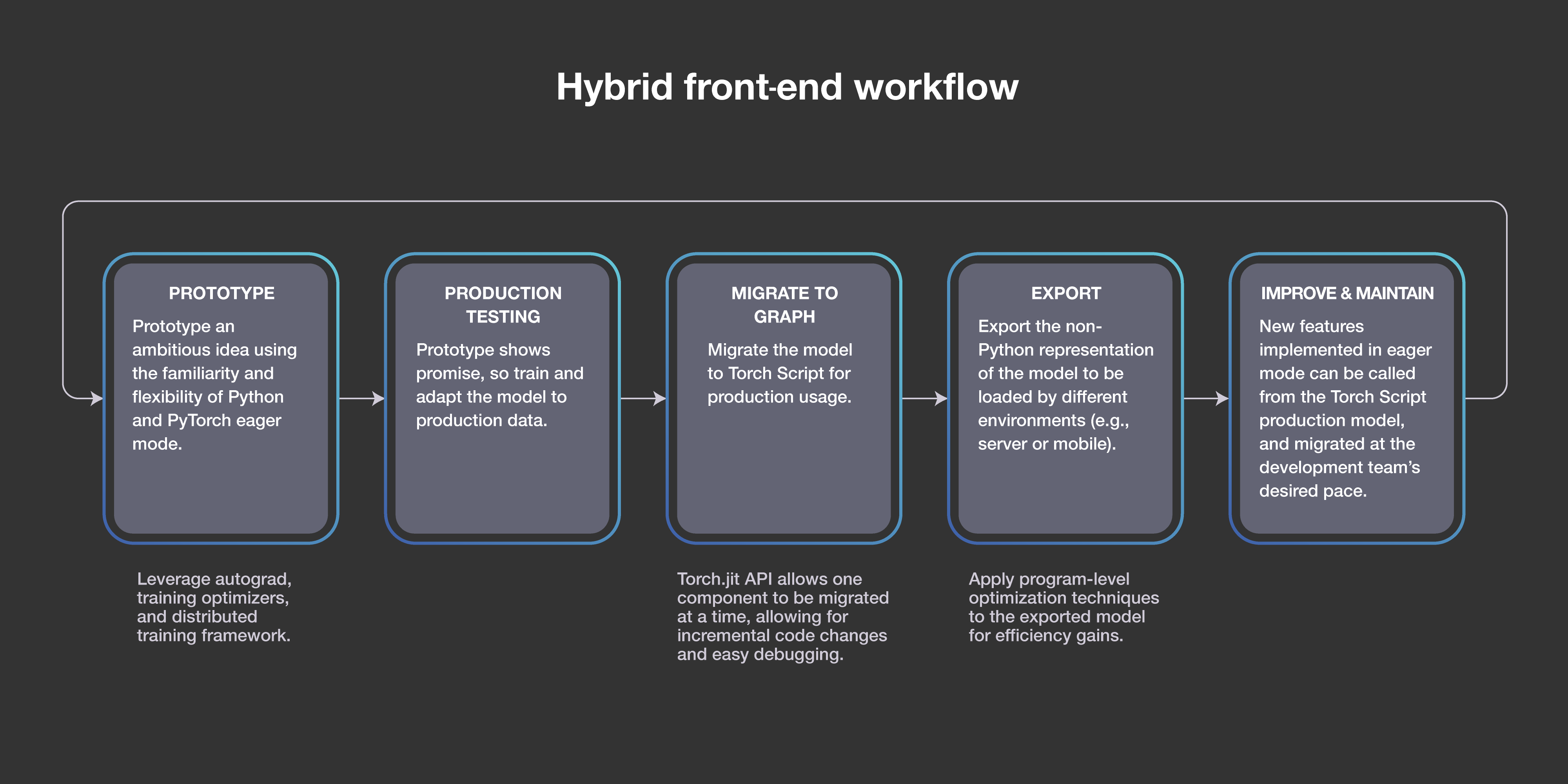
The growing PyTorch community
When PyTorch first launched in early 2017, it quickly became a popular choice among AI researchers, who found it ideal for rapid experimentation due to its flexible, dynamic programming environment and user-friendly interface. We’ve seen this community grow quickly since then. PyTorch is now the second-fastest-growing open source project on GitHub, with a 2.8x increase in contributors over the past 12 months.
We’re incredibly excited and thankful for the community that’s formed around PyTorch, and grateful to everyone who has contributed to the codebase, provided guidance and feedback, and built cutting-edge projects using the framework. To that end, we want to continue enabling developers to more easily learn how to build, train, and deploy machine learning models with PyTorch through new education programs.
Education courses bring AI developers together
Last month, Udacity and Facebook launched a new course, Introduction to Deep Learning with PyTorch, along with a PyTorch Challenge Program, which provides scholarships for continued AI education. In just the first few weeks, we saw tens of thousands of students actively learning in the online program. What’s more, the education courses have started to bring the developer community closer together through real-world meet-ups that have organically formed across the globe, from the U.K. to Indonesia.
The full course is now available to everyone free of charge through the Udacity website, and developers will soon be able to continue their PyTorch education in more advanced AI Nanodegree programs.
Beyond online education courses, organizations like fast.ai also offer software libraries to support developers as they learn how to build neural networks with PyTorch. fastai, a library that simplifies training fast and accurate neural nets, has garnered 10,000 stars on GitHub since its release two months ago.
We’ve been really excited to see the success developers have had with the library. For example, Santhosh Shetty used fastai to double the previous best accuracy for damage level classifications after disasters, and Alena Harley reduced the false-positive rate for tumor-normal sequencing by 7x compared with that of traditional approaches. In addition, Jason Antic created a project called DeOldify that uses deep learning for colorizing and restoration of old images.
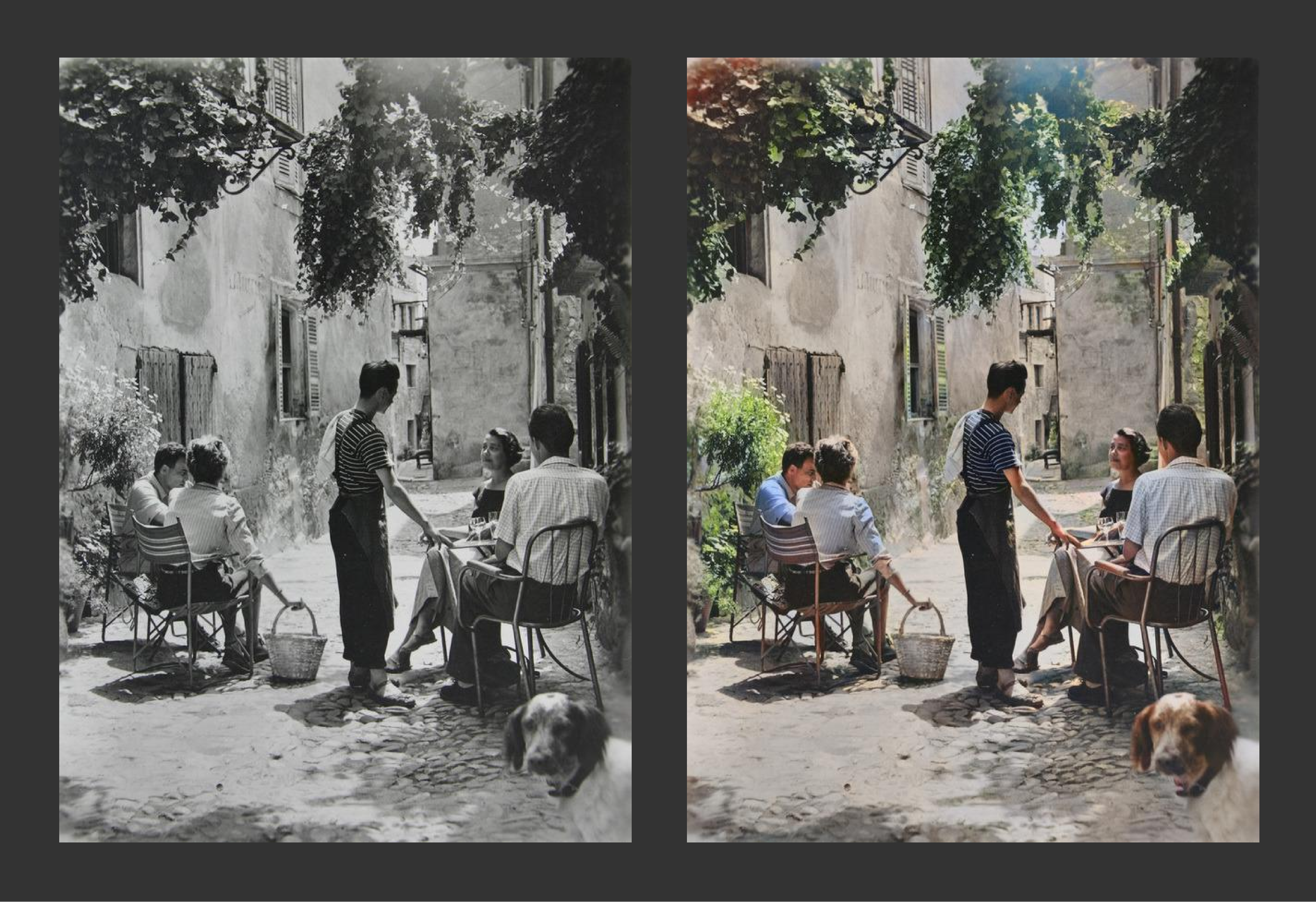 Image used courtesy of Jason Antic.
Image used courtesy of Jason Antic.
New projects extend PyTorch
PyTorch has been applied to use cases from image recognition to machine translation. As a result, we’ve seen a wide variety of projects from the developer community that extend and support development. A few of these projects include:
- Horovod — a distributed training framework that makes it easy for developers to take a single-GPU program and quickly train it on multiple GPUs.
- PyTorch Geometry – a geometric computer vision library for PyTorch that provides a set of routines and differentiable modules.
- TensorBoardX – a module for logging PyTorch models to TensorBoard, allowing developers to use the visualization tool for model training.
In addition, the teams at Facebook are also building and open-sourcing projects for PyTorch such as Translate, a library for training sequence-to-sequence models that’s based on Facebook’s machine translation systems.
For AI developers who are looking to jump-start their work in a specific area, the ecosystem of supported projects provides easy access to some of the industry’s latest cutting-edge research. (Follow @PyTorch to keep up to date.) We’re looking forward to checking out new projects from the community as PyTorch continues to evolve.
Getting started in the cloud
To make PyTorch more accessible and user-friendly, we’ve continued to deepen our partnership with cloud platforms and services such as Amazon Web Services, Google Cloud Platform, and Microsoft Azure. Just recently, AWS launched Amazon SageMaker Neo with support for PyTorch, allowing developers to build machine learning models in PyTorch, train them once, and then deploy anywhere in the cloud or at the edge with up to 2x improvement in performance. Developers can also now try PyTorch 1.0 on Google Cloud Platform by creating a new Deep Learning VM instance.
In addition, Microsoft’s Azure Machine Learning service, now generally available, allows data scientists to seamlessly train, manage, and deploy PyTorch models on Azure. Using the service’s Python SDK, PyTorch developers can leverage on-demand distributed compute capabilities to train their models at scale with PyTorch 1.0 and accelerate their path to production.
AI developers can easily get started with PyTorch 1.0 through a cloud partner or local install, and follow updated step-by-step tutorials on the PyTorch website for tasks such as deploying a sequence-to-sequence model with the hybrid front end, training a simple chatbot, and more. The updated release notes are also available on the PyTorch GitHub.
We look forward to continuing our collaboration with the community and hearing your feedback as we further improve and expand the PyTorch deep learning platform.
We’d like to thank the entire PyTorch 1.0 team for its contributions to this work.








