- Horizon is the first open source end-to-end platform that uses applied reinforcement learning (RL) to optimize systems in large-scale production environments.
- The workflows and algorithms included in this release were built on open frameworks — PyTorch 1.0, Caffe2, and Spark — making Horizon accessible to anyone using RL at scale.
- We’ve put Horizon to work internally over the past year in a wide range of applications, including helping to personalize M suggestions, delivering more meaningful notifications, and optimizing streaming video quality.
Today we are open-sourcing Horizon, an end-to-end applied reinforcement learning platform that uses RL to optimize products and services used by billions of people. We developed this platform to bridge the gap between RL’s growing impact in research and its traditionally narrow range of uses in production. We deployed Horizon at Facebook over the past year, improving the platform’s ability to adapt RL’s decision-based approach to large-scale applications. While others have worked on applications for reinforcement learning, Horizon is the first open source RL platform for production.
While we are working on a variety of reinforcement learning projects that use feedback to improve performance, Horizon is focused specifically on applying RL to large-scale systems. This release includes workflows for simulated environments as well as a distributed platform for preprocessing, training, and exporting models in production. The platform is already providing performance benefits at Facebook, including delivering more relevant notifications, optimizing streaming video bit rates, and improving M suggestions in Messenger. But Horizon’s open design and toolset also have the potential to benefit others in the field, particularly companies and research teams interested in using applied RL to learn policies from large amounts of information. More than just evidence of our continued investment in RL, Horizon is proof that this promising field of AI research can now be harnessed for practical applications.
Making decisions at scale: How Horizon harnesses RL for production
Machine learning (ML) systems typically generate predictions, but then require engineers to transform these predictions into a policy (i.e., a strategy to take actions). RL, on other hand, creates systems that make decisions, take actions, and then adapt based on the feedback they receive. This approach has the potential to optimize a set of decisions without requiring a hand-crafted policy. For example, an RL system can directly choose a high or low bit rate for a particular video while the video is playing, based on estimates from other ML systems and the state of the video buffers.
While RL’s policy optimization capabilities have shown promising results in research, it has been difficult for the artificial intelligence community to adapt these models to handle a very different set of real-world requirements for production environments. With Horizon, we focused on the challenge of bridging two very different types of applications: the complex but ultimately limited environments of research-related simulators; and ML-based policy optimization systems, which rely on data that’s inherently noisy, sparse, and arbitrarily distributed. Unlike the games in which RL-powered bots can respond to a constrained set of predictable and repeatable rules, real-world domains are impossible to simulate perfectly, and feedback can be harder to incorporate in deployed code, where any changes must be made with more care than is typically needed in a controlled, experimental setting.
Similar to how deep learning revolutionized the application of neural networks, projects such as Horizon have the potential to define how scientists and engineers apply RL to production settings, using policy optimization to make an impact. In particular, Horizon takes into account issues specific to production environments, including feature normalization, distributed training, large-scale deployment and serving, as well as data sets with thousands of varying feature types and distributions and high-dimensional discrete and continuous-action spaces.
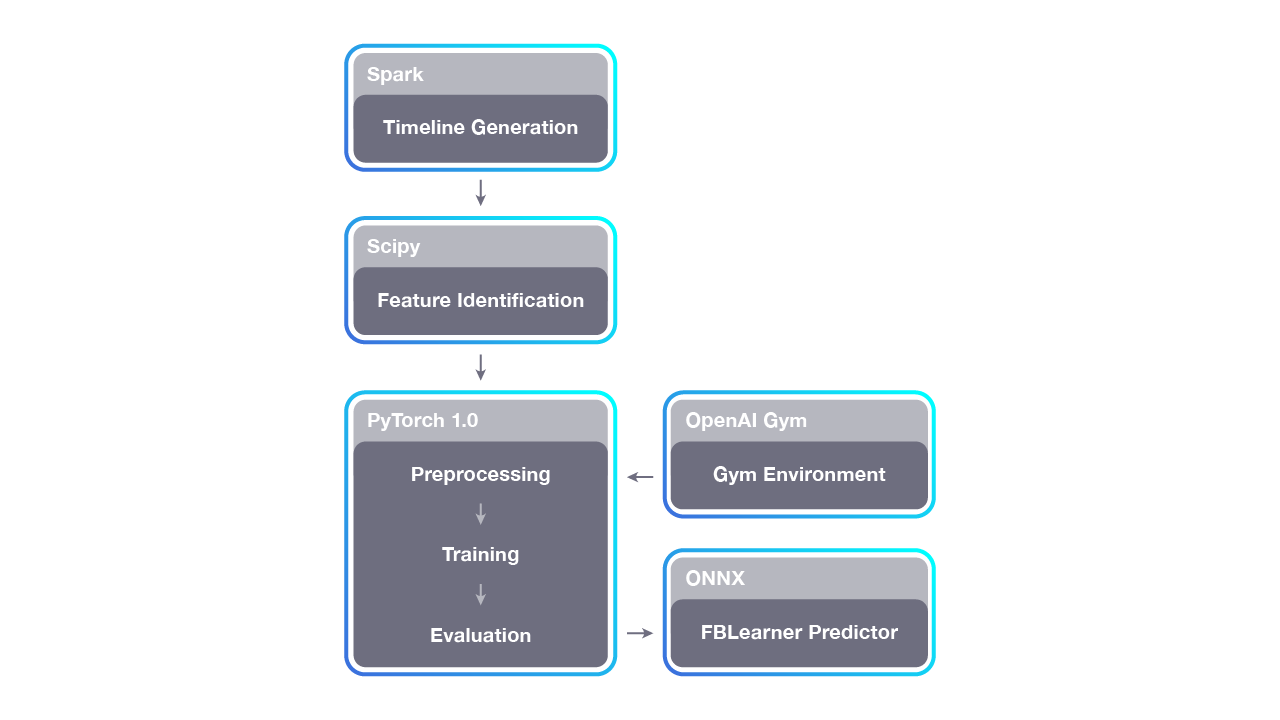
Horizon’s pipeline is divided into three components: (1) timeline generation, which runs across thousands of CPUs; (2) training, which runs across many GPUs; and then (3) serving, which also spans thousands of machines. This workflow allows Horizon to scale to Facebook data sets. For on-policy learning (e.g., using OpenAI Gym), Horizon can optionally feed data directly to training in a closed loop.
Horizon also addresses the unique challenges posed by building and deploying RL systems at scale. RL is typically trained in an online fashion, where a system begins by picking actions at random and then updates in real time. Given the scale and impact of these systems at Facebook, this randomness and real-time updating is not an option at present. Instead, our models begin by training on a policy that a product engineer designed. The models must be trained offline, using off-policy methods and counterfactual policy evaluation (CPE) to estimate what the RL model would have done if it were making those past decisions. Once the CPE results are admissible, we deploy the RL model in a small experiment in which we can collect results. Interestingly, we have found that, unlike prior systems that remain relatively constant, the RL systems continue to learn and improve over time.
Industry data sets often contain billions of records, as well as thousands of state features with arbitrary distributions and high-dimensional discrete and continuous-action spaces. From our research and observations, we have found that applied RL models are more sensitive to noisy and unnormalized data than traditional deep networks. Horizon preprocesses these state and action features in parallel using Apache Spark, and our Spark pipelines are included in the open source release. Once the training data has been preprocessed, we use PyTorch-based algorithms for normalization and training on the graphics processing unit.
And while Horizon can run on a single GPU or CPU, the platform’s design is focused on large clusters, where distributed training on many GPUs at once allows engineers to solve for problems with millions of examples, and to iterate their models more quickly. We use the data parallel and distributed data parallel features in PyTorch for this distributed training. The release includes Deep Q-Network (DQN), parametric DQN, and deep deterministic policy gradient (DDPG) models. During training, we also run CPE and log the evaluation results to TensorBoard. Once training is complete, Horizon then exports those models using ONNX, so they can be efficiently served at scale.
In many RL domains, you can measure the performance of a model by trying it out. At Facebook, we want to ensure that we thoroughly test models before deploying them at scale. Because Horizon solves policy optimization tasks, the training workflow also automatically runs several state-of-the-art policy evaluation techniques, including sequential doubly robust policy evaluation and MAGIC. The resulting policy evaluation report is exported in the training flow and can be observed using TensorBoard. The evaluation can be combined with anomaly detection to automatically alert engineers if a new iteration of the model has radically different performance than the previous one, before the policy is deployed to the public.
Learning on the job: Horizon’s impact on Messenger, 360 video, and more
In the year since we started using Horizon internally, the platform has demonstrated how RL can make an impact on production applications, by using immediate feedback to make performance-boosting decisions.
For example, Horizon has allowed us to improve the image quality of 360-degree video viewed on Facebook by optimizing bit rate parameters in real time. The platform factors in both the amount of available bandwidth and the amount of video that’s already been buffered, to determine whether it’s possible to shift to higher quality video. This process takes advantage of RL’s ability to create incentives in the moment, using new and unsupervised data — it works while a given video is playing, rather than analyzing performance and carefully annotated data after the fact.
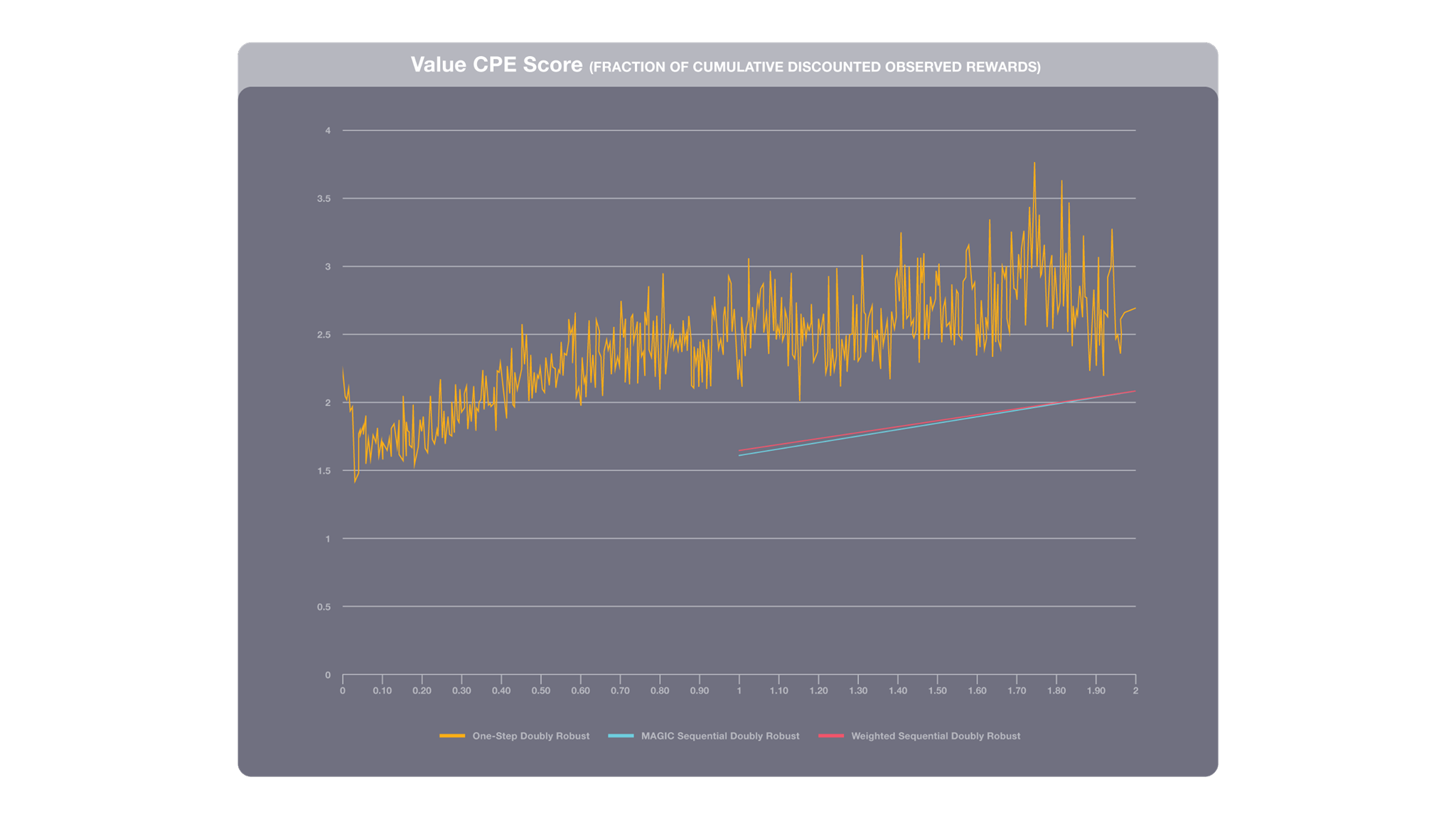
Counterfactual policy evaluation provides insights to engineers deploying RL models in an offline setting. This graph compares several CPE methods with the logged policy (the system that initially generated the training data). A score of 1.0 means that the RL and the logged policy match in performance. These results show that the RL model should achieve roughly 2x as much cumulative reward as the logged system.
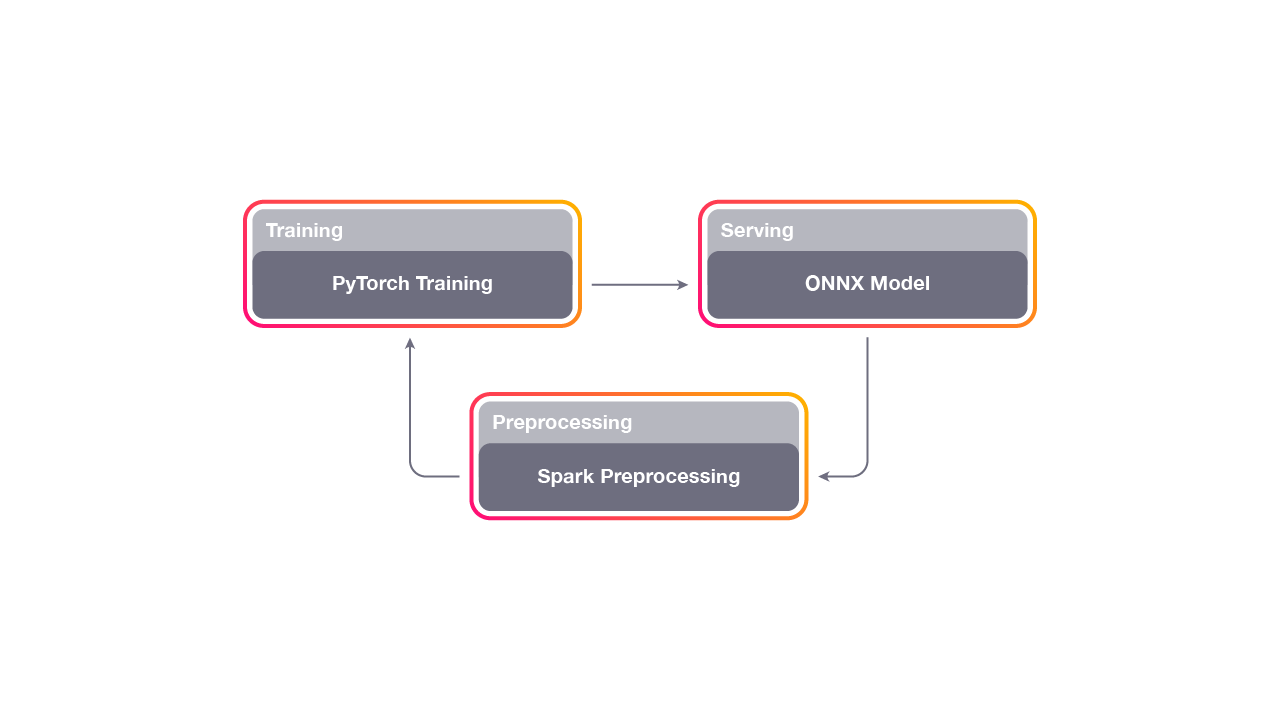
This high-level diagram explains the feedback loop for Horizon. First, we preprocess some data that the existing system has logged. Then, we train a model and analyze the counterfactual policy results in an offline setting. Finally, we deploy the model to a group of people and measure the true policy. The data from the new model feeds back into the next iteration, and most teams deploy a new model daily.
Horizon also filters suggestions for M, the intelligent assistant in Messenger. M offers suggestions in people’s open conversations to suggest relevant content and capabilities to enrich the way people communicate and get things done in Messenger. Horizon uses RL — which is more scalable, forward-looking and responsive to user feedback than rules-based approaches to learning dialog policies — to help M learn over time. For example, if people interact with one suggestion with more regularity, M might surface it more. With Horizon, M has become smarter and highly personalized as it helps millions of people communicate each day.
The platform has also improved the way we use AI to help determine which Facebook notifications to send to people and how often to send them. In the past, rather than sending every possible notification (indicating new posts, comments, etc.), we’ve used ML models to help predict which ones are likely to be the most meaningful or relevant and to filter out others. But these models relied on supervised learning and didn’t account for the long-term value of sending notifications. For example, someone who visits the platform multiple times a day may not need a notification for a post they would have seen anyway, whereas a less active person could benefit from notifications to make sure they do not miss noteworthy posts from family and friends.
To better address these long-term signals — and to make notifications work as intended, providing value to the entire range of people on the platform — we used Horizon to train a discrete-action DQN model for sending push notifications. This model receives a reward when someone engages on a post they would otherwise miss and a penalty for sending the notification. The RL model lets the notification through only when the value to the person (alerting them to a noteworthy post by a close friend or family member, for example) is higher than the penalty (an additional alert popping up on their device). The model is also regularly updated with large batches of state transitions, allowing it to improve incrementally and to ultimately tune the volume of notifications. Since we replaced the previous, supervised learning-based system with Horizon’s RL-enabled version, we have observed an improvement in the relevance of notifications, without increasing the total number of notifications sent out. Instead of defining relevance by tapping or clicking the notification, we can look more broadly and deeply to ensure that the information provides a real benefit.
Tools for anyone to deploy RL in production
These benefits highlight what RL has to offer the industry, which is the ability to learn optimal policies directly from samples gathered under a previous, sub-optimal policy. And though we’ve identified specific use cases and applications that are well-suited to RL, this is only the beginning of an exciting journey. Given the collective talent and creativity across the AI community, we can’t wait to see the ideas, features, and products that Horizon inspires.
Anyone who is using machine learning to make decisions can try Horizon. The first step is to log the propensity (the probability that the action was taken) and the alternatives (what other actions were possible). Horizon uses the propensity and alternatives to learn when a better action is available. The second step it to define and log the reward (the value that is received from taking the action). After this data is collected, it’s possible to run Horizon’s training loop and export a model that will make new decisions and maximize the total reward.
Horizon is part of our commitment to the open development of AI — it was an internal Facebook platform that we’re now open-sourcing, and it works with tools that we have already made available to the community, including PyTorch 1.0 and Caffe2. And although Horizon is tuned for production purposes, our experience with the platform has also revealed important research related to integrating RL into other systems. We are leveraging the Horizon platform to discover new techniques in model-based RL and reward shaping, and using the platform to explore a wide range of additional applications at Facebook, such as data center resource allocation and video recommendations. We’re also planning to add more models and workflows to help others turn RL’s long-term promise into immediate action. For more details, read our full white paper on the development and internal use cases for Horizon.
In addition to making an impact on new applications, Horizon could transform the way engineers and ML models work together. Instead of driving models by writing rules that are difficult to interpret and maintain, we envision a two-way conversation between engineers and the models they work with, in which engineers can specify their high-level goals, and work in tandem with machine learning to realize these goals and adapt them to an ever-changing decision landscape. Horizon is the first step in this journey, and we invite you to clone our GitHub repository and try it out.
We’d like to thank Yitao Liang for his contributions to Horizon.








