
Two years ago, we rewrote our mobile apps on iOS and Android to use the native development stacks in place of the custom web-stack we had been developing. This gave us finer control over when and how items were downloaded, cached, and freed. It also opened up access for deeper integration into the respective operating systems and revealed a full toolbox for tuning and tweaking all systems under the hood.
Testing is an important part of our development, but in switching to native, we lost the ability to A/B test. Not every test makes it into production, but even failed tests help us understand how to improve. Losing some of this ability became a challenge.
A/B Testing
Shipping our apps on iOS and Android requires developers from many different teams to coordinate and produce a new binary packed with new features and bug fixes every four weeks. After we ship a new update, it’s important for us to understand how:
• New features perform
• The fixes improved performance and reliability
• Improvements to the user interface change how people use the app and where they spend their time
In order to analyze these objectives, we needed a mobile A/B testing infrastructure that would let us expose our users to multiple versions of our apps (version A and version B), which are the same in all aspects except for some specific tests. So we created Airlock, a testing framework that lets us compare metric data from each version of the app and the various tests, and then decide which version to ship or how to iterate further.
Build from scratch
We began with the simplest experiment possible–using the A/B binning system we had for our web-stack, we constructed an experiment to test changing a chat icon into the word “Chat.” When the app started up, it would send a network request to our servers requesting the parameters for that experiment. Once the response came back, we would update the button and voilà, some employees had the icon and others had the word “Chat.” Our expectation was that the only effect it would have would be to impact the amount of messages sent and likely not by much, and that no other metrics would move.
Exposure logging
Once that version of the app went public, we waited for the data to stabilize and found that the people who saw the word “Chat” were much more engaged with the app. Had we found some secret, magic like-incentive? Sadly, no. We had arrived at a pile of bugs, the main issue being that one of the many components was incorrectly caching the value. With a system this large, the infrastructure had to be bulletproof or the data gathered was useless.
The data pipeline began with the server deciding which variant a given person belonged to. Then that value had to be packaged up and sent to the device, which would parse the response and store it. Next, the value would be used to reconfigure the UI and then it was finally available onscreen. The problem was that we were relying on the server’s categorization for our data analysis. A single bug led to a large number of people seeing a different variant than we had anticipated. The server was insisting, “I told the device to show the string!” but somewhere along the way the statement became a little fuzzy (a bug in the client storage logic).
Deployment graph for a given experiment
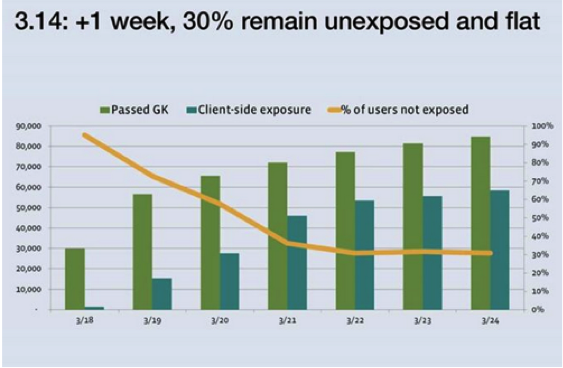
The graph above shows how an experiment was deployed. The light green bar is the number of people in the experiment and the dark green bar is the actual number of affected users. As we can see, the difference between the data from server and device are pretty large: at the first day, most people received the configuration but most users did not see our experiment.
This issue is coupled with the problem of not only what the device is told, but what our data analysts need to know when the device receives the information and shows it correctly in UI. Even if the information arrives correctly, there is a delay during which the UI is incorrect. We solved this by adding a two-way handshake. The device requests the data for an experiment and the server logs the response that it sends out. When the client actually uses data, it logs it on the server. Therefore, even if someone does not see what we want, we can still perform the correct analysis (but have to beware of selection bias or skew if the distribution ends up uneven for any reason).
Scale it up
Over the course of a few months, we had to scale our system from supporting two experiments to supporting many throughout the entire app. The experiment that drove the evolution of Airlock was a project we started with the intent of evolving and simplifying the navigation model within our apps. Over the course of a few months we tested making the left-hand drawer narrower with only icons, putting a tab-bar at the bottom of the screen with your timeline in it, combining friend requests and notifications into one tab in a tab-bar, and eventually landing on the tab-bar design that is now the user interface for the Facebook for iPhone app. We built a bunch of different versions of the UI that didn’t make the cut, but that’s the nature of testing.
The creation of Airlock helped us ship a navigation model that feels slicker, is easier to use one-handed, and keeps better track of your state in the app. This tool has allowed us to now scale the framework to support 10 or 15 different variations of a single experiment and put it in the hands of millions of people using our apps. We had to relearn the rules of not letting one experiment pollute another, keeping some experiments dependent and others exclusive, and how to ensure the logging was correct in the control group. The last bit was tricky because sometimes a control group means that some piece of UI doesn’t exist. How does one log that someone did not go to a place that doesn’t exist? Here we learned to log both the decision on which UI to construct and then separately to log the interaction with it.
As the framework scaled to support more experiments, the amount of parameters requests, data logging, and client-side computation began to rise very quickly. The framework needed to be fast on the client in order to have experiments ready without blocking any of the startup path, so we optimized the cold-start performance on our apps was so that basic, critical configurations could be loaded when the app starts and all heavy work was deferred until after the app’s UI is displayed. Likewise, we had to tune the interaction with the device and the server, minimizing the data flow and simplifying the amount of data processing on both ends.
Airlock has made it possible to test on native and improve our apps faster than ever. With the freedom to test, re-test, and evaluate the results, we’re looking forward to building better and better tests and user experiences.








