
As Facebook’s infrastructure has scaled to connect more than 1.5 billion people around the world, our networking team has unveiled a series of projects aimed at breaking apart the hardware and software components of the network stack to open up more flexibility, as we had previously done with our racks, servers, storage, and motherboards in the data center.
We started with Wedge, an OS-agnostic top-of-rack switch, and FBOSS, a set of network-oriented applications running on Linux that enabled the switch to operate with the same power and flexibility of a server. We then took the same disaggregated approach to our network architecture. We moved away from a hierarchical system of clusters to a data center fabric: smaller server pods that were connected to one another and behaved like one high-performance network within the data center. Finally, we built 6-pack, a modular switch platform that is used in our new fabric.
After we contributed Wedge to the Open Compute Project last year, it was accepted as an OCP switch, and thousands of them have been deployed throughout our data centers. We’ve also been testing the 6-pack hardware at the network level for our data center fabric and scaling our Wedge software beyond the top-of-rack to 6-pack requirements.
As we continue to work to scale our hardware and software networking components to operate at higher speeds and handle more complexity, we’re excited to announce at this year’s OCP Summit that we’re opening up the designs for 6-pack and our next-generation TOR switch, Wedge 100, which is an important step toward supporting 100G connectivity throughout our data centers.
We have submitted a detailed bill-of-materials, schematics, CAD, Gerber, and mechanic files, all in as native a format as possible to allow any contract manufacturer to produce these switches. In addition, we have also contributed our test plan outlines for others to see the extent of testing both at the hardware and network level that we perform. Given that OCP 100G switches and open modular switches are relatively new to the industry, we are looking forward to collaborating with the OCP community more on the design and deployment of 100G technologies.
Hardware

Wedge 100 – a 32x100G TOR switch
Wedge 100 is Facebook’s second-generation TOR switch:
- Uses Broadcom’s Tomahawk ASIC
- Supports the OpenRack v2 bus bar
- Now supports COM-E as the CPU module
- Supports the 100G QSFP28 DAC cables and 55C CWDM4 optic transceivers
We did this as a critical step toward supporting 100G throughout our data centers, especially for our new Yosemite servers.
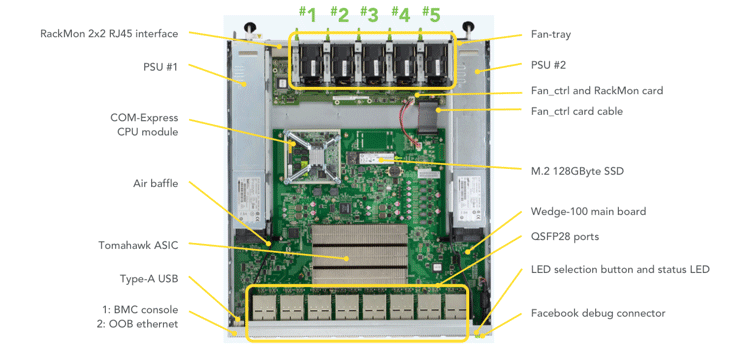
A lot of what we’ve done in Wedge 100 is to accommodate 100G connectivity and support the 55C optic at an ambient 35C environment by having the five-fan tray, avoiding recycling air, and having multiple on-board temperature sensors.
We’ve also performed extensive hardware testing to ensure all the varied connectivity we need is supported. We have standardized on CWDM4 for the QSFP28 optical transceiver, but it can work with standards from other MSAs, including SR4, LR4, and CLR4. It also supports different types of DAC cables.
We have tested our QSFP28 port in the following modes:
- 1x100G: CWDM4 QSFP28 optic (to connect to a 100G switch port)
- 2x50G: QSFP28-2xQSFP28 Y-cable (Y-cable that connects to Yosemite’s CX4 NIC)
- 4x25G: QSFP28-4xSFP28 fan-out cable (to connect to Leopard 25G NIC)
- 1x40G: QSFP+ 40G SR4 optic and QSFP+ 40G LR4 optic (to connect to a 40G switch port)
- 4x10G: QSFP-4xSFP fan-out cable (to connect to 10G SFP+ NIC)
Later this year, Wedge 100 will be entering mass production, and when it does, we will update the design package we have contributed at the OCP Summit. At the same time, we will work with our ODM partner, Accton, to make Wedge 100 available for others to order, and customers will be able to load FBOSS software or other open source software onto it.
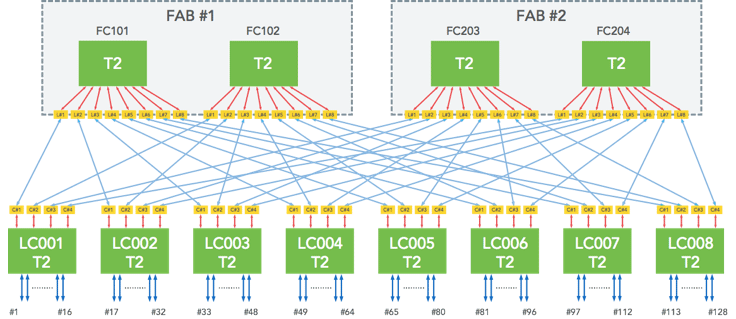
6-pack – a 128x40G modular switch
We’ve already covered the general architecture of 6-pack. This is the internal connectivity among all the fabric and line cards:
In addition to the data plane, we also have an OOB Ethernet network:
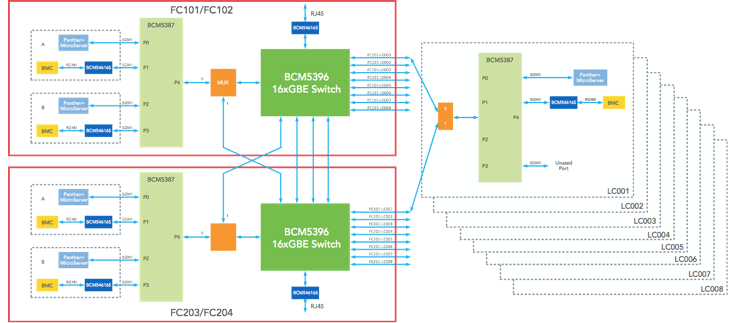
Beyond the connectivity, 6-pack is effectively 12 of our Wedge 40 switches in a physical enclosure. We designed this specifically for modularity and scale. Much of the challenge around 6-pack was related to the network-level design (fabric) and the software, and we will cover those below.
Hardware testing in the network
Once we have designed and built the hardware and performed the appropriate hardware-level testing, we then move the hardware into network-level testing. We do that for every switch, but here, we will cover specifically the network-level testing we did for 6-pack within our data center fabric.
The smallest building block in our fabric is a server pod: 48 top-of-rack switches connected to four fabric switches (FSWs). This is significantly smaller than the previous generation of topology we had in Facebook data centers (where a cluster switch could have hundreds of top-of-racks attached to it). We targeted the FSW as the first place where a 6-pack running FBOSS would be deployed.
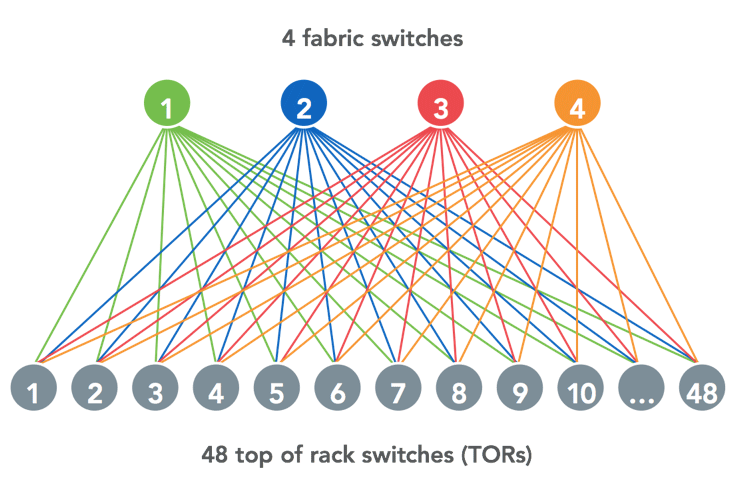
The FSWs in these server pods are connected to various other switches, including spine switches (SSWs) in multiple spine planes and edge switches (ESWs) in edge pods. In addition to many different types of peerings, FSWs have a number of other requirements:
- Aggregation of traffic from the RSWs
- Heavy use of BGP policies
- Heavy use of ECMP
- Quick reaction to link failures
As part of developing our data center fabric, we built an extensive test topology that would allow us to evaluate both third-party switches and our own Facebook switches. We leveraged and developed a number of testing tools, including prefix injection and traffic generation as well as statistics collection and dashboards.
Through work in this test lab, we found that the scalability and performance requirements grow by over an order of magnitude over what is expected of the top-of-rack switch:
- 16K routes need to be programmed on a 6-pack as opposed to 1K on a Wedge.
- Traffic rate on 6-pack is up to 5.12Tbps, while it’s 640Gbps on Wedge. This means that even millisecond-scale outages during service software updates would be much more noticeable on the 6-pack than on the Wedge.
- Failure domain increases to over 48 racks.
- Up to 112 active BGP peerings as opposed to just four on a Wedge.
We will go over some of the most critical test scenarios in the fabric for an FSW.
1. Functionality
We use BGP everywhere, and there were many BGP peerings to validate for an FSW:
- Peerings within the FSW itself (among all the line cards and fabric cards)
- Peerings down to the 48 top-of-rack switches
- Peerings up to spine switches
Below is an example of FBOSS command-line output that we used to verify the peerings.

In addition, there was significant route policy processing to validate. From a data plane perspective, we also had to check that ECMP was working across all links at all tiers.
2. Failure conditions
We tested all sorts of failures, including:
- Bringing BGP peers up and down
- Inserting/removing DAC cables and fiber optics
- Inserting/removing line cards and fabric cards in the 6-pack
- Killing/restarting various FBOSS processes
- Bringing the whole 6-pack up and down
The initial testing with these failures is verification of correctness and functionality. After that, we performed these failures very quickly and over time to validate 6-pack and FBOSS were able to function properly under such stress. For example, we repeatedly flapped all 16K routes every 60 seconds continuously and expected correct operations.
3. Performance testing and effect on traffic
During all this failure testing, we measured the impact on traffic forwarding and how much traffic was being dropped. For example, we might shut down an interface and then measure the effect on inter-pod traffic. This means that the interface shutdown has to be detected, propagated locally within the 6-pack, and then propagated up to the spine switches and down to other pods. With 1 million packets per second as data traffic, we measured only 1900 packets were dropped. This effectively means the failure was handled and rerouted within 2 milliseconds!
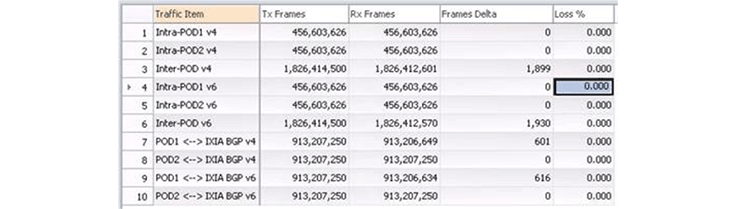
Finally, while a number of these tests are automated (especially the ones for various failure scenarios), we still have the goal to automate this entire test suite so we can validate new SW images more quickly.
Scaling software beyond the top-of-rack
Now that we’ve looked at the hardware itself and the network topology, it’s time to deep dive into the software, FBOSS.
By the middle of 2015 we had matured the FBOSS software and overcome many operational challenges. In this effort we were greatly helped by the fact that the software architecture of FBOSS on Wedge looks a lot like the architecture for our regular servers and shares many existing Facebook components. At the point of this writing we now have thousands of Wedges running FBOSS software in production.
We already had our test setup in place for the data center fabric topology, and so we turned our attention to FBOSS running on a 6-pack-based fabric switch (FSW). As we looked at the test setup for fabric, we realized this was going to be a much more difficult level of control plane complexity than we had tackled for Wedge.
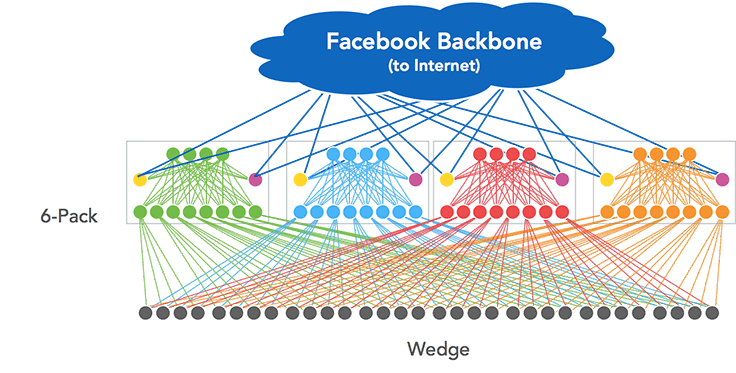
BIG decision: No central brain, just a bunch of Wedges
Brainstorming on how we would build this chassis switch, we first considered the traditional model of building these big switches, where there is a supervisor module that serves as the brains of the system. The supervisor module implements all the required routing protocols and programs the forwarding ASICs located on the connected line cards, which in turn act as dumb forwarding devices. We deliberately did not take this approach. Instead, we viewed the 6-pack as just a set of Wedges connected together.
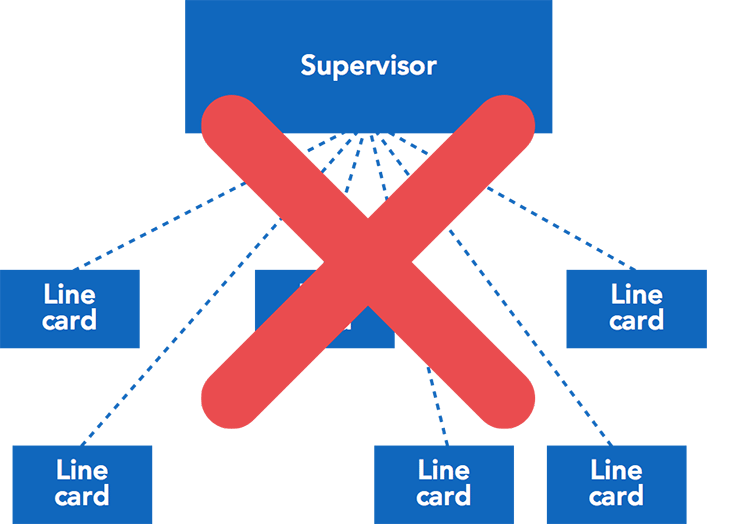
Looking inside the 6-pack, we see something like this, and this topology looks deliberately like the pod design of our data center fabric.
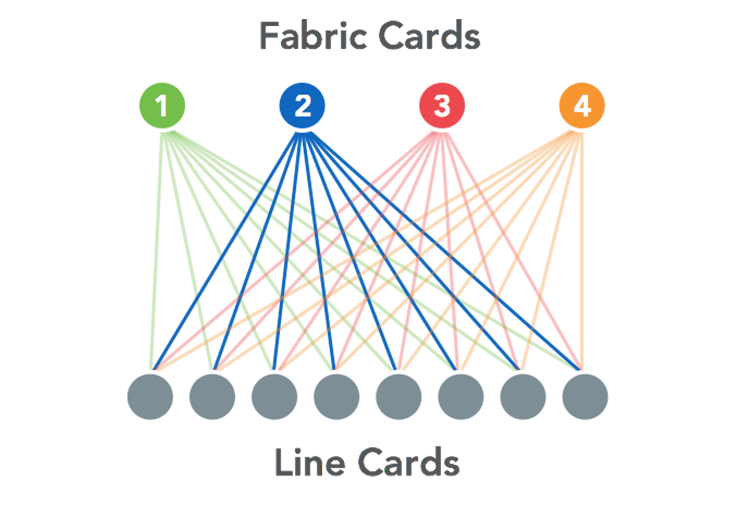
We viewed each of these line cards and fabric cards as a individual Wedges, each running an independent instance of identical FBOSS software. BGP was chosen as the internal protocol to communicate between the line and fabric cards. These choices had some great upsides for us:
- We could start testing on 6-packs from day one, by just running Wedge software on each of the cards.
- Since Wedge and 6-pack would be running identical software any improvements made for one would automatically be available for use on the other.
- BGP is the routing protocol of choice in our data center fabric. That meant we have to just get one routing protocol right for communicating in both external and internal topologies.
- All monitoring tools that monitor system or link health would now look inside 6-pack and give precise information about internal 6-pack components as well.
With this design philosophy settled, we then started tackling trying to make the Wedge software scale to 6-pack requirements. As described in the previous sections, there was a long list of criteria to specify, benchmarks to meet, and tests to pass. Below, we highlight a few of the challenges we addressed along the way.
1. Out of TCAM!
Looking at the Broadcom Trident 2 ASIC (the forwarding chip that powers Wedge and 6-pack) specifications, it was obvious that we wouldn’t be able to fit the 16K (8K IPv6 + 8K IPv4) routes in the chip. Not surprisingly, the first time testing just installed Wedge software in the test lab, nothing came up at all.
We found two features on the Trident 2 – Unified forwarding tables (UFT) and Algorithmic LPM (ALPM) – that could be of help here, and we choose UFT. This allowed us to partition the CAM and TCAM memories in a way that suited us. We leveraged the fact that Trident 2 lets you put host routes in CAM tables, leaving precious TCAM space to be utilized solely for prefixes that really need longest prefix matching. With these optimizations we were able to fit the routes and get our testing of the ground.
2. Why so slow?
Even though we could now get the routes programmed on the cards, programming and unprogramming them still took a very long time — a laborious 300 seconds. The CPUs were running very high during this time, pointing to bottlenecks in the software. Worse, this would cause BGP keepalive messages to get delayed, leading to session flaps, which in turn caused cascading instability.
At this time, we considered more hardware-oriented options like using FPGA chips to speed up route programming. However, this late in the design process, this was not an option for us, and our challenge was to solve this purely in software. At this point we turned to the software profiling tools we knew well and started revisiting the design of how routes were stored and looked up in our software. With multiple rounds of software optimization and profiling, we are able to get the 16K route programming time down to ~5 seconds, which was our benchmark. Of that time, 90+ percent is spent in actually doing the work on the Trident 2 ASIC.
3. Half the links not used?!
As described in the test topology above, we had Wedge switches uplinked to a 6-pack and a vendor switch. The 6-pack was then uplinked to next layer switches (our spine switches). We had ECMP paths set up between Wedges and 6-pack and the vendor switch and between 6-pack, the vendor switch, and the SSWs. We observed that while the Wedges were utilizing links in its ECMP group toward 6-pack evenly, the 6-pack only sent traffic on half its uplinks on the ECMP group toward the SSW. Interestingly, if we shut down the vendor switch, 6-pack would start utilizing all links in its ECMP group.
We were running into a classic problem in switching, known as hash polarization. Recall that Wedge and 6-pack are running the same software. That meant that they were using the same hashing function to distribute packets over links in an ECMP group. Chaining two identical hashing functions in such a way is a surefire recipe for getting poor ECMP link group utilization. To fix this, we came up with new hashing functions, so we could use different hashing functions on each layer of the network fabric. This applies both to the internal and external topologies – i.e., different hashing functions get used on the Wedge vs. line card and line card vs. fabric card.
4. If a link/line card/fabric card/6-pack fails in a fabric, does anyone notice?
In our experience running a large network, we know that component failure will be a common occurrence. The challenge we set ourselves was that a failure in the fabric should go unnoticed to end users of the network.
We started with measuring impact of link failures in our lab topology presented above. While we were able to get our route programming down to 5 or 10 seconds, that is still too long to handle link failures. Taking a systems view, this is what was happening upon a link failure:
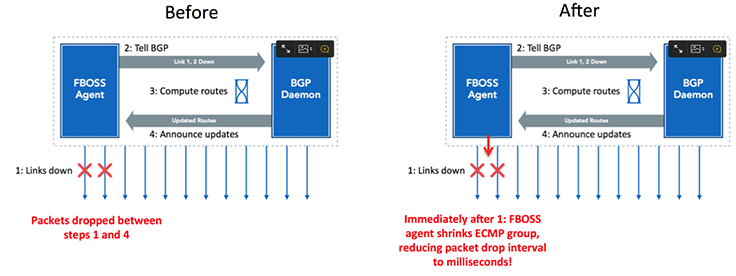
Imagine we have a ECMP group for a route, which includes all the links shown by arrows in the diagram above. When links go down, the following steps happen:
- FBOSS agent (the process which talks to the switching ASIC) notices the link failures.
- FBOSS agent sends a message to BGP daemon telling it that peers reachable over the down links are no longer reachable. This is done to short circuit BGP peer’s timing out due to keep alive messages being missed.
- BGP computes new routes, taking out the routes reachable over the next hops going over the down links.
- FBOSS agent updates the routes in FIB and shrink the ECMP group.
The above situation meant that we would continue to lose packets during steps 1, 2, and 3. The time we lost packets for would also vary depending on the number of failures and how close they occurred to each other. To see why, imagine that multiple links failed very close (in time) to each other. This may cause multiple updates to be queued on the FBOSS agent. This would cause packets to be lost until all updates were applied.
Once we look at the system in that way, the solution becomes almost obvious. Rather than waiting for BGP to tell us of the updated routes, we just had FBOSS agent shrink the ECMP group on noticing the link failure. This meant that we could get the packet loss time to be on the order of a few milliseconds. Steps 2 to 4 would still continue to update data structures in the software.
Tackling link failure in this way actually solves bigger failures as well. A line card failure, fabric card failure, or even a 6-pack failure is seen by its neighbors as just a set of link failures. Now that we handle link failure quickly, all of these failure modes are addressed quickly. Further, since the same FBOSS software runs on a Wedge as on a 6-pack, we now automatically handle link failures on Wedges as well.
Looking back, looking ahead
Looking back, we’re excited about how far our hardware, our network test capabilities, and FBOSS itself have progressed over the last year. This has been an awesome effort from all our teams, including network hardware, network engineering, and network software. We’re now at thousands of Wedges across the Facebook network, and we’re looking ahead to scaling out our newly contributed hardware as well. We expect to address even more roles beyond the FSW, moving to the spine switches and the edge switches.
Also, the reason we share our hardware and network designs and our tests and software is to help bring change to the networking industry and to continue to broaden the networking ecosystem. We look forward to collaborating with the ecosystem on our open hardware designs, 100G optics testing, network level testing, and software solutions. Looking forward already to the next summit!








