
Large-scale companies serve millions or even billions of people who depend on the services these companies provide for their everyday needs. To keep these services running and delivering meaningful experiences, the teams behind them need to find the most relevant and accurate information quickly so that they can make informed decisions and take action. Finding the right information can be hard for several reasons. The problem might be discovery — the relevant table might have an obscure or nondescript name, or different teams might have constructed overlapping data sets. Or, the problem could be one of confidence — the dashboard someone is looking at might have been superseded by another source six months ago.
Many companies, such as Airbnb, Lyft, Netflix, and Uber, have built their own custom solutions for this challenge. For us, it was important to make the data discovery process simple and fast. Funneling everything through data experts to locate the necessary data each time we need to make a decision was not scalable. So we built Nemo, an internal data discovery engine. Nemo allows engineers to quickly discover the information they need, with high confidence in the accuracy of the results.
We have more than a dozen different types of data artifacts, including Hive tables that store raw data, Scuba tables, dashboards, AI data sets, and Cubrick. Before Nemo, internal surveys indicated that finding the right data was a major pain point for data engineers. Nemo has dramatically improved that, increasing the data search success rate by more than 50 percent, even as the total number of artifacts has more than tripled and queries per second (QPS) has more than doubled.
Data discovery
A data engineer is interested in seeing how his latest experiment influenced latency. A product manager wants to see country-based usage trends over the past quarter. A production engineer wants to list task crashes grouped by the owning team. Each of these people knows that the information is available somewhere, but the knowledge of where to look is often limited to a small number of senior employees. Even phrasing the query properly is tricky: What search terms would you use to ask for “that table that lists share events”?
Various grassroots solutions have sprung up, but scalable solutions are not easy to come by. As we grow, the problem intensifies, both because the number of new tables created each day grows in turn, and because the distance — physical or organizational — between the team that created the data and the team that consumes it increases. Our original data discovery solution used an Elasticsearch cluster to index metadata about each artifact — its creator, size, column structure, description, etc. Searches were plain text. As the data sets grew, search quality deteriorated.
Nemo revamps this original solution in several ways: We use Unicorn, the same search infrastructure used for the social graph, to store data, which resolves scalability issues. Searches can be more sophisticated, allowing engineers to, for example, restrict a search to dashboards that are viewed at least 200 times per month or to tables that contain data from the past week. Searches can also filter out tables with data privacy restrictions in place. Personalization signals are also incorporated, taking an engineer’s role and team into account, and we use a gradient-boosted decision tree model in a post-ranking phase, which incorporates a wide array of signals from the metadata.
Also, Nemo has the ability to parse and answer natural language queries. For instance, you can ask “How many weekly active users are there on Instagram?” and get a pointer to the table that contains the relevant data. Of course, in order to actually see the data, you need the proper permissions, which are already built into the search engine. Last, Nemo uses trust signals it extracts from the data that reflects data quality, recency, usage and lineage. These signals are used in the ranking process so that people can find high-quality results while not compromising on their relevance.
Search engine architecture
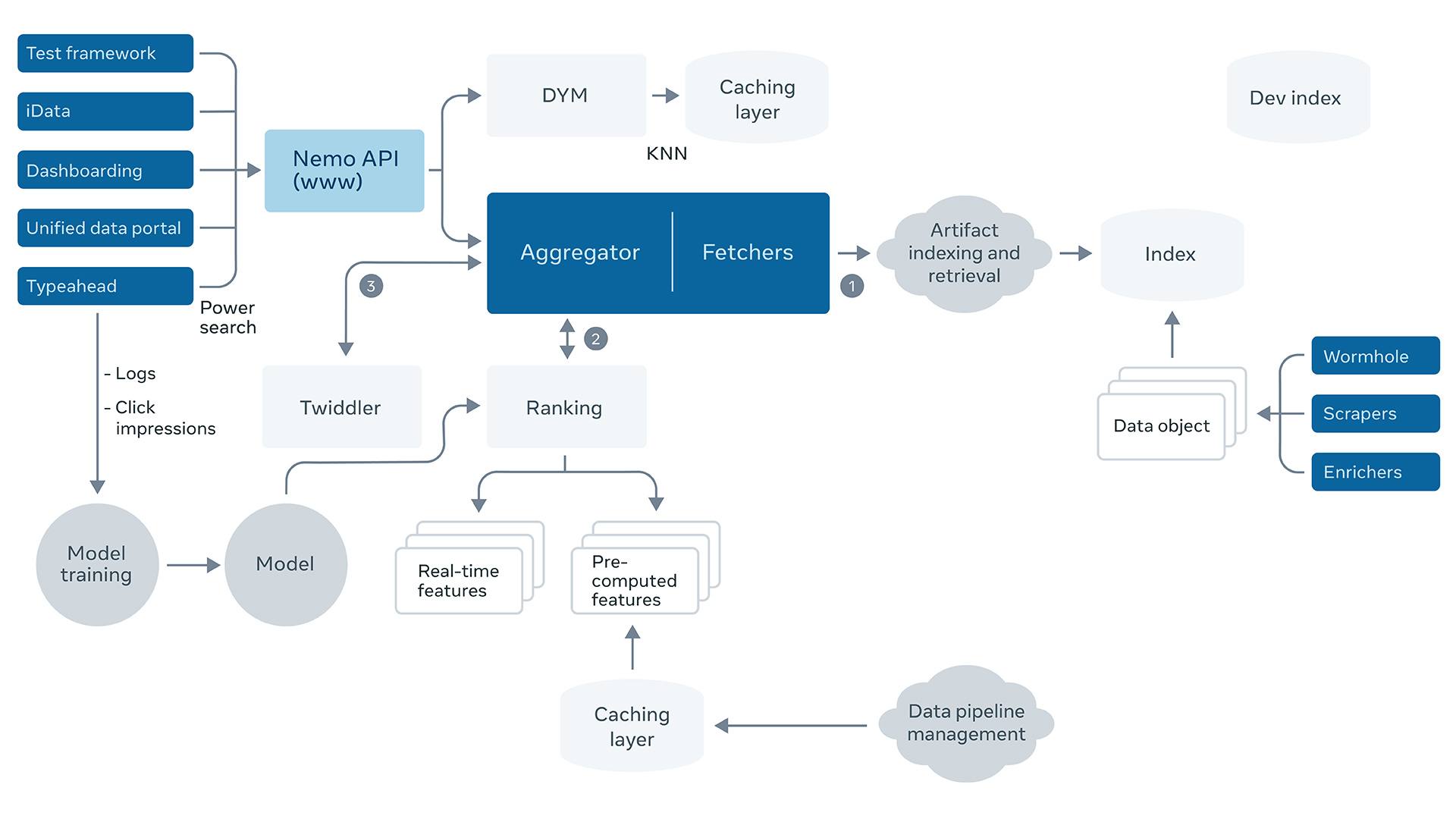
Nemo has two major components, indexing and serving, with a front end on top of the serving section. Indexing is in turn divided into bulk indexing, which happens daily, and instant indexing, which updates the index immediately. Thus, whenever a Hive table is created, an instant update guarantees that it is findable by name or creator within seconds. Other signals, such as the number of engineers who accessed the table over the past month, are collected in a heavier bulk process and can lag by a day or two. While the biggest data artifact sources, such as Hive, are handled by the engineers working on Nemo itself, engineers who create a new type of data artifact can make their artifacts searchable on their own by invoking the Nemo APIs.
Nemo indexing is generally aware of our data ecosystem. For example, if a data pipeline duplicates a column into a downstream table, the original column’s description and the upstream table’s name are also stored for the downstream artifact. Presto queries of data artifacts are noted, so if an engineer performs a Presto query, that will increase the Nemo score both generally, for that table, and for the specific engineer who performed the search.
For serving, a spaCy-based NLP library performs text parsing; the retrieval and initial ranking steps are handled by Unicorn, and more sophisticated signals (like kNN-based scoring and the FBLearner-trained ML model) are used for post-processing. In addition, various social signals — such as the list of users of a given artifact — are factored in during post-processing. Textless queries, which are usually just a list of type and quality restrictions, are specially handled, with the final score emphasizing usage at the personal and team level.
The front end is responsible for displaying results and various other technicalities, like providing a query-building system so that users can easily specify multiple restrictions, which are simply translated into Unicorn queries. It also highlights duplicated or low-quality artifacts to steer users toward the correct choice.
Nemo signals vary widely, from simple textual ones (degree of overlap between artifact name and query text) to content-aware ones (how many widgets appear in this dashboard) to highly personalized ones (how many people with your role have accessed this table recently). Nemo also computes a trust score for artifacts, indicating how likely they are to be a reliable source of data. This score is independent of the specific query and focuses on usage and freshness signals, using manual heuristics. When evaluating result quality for training, Nemo counts not just clicks but also other actions taken by the user. For instance, if an artifact was shown to the user and then they accessed it later that day, that is generally a good indication that they found it useful.
Lessons learned
We are a large company, but the number of internal users is still orders of magnitude less than the number of people who use our apps and services. Because of this, when we iterated on the model, each A/B test took a significant amount of time (days or weeks), and running multiple tests in parallel was impractical. In addition, labeling was not trivial: Deciding whether a search result is correct usually requires domain-specific experience, and the data set is quite volatile, so the half-life of high-quality labels is low. Creating “golden sets” for testing and training was a periodic time sink, but it was important to enable development.
As with any large organization, not all our data can be up-to-date simultaneously. By recognizing signals as to which artifacts should be used, Nemo also plays a role in maintaining code and data health. Proper ranking reduces the chance that an engineer might use outdated artifacts. Similar to the trend of direct answers in a browser search bar, Nemo is becoming more about intent and less about the raw search terminology over time. Nemo is already used by tens of thousands of engineers as part of their regular workflow, directing them to the information they need, and it will grow with us as we continue to grow. With Nemo, we have a scalable solution for the future.







