
More than a billion people now use Facebook Messenger to instantly share text, photos, video, and more. As we have evolved the product and added new functionality, the underlying technologies that power Messenger have changed substantially.
When Messenger was originally designed, it was primarily intended to be a direct messaging product similar to email, with messages waiting in your inbox the next time you visited the site. Today, Messenger is a mobile-first, real-time communications system used by businesses as well as individuals. To enable that shift, we have made many changes through the years to update the backend system. The original monolithic service was separated into a read-through caching service for queries; Iris to queue writes to subscribers (such as the storage service and devices); and a storage service to retain message history. This design optimized Messenger for a mobile-first world and helped fuel its success.
To help improve Messenger even more, we now have overhauled and modernized the storage service to make it faster, more efficient, more reliable, and easier to upgrade with new features. This evolution involved several major changes:
- We redesigned and simplified the data schema, created a new source-of-truth index from existing data, and made consistent invariants to ensure that all data is formatted correctly.
- We moved from HBase, an open source distributed key-value store based on HDFS, to MyRocks, Facebook’s open source database project that integrates RocksDB as a MySQL storage engine.
- We moved from storing the database on spinning disks to flash on our new Lightning Server SKU.
The result has been a better experience for Messenger users themselves, who can now enjoy a more responsive product with enhanced functionality, such as mobile content search. We also have improved system resiliency, reduced latency, and decreased storage consumption by 90 percent. This was achieved in a seamless way that did not cause any disruption or downtime, but it required us to plan for and execute two different migration flows to account for every single Messenger user.
Handling the challenge of migrating at scale
HBase had been our database since 2010 and it served us well, but the change to MyRocks helped us realize several important benefits. We can now leverage our new Lightning Server SKU, from the Open Compute Project, to serve data housed in flash storage instead of relying on spinning disks. Also, the replication topology for MySQL is more compatible with the way Facebook data centers operate in production, enabling us to reduce the number of physical replicas of data while producing better availability and disaster recovery.
Once we decided to update the service and move to MyRocks, migrating data between storage systems while keeping Messenger up and running for more than 1 billion accounts proved to be an interesting challenge.
We wanted to make sure people using Messenger had an uninterrupted experience during the migration process. The migration required extensive reading across all historical data on HBase clusters, which are I/O operations bound. If we proceeded too aggressively, we would downgrade the performance of HBase, leading to errors that negatively affect the user experience. Also, business users often have many Messenger chat windows active simultaneously around the clock for tasks such as helping with customer service, taking online orders from customers, or providing updates based on customers’ requests. This also meant that as we worked on the migration, we had to make code changes to support new product features on both the old and new systems so that people using Messenger would not experience disruptions when their accounts were moved to the new database.
It was also crucial to ensure that we migrated all the information for every single Messenger account, which meant petabytes of information. Since we were changing the data schema, we had to carefully parse the existing data, handle messy legacy data, cover corner cases, and resolve conflicts so that people saw the exact same messages, videos, and photos as before.
As we were also migrating to a brand-new database, we were also developing the service and designing and manufacturing the Lightning flash servers at the same time. Rolling out the new service required fixing software, kernel, firmware, and even physical power path bugs.
To address these challenges, we designed two migration flows for all Messenger accounts. The normal flow covered 99.9 percent of accounts, while the buffered migration flow covered the remaining, hard-to-migrate accounts. We did a thorough data validation, prepared a revert plan, and performed an accounting job to verify we didn’t miss anyone. When we were confident we had migrated every account to the new system, we finally took the old system offline.
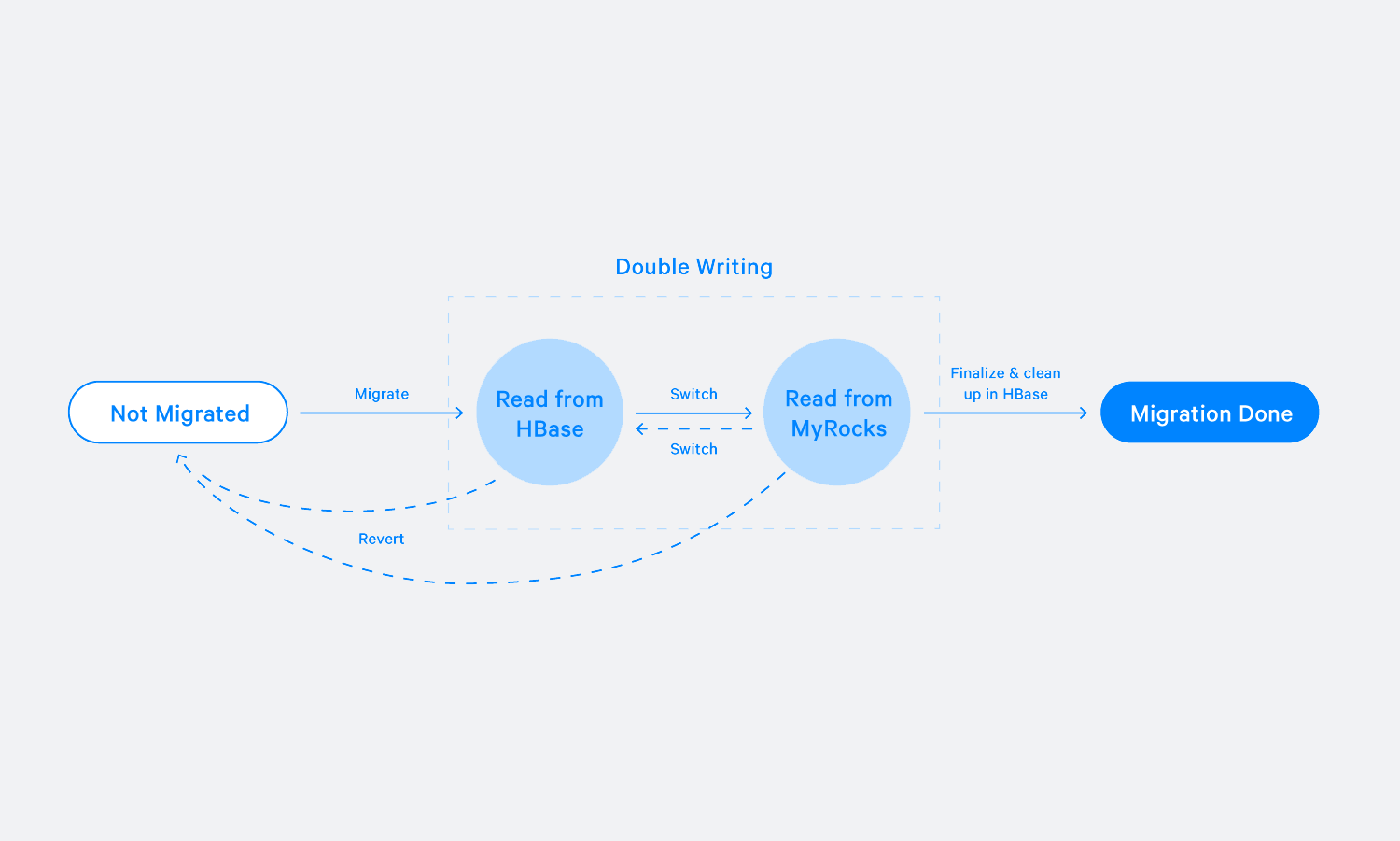
Normal migration
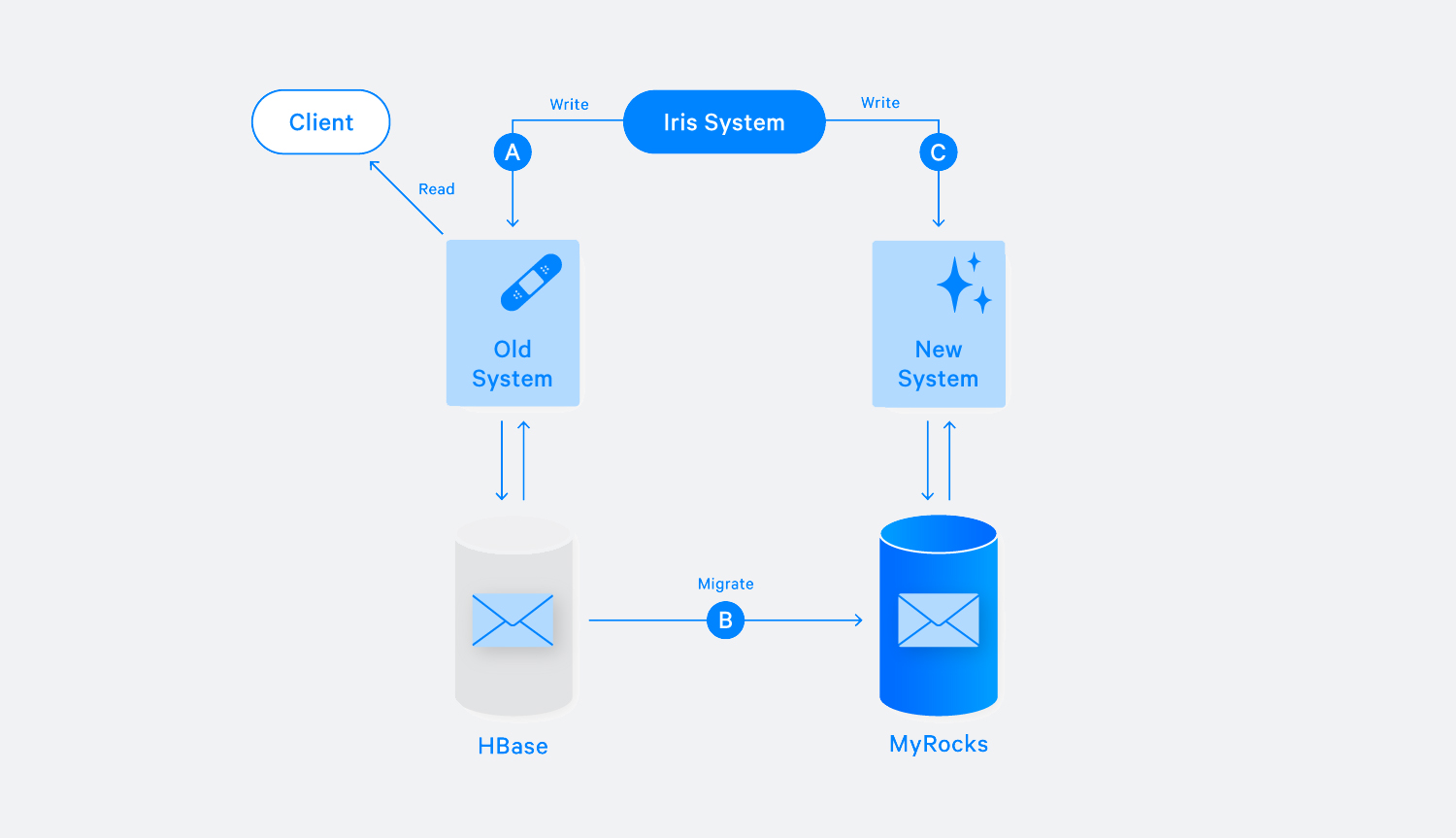
It is critical to have strong data consistency before and after migration to ensure the correct product experience. The basic single-user migrator does this through a crucial assumption: that no data is written to the account during migration. To ensure this, we clearly defined the state machine and developed abundant monitoring tools. For each account at any given time, the state machine puts it in one of three “static states” (not-migrated, double-writing, or done), or it is in a “dynamic state” and is actively undergoing migration. When migration starts, we log the last position of data in the old system (both the storage service and Iris have this information) and then start migrating data to new system (shown in step B in Chart 2 below). Once finished, we check whether the data position moved. If not, the account now allows writing traffic to the new system (step C in Chart 2) and enters the double-writing state. Otherwise, we classify this account migration as failed, clean up the data in MyRocks, and let a future migration job try to migrate that account again.
During the double-writing step, the migrator performs data validation and API validation to ensure accuracy. For data validation, we confirm that the data we have in HBase matches the data in MyRocks. If both systems process the data identically, the data will conform no matter how many new messages are received. For API validation, we issue read requests to both systems, old and new, and compare responses to make sure they are equivalent, in order to make sure the client can read seamlessly from either system.
Before reaching the done status in the workflow, we verify that the account has been successfully migrated. If issues are detected, there is a complete revert plan that can roll back an account to the not-migrated state. Whether migrating an individual or a large group of Messenger accounts, we developed tools to switch where their reads are served from as well as reverting back to the old system and wiping the data from the new system.
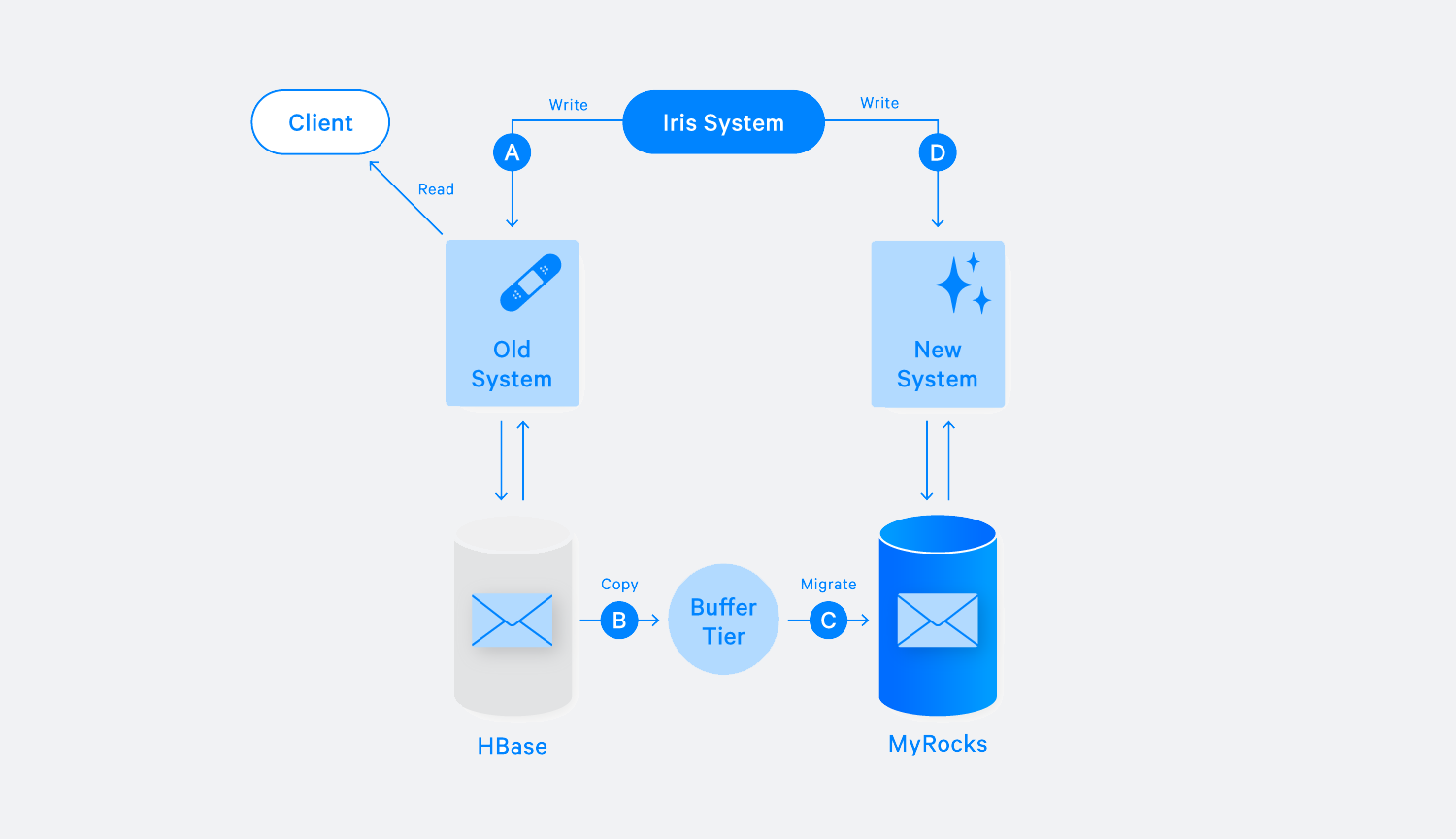
Buffered migration flow
Some accounts cannot be migrated in the normal way. For example, a large business may run a Messenger bot to serve its customers, and there is no window of time to perform the migration when new messages aren’t coming in. These accounts might also be much larger than is typical. So we developed a different flow to migrate these users. We set a cutoff time, called a migration start time, and then take a snapshot of the account’s data at that moment. We then copy the snapshot to a buffer tier (step B in Chart 3), which usually takes about 10 percent of the migration time. Then we migrate the data from the buffer tier to MyRocks (step C in Chart 3). Meanwhile, the write traffic to the new (MyRocks) system is queueing up in Iris (step D in Chart 3). Iris was designed to be able to queue messages for weeks, so we were able to concurrently migrate hundreds of high-volume accounts, with each one receiving up to thousands of messages per second. Once all data from the buffer HBase tier is migrated, the account enters the double-writing state as a normal flow: We resume write traffic to MyRocks. The new system then quickly drains the queue and catches up with the old system.
In this workflow, we also have two options to choose a buffer tier. We’ve built a dedicated HBase tier as the buffer tier, which keeps the exact same schema as old system; this approach can work for most accounts in the buffered migration flow. But for accounts with an extremely large amount of data, we reserve dedicated servers with SSDs, using embedded RocksDB as a buffer. This made their migration even faster.
Migrate at scale
To manage migration jobs at a high level, we’ve leveraged the Bistro framework, another Facebook open source project, to parallelize the work. We are able to flexibly schedule jobs, track progress, log and analyze the progress, and throttle jobs if issues arise with the service.
When we start to mark migrated accounts as “done,” all new Messenger accounts are then created on the new system only. We gradually stop writing traffic to HBase, one cluster at a time. We then run an accounting job to make sure every single account found in HBase has actually been migrated and no account has been left behind. Through this approach, we were able to finish this mass migration with 100 percent of Messenger accounts moved to the new system.
Benefits of the new system
In the end, we migrated 99.9 percent of accounts via the normal migration flow in two weeks, and finished the remaining via the buffered migration flow two weeks after.
The simplified data schema directly reduced the size of data on disk. We saved additional space in MyRocks by applying Zstandard, a state-of-the-art lossless data compression algorithm developed by Facebook. We were able to reduce the replication factor from six to three, thanks to differences between the HBase and MyRocks architectures. In total, we reduced storage consumption by 90 percent without data loss, thereby making it practical to use flash storage.
Compared with HBase, MyRocks at Facebook has more mature and more automated features to handle disaster recovery. In cases where we need to completely switch to another data center, we no longer need to involve human supervisors and perform manual operations. Automation makes switching data centers orders of magnitude faster than with the old system.
MyRocks is optimized in both reading and writing, and by leveraging Lightning with flash storage, we realized latency wins, in part because we are no longer bound on I/O in HBase. Read latency is now 50 times lower than in the previous system. People using Messenger can see that it is now much faster to scroll back though old messages. MyRocks is also more resilient.
These performance and architecture improvements have also enabled Messenger to add new features much more easily. The migration to MyRocks has helped us to launch message content search on mobile, a frequently requested feature. It was hard to implement mobile message search using HBase. Because it is I/O bound, it would require an equivalent read-heavy job to build an index for search. By switching to MyRocks, Messenger has now directly adopted the established Facebook search infrastructure built on top of MySQL, and we now have more than sufficient headroom to allow users to search their conversations on mobile as well as on desktop.
With the database migration complete, we now have a system in place to support further improvements and new features in Messenger. We are looking forward to sharing more updates in the future.








