
Incident investigation can be a daunting task in today’s digital landscape, where large-scale systems comprise numerous interconnected components and dependencies
DrP is a root cause analysis (RCA) platform, designed by Meta, to programmatically automate the investigation process, significantly reducing the mean time to resolve (MTTR) for incidents and alleviating on-call toil
Today, DrP is used by over 300 teams at Meta, running 50,000 analyses daily, and has been effective in reducing MTTR by 20-80%
By understanding DrP and its capabilities, we can unlock new possibilities for efficient incident resolution and improved system reliability.
What It Is
DrP is an end-to-end platform that automates the investigation process for large-scale systems. It addresses the inefficiencies of manual investigations, which often rely on outdated playbooks and ad-hoc scripts. These traditional methods can lead to prolonged downtimes and increased on-call toil as engineers spend countless hours triaging and debugging incidents.
DrP offers a comprehensive solution by providing an expressive and flexible SDK to author investigation playbooks, known as analyzers. These analyzers are executed by a scalable backend system, which integrates seamlessly with mainstream workflows such as alerts and incident management tools. Additionally, DrP includes a post-processing system to automate actions based on investigation results, such as mitigation steps.

DrP’s key components include:
- Expressive SDK: The DrP SDK allows engineers to codify investigation workflows into analyzers. It provides a rich set of helper libraries and machine learning (ML) algorithms for data access and problem isolation analysis, such as anomaly detection, event isolation, time series correlation and dimension analysis.
- Scalable backend: The backend system executes the analyzers, providing both multi-tenant and isolated execution environments. It ensures that analyzers can be run at scale, handling thousands of automated analyses per day.
- Integration with workflows: DrP integrates with alerting and incident management tools, allowing for the auto-triggering of analyzers on incidents. This integration ensures that investigation results are immediately available to on-call engineers.
- Post-processing system: After an investigation, the post-processing system can take automated actions based on the analysis results. For example, it can create tasks or pull requests to mitigate issues identified during the investigation.
How It Works
Authoring Workflow
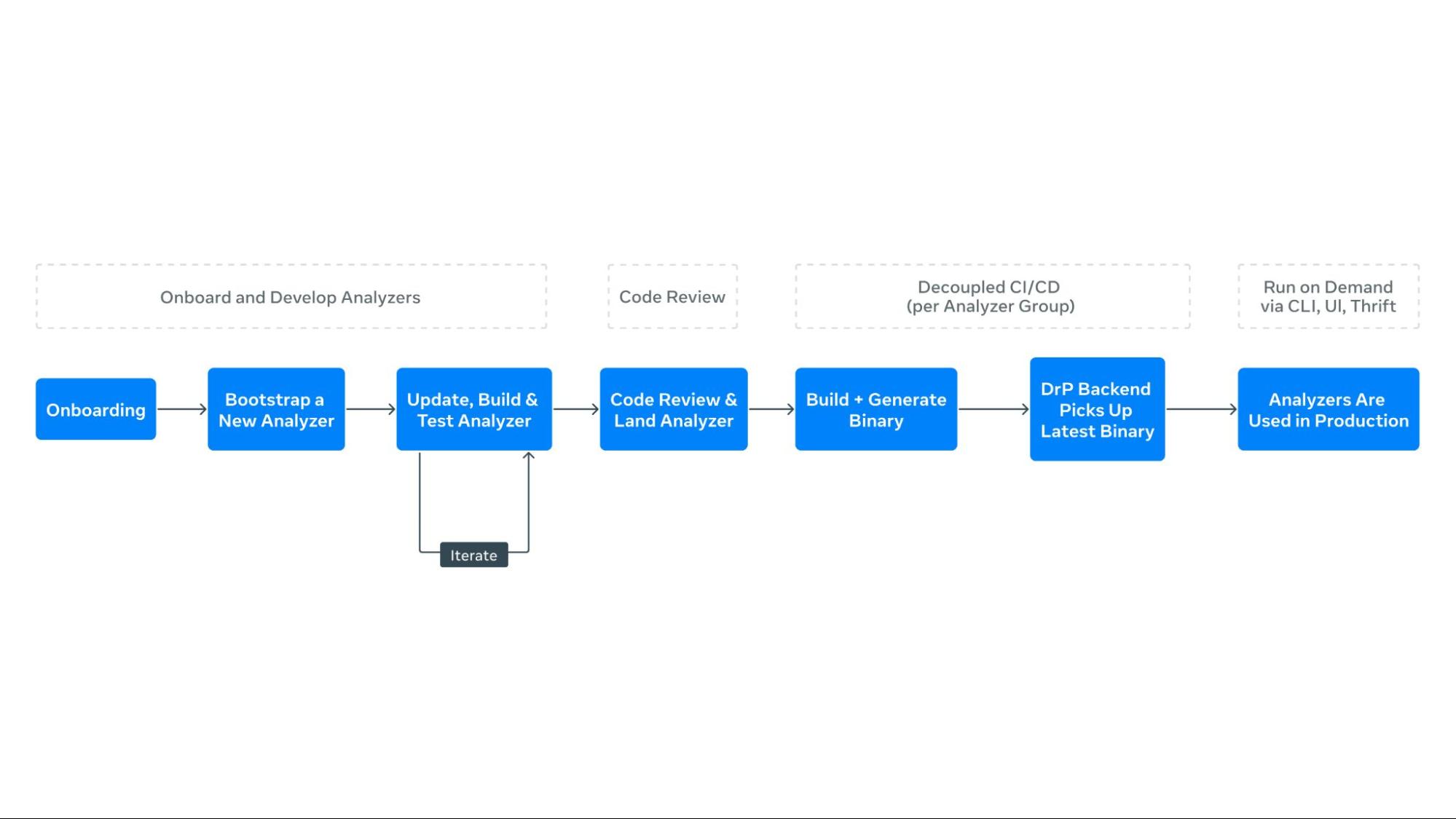
The process of creating automated playbooks, or analyzers, begins with the DrP SDK. Engineers enumerate the investigation steps, listing inputs and potential paths to isolate problem areas. The SDK provides APIs and libraries to codify these workflows, allowing engineers to capture all required input parameters and context in a type-safe manner.
- Enumerate investigation steps: Engineers start by listing the steps required to investigate an incident, including inputs and potential paths to isolate the problem.
- Bootstrap code: The DrP SDK provides bootstrap code to create a template analyzer with pre-populated boilerplate code. Engineers extend this code to capture all necessary input parameters and context.
- Data access and analysis: The SDK includes libraries for data access and analysis, such as dimension analysis and time series correlation. Engineers use these libraries to code the main investigation decision tree into the analyzer.
- Analyzer chaining: For dependent service analysis, the SDK’s APIs allow for seamless chaining of analyzers, passing context and obtaining outputs.
- Output and post-processing: The output method captures findings from the analysis, using special data structures for both text and machine-readable formats. Post-processing methods automate actions based on analyzer findings.
Once created, analyzers are tested and sent for code review. DrP offers automated backtesting integrated into code review tools, ensuring high-quality analyzers before deployment.
Consumption Workflow
In production, analyzers integrate with tools like UI, CLI, alerts, and incident management systems. Analyzers can automatically trigger upon alert activation, providing immediate results to on-call engineers and improving response times. The DrP backend manages a queue for requests and a worker pool for secure execution, with results returning asynchronously.
- Integration with alerts: DrP is integrated with alerting systems, allowing analyzers to trigger automatically when an alert is activated. This provides immediate analysis results to on-call engineers.
- Execution and monitoring: The backend system manages a queue for analyzer requests and a worker pool for execution. It monitors execution, ensuring that analyzers run securely and efficiently.
- Post-processing and insights: A separate post-processing system handles analysis results, annotating alerts with findings. The DrP Insights system periodically analyzes outputs to identify and rank top alert causes, aiding teams in prioritizing reliability improvements.
Why It Matters
Reducing MTTR
DrP has demonstrated significant improvements in reducing MTTR across various teams and use cases. By automating manual investigations, DrP enables faster triage and mitigation of incidents, leading to quicker system recovery and improved availability.
- Efficiency: Automated investigations reduce the time engineers spend on manual triage, allowing them to focus on more complex tasks. This efficiency translates to faster incident resolution and reduced downtime.
- Consistency: By codifying investigation workflows into analyzers, DrP ensures consistent and repeatable investigations. This consistency reduces the likelihood of errors and improves the reliability of incident resolution.
- Scalability: DrP can handle thousands of automated analyses per day, making it suitable for large-scale systems with complex dependencies. Its scalability ensures that it can support the needs of growing organizations.
Enhancing On-Call Productivity
The automation provided by DrP reduces the on-call effort during investigations, saving engineering hours and reducing on-call fatigue. By automating repetitive and time-consuming steps, DrP allows engineers to focus on more complex tasks, improving overall productivity.
Scalability and Adoption
DrP has been successfully deployed at scale at Meta, covering over 300 teams and 2000 analyzers, executing 50,000 automated analyses per day. Its integration into mainstream workflows, such as alerting systems, has facilitated widespread adoption and demonstrated its value in real-world scenarios.
- Widespread adoption: DrP has been adopted by hundreds of teams across various domains, demonstrating its versatility and effectiveness in addressing diverse investigation needs.
- Proven impact: DrP has been in production for over five years, with proven results in reducing MTTR and improving on-call productivity. Its impact is evident in the positive feedback received from users and the significant improvements in incident resolution times.
- Continuous improvement: DrP is continuously evolving, with ongoing enhancements to its ML algorithms, SDK, backend system, and integrations. This commitment to continuous improvement ensures that DrP remains a cutting-edge solution for incident investigations, while its growing adoption across teams enables existing workflows and analyzers to be reused by others, compounding the shared knowledge base and making it increasingly valuable across the organization.
What’s Next
Looking ahead, DrP aims to evolve into an AI-native platform, playing a central role in advancing Meta’s broader AI4Ops vision, enabling more powerful and automated investigations. This transformation will enhance analysis by delivering more accurate and insightful results, while also simplifying the user experience through streamlined ML algorithms, SDKs, UI, and integrations facilitating effortless authoring and execution of analyzers.
Read the Paper
DrP: Meta’s Efficient Investigations Platform at Scale
Acknowledgements
We wish to thank contributors to this effort across many teams throughout Meta
Team – Eduardo Hernandez, Jimmy Wang, Akash Jothi, Kshitiz Bhattarai, Shreya Shah, Neeru Sharma, Alex He, Juan-Pablo E, Oswaldo R, Vamsi Kunchaparthi, Daniel An, Rakesh Vanga, Ankit Agarwal, Narayanan Sankaran, Vlad Tsvang, Khushbu Thakur, Srikanth Kamath, Chris Davis, Rohit JV, Ohad Yahalom, Bao Nguyen, Viraaj Navelkar, Arturo Lira, Nikolay Laptev, Sean Lee, Yulin Chen
Leadership – Sanjay Sundarajan, John Ehrhardt, Ruben Badaro, Nitin Gupta, Victoria Dudin, Benjamin Renard, Gautam Shanbhag, Barak Yagour, Aparna Ramani








