
- At Meta, we use invisible watermarking for a variety of content provenance use cases on our platforms.
- Invisible watermarking serves a number of use cases, including detecting AI-generated videos, verifying who posted a video first, and identifying the source and tools used to create a video.
- We’re sharing how we overcame the challenges of scaling invisible watermarking, including how we built a CPU-based solution that offers comparable performance to GPUs, but with better operational efficiency.
Invisible watermarking is a powerful media-processing technique that allows us to embed a signal into media in a way that’s imperceptible to humans but detectable by software. This technology offers a robust solution for content provenance tagging (an indication of where the content came from), enabling the identification and tracking of content to support various use cases. At its core, invisible watermarking works by subtly modifying pixel values in images, waveforms in audio, or text tokens generated by large language models (LLMs) to embed a small amount of data. The design of watermarking systems adds necessary redundancy; this ensures the embedded identification remains persistent through transcodes and editing, unlike metadata tags that can be lost.
Bringing an invisible watermarking solution to production at scale presents many challenges. In this blog post, we’ll discuss how we overcame challenges with deployment environments, bitrate increases, and visual quality regressions to adapt to real-world use cases.
Some Helpful Definitions
Digital watermarking, steganography, and invisible watermarking are related concepts, but it’s important to understand their differences:
| Feature | Digital Watermarking | Steganography | Invisible Watermarking |
| Purpose | Content attribution, protection, provenance | Secret communication | Content attribution, protection, provenance |
| Visibility | Visible or invisible | Invisible | Invisible |
| Robustness
against content modifications |
Medium to high | Usually low | High (survives edits) |
| Payload / Message Capacity | Medium (varies) | Varies | Medium (e.g., >64 bits) |
| Computational Cost | Low (visible) to high (invisible) | Varies | High (advanced ML models) |
The Need for Robust Content Tagging
In today’s digital landscape, where content is constantly shared, remixed, and even AI-generated, important questions arise:
Who Published the Video First?
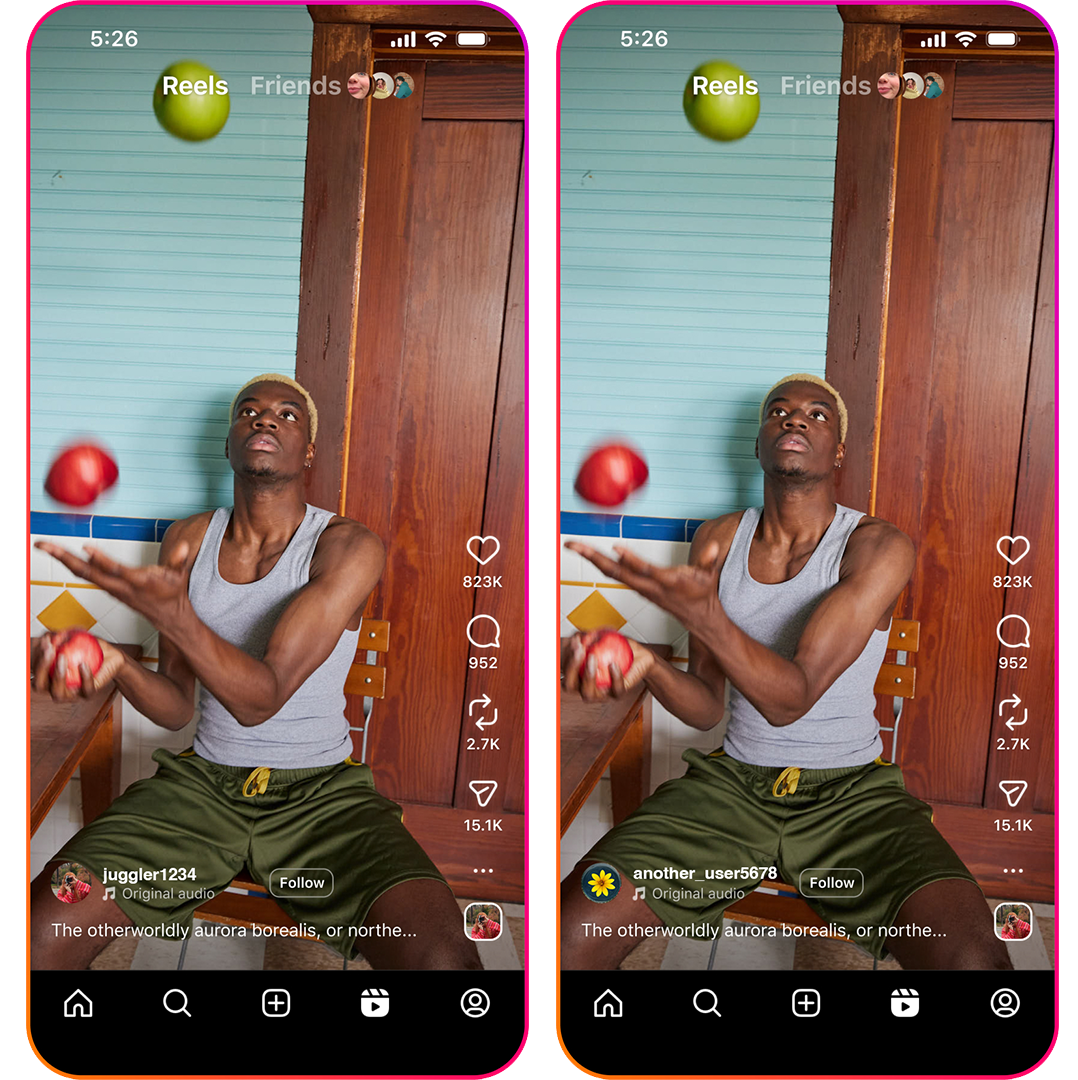
In the photos in Figure 1, you can see two different user names, but there’s no visual indicator of who uploaded this image first. Invisible watermarking can help identify the first time a video was uploaded.
Is It Even a Real Image?
With increasingly realistic generative AI (GenAI) videos, distinguishing between real and AI-generated content is increasingly challenging. Invisible watermarking can be used to infer if content such as in Figure 2 is AI-generated.

What Camera Was Used?
When encountering a compelling image or video like the one in Figure 3, people often wonder about the source and tools used for creation. Invisible watermarking can infer this information directly.

Traditional methods such as visual watermarks (which can be distracting) or metadata tags (which can be lost if a video is edited or re-encoded) do not address these challenges adequately and robustly. Due to its persistence and imperceptibility, invisible watermarking presents a superior alternative.
The Scaling Journey: From GPUs to CPUs
Earlier digital watermarking research (starting in the 1990s) employed digital signal-processing techniques (such as DCT and DWT) to modify an image’s spectral properties to hide imperceptible information. Although these methods proved highly effective for static images and were considered a “solved problem,” they are not adequately robust against the various types of geometric transformations and filtering we see in social media and other real-world applications.
Today’s state-of-the-art solutions (such as VideoSeal) use machine-learning (ML) techniques providing significantly improved robustness against the type of edits seen in social media. However, the application of solutions to the video problem domain (i.e., frame-by-frame watermarking) may be prohibitively computationally expensive without the necessary inference optimizations.
GPUs may seem an obvious solution for deploying ML-based video watermarking solutions. However, most types of GPU hardware are specialized for the training and inference of large-scale models (such as LLMs and diffusion models). They have partial or no support for video transcoding (compression and decompression). Enabling invisible watermarking for videos has therefore posed unique challenges for our existing video-processing software (FFmpeg) and hardware stack (GPUs without video-transcoding capabilities or other custom accelerators for video processing without efficient ML-model inference capabilities).
GPU Optimization Attempts and the Shift to CPUs
Our embedding architecture uses FFmpeg with a custom filter to compute and apply invisible watermark masks to the videos. The filter acts as a reusable block that can be added easily to existing video processing pipelines. Migrating to a more optimal inference service for warmed-up models would mean sacrificing the flexibility of our FFmpeg filter, so for our application that was not an option.
Profiling our invisible watermarking filter revealed low GPU utilization. We implemented frame batching and threading in the filter, but these efforts yielded no significant improvements to latency or utilization. GPUs with hardware video encoders and decoders can more easily reach high throughput, but the GPUs available for our service lack video encoders, requiring frames to be sent back to the CPU for encoding. Here a software video encoder can end up being a major bottleneck for pipelines using low-complexity ML models on a GPU.
Specifically, we encountered three primary bottlenecks:
- Data transfer overhead: Transferring high-resolution input video frames back and forth between CPUs and multiple GPUs posed challenges to thread and memory optimizations, yielding suboptimal GPU utilization.
- Inference latency: Processing multiple invisible watermarking requests across multiple GPUs in parallel on the same host led to a dramatic increase in inference latency.
- Model loading time: Despite the model’s small size, loading the model consumed a significant portion of the total processing time. Relying on FFmpeg prevented us from using warmed-up, pre-loaded models on the GPUs.
Recognizing these limitations, we began investigating CPU-only inference. The embedder’s neural network architecture is more favorable to GPUs, and initial benchmarks showed that end-to-end (E2E) performance was more than two times slower on CPUs. By adjusting threading parameters for the encoder, decoder, and PyTorch, and optimizing sampling parameters used by the invisible watermarking filter, we saw significant improvements.
Ultimately, with properly tuned threading and embedding parameters, the E2E latency for running invisible watermarking on a CPU in a single process was within 5% of GPU performance. Crucially, we could run multiple FFmpeg processes in parallel on CPUs without increased latency. This breakthrough allowed us to calculate the capacity needed and achieve a more operationally efficient solution compared to a GPU-based solution.
To validate our CPU solution’s scalability in a distributed system, we conducted comprehensive load tests. Given a pool of CPU workers, we generated test traffic at increasing request rates to identify the peak performance point before per-request latency began to rise. For comparison, we used the same parameters with GPU inference on a pool of GPU workers with similar capabilities. The results confirmed that our CPU solution could perform at scale, comparable to our local test findings. This achievement allowed us to provision the required capacity with greater operational efficiency compared to a GPU-based approach.
Optimization Considerations and Trade-offs
Deploying invisible watermarking at scale presented several optimization challenges, primarily involving trade-offs between four metrics:
- Latency: The speed at which the watermarking process occurs
- Watermark detection bit-accuracy: The accuracy of detecting embedded watermarks
- Visual quality: Ensuring the embedded watermark is imperceptible to the human eye
- Compression efficiency (measured by BD-Rate): Ensuring the embedded watermark does not significantly increase bitrate
Optimizing for one metric may negatively impact others. For example, a stronger watermark for higher bit accuracy might lead to visible artifacts and increased bitrate. We can’t create a perfectly optimal solution for all four metrics si
Managing BD-Rate Impact
Invisible watermarking, while imperceptible, introduces increased entropy, which can lead to a higher bitrate for video encoders. Our initial implementation showed a BD-Rate regression of around 20%, meaning users would need more bandwidth to watch a watermarked video. To mitigate this, we devised a novel frame-selection method for watermarking so that the BD-Rate impact is largely reduced while increasing visual quality and minimally impacting watermark bit detection accuracy.
Addressing Regressions in Visual Quality
We need to ensure the “invisible” watermark remains truly invisible. We initially observed noticeable visual artifacts despite high-quality metric scores (VMAF and SSIM).
We addressed the visual-quality evaluations by implementing a custom post-processing technique and iterating through different embedding settings through crowdsourced manual inspections. This subjective evaluation was crucial for unblocking us, as traditional visual quality metrics proved insufficient for detecting the type of artifact an invisible watermark can at times introduce. As we tuned the algorithm for human invisibility, we closely monitored the bit accuracy impact to achieve an optimal balance between visual quality and detection accuracy.
Learnings and the Road Ahead
Our journey to deploy a scalable, invisible watermarking solution provided valuable insights:
With proper optimizations, CPU-only pipelines can reach performances comparable to GPU pipelines for specific use cases at much lower cost. Contrary to our initial assumptions, with the right optimizations CPUs offered us a more operationally efficient and scalable solution for our invisible-watermarking system. While GPUs are still faster for the invisible watermark model inference, we were able to use optimizations to bring down the overall compute and latency with the CPU fleet.
Traditional video quality scores are insufficient for invisible watermarking: We learned that metrics like VMAF and SSIM do not fully capture the perceptual quality issues introduced by invisible watermarking, necessitating manual inspection. More research is needed to develop a metric to programmatically detect the visual-quality loss incurred by invisible watermarking.
The quality bar for production use is high: Watermarking techniques may not directly apply to real-world use cases due to the impact on BD-Rate and downstream video compression. We needed to expand upon the literature to keep BD-Rate impacts low while maintaining excellent bit accuracy for detection.
We successfully shipped a scalable watermarking solution with excellent latency, visual quality, detection bit accuracy, and a minimal BD-Rate impact.
As our North Star goal, we aim to continue to improve the precision and copy-detection recall with invisible watermark detection. This will involve further tuning of model parameters, pre- and post-processing steps, and video encoder settings. Ultimately, we envision invisible watermarking as a lightweight “filter block” that can be seamlessly integrated into a wide range of video use cases without product-specific tweaks, providing minimal impact on the user experience while offering robust content provenance.








