
- OpenZL is a new open source data compression framework that offers lossless compression for structured data.
- OpenZL is designed to offer the performance of a format-specific compressor with the easy maintenance of a single executable binary.
- You can get started with OpenZL today by visiting our Quick Start guide and the OpenZL GitHub repository.
- Learn more about the theory behind OpenZL in this whitepaper.
Today, we are excited to announce the public release of OpenZL, a new data compression framework. OpenZL offers lossless compression for structured data, with performance comparable to specialized compressors. It accomplishes this by applying a configurable sequence of transforms to the input, revealing hidden order in the data, which can then be more easily compressed. Despite applying distinct transformation permutations for every file type, all OpenZL files can be decompressed using the same universal OpenZL decompressor.
A Decade of Lessons
When Zstandard was announced, it came with a simple pitch: It promised the same or better compression ratio of prior default but at the much increased speed required by datacenter workloads. By pairing strong entropy coding with a design that fully utilized modern CPU capabilities, Zstandard offered a substantial improvement that justified its presence in datacenters.
However, while it was improved over time, remaining within the Zstandard framework offers diminishing returns. So we started looking for the next great leap in data compression.
In this quest, one pattern kept repeating: Using generic methods on structured data leaves compression gains on the table. Data isn’t just byte soup. It can be columnar, encode enums, be restricted to specific ranges, or carry highly repetitive fields. More importantly, it has predictable shapes. A bespoke compressor that leans into that structure can beat general-purpose tools on both ratio and speed. But there’s a catch — every bespoke scheme means another compressor and decompressor to create, ship, audit, patch, and trust.
OpenZL is our answer to the tension between the performance of format-specific compressors and the maintenance simplicity of a single executable binary.
Make the Structure Explicit
General compressors rely on a one-size fits all processing strategy, or alternatively spend a lot of their cycles guessing which techniques to use. OpenZL saves those cycles by making the structure an explicit input parameter. Compression can then focus on a sequence of reversible steps that surface patterns before coding.
As a user, you provide OpenZL with the data shape (via a preset or a thin format description). Then the trainer, an offline optimization component, builds an effective compression config that can be re-employed for similar data. During encoding that config resolves into a concrete decode recipe that’s embedded into the frame. The universal decoder will directly execute that recipe, without any out-of-band information.
An Example Compression Using OpenZL
As an example, let’s compress sao, which is part of the Silesia Compression Corpus. This file follows a well-defined format featuring an array of records, each one describing a star. Providing this information to OpenZL is enough to give it an edge over generic lossless compressors, which only see bytes.
Comparison on a M1 cpu, using clang-17
| Compressor | zstd -3 | xz -9 | OpenZL |
| Compressed Size | 5,531,935 B | 4,414,351 B | 3,516,649 B |
| Compression Ratio | x1.31 | x1.64 | x2.06 |
| Compression Speed | 220 MB/s | 3.5 MB/s | 340 MB/s |
| Decompression Speed | 850 MB/s | 45 MB/s | 1200 MB/s |
Crucially, OpenZL produces a higher compression ratio while preserving or even improving speed, which is critical for data center processing pipelines.
For illustration, this result is achieved using the following simple graph:
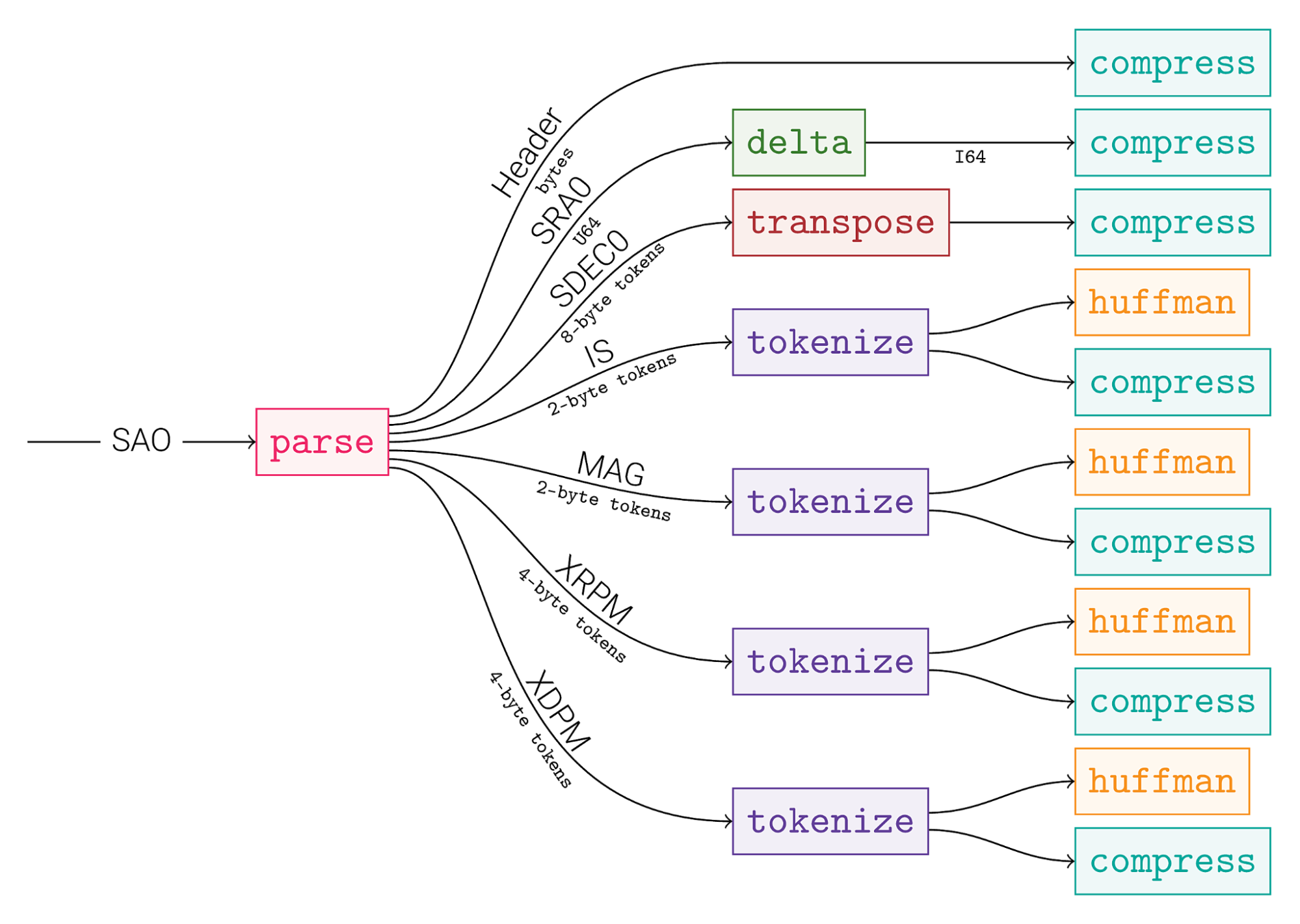
A Brief Explanation
So what is happening in this example?
We start by separating the header from the rest, a large table of structures. Then each field gets extracted into its own stream: the array of structures becomes a structure of arrays. After that point, we expect that each stream contains homogeneous data of the same type and semantic meaning. We can now focus on finding an optimal compression strategy for each one.
- SRA0 is a position on the X axis. Due to the way the table is generated, the index is mostly sorted, inviting the use of delta to reduce the range of values represented. This mechanically makes the resulting stream easier to compress.
- SDEC0 is a position on the Y axis. It’s not as well sorted as the X axis, but we can at least exploit the fact that it’s bounded between a minimum and a maximum. This makes the higher bytes more predictable, which can be exploited for better compression with the transpose operation.
- The other fields (IS, MAG, XRPM, XDPM) share a common property: their cardinality is much lower than their quantities, and there is no relation between 2 consecutive values. This makes them a good target for tokenize, which will convert the stream into a dictionary and an index list.
- The resulting dictionaries and index lists are very different. They benefit from completely different compression strategies. So they are sent to dedicated processing graphs.
The graph continues beyond these steps. But at some point, we can also stop making decisions. The main work is to group data into homogeneous streams. After that, one can count on openzl to take care of the rest.
To go even further, we would like to generate compression strategies that are specifically fine-tuned for each stream. This is where the offline trainer stage comes into play.
Generate a Compressor Automatically
It’s possible to take full control of the compression process, but it’s also not required. A faster strategy is to just describe your data and let the system learn a compression config.
Describe the input: With the Simple Data Description Language (SDDL), you sketch how the bytes map to fields — rows, columns, enums, nested records. SDDL is for parsing only; it just tells OpenZL the shape of your data. Alternatively, you can write your own parser function directly using one of the supported languages, and register it with OpenZL to delegate the logic.
Learn the config: Starting from a preset, a parser function or an SDDL description, the trainer runs a budgeted search over transform choices and parameters to produce a Plan. It can provide a full set of speed/ratio tradeoffs, or directly target the best configuration respecting some speed constraints. Internally it uses a cluster finder (to group fields that behave alike) and a graph explorer (to try candidate subgraphs and keep score).
Resolve at encode-time: While compressing, the encoder turns the Plan into a concrete recipe — the Resolved Graph. If the Plan has control points, it picks the branch that fits the data and records that choice into the frame.
Decode without coordination: Each frame chunk carries its own resolved graph. The single decoder checks it, enforces limits, and runs the steps in order. When a plan improves, you just roll out the new plan, no new decompressor needed. Old data keeps decoding; new data get improved gains.
In practice the loop is straightforward: describe (SDDL) → train (produce a plan) → compress (emit frames with resolved graphs) → decode anywhere with the same binary.
Embracing Changes: Re-Training and In-Flight Control
In the real world, data evolves constantly, in both structure and content. A compressor built for one version of a schema would have a short lifetime.
Thankfully, with the flexibility offered by compression plans, we can react swiftly to data changes. At Meta, this is the core mission of Managed Compression, originally created to automate dictionary compression with Zstandard, and presented in an earlier blog on how we improved compression at with Zstandard.
OpenZL offers a training process that updates compression plans to maintain or improve compression performance, based on provided data samples. Now the synergy with Managed Compression is apparent: Each registered use case is monitored, sampled, periodically re-trained, and receives new configs when they prove beneficial. The decompression side continues to decode both old and new data without any change.
Runtime Adaptation: A compression config can include control points that read lightweight statistics at compression time (e.g., string repetition stats, run-length, histogram skew, delta variance) and choose the best branch of the Plan to go to next. Many technologies can be used, and textbook classifiers qualify. Control points handle bursts, outliers, and seasonal shifts without brute-force exploration: exploration is bounded, in order to maintain speed expectations. Taken branches are then recorded into the frame, and the decoder just executes the recorded path.
This gives the best of both worlds: dynamic behavior at compression time to handle variations and exceptions — without turning compression into an unbounded search problem — and with zero complexity added to the decoder.
The Advantages of the Universal Decoder
OpenZL is capable of compressing a vast array of data formats, and they can all be decompressed with a single decompressor binary. Even when the compression configuration changes, the decoder does not. This may sound like operational minutiae, but it’s critical to OpenZL’s deployment success.
- One audited surface: Security and correctness reviews focus on a single binary with consistent invariants, fuzzing, and hardening; there’s no myriad of per-format tools that can drift apart.
- Fleet-wide improvements: A decoder update (security or performance — SIMD kernels, memory bounds, scheduling) benefits every compressed file, even those that predate the change.
- Operational clarity: Same binary, same CLI, same metrics and dashboards across datasets; patching and rollout are uneventful by design.
- Continuous training: With one decoder and many compression plans, we can keep improving while the system is live. Train a plan offline, try it on a small slice, then roll it out like any other config change. Backward compatibility is built-in — old frames still decode while new frames get better.
In other words, it’s possible to afford domain-specific compression without fragmenting the ecosystem.
Results With OpenZL
When OpenZL is able to understand and parse the file format, it is able to offer large improvements in compression ratio, while still providing fast compression and decompression speed. However, this is no magic bullet. When OpenZL doesn’t understand the input file format, it simply falls back to zstd.
OpenZL, through its offline training capabilities, is also able to offer a wide range of configurations in the tradeoff space of compression ratio, compression speed, and decompression speed. Unlike traditional compressors, which offer configuration by setting a compression level, OpenZL offers configuration by serializing the compressor graph. This allows an immense amount of flexibility to select diverse tradeoffs.
These results are based on datasets we’ve developed for our whitepaper. The datasets were chosen because they are highly structured and in a format that OpenZL supports. Every figure below is produced with scripts in the OpenZL repository so they can be reproduced, and the input data and logs from our runs have been uploaded to GitHub.
Note that data points connected by a line are pareto-optimal. All such points have the property that there is no point in the same dataset which beats them in both metrics.
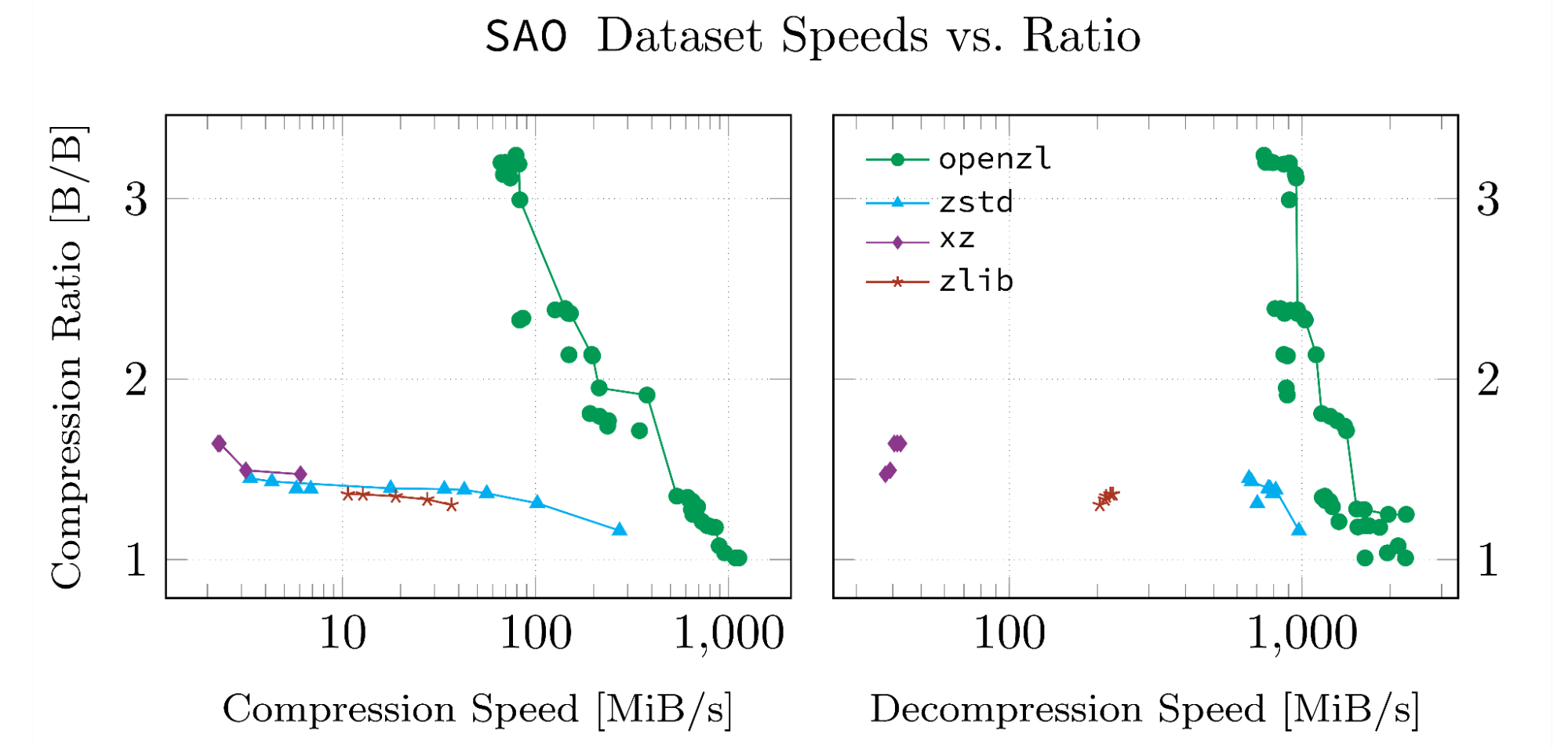
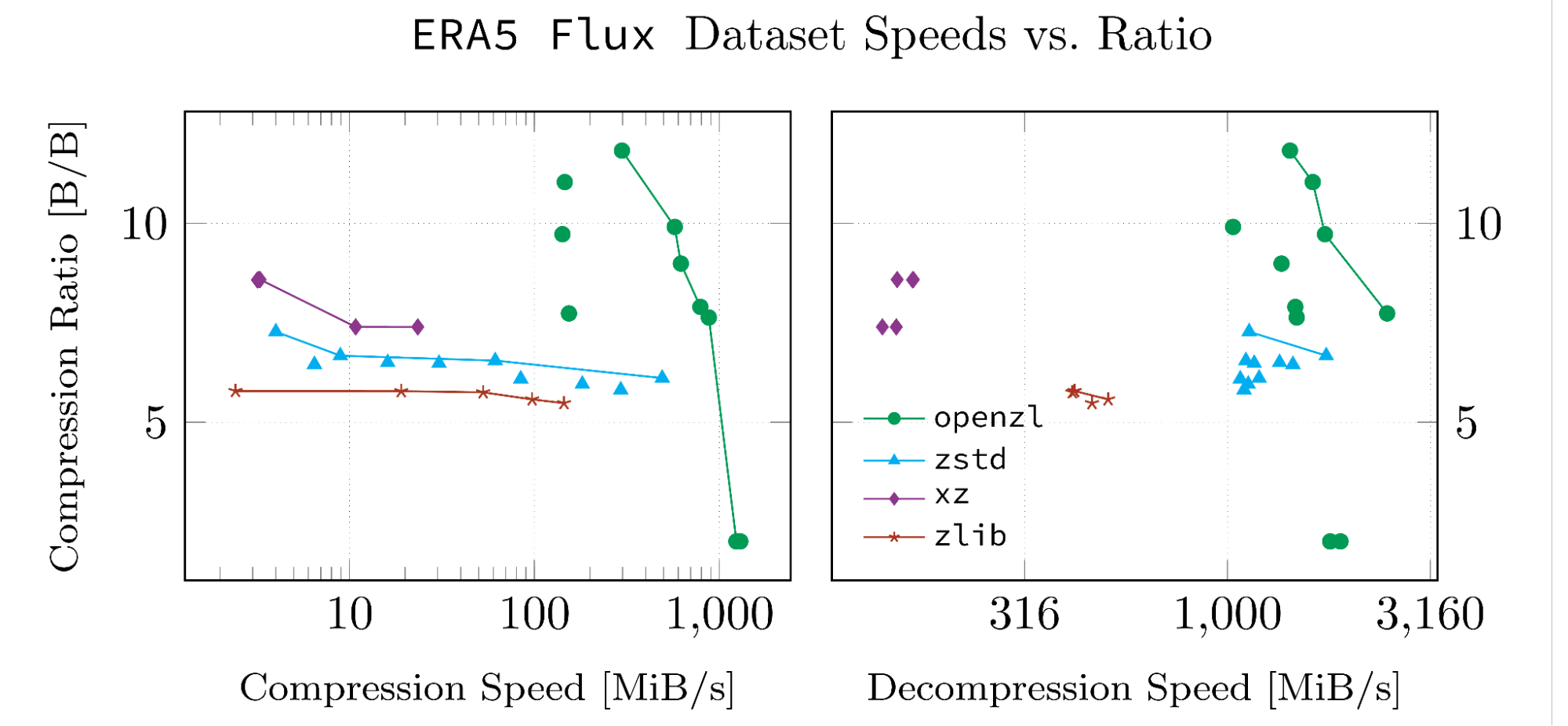
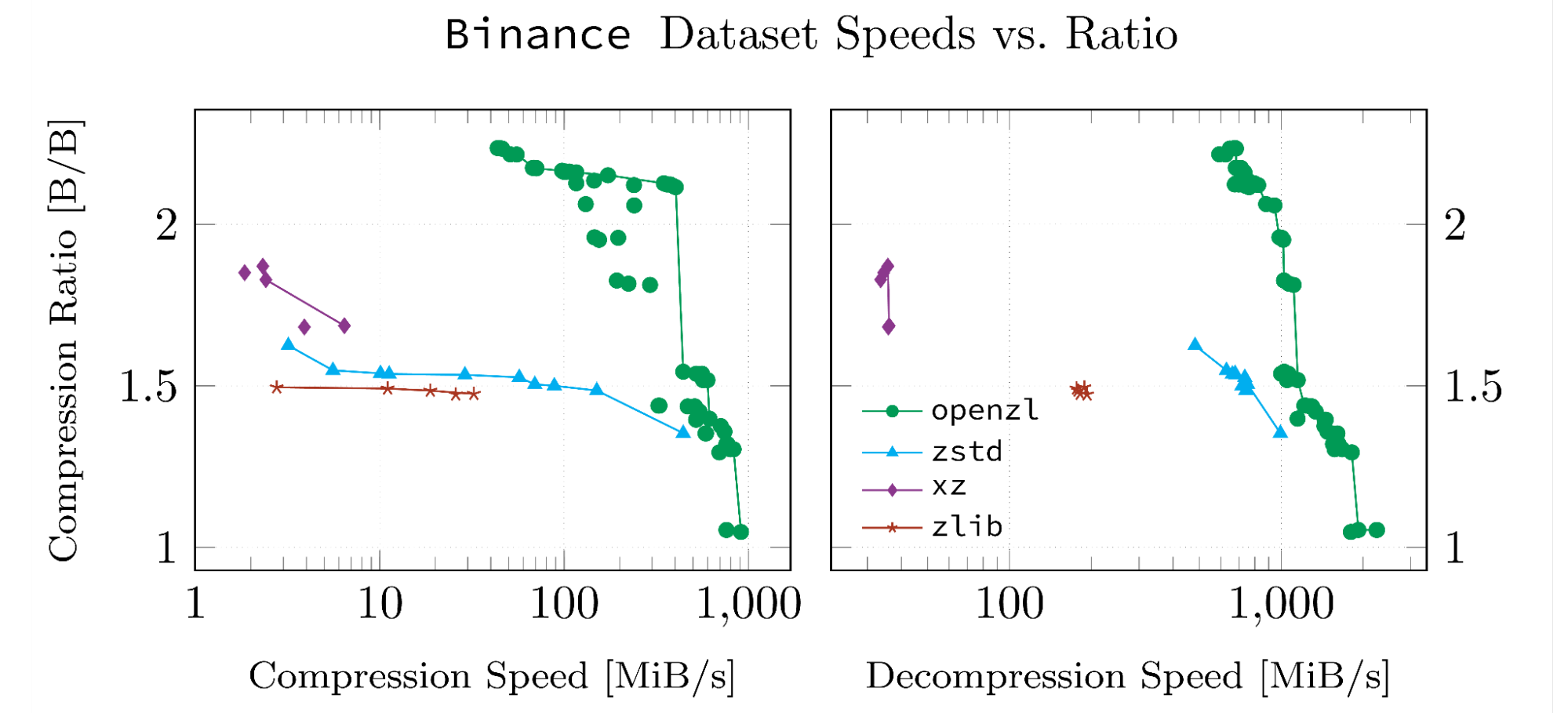
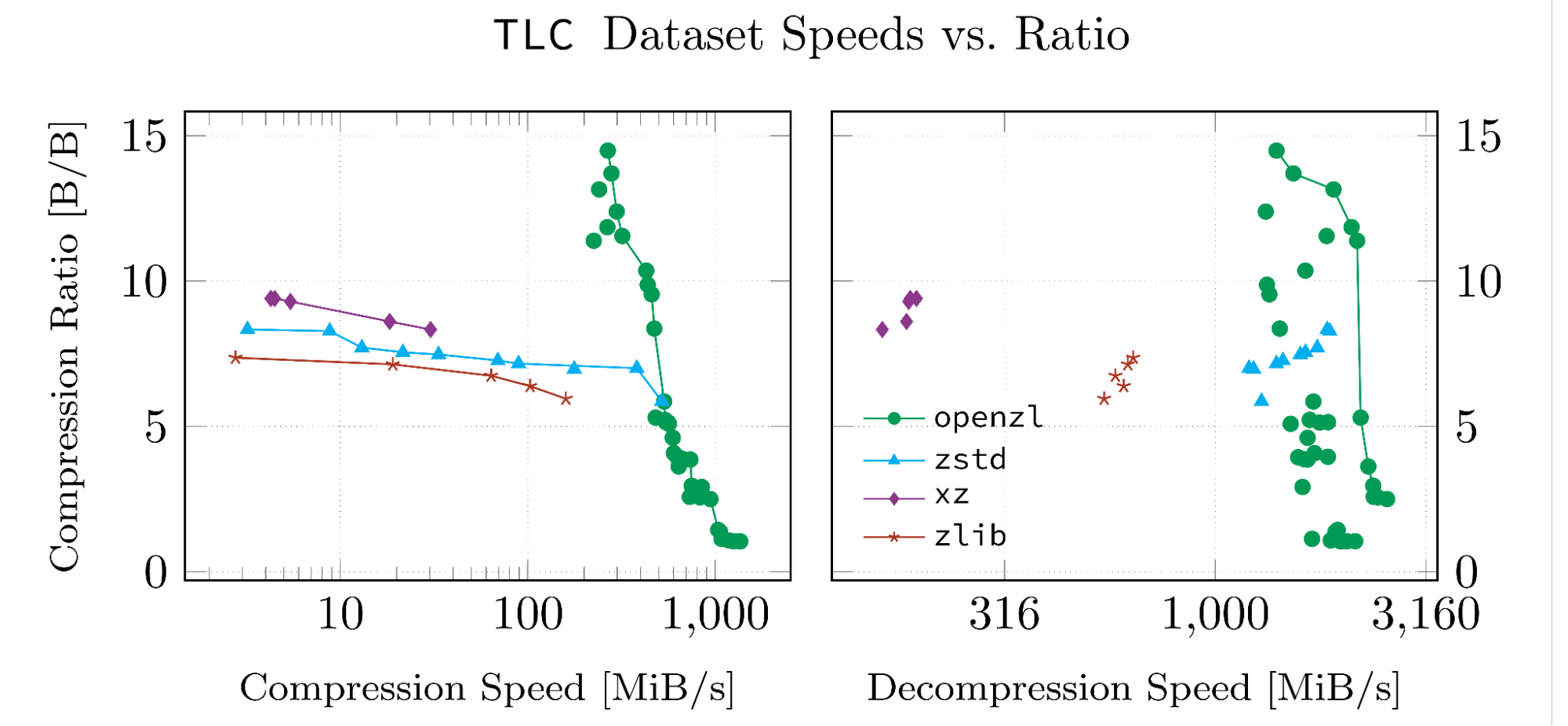
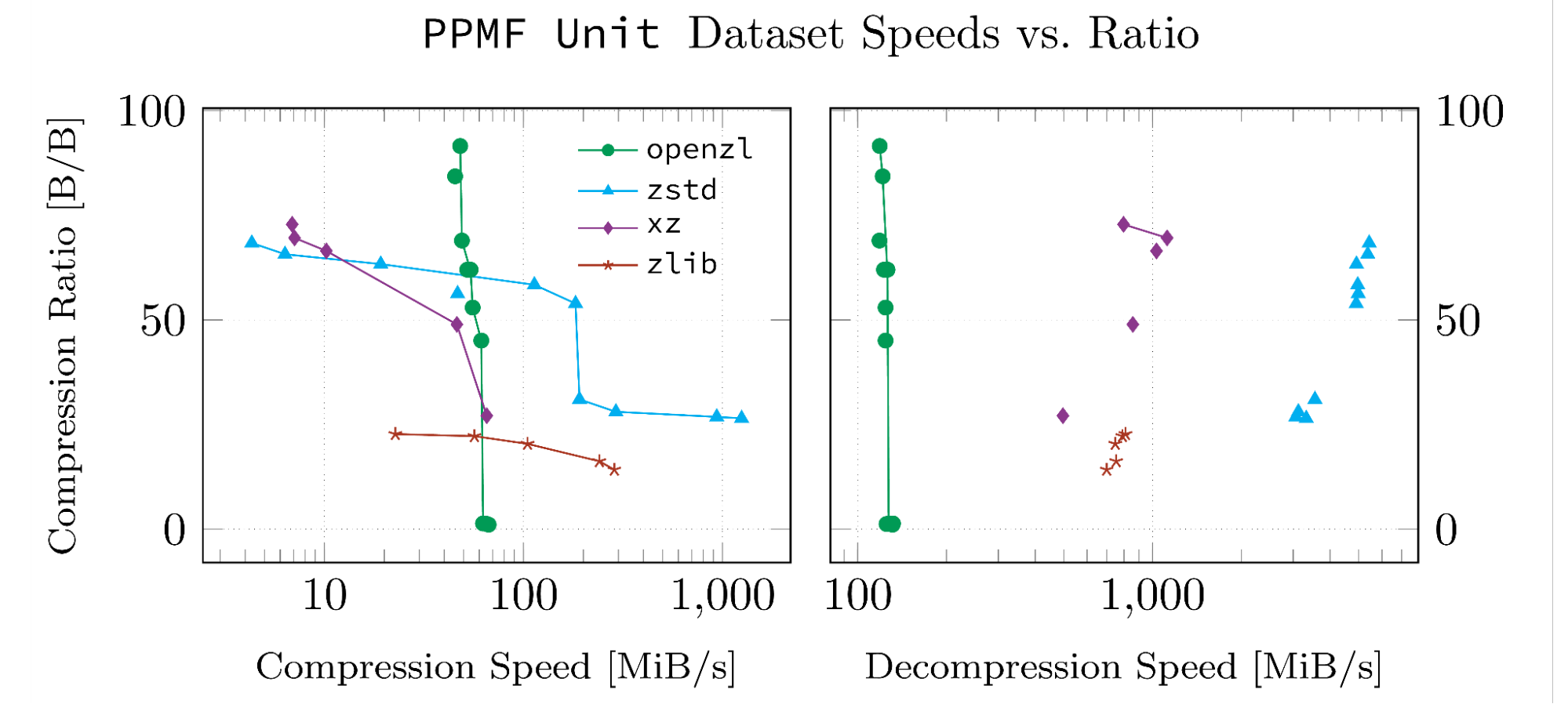
When It’s Not Useful
OpenZL relies on a description of some structure to leverage its set of transforms. When there is no structure, there is no advantage. This is typically the case in pure text documents, such as enwik or dickens. In these cases, OpenZL falls back to zstd, offering essentially the same level of performance.
Getting Started With OpenZL
OpenZL’s selection of codecs is well-suited to compressing vector, tabular, or tree-structured data, and can be expected to perform well with numeric, string, or binary data. Common examples include timeseries datasets, ML tensors, and database tables. Keep in mind that we are bound by the limits of information theory, so the input needs to have some order that can be uncovered. As time goes on, we plan to incorporate additional codecs, as described in the next section.
If your data fits one of the above categories, then give it a try! Visit the OpenZL site and our Quick Start guide to get started.
If you want to dive into the code, check out the GitHub repository for source, documentation, and examples. We welcome contributions and feedback from the community!
Where We’re Going
OpenZL’s general direction is set: make it easier to expose structures, and exploit it with automated compression plans for evolving data.
Next up: We’re extending the transform library for time-series and grid-shaped data, improving performance of codecs, and enabling the trainer to find better compression plans faster. We also are actively working to extend SDDL to describe nested data formats more flexibly. Finally, the automated compressor explorer is getting better at proposing safe, testable changes to a compression plan within a specified budget.
Where the community can help: If you have a format or a dataset with obvious structure, try compressing it with an OpenZL prebuilt Plan. If it’s promising, try generating a new plan with the trainer or customizing it with our documentation to improve it. If it’s a format that the public might want, send it to us in a PR.
You can also contribute to the OpenZL core. If you have a knack for optimizing C/C++, help us speed up the engine or add transforms to cover new data formats. If your super power is reliability, the project would surely benefit from more validation rules and resource caps. And if you care about benchmarks, add your dataset to the harness so others can reproduce your results.
How to engage: Open an issue on the GitHub issue board. If you have a use-case for which you would expect OpenZL to do better, provide a few small samples, so that we can analyze them together. You may also contribute to codec optimizations, and propose new graphs, parsers or control points. All these topics do not impact the universality of the decoder.
We believe OpenZL opens up a new universe of possibilities to the data compression field, and we’re excited to see what the open source community will do with it!
To learn more about Meta Open Source, visit our website, subscribe to our YouTube channel, or follow us on Facebook, Threads, X, Bluesky and LinkedIn.








