
- Meta has developed Privacy Aware Infrastructure (PAI) and Policy Zones to enforce purpose limitations on data, especially in large-scale batch processing systems.
- Policy Zones integrates with Meta’s exabyte-scale data warehouse and processing systems, using runtime enforcement and SQL parsing to propagate and enforce privacy annotations across millions of daily data flows per day, performing trillions of user consent checks per hour, and through our stream processing systems which transport multiple petabytes per hour.
- We’ve built tools to help engineers use Policy Zones, so that they can quickly respond to privacy requirements. As a testament to its usability, these tools have allowed us to deploy Policy Zones across data assets and processors in our batch processing systems.
- Policy Zones technology is used at scale in batch processing systems to meet our privacy commitments to our users across Meta’s family of apps. While Policy Zones technology has become widely used in our batch processing systems, we are continuing to invest in PAI to make it even easier to use for our engineers.
Meta’s Privacy Aware Infrastructure (PAI) is designed to streamline data flows while ensuring purpose limitation and transparency, leveraging automation to reduce the overhead associated with privacy requirements. This enables our engineers to focus on building innovative products that people love, while always honoring their privacy. By making privacy a core part of our infrastructure, we’re empowering product teams to create new experiences that delight our community.
In our previous blogs, we introduced PAI and its key components, including data lineage and data understanding. These foundational elements have enabled us to effectively manage and track data flows at scale. As we moved forward to enforce purpose limitation, we recognized the need for a robust solution to control how data flows in complex systems, and remediate data flow at scale so that engineers can focus on production innovation with limited friction arising from privacy compliance.
In this blog, we will deep dive into our Policy Zones approach for batch processing systems and how we use it to protect users’ messaging data. These systems process data in batch (mainly via SQL), such as our exabyte data warehouse that powers Meta’s AI training and analytics workflows. 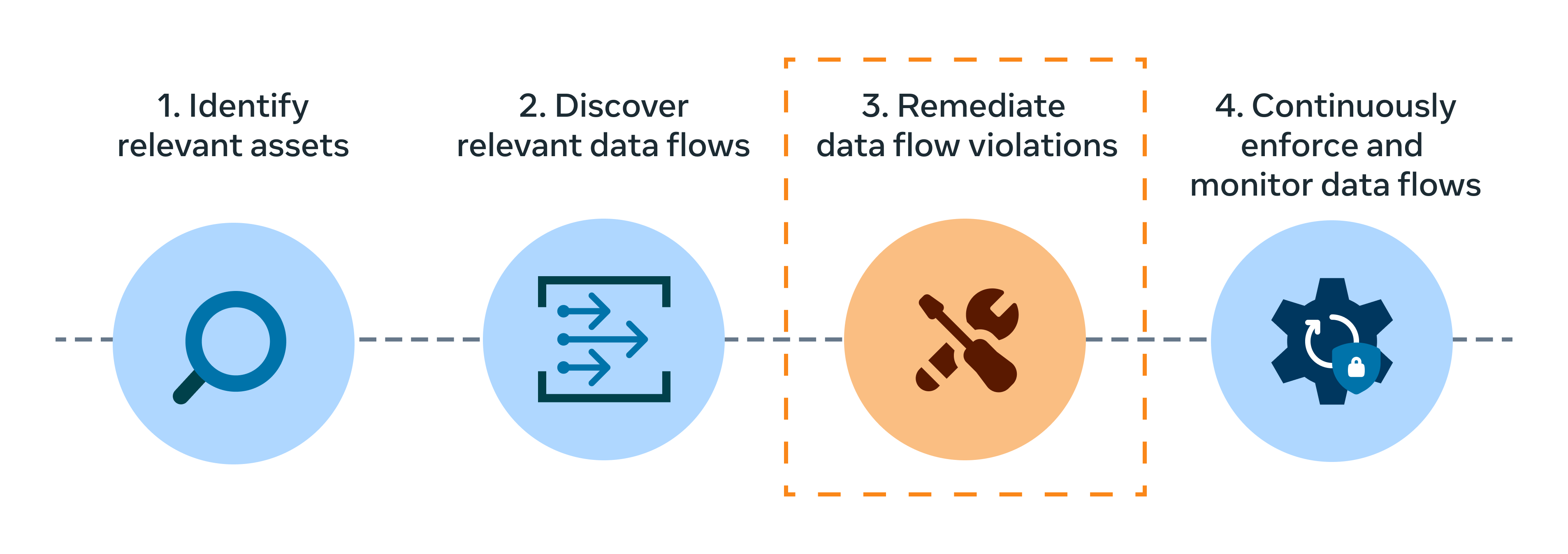
Before Policy Zones, we relied on conventional access control mechanisms like access control lists (ACL) to protect datasets (“assets”) when they were accessed. However, this approach requires physical coarse-grained separation of data into distinct groupings of datasets to ensure each maintains a single purpose. While viable at a small scale, this approach leads to significant operational overhead as it requires frequent and exhaustive audits of many individual assets to ensure the continuous validity for a sizable privacy control.
Data flow control for batch processing systems via Policy Zones
To mitigate the challenges associated with coarse-grained physical data separation, we have invested in Policy Zones as a key component of our PAI strategy. It leverages Information Flow Control (IFC) principles to offer a more durable and sustainable approach by controlling not only how data is accessed but also how data is processed and transferred in real time. We developed tools and APIs for developers to easily integrate Policy Zones, which automatically track and protect data flows by enforcing flow restrictions at runtime, to their code. To maintain data integrity, Policy Zones enforce a fundamental principle: The restrictions on downstream data must be equal to or more restrictive than those of the upstream source from which the data originates. Once the data is protected by Policy Zones, any future processing or usage of the data has to be compatible with the restrictions or it will be blocked.
Meta’s data warehouse is a critical component of our data processing infrastructure, supporting various workloads such as batch analytics, real-time processing, and machine learning. Engineers have developed numerous data processing systems to cater to different usage patterns, resulting in millions of jobs running daily to process and transform data. Policy Zones operates at tremendous scale, including:
- Controlling access for millions of datasets,
- Analyzing the processing of tens of millions of data flows per day across hundreds of thousands of unique queries,
- Performing batch user consent checks that performs trillions of consent checks per hour across datasets that span different purpose-use boundaries,
- Handling hundreds of distinct data policy requirements for any given flow.
The intricate relationships between datasets are exemplified in the following diagram, which depicts a single deployment of Policy Zones enforcing a purpose-use limitation on a subset of data processing within the warehouse. This visual representation highlights the complexity of data dependencies and the need for robust policy enforcement mechanisms. Each dot represents a single dataset, and each line between them represents a data dependency. In other words, in order to compute a given dataset (represented by dots), you would need to use all of the datasets that are connected to it (represented by lines).
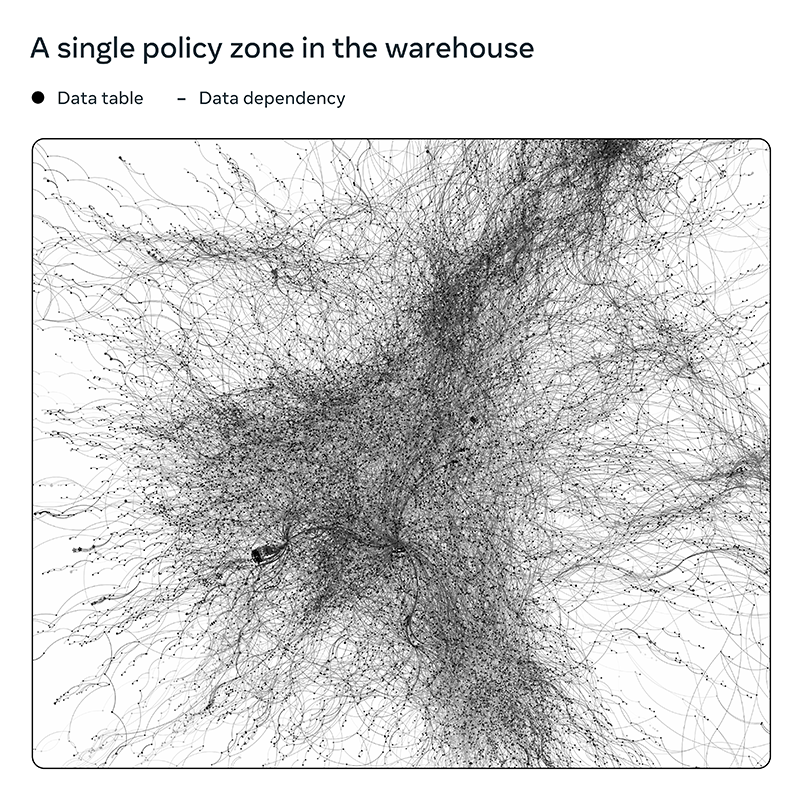
At first glance, the intricate web of data dependencies may seem daunting to manage. However, Policy Zones is designed to track and enforce policies across these complex relationships. While compartmentalizing such a complex system can be resource intensive, Policy Zones offers a more efficient and effective solution for managing data dependencies and ensuring privacy requirements. To address the challenges we’ve faced over the years, we’ve had to develop innovative solutions for our batch processing systems, which are essential for managing the vast amounts of data that flow through our systems. The table below describes the key challenges and our approaches to solving them.
| Challenge | Approach |
| Coarse-grained data separation to compartmentalize purpose use: A common strategy for managing distinct purposes is to separate data and its processing entirely, a technique known as data compartmentalization. However, this approach can be difficult to implement due to the intricate web of data dependencies that exist within our systems. | Fine-grained information flow tracking: We track how data flows to ensure that the restrictions are at least as restrictive as the sources used to populate the output datasets. As a result, engineers do not need to coarsely compartmentalize their data. Fine-grained tracking allows us to more efficiently profile risk without needing to separate data and its processing to specific purposes. |
| Overly conservative labeling of data (label creep): By default, any incidental access of purpose-use limited data results in all of the derived datasets needing to be purpose-use limited, even if the access is spurious. We need a way to stop propagation (called reclassification) of sensitive data labels when the data is transformed to no longer be sensitive. | Policy Zone Manager (PZM): We built a suite of tools that aids in carefully propagating purpose-use limitations that will identify potential over-labeling situations; these are controlled through a reclassification system, which allow engineers to safely stop propagation. |
| Lack of governance, extensible data model: There are numerous internal data policies and individual privacy controls active at any given time, with new policies being created regularly by various public commitment-oriented teams. These teams need to have strong controls over how their data policies are being enforced. It’s also critical that each policy operates independently from other policies due to the different stages of rollout each policy is in. | Governable Data Annotations (GDAs) are precise, governed annotations on datasets that describe the kinds of data that are subject to purpose-use limitations. Their entire lifecycle is subject to precise controls; they limit who can create them, who can associate the annotation on a dataset, who can remove an annotation, among other controls. The annotation labels are human readable, e.g., MESSAGING_DATA describes user data from a messaging context. |
Below we will describe how we scaled out Policy Zones in batch processing systems via a walkthrough of one of the ways we protect messaging data across Meta’s family of apps.
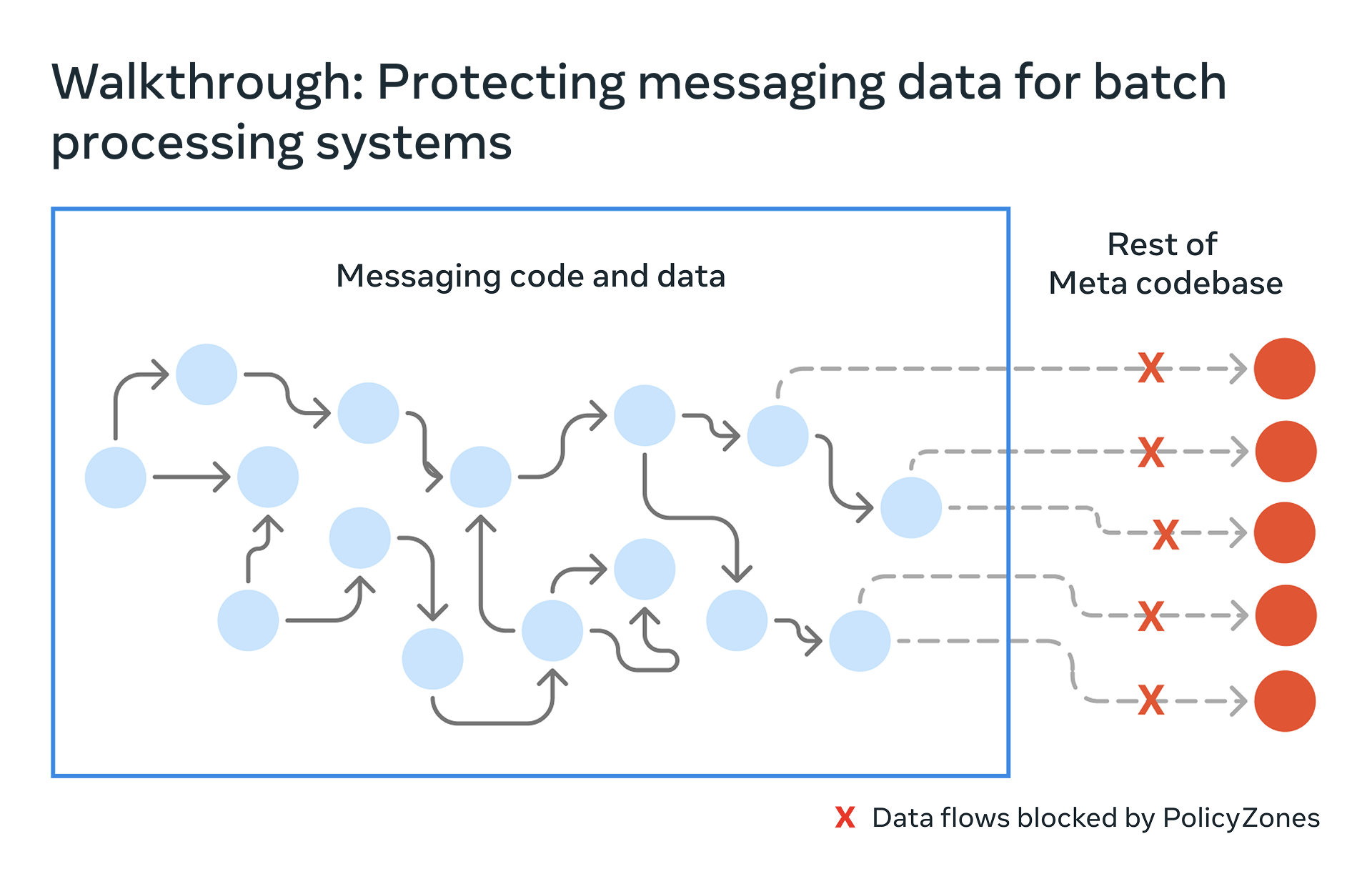
We’ll walk through how we protect user’s messaging data with Policy Zones across our batch processing systems. Users send messages to others through apps like Facebook Messenger. Messenger supports end-to-end encryption. Additionally, to support platform integrity and reliability, we process certain non-content messaging data, such as delivery timestamps and status, to support product performance improvement, detect abuse, and protect users from harmful conduct.
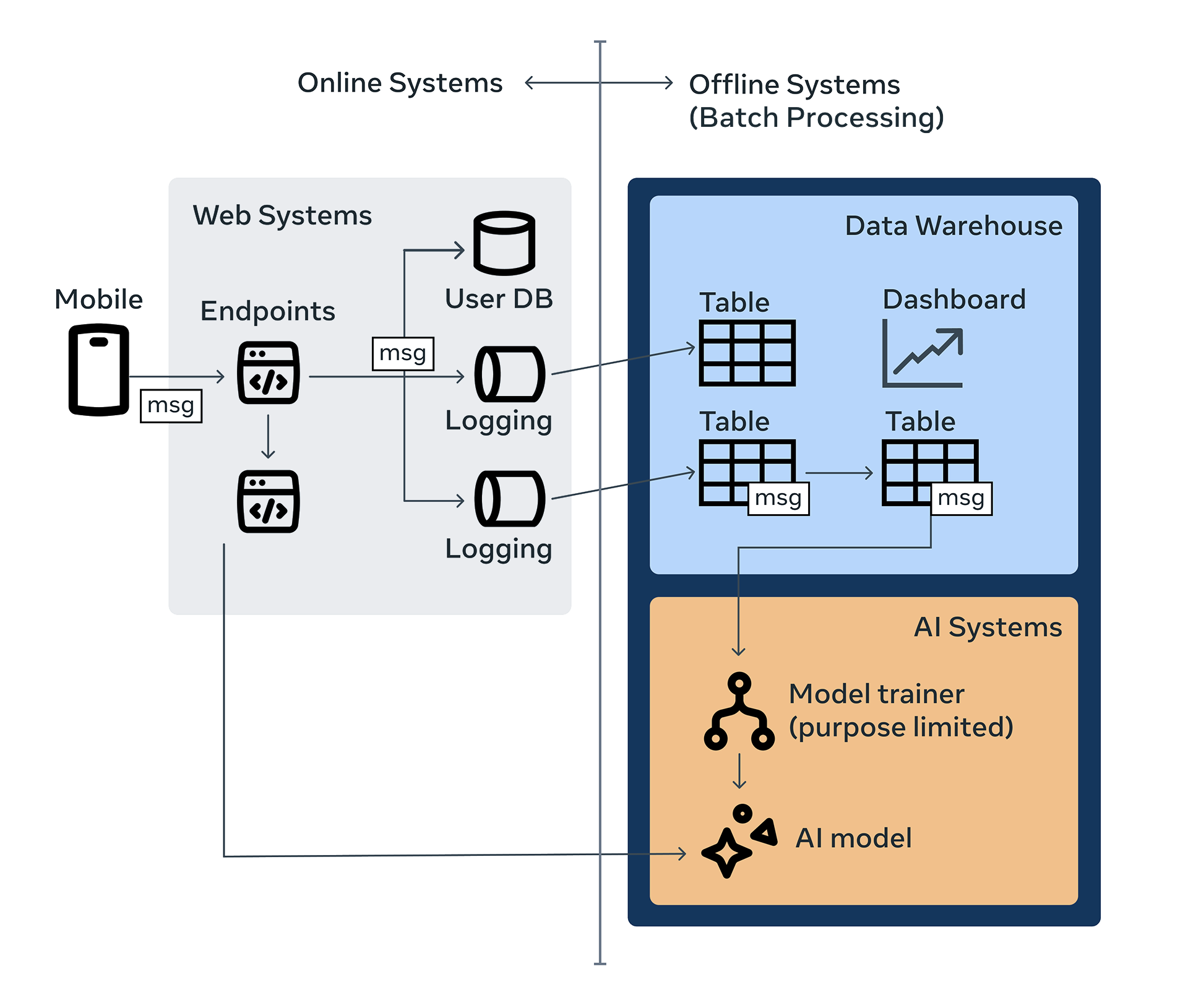
Messaging data is collected from these apps and enters into our data warehouse and AI systems via logging or database scrapes from web systems. It is streamed through our message queue, Scribe, where it can be processed in real time or stored in a time-partitioned dataset for asynchronous batch processing.
The logging libraries are configured in a fluent builder pattern. Below is a snippet that shows how a logger is configured to log messaging metadata. The key element is that the logger is associated with a Policy Zones annotation; in this blog post we call it MESSAGING_DATA. This annotation is called a Governable data annotation (GDA). GDAs are simple, human-readable labels that affect the behavior of access on the dataset. GDAs have controls on their lifecycle that ensure data policies are upheld. In the representative code snippet below, the annotation on the logger will restrict where the data can flow, in particular it can only flow to other datasets that have this annotation, and further that access to it is restricted to allowed purposes defined in a separate central configuration.
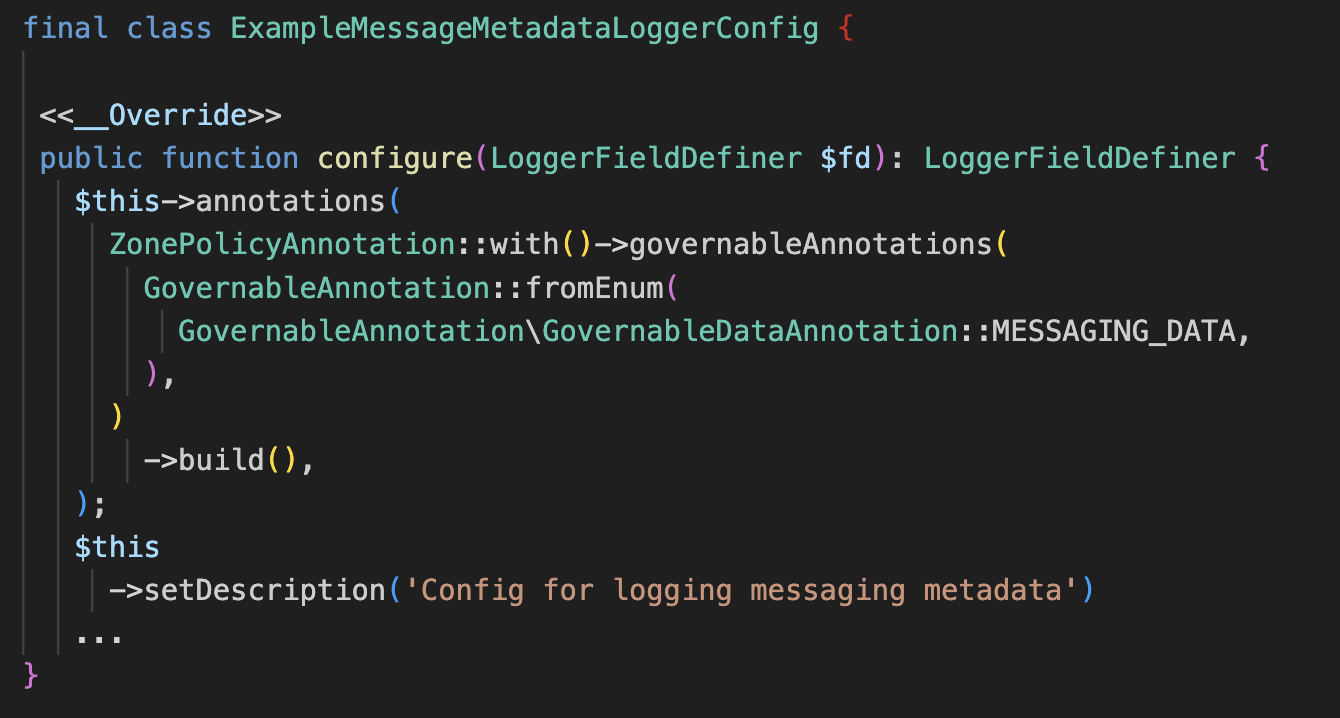
The above annotation on the logger will trigger Policy Zones’ infrastructure to impose certain restrictions. One key requirement is that downstream data assets, which rely on this logger’s data, must also carry the same annotation. This is done by leveraging Policy Zone’s flow control mechanisms that reason about how data flows through our systems. A processor can access a dataset annotated with a GDA if the Policy Zones infrastructure has checked the flow of data.
The logger config code snippet above generates code that writes data to a corresponding Scribe message queue category from our web servers. Policy Zones verifies that the messaging GDA is associated with this downstream Scribe category, ensuring compliant data flow (see the corresponding flow below).
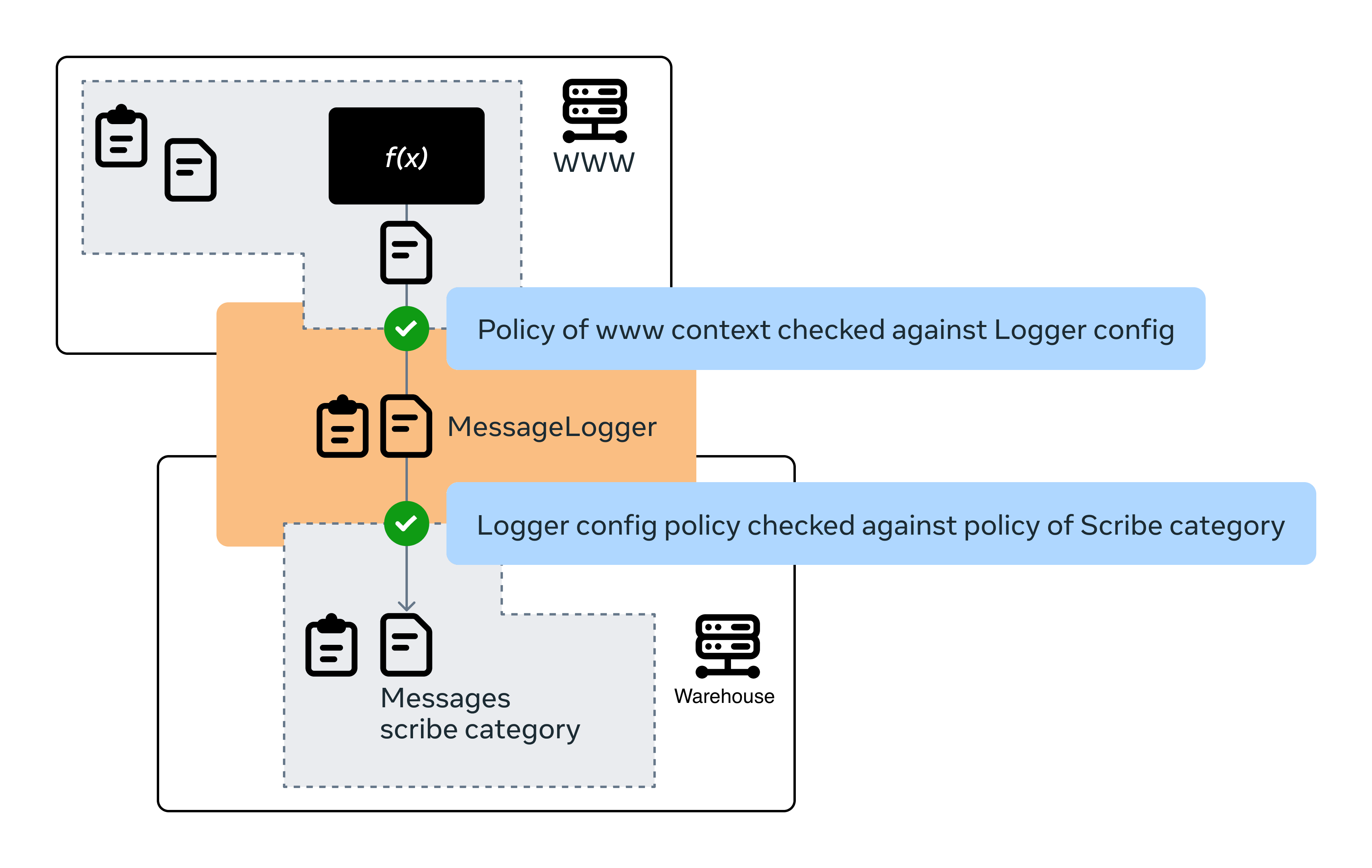
Scribe category data is processed by our stream processing systems and ingested into the warehouse in the form of time-partitioned datasets. These time-partitioned datasets are used by our batch processing to compute derived datasets to product support analytics, machine learning, and operational monitoring, among other uses.
Enforcing zones as data flows through the warehouse
In the next section, we’ll explore how Policy Zones enforces purpose-use limitation in the warehouse. Data processing within the data warehouse is typically represented using SQL, which defines how to store, transform, and retrieve relational data. SQL’s declarative nature and robust support for relational data processing enables users to write large-scale data processing jobs that can handle petabytes of data with minimal code. These attributes significantly enhance the efficiency and effectiveness of privacy-related tasks, allowing for scalable, policy-compliant data processing across our infrastructure. The most popular warehouse processors, like Presto, are SQL-based.
Scheduling these queries is done through our distributed job scheduling framework, Dataswarm. Users specify the frequency of runs and what data they depend on. Since our data is primarily time-partitioned, job schedules mirror the partitioning scheme of the data starting in a waiting state, and then run as soon as new time partitions become available. An example representative dataswarm pipeline is shown below, that calculates daily messages sent. It does this by reading a representative example of an input messages metadata logger dataset (described above), transforming that data and then writing it into an output messages_sent table.
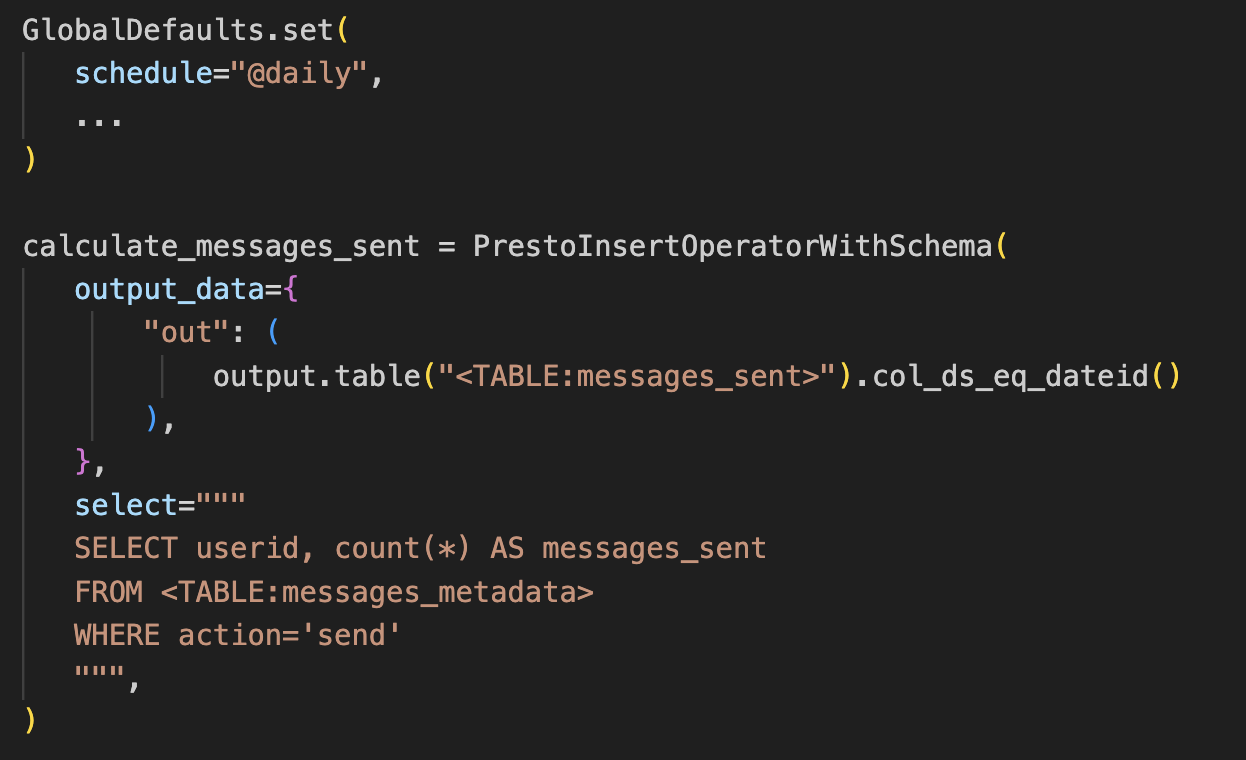
The example query in the Dataswarm pipeline above illustrates how to compute a derived dataset, calculating the daily number of messages sent per user. This concise, templatized SQL statement is processed by Dataswarm, which generates a fully expanded SQL statement that Presto then interprets to initiate a distributed job across thousands of machines. By abstracting away the execution details, engineers can focus on defining high-level transformations, simplifying the development process and improving productivity.
![]()
We built Unified Programming Model (UPM), a SQL parser that intercepts queries issued by various data processors and translates them into semantic trees. These trees capture the inputs, outputs, and transformations of each data movement step, providing the necessary signals for precise policy enforcement as data flows through the system.
As shown in the diagram below, the process begins with data processors issuing SQL queries. UPM parses those queries and sends the information about the transformation to the first key piece of Policy Zones infrastructure: the Policy Evaluation Service (PES). PES performs flow control checks, validating whether the data movement and transformation steps comply with privacy policies. The diagram below shows how Policy Zones integrates with the existing batch processing infrastructure.
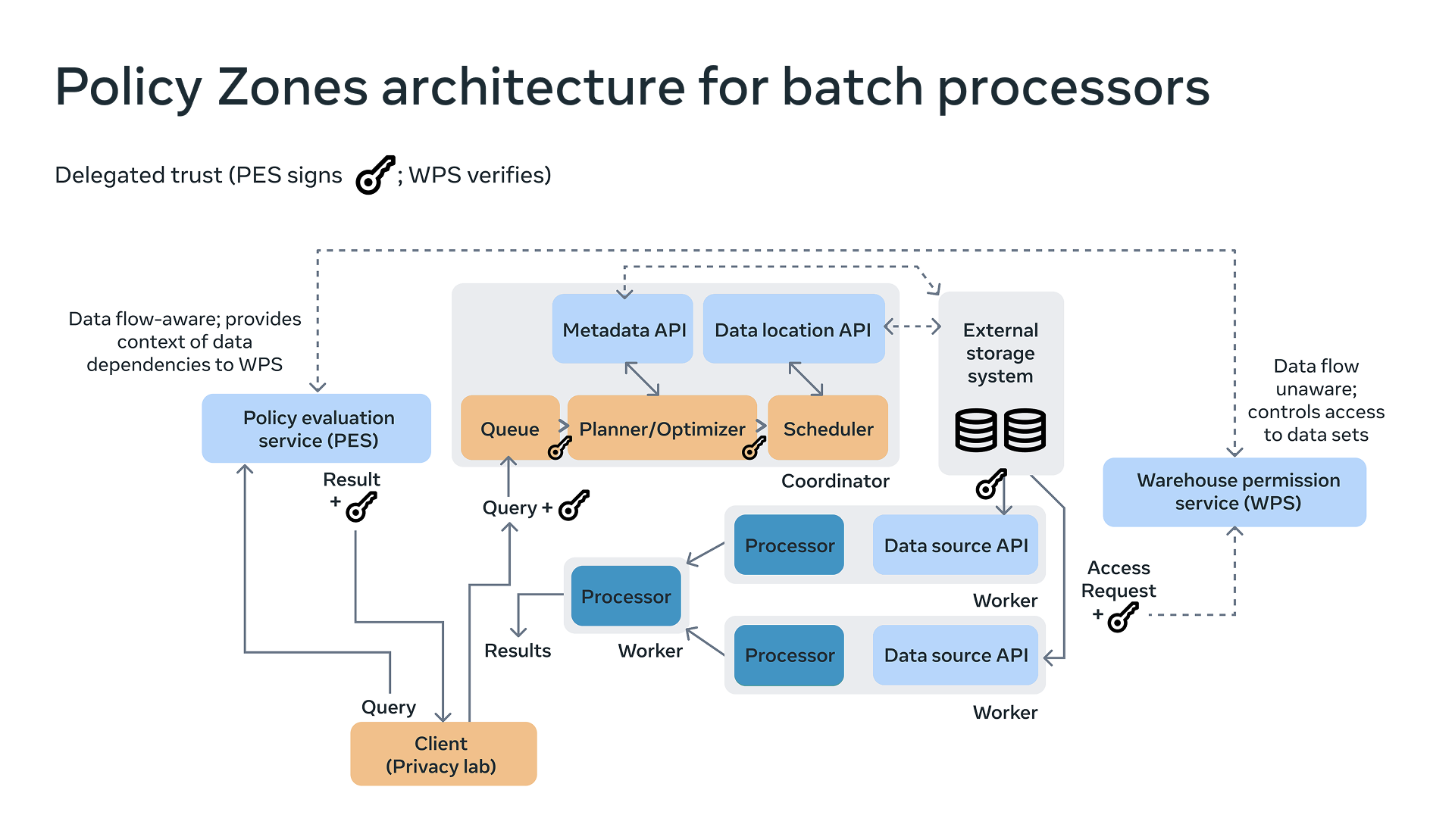
If a flow is allowed, PES passes the decisions to the compute engines, which then perform the actual low-level data accesses. PES also forwards the checking results to the Warehouse Permission Service (WPS), which performs a final validation, ensuring that access to warehouse data is reasoned about in a policy-aware manner. WPS was built to service traditional access control. We have since augmented its abilities to also ensure safe flows according to the GDAs annotated on the accessed datasets. It does this through propagation of a special token (depicted above with a key icon). PES issues the key to the client, which contains cryptographically signed contextual information. That key is then forwarded through the compute engines and passed in at time of access. This allows WPS to have enough context to reason about the access in the greater context of the overall flow. To illustrate this change, let’s look at how WPS has changed with the integration of Policy Zones. Historically, WPS only received individual access requests (e.g., “read table A by identity X,” or separately, “write table B by identity Y”). With our Policy Zones integration, WPS can now see additional information such as, “read table A by identity X and PES says the read satisfies the GDA flow safety requirements on the MESSAGING_DATA GDA.”
Processors integrate against Policy Zones through a client-side library we refer to as PrivacyLib. PrivacyLib abstracts the coordination logic, operational monitoring, and service calls in an effort to separate concerns between data processing business logic and privacy checking.
Stream processing. Up until this point, we’ve described how data flows from web server frontends to time-partitioned datasets in the warehouse via an ingestion system that reads from Scribe categories. However, there are also real-time stream processing systems that directly operate against the Scribe categories, rather than working on the bulk time-partitioned datasets. These systems are often used in latency-sensitive systems where we need to compute results quickly from large datasets (e.g., categorizing newly created users originating from a spam bot based on their recent events to detect terms of service violations).
Policy Zones are also integrated into these systems in much the same way. XStream is our next-generation stream processing system that provides a SQL-like interface for defining streaming data transformations. We use the same UPM parse to determine safe data flows. Key to scaling and reliability is that we analyze the streaming application statically before it starts processing events. This is made possible by XStream’s declarative data transformation programming model. Other realtime processing systems are handled by Policy Zones for function-based systems, which was alluded to in our earlier blog post about Policy Zones.
The critical component in allowing fine-grained data separation is the Flows-To evaluator in PES. After the source-sink data dependency information is extracted, PES determines if the flow of data is permissible by using information-flow control-theoretic checks. Some of these checks can include ensuring a consent check was performed by the data processor (e.g., to ensure the user permits their data to be used for a certain purpose), or that the GDA from the source tables are also on the destination table. These checks can be modeled as a lattice where the nodes represent different GDA labeling states and purpose use, and the edges between them represent allowed (safe) transitions. The code snippet below shows the logic of one of the functions that performs our purpose-use checks for GDAs, written in Rust, with some modifications made for clarity.
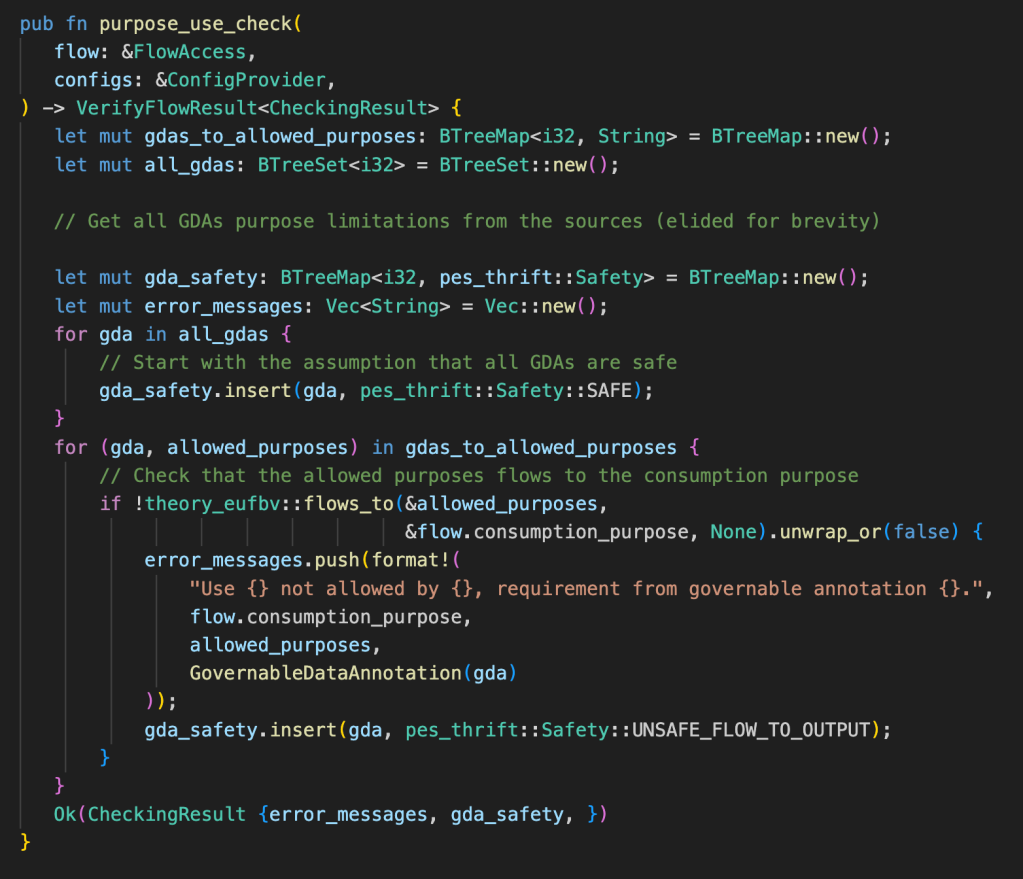
Putting the pieces together, PES and WPS integrate into our batch processing systems to allow seamless flow safety checks against our purpose-use limitation requirements. Instead of traditional coarse-grained data separation, engineers can write batch processing queries that access datasets with heterogeneous purpose-use requirements all in the same warehouse. People do not necessarily need to request permission to special purpose-use limited silos of the warehouse as Policy Zones can ensure the data is protected despite being commingled with other non-purpose-use restricted datasets. This unique ability is particularly useful for machine learning workflows, which we discuss in the next section.
Enforcing zones for AI training workflows
Non-content messaging data is used to train models, such as spam filters, to identify and block unwanted or malicious messages, ensuring a safe user experience. PES is integrated directly into the APIs used by workflows for reading and writing data and models, enforcing strong data usage protections. Below is a main scenario detailing data flow in the ML stack. The diagram below shows the component architecture of AI training at Meta, and how Policy Zones integrates with it. Key to our architecture is that PES integrates principally at the control plane of AI training. To build intuition from the previous general purpose warehouse processing section, this is analogous to checking SQL statements rather than checking individual rows being accessed.

Machine learning training workflows are defined by user-authored scripts, which can be created using internal authoring tools, all of which utilize Python. Users also have the option to directly write custom Python code to interact with workflow scheduling tools like FBLearner. During the training process, large-scale dataframes are loaded into the training workflow. These dataframes can be sourced from Data Warehouse or directly from real-time batch services.
In scenarios involving distributed training, intermediate storage like temporary tables are used to temporarily store data outputs between operators. The resulting models are stored in the model storage system. For tasks such as transfer learning or recurring/continuous training, these models can be retrieved from the model storage and reintroduced into the training workflow for incremental updates.
Workflows can be annotated with purpose-use requirements in the following ways.
- Automatic inference: PES automatically infers annotations from upstream data dependencies and applies them to the current workflow and all downstream dependent models or assets, provided there are no conflicts.
- Manual override: Users can manually override the inferred annotations when authoring workflows or in the model type linked to the workflows. The “Model Type” is a widely used concept at Meta to describe the clearly delineated business purpose for the machine learning work.
Below is a representative code example defining a training workflow:
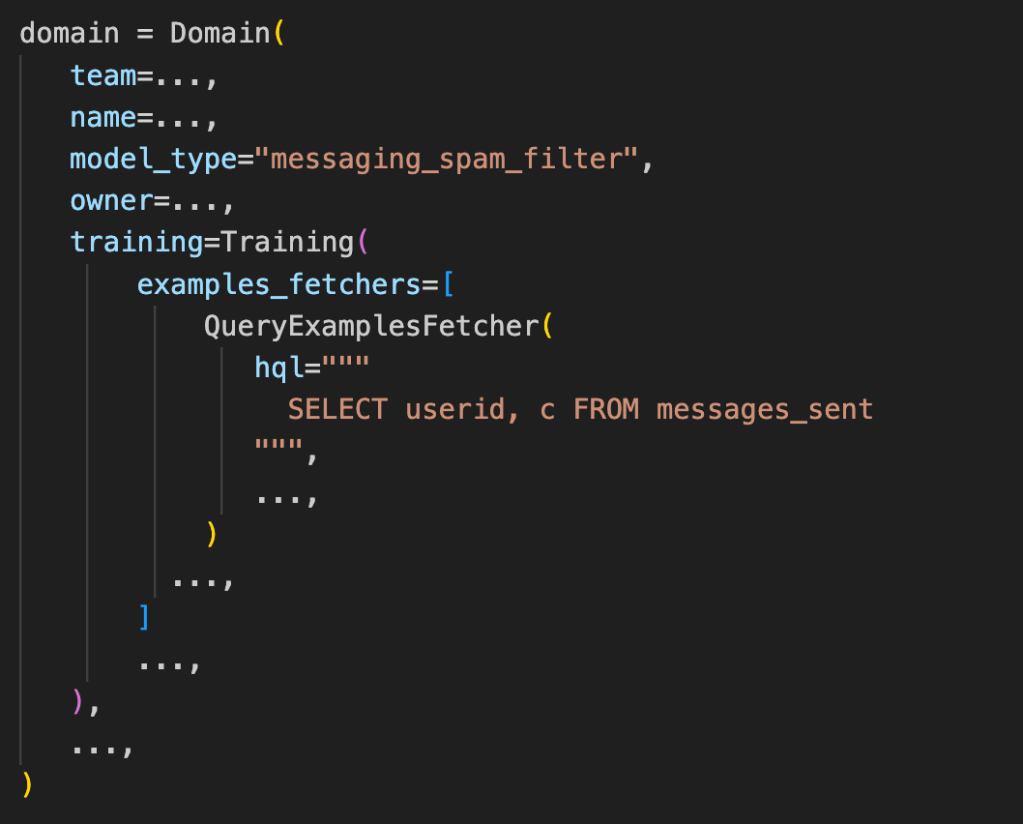
We associate model types with a GDA. The following shows the configuration information for the messaging_spam_filter model type; note that it is annotated with the MESSAGING_DATA GDA.
At run time, we associate all accesses during the workflow with a model type and ensure that the assets being written to also have GDA. PES is integrated into various data reading and writing APIs within the AI training stack to accommodate this capability. When a workflow reads data, it retrieves the data’s annotations. The first annotation is applied to the workflow. When the workflow outputs data, the data output is annotated with the current workflow’s annotation, including any intermediate datasets.
How Policy Zones are applied reliably at scale
Policy Zones Manager (PZM) enables engineers to reliably integrate Policy Zones to existing data processing and propagate them to new processing code. PZM supports two major workflows: applying zones to existing processing, and propagating zones from new processing. Although many components are shared between these two workflows, the overall experience is quite different for engineers.
Applying zones to existing processing. PZM allows engineers to seed a proposed annotation on a dataset (e.g., the logger from the beginning of the blog post) to understand the downstream implications. Since Policy Zones is an enforcement mechanism, care must be taken in applying GDAs as it may break production workflows. PZM will guide an engineer trying to add a GDA through the right steps to avoid any production breakage. It does this by simulating the potential effects of enforcement that comes from the new GDA labeling, and then suspending flows that would break. These suspensions are then tracked and burned down by the engineer to ensure complete end-to-end compliance with the GDA’s purpose-use requirements.
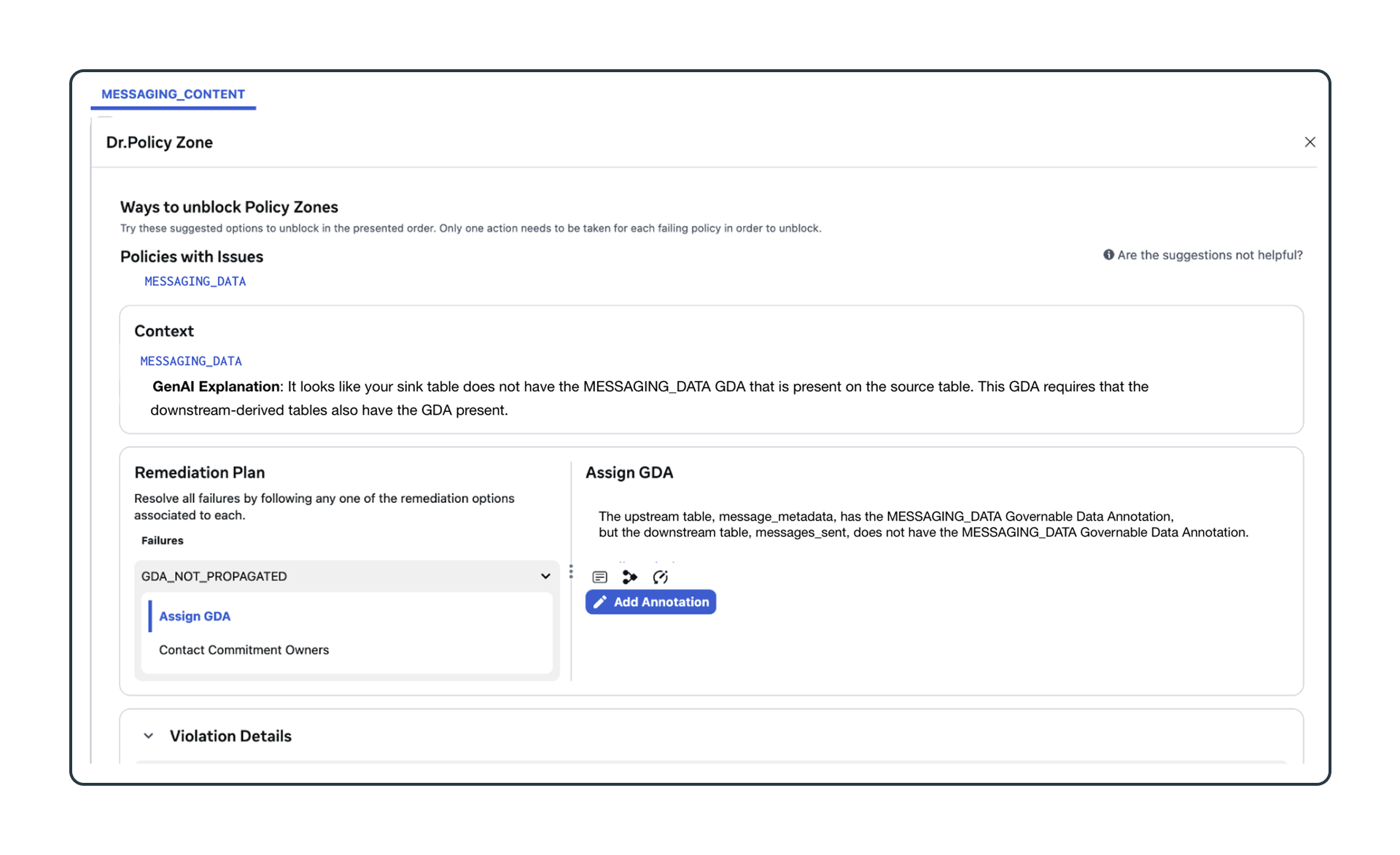
Propagating Zones from new processing. As engineers build new processing pipelines, PZM validates the new flows and surfaces any issues detected with the data flow. As data flows through our warehouse, we need to ensure derived datasets continue to be properly annotated. When a user tries to derive new datasets from Policy Zones-protected data, the system may automatically repair the flow (e.g., by propagating the annotation when the intention is clear from context), or if the context is unclear, will present an interstitial to the user. Dr Policy Zone (Dr. PZ) is a debugger tool that guides an engineer to resolve these kinds of Policy Zones errors.
To illustrate how Dr. PZ works, recall above the example SQL statement that computes message sends for each user. The SQL read from the message_metadata table and wrote to the messages_sent table. If the output table does not have the right set of GDAs, the user will be presented with an error message and ways to fix their in-development pipeline. We use generative AI to simplify the explanation to the user and also to provide some remediation guidance. The screenshot below shows an example of a dialog an engineer would interact with in Dr. PZ.
 Reclassification is critical to limiting over-annotation from spurious flows. In our messaging example, reclassification allows us to stop propagating the MESSAGING_DATA GDA on an output table even if the source table may have it. Reclassifications are governed by a precise set of rules that ensure the high-level data policies are not broken. In general, reclassifications are controlled by separate safeguards independent from Policy Zones. Allowed reclassifications are specific to each GDA and may include: different privacy systems Policy Zones is not natively aware of, complex privacy-preserving transformations (e.g., differential private mechanisms), or through routine review by human subject matter experts.
Reclassification is critical to limiting over-annotation from spurious flows. In our messaging example, reclassification allows us to stop propagating the MESSAGING_DATA GDA on an output table even if the source table may have it. Reclassifications are governed by a precise set of rules that ensure the high-level data policies are not broken. In general, reclassifications are controlled by separate safeguards independent from Policy Zones. Allowed reclassifications are specific to each GDA and may include: different privacy systems Policy Zones is not natively aware of, complex privacy-preserving transformations (e.g., differential private mechanisms), or through routine review by human subject matter experts.
Learnings and challenges
In our blog post that introduced Policy Zones, we discussed some of the high level learnings and challenges of scaling out Policy Zones. In this section, we focus on the learnings and challenges from scaling Policy Zones for batch processing.
Opaque operators. Not all processing in the warehouse is SQL-based. An example would be small-scale intermediate processing in a general purpose programming language: Dataswarm supports PhpMethodOperator, which allows one to write arbitrary Hack code transformations on (small) warehouse datasets. For these cases, we built processor-specific integration points to capture the context of the data flow. PrivacyLib makes integrations relatively straightforward. The major challenge we had to overcome was finding the right place to integrate Policy Zones checking. We targeted low-level data access call sites as PrivacyLib can help stitch together data dependency information (e.g., by logging reads to correlate against future writes by a data processor).
Reclassification versus complex data policies. Our original instantiation of policy rules was quite expressive. It allowed the formulation of intricate data flow policies. An advantage of this approach is that we did not need to use reclassification as the policy captured most of the subtle intricacies. The major disadvantage of this approach was that it was very difficult for engineers to understand and debug blocked flows. We decided to simplify our policy language to a nominal typing system of flat, hierarchy-free human-readable labels. Safe transitions could only be described through transitions from one set of GDAs to another set. We found that nuances in a data policy were better tracked by our reclassification system so engineers could generally have a simple model of the policy that worked for most data processing.
The future of Policy Zones for batch processing
Policy Zones enables developers to quickly innovate in our data warehouse while respecting the various privacy requirements on the data they are using. Policy Zones has hit major milestones in the warehouse, but we still have exciting opportunities ahead of us. These include:
Reducing friction through generative AI: Navigating Policy Zones errors can be quite tricky at times. We’ve built an expert system in Dr. PZ that attempts to help engineers navigate the right remediation plan. In addition to this deterministic system, we are also experimenting with using generative AI to help a user navigate the right path and better understand why they are being blocked.
Closing the gap on opaque operators: as mentioned in the previous section, we’ve had challenges in tracking the data dependencies in some of our processing. For the time being, we’ve resorted to traditional coarse-grained data separation and siloing processing. However, we are continuing to close this gap through improved PrivacyLib integrations to further reduce friction for engineers so they can enjoy the benefits of fine-grained data tracking.
Seamless hand-off to Policy Zones for function-based systems: in our original blog post we described two versions of Policy Zones. This post focuses on the first, Policy Zones for batch processing systems. A future post will focus on the second, Policy Zones for function-based systems.
In day-to-day usage, the end-to-end flow of data and processing touches on both of these systems. Today, we have a process to ensure that the requirements from one Policy Zones system are eventually mirrored in the other as data moves between the two. We hope to make this experience more seamless so that engineers don’t have to think about two separate runtimes.
Acknowledgements
The authors would like to acknowledge the contributions of many current and former Meta employees who have played a crucial role in developing purpose limitation for batch processing systems over the years. In particular, we would like to extend special thanks to (in alphabetical order) Aihua Liu, Alex Ponomarenko, Alvin Wen, Andy Modell, Anuja Jaiswal, Avi Heroor, Ben Sharma, CJ Bell, Chris Green, David Taieb, Dávid Koronthály, Dino Wernli, Dong Jia, Ganapathy (G2) Krishnamoorthy, Govind Chandak, Guilherme Kunigami, Gunjan Jha, Harsha Rastogi, Ian Carmichael, Iuliu Rus, James Gill, Jon Griffin, Jerry Pan, Jesse Zhang, Jiahua Ni, Jiang Wu, Joanna Jiang, John Ahlgren, John Myles White, Judy Nash, Jun Fan, Jun Fang, Justin Slepak, Kuen Ching, Lung-Yen Chen, Manos Karpathiotakis, Marc Celani, Matt Shaer, Michael Levin, Mike Lui, Nimish Shah, Perry Stoll, Pradeep Kalipatnapu, Prashant Dhamdhere, Prashanth Bandaru, Rajesh Nishtala, Ramnath Krishna Prasad, Ramy Wassef, Robert Rusch, Ruogu Hu, Sandy Yen, Saurav Sen, Scott Renfro, Seth Silverman, Shiven Dimri, Sihui Han, Sriguru Chakravarthi, Srikanth Sastry, Sundaram Narayanan, Sushil Dhaundiyal, Tariq Sharif, Tim Nguyen, Tiziano Carotti, Thomas Lento, Tony Harper, Uday Ramesh Savagaonkar, Vlad Fedorov, Vlad Gorelik, Wolfram Schulte, Xiaotian Guo, Xuelian Long, Yanbo Xu, Yi Huang, and Zhi Han. We would also like to express our gratitude to all reviewers of this post, including (in alphabetical order) Avtar Brar, Brianna O’Steen, Chloe Lu, Chris Wiltz, Jason Hendrickson, Jordan Coupe, Morgan Guegan, Rituraj Kirti, Supriya Anand, and Xenia Habekoss. We would like to especially thank Jonathan Bergeron for overseeing the effort and providing all of the guidance and valuable feedback, and Ramnath Krishna Prasad for pulling required support together to make this blog post happen.








