
Meta is currently operating many data centers with GPU training clusters across the world. Our data centers are the backbone of our operations, meticulously designed to support the scaling demands of compute and storage. A year ago, however, as the industry reached a critical inflection point due to the rise of artificial intelligence (AI), we recognized that to lead in the generative AI space we’d need to transform our fleet.
Our increased focus on AI was driven both by its rise in driving business outcomes and the huge growth in these types of workloads’ computational needs. In addition to wider use of traditional AI for things like ad targeting, we have also seen increasing numbers of large generative AI models that mimic almost-human intelligence in everything from human verbal interaction to the creation of pictures and other media. And these types of models are huge, with trillions of training parameters, and to train them we need vast resources.
In this process, we’ve built one of the world’s largest AI training infrastructures, and it has been growing exponentially over the last years. Meta’s training infrastructure comprises dozens of AI clusters of varying sizes, with a plan to scale to 600,000 GPUs in the next year. It runs thousands of training jobs every day from hundreds of different Meta teams. Training jobs characteristics vary greatly too. They can be as small as a single GPU running for a couple minutes, while generative AI jobs can have trillions of parameters and often span thousands of hosts that need to work together and are very sensitive to interruptions. In addition to that, training jobs are tied much closer to the hardware, and that hardware varies greatly. Meta runs different types of backend networks, topologies, and training jobs that have tight dependencies between software and hardware components.
This transition has not been without its challenges. We had to reconfigure the fleet without disrupting our hypergrowth, a task akin to rebuilding an airplane mid-flight. This pushed us to innovate and collaborate with vendors and utility companies to create a supportive ecosystem. In this blog we will discuss only one of these transformations. We will describe how Meta is maintaining these training clusters and what sets us apart from the average AI environment. And what do we mean by maintaining? Basically, any kind of operation that updates or verifies software and firmware components in the clusters, including the networking path.
The main characteristics of GPU training
GPU training has some demanding characteristics:
- Capacity guarantees: While some training jobs can be paused, a lot of Meta jobs are time-critical and recurring or online. This means we cannot take large amounts of capacity on a default basis.
- Bad hosts are very bad: Since many jobs require all hosts to be synchronized, bad hosts that are a bit slower, have some non-fatal hardware, or have networking issues are extremely damaging.
- Low interruption rate: Since many hosts work with each other on a shared problem, AI training jobs are sensitive to interruptions.
- Rollout safety: The AI software stack is deep, and problems are often hard to pinpoint, so we need to be careful when rolling out new components.
- Host consistency: AI training jobs are in general cross-host, and while outside of the CUDA version there are rarely hard incompatibilities, we have learned that cluster consistency is highly important for debugging and SEV avoidance.
What’s special about Meta’s GPU training?
Meta uses bespoke training hardware with the newest chips possible and high-performance backend networks that are highly speed optimized. We also try to stay as current and flexible as possible with the software stack; in the event of firmware upgrades, this allows us to utilize new features or reduce failure rates.
Together this means we have more than:
- 30 maintenance operations
- 50 different components that are updated
- Three different host-verification tasks to ensure optimal performance and stability
- Thousands of disruptive AI host tasks every day
And we need to do them safely, while guaranteeing capacity. After all, our training clusters are also used flexibly to run a wide variety of workloads, from single-host to some of the biggest training jobs in the world, and from offline tasks to jobs that need to be up and running 24/7.
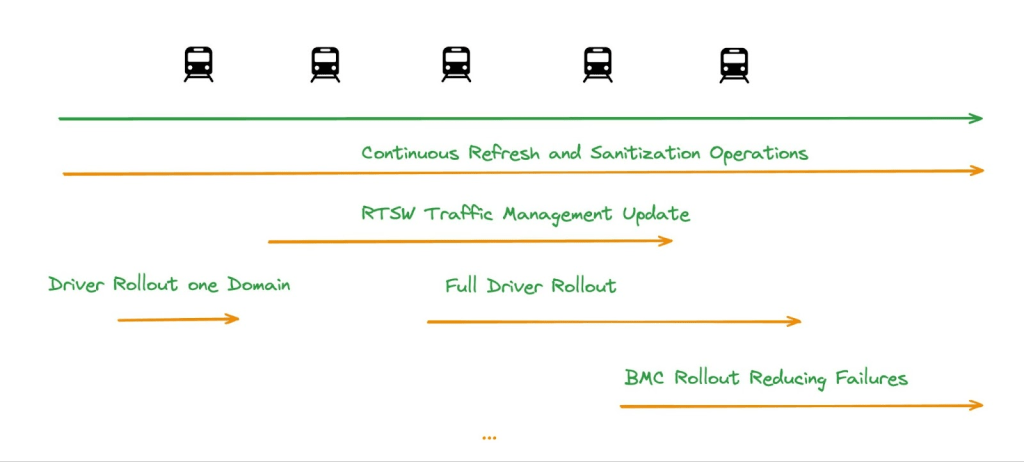
Given the variety of upgrades, we have a large amount of overlapping inflight changes at any given time, including some that are consistently being applied, such as verification tasks. Accepting this gives Meta the flexibility we need in using cutting-edge hardware, scaling our infrastructure, and using both in flexible ways. In smaller environments it is often possible to keep clusters in a consistent state and upgrade the whole cluster and all of its firmware and software components in the same maintenance window. Doing this in a large, diverse environment like Meta, however, would introduce big risks and be operationally infeasible. Instead, we ensure components are compatible with each other and roll component upgrades up in a sliding fashion. This approach also allows us to guarantee capacity availability.
Maintenance trains
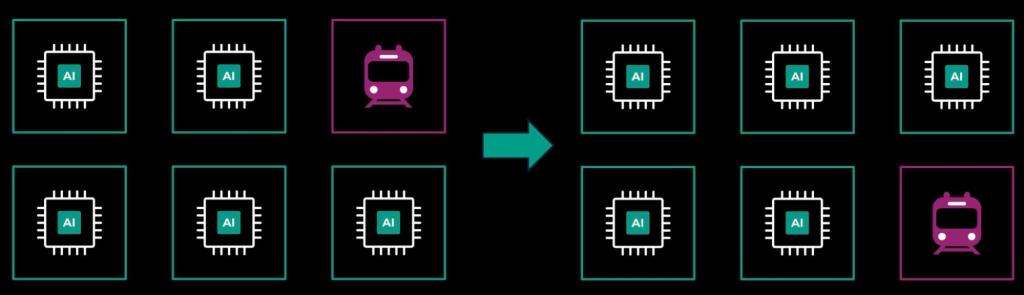
Outside of special cases, Meta maintains its fleet of clusters using a technique called maintenance trains. This is used for all capacity, including compute and storage capacity. A small number of servers are taken out of production and maintained with all applicable upgrades. Trains provide the guarantee that all capacity minus one maintenance domain is up and running 24/7, thus providing capacity predictability. This is mandatory for all capacity that is used for online and recurring training.
Maintenance trains pick up any new upgrade and guarantee a full-visit cycle in a guaranteed timeframe. Longer-running upgrades can have lower rollout guarantees and may be scheduled to be applied in multiple cycles. So you can have many overlapping upgrades, and, if beneficial, upgrades can be aligned.
For AI capacity, we have optimized domains that allow for different kinds of AI capacity, very strict SLOs, and a contract with services that allows them to avoid maintenance-train interruptions, if possible.
Gradual rollouts
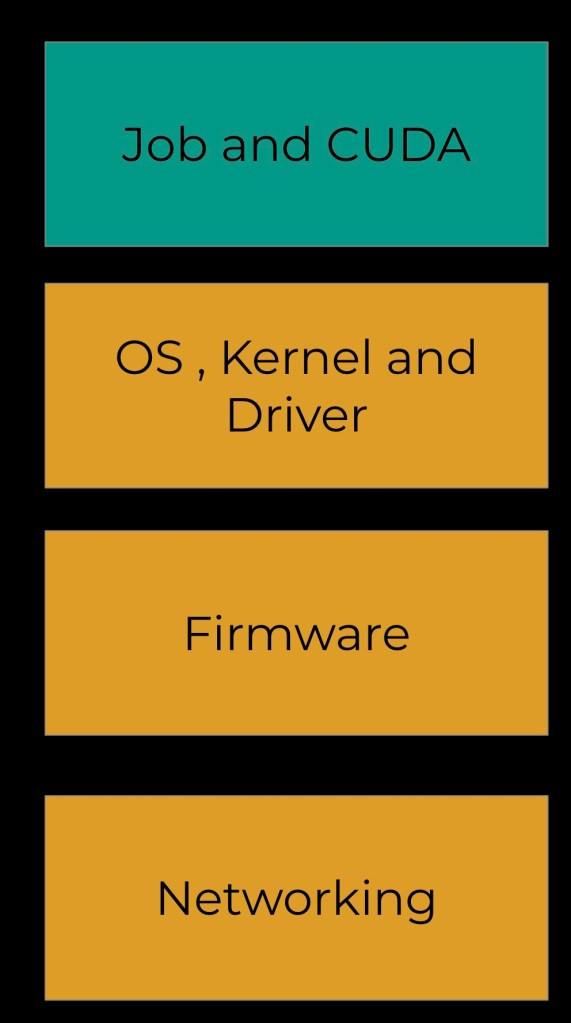
Because of the scale of our infrastructure, we had to ensure that all disruptive rollouts outside of special cases happen in a gradual fashion. This means different servers in a cluster can run a different host stack for a short period of time. This is quite normal in traditional capacity but challenging in AI training, since AI jobs are very closely tied to the hardware.
At Meta, we’ve ensured that jobs have a consistent stack but upgrade lower-level components in a gradual fashion. In contrast to this, the AI job itself, which includes the CUDA library, is always consistent. This distinction is necessary because lower-level components often require hours to install and configure or require rebooting the host, while higher-level components in the job container itself can be restarted fluidly.
This sounds simple, but because of the tight integration of AI with hardware, we have needed to do a lot of development, including careful testing on all lower levels, special monitoring, and tight work with vendors.
By and large, this has been very successful. The AI stack in general has matured a lot over the past three years. We also added tooling for rare compatibility-breaking upgrades.
Selecting the correct maintenance domains
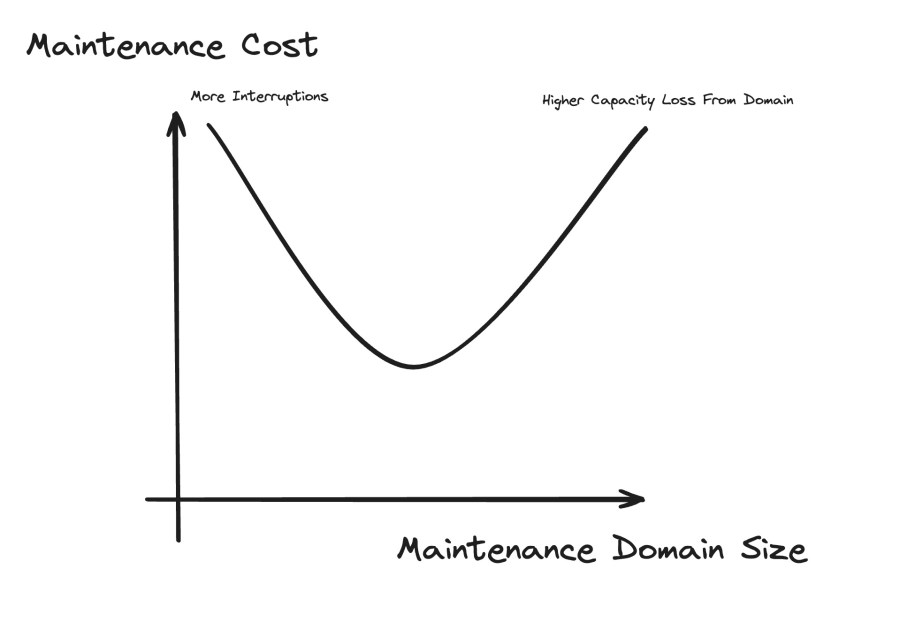
One way to ensure optimal AI performance was to work with AI teams to design the optimal size of maintenance domains. A maintenance domain is the percentage of capacity we take down in one go, and selecting the optimal size is a function of both the cost of interruptions and the capacity that is lost during the maintenance duration. Since interruption costs are high for AI jobs, optimizing this relationship allowed us to significantly reduce the maintenance overhead for AI capacity.
OpsPlanner: Meta disruptive-work orchestrator
Critical to AI capacity are the consistency requirements. For example, if you want to move to a new CUDA version, you may need all of the capacity on a new driver version. This becomes really difficult in an environment with thousands of hosts and lots of planned and unplanned operations that may overlap with each other. To do this safely and guarantee hosts have the correct upgrades applied before entering production, Meta has unified them in the OpsPlanner work orchestrator. Not only can it work on overlapping scopes of operations and correctly serialize them, it also takes them safely out and into production. In addition, it has a built-in handover flow that ensures correct escalation behavior and avoids overlaps and deadlocks. OpsPlanner can also ensure upgrades are applied to hosts before they are returned to production. And OpsPlanner owns planned maintenance and failure buffers and safeguards them. Furthermore, it’s highly effective and efficient: OpsPlanner currently handles a million operations per day.
Safety and failure scenarios
Meta has a deep stack of safety features that includes:
- Autostop of maintenance trains if maintenance or failure buffers are exhausted;
- Automatic offboarding of failing upgrades; and
- Rollout phases for upgrades, so that only well-tested changes reach global systems.
If something does go wrong, however, we can react quickly, depending on the needed fix, with emergency trains, large-scale maintenance for breaking upgrades, and more.
Rapidly moving to the future of generative AI
At Meta, we believe in moving fast and learning by doing. Rapid innovation is in our ethos. This is what fundamentally shaped our journey as we continually innovated towards building the foundational infrastructure that makes us leaders in generative AI. We will remain dedicated to creating technologies that not only benefit Meta but also have a positive impact on society as a whole.
As we move forward, we invite you to join us on this journey. Together, we can shape a future where AI is not just a tool but a force for good, transforming industries, empowering individuals, and creating a more sustainable world.
The best is yet to come, and we are excited to pioneer tomorrow’s possibilities in generative AI.








