")
- Meta’s Systematic Code and Asset Removal Framework (SCARF) has a subsystem for identifying and removing unused data types.
- SCARF scans production data systems to identify tables or assets that are unused and safely removes them.
- SCARF avoids tedious manual work and ensures that product data is correctly removed when a product is shut down.
This is the third and final post in our series on Meta’s Systematic Code and Asset Removal Framework (SCARF). SCARF contains a combination of subsystems that analyze code and data usage throughout Meta to aid in the safe and efficient removal of deprecated products. In our first post on automating product deprecation, we discussed the complexities of product deprecations and introduced SCARF’s workflow management tools that guide engineers through a coordinated process to safely deprecate products. In the second post on automating dead code cleanup, we discussed SCARF’s dead code subsystem and its ability to analyze both static and dynamic usage of code to automatically generate change requests to remove unused code. Throughout this series, we have referred to the example of the deprecation of a photo sharing app called Moments, which Meta launched in 2015 and eventually shut down in 2019.
In this post, we introduce the subsystem responsible for automating the identification and safe removal of unused data types at Meta. This process can be unexpectedly difficult, because large software systems are inevitably interconnected. Moments relied on several pieces of shared Facebook functionality and infrastructure, and deleting it was more complicated than simply turning off servers and removing data tables.
Unused data cleanup
SCARF implements an unused data type cleanup system for Meta engineers to leverage when they want to ensure consistent removal of unused data. SCARF scans data systems to identify each type of data stored (for example, identifying all the tables in a relational database) and, for each of these, determines whether the data is being used. If any of the assets are not in use, SCARF initiates a process to safely remove them.
The types of data tracked by SCARF vary and include things like database tables, partitioned “use cases” in shared storage systems, or object classes. Each represents a class of data — not individual records. Meta has a separate system, DELF, for deleting individual records, rows, and objects.
SCARF coordinates several kinds of tasks for each data system: metadata collection (e.g., data quantity, field types), usage collection, analysis, and actions. These tasks share some common components and adhere to a standardized format; however, the implementation is inherently specific to each supported data system.
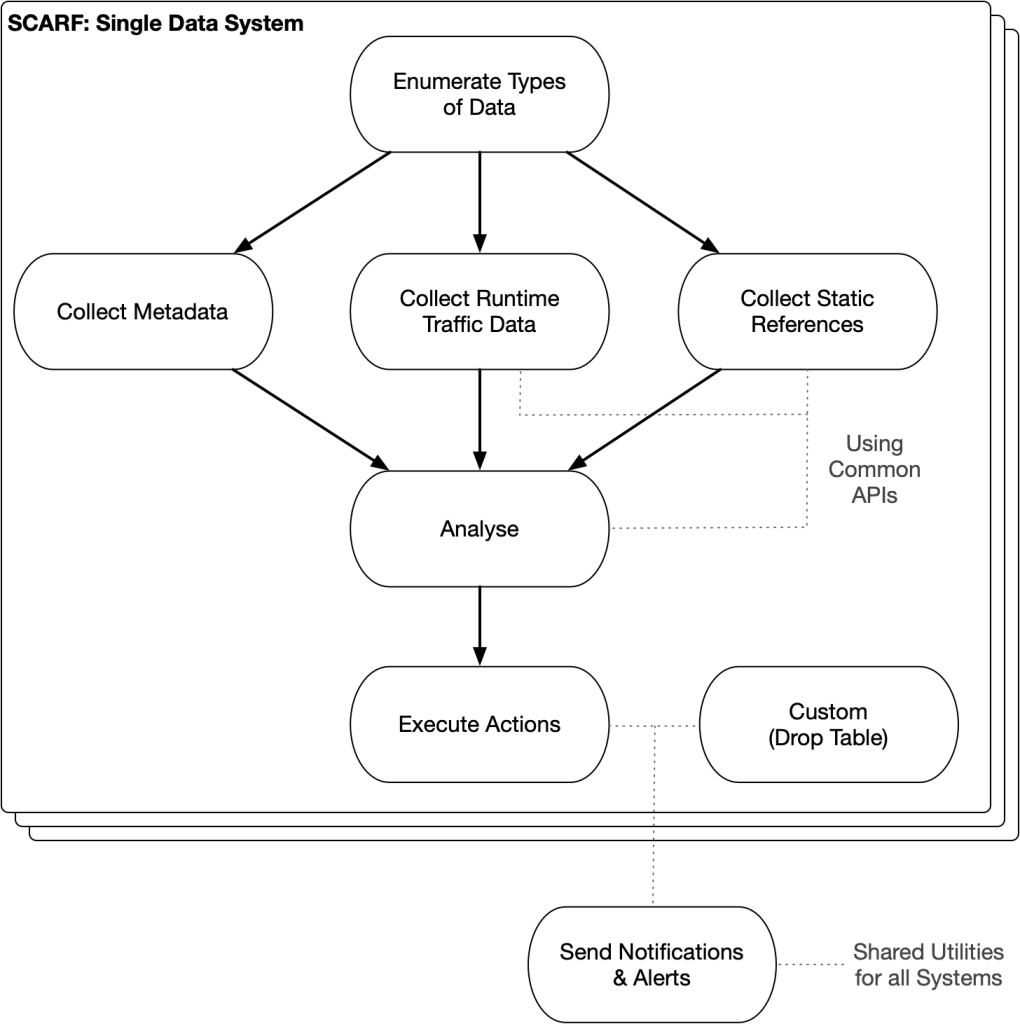
Measuring usage
SCARF tracks two primary metrics to determine if deletion is safe: It measures static usage by identifying code that appears to query a type of data; and it measures runtime usage by observing access patterns in production.
As mentioned in our blog post, Automating dead code cleanup, SCARF statically analyzes Meta’s codebases using Glean. Glean presents static analysis facts extracted from the compiler in an indexed, standardized format. SCARF queries Glean to locate code that appears to reference each type of data. For example, each type of data stored in Meta’s object graph data system TAO is referenced by an enum value: We can locate usages of each enum value in code across multiple languages.
viewed_photo = TAO.fetch(
id=objectId,
type=TAOType.USER_VIEWED_PHOTO,
)
SCARF also measures the usage of each type of data at runtime. We instrument Meta’s data systems to publish counters indicating how many reads each type of data has received from relevant sources, like production traffic from our webserver fleet, while ignoring traffic created by backup infrastructure.
Some of our data systems, like TAO, receive billions of requests per second. Instrumenting a data system at that scale, while ensuring we only measure certain types of usage, presents complex engineering challenges to avoid costly performance degradations.
Orchestrating removal
Once SCARF detects that a type of data is completely unused by combining the signals from our metadata, traffic analysis, and code references, it notifies the engineering team responsible for that data type, via an internal ticket, that cleanup will proceed .
After a configured time, SCARF blocks all reads and writes via a data system specific mechanism. This period of time is important as it acts as a dry run of what would happen when the data is truly deleted. Once this period elapses, the data will be deleted. The system keeps an internal log of actions it has performed for our records.
For example, if a type of data in TAO has no code references or production traffic, after a notification and waiting to see if there are objections, SCARF will instruct TAO to raise an error any time a service attempts to read from or write to that type of data. After a further monitoring phase, it will instruct TAO to delete the data.

Note that SCARF does not wait for the engineer’s acknowledgement when the internal ticket is filed – the system biases towards the automatic removal of unused data types and relies on its thorough analyses to ensure that only unused data is removed. If something is unused for long enough, it is less and less likely that problems will arise when automation cleans it up. Biassing towards automation improves efficiency and allows the system to scale beyond a process that requires manual approvals for every action.
Should a mistake be made, the access restriction period acts as a buffer where any mistakes can be caught before any data deletion occurs and our analysis can be updated to account for any missing signals. In the worst case, if data is deleted but should not have been, many systems at Meta provide backups to protect against data loss; and while the backups are available, they can act as a final safeguard to protect against erroneous deletions.
Engineers can interact with SCARF’s deletion process in various ways. As mentioned earlier, they can override the usage signals that SCARF detects in order to proceed with the deletion, if they determine those signals to be false-positives. They can also accelerate the process by shortening the waiting periods. Finally, engineers can highlight problems they have noticed back to our team who build SCARF itself: Often engineers will notice false-positives (cases when SCARF detects something as used, but it isn’t), and rarely false-negatives (when SCARF detects no usage, but there actually is usage), in the usage signals collected by SCARF.
Coping with cross-system dependencies
Meta has many different systems for storing data, many of which are specialized for a certain use-case. A high-quality product will often require the features of multiple different data systems. For example, TAO is a graph database that excels at serving many small, fast queries, but it wouldn’t be used for tasks like machine learning, ranking, or aggregation. As such, Meta frequently leverages multiple data storage systems for a single product, including data pipelines that move data between systems. SCARF hence has to understand the interconnections between these systems to ensure data is removed from each place it is stored and to prevent deletions from occurring out of order.
SCARF models these through a curated set of generated asset relationships. For a given asset and its corresponding inbound and outbound dependencies, SCARF determines the nature of the relationship, which dictates which asset must be deleted first and whether the deletion of one asset necessitates the deletion of the other. For example, some assets exist solely as the result of moving data between systems and must be removed together in a multi-step process. This modeling of system relationships within SCARF enables more thorough orchestration of data cleanup and prevents the system from attempting to delete assets out of order.
Coping with code usage
Thinking of Meta’s code and data definitions as a single dependency graph, SCARF can be seen as a system that prunes leaves and isolated nodes in this graph. This dependency graph changes over time, as new nodes and edges come and go with every piece of engineering work.
SCARF is unable to automatically remove data if it identifies code that could use this data, even if that code is not being run: SCARF, by design, will not break edges in this graph. For example, if an engineer commits a script referencing a type of data in TAO for debugging purposes, SCARF would correctly identify that as a reference to the use case and prevent deletion — even if the script is no longer used.
As mentioned in part two of this series, SCARF’s dead code subsystem works to help solve this problem through the automated removal of known dead code. If the dead code system is able to remove the unused script, the unused data can then be removed.
Removing data at scale
Removing unused data types not only simplifies our internal infrastructure, but also saves material capacity costs. In the last year, it has removed petabytes of unused data, across 12.8M different data types stored in 21 different data systems. While, in many products, an individual piece of data may consist of an identifier (primary key) and a small amount of data, at Meta’s scale there are billions of such rows. Data logged during routine usage of our services to provide analytics, operational logging, or analysis will also consist of billions of rows, multiplied by the retention of historical data in our warehouse, and our backups.
SCARF concurrently operates on millions of assets each day and drastically reduces the overhead on our teams from having to manually intervene and clean up unused data. The team that maintains SCARF has developed strong partnerships with our colleagues that build and maintain these various data systems to leverage their expertise and to work together to provide the APIs that SCARF invokes to safely restrict access to and eventually clean up data.
SCARF runs on a daily cadence: The lifecycle of products and features means that there are new types of data being created every day as well as types of data that become unused every day. Running the system regularly ensures that as the final references to assets are deleted, SCARF picks up these changes quickly and can trigger the relevant automation.
A summary of SCARF
SCARF provides a powerful suite of tools to the company’s engineering teams. Its workflow management tooling powers thousands of human-led deprecation projects alongside the millions of code and data assets it has cleaned automatically.
SCARF also serves useful purposes for Meta’s privacy teams: We can use the tool to monitor the progress of ongoing product deprecations and ensure that they are completed in a timely manner. When there’s work that our automation is unable to do, SCARF’s internal tooling educates engineers about what they need to do and how to do it safely. The information it provides is not generic: It is tailored to the specific code and data that an engineer is deleting, empowering them to make the right decisions in the most efficient manner.
By discussing privacy innovations like SCARF, we hope to create transparency about our continuous investment in infrastructure that delivers privacy protections for the people that use our products and services. Our dedication to automating and orchestrating unused code and data deletion in a comprehensive manner is just one example of the substantive privacy by design measures we focus on at Meta.
Product deprecation can be safe, efficient, and thorough, even with infrastructure as complex and vast as Meta’s. Combining automation with engineering tooling is a tried and tested strategy that we have found to be very effective. We are investing in this space for the long-term since product deprecation is a continuous part of the data lifecycle, which contributes to the sustained success of any large tech company like Meta.








